MultiAgentBench:一套真正评测多智能体协作与博弈能力的基准
- 摘要:大语言模型已经展现出作为自主智能体的显著能力,但现有基准要么只关注单智能体任务,要么局限于狭窄领域,无法刻画多智能体协作与竞争的动态过程。本文提出 MultiAgentBench,这是一个面向 LLM 多智能体系统的综合性评测基准,覆盖多种交互式场景。该框架不仅评估任务完成情况,还通过新提出的、基于里程碑的关键绩效指标来衡量协作与竞争质量。此外,作者系统评估了多种协调协议,包括 star、chain、tree 和 graph 拓扑,以及 group discussion 和 cognitive planning 等策略。实验表明,gpt-4o-mini 平均任务分最高;在 research 场景中,graph 结构是最优协调协议;cognitive planning 可将里程碑达成率提升 3%。代码和数据集已开源:https://github.com/ulab-uiuc/MARBLE
- 其他信息
- 论文同时提出了 benchmark 和运行框架 MARBLE(Multi-agent cooRdination Backbone with LLM Engine)
- 覆盖 6 类场景:research、Minecraft、database、coding、Werewolf、bargaining
- 重点不只评最终任务结果,还评估 planning、communication、milestone progression 和 competition
论文动机
这篇论文的本质很直接:大家都在说 LLM agent 能协作、能分工、能博弈,但此前 benchmark 大多测的是单智能体,或者只测某个窄任务,几乎没有系统回答一个核心问题:一群 LLM agent 放到真实交互环境里,到底会不会合作,合作质量如何,竞争时又会不会出现真正的策略行为。
论文要解决的旧问题主要有三类:
- 只看结果,不看过程。以往 benchmark 常只看任务是否做完,却不看中间是谁推动了进展、沟通有没有价值、计划是否合理。
- 只看单体,不看群体。多智能体最关键的是 communication、role assignment、trust、conflict,但旧 benchmark 很少显式测这些。
- 只看合作,不看竞争。真实世界里很多场景既有协作也有对抗,比如狼人杀、谈判,过去缺少统一评测。
作者因此提出 MultiAgentBench 和底层框架 MARBLE,目标不是再造一个 agent system,而是造一把“尺子”:既量任务完成,也量 coordination,还量 competition。
先看总览图,图里已经把论文主线说清楚了:多智能体系统在不同环境中交互,最后从任务表现和协同表现两条线评测。
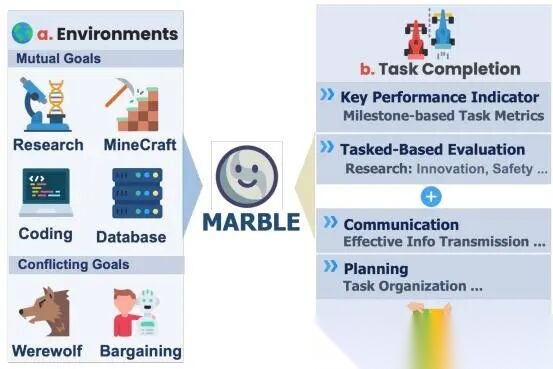
MultiAgentBench 总览
这篇论文的一个关键判断是:多智能体系统不能只用最终分数衡量,因为很多任务是迭代推进的,所以他们引入 milestone-based KPI。这个设计背后的直觉很像项目管理:不是只看最后论文写没写完,而是看中间有没有完成文献调研、方法设计、实验计划这些关键节点。
提出的方法
论文方法分成两层:
- 一层是运行框架 MARBLE:让多个 agent 真能在环境里协同。
- 一层是评测框架 MultiAgentBench:定义场景、指标和比较方式。
- MARBLE 框架的本质
MARBLE 的核心不是“让 agent 更聪明”,而是把多智能体系统拆成几个必要部件:关系图、认知模块、协调引擎、记忆、环境、通信、动作。
整体结构见图:
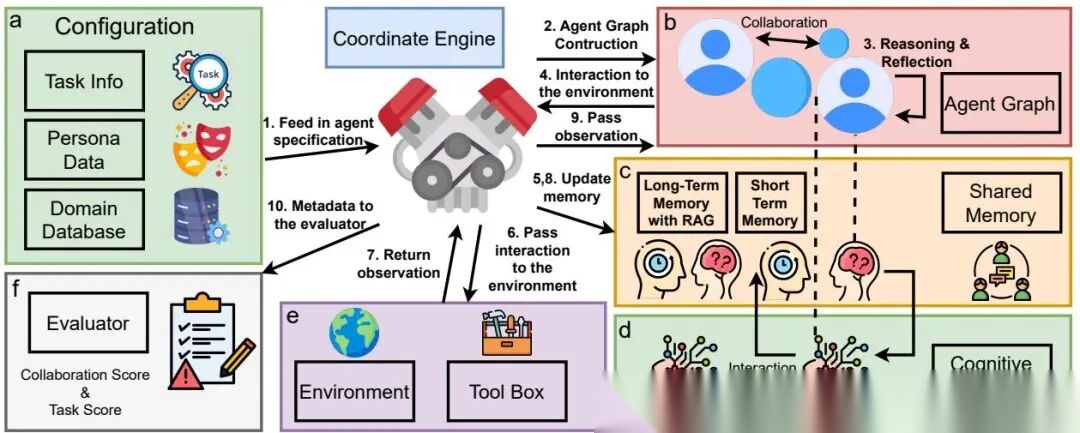
MARBLE 框架
图中最重要的是两点:
- agent 之间不是任意通信,而是按图结构通信;
- planning 和 acting 被拆开,planner 负责分解任务,actor 负责执行。
1.1 Agent Graph
作者把多智能体系统形式化为图:
其中 是 agent 集合, 是边集。每条边写成三元组:
这里 表示关系类型,比如 collaborates、supervises、negotiates。
这公式看似简单,实质上是在说:多智能体不是“多人同时调用同一个 LLM”,而是一个带关系约束的社会结构。边决定了谁能和谁说话,怎么说话。这个设计把“组织结构”正式纳入 benchmark。
1.2 Cognitive Module
这一部分没有复杂公式,但很关键。作者认为多智能体协作不是只靠 prompt 轮流对话,还需要内部状态:
- persona
- agent 间关系
- reasoning strategy
- 历史经验
它有点像给每个 agent 配了一个“社会化脑内模型”。例如狼人杀中,Seer 不只是做推理,还要考虑“我现在暴露身份会不会被刀”“别人会不会相信我”。
1.3 Coordination Engine
这里是系统调度核心。作者区分了两种角色:
- planner:做任务分解、分配、统筹
- actor:真正去和环境、工具、其他 agent 交互
这很像公司里“项目经理”和“执行人员”的分工。
作者比较了四种 coordination protocol,如图 3 所示:
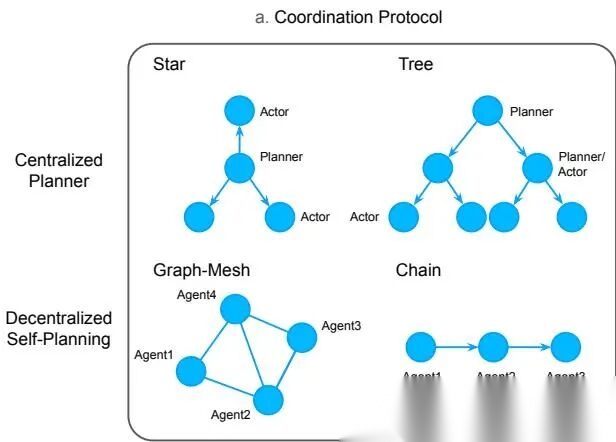
协调协议与规划策略
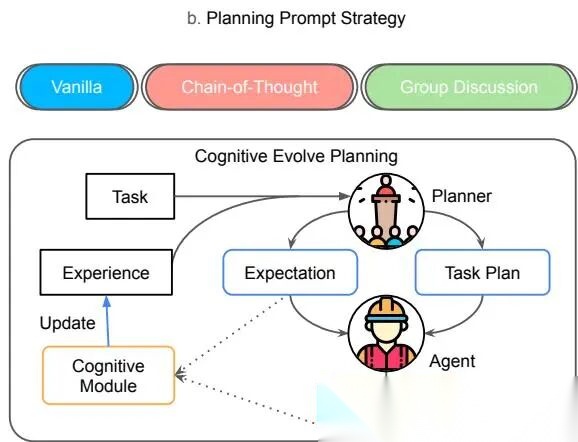
协调协议与规划策略-续
四种结构的本质区别:
- Star:一个中心 planner 指挥所有人。控制强,但容易瓶颈。
- Tree:分层管理。比 star 更可扩展,但层级传递可能失真。
- Graph:网状互联。最灵活,支持并行协作。
- Chain:串行传递。适合依赖链明确的任务,但并行性差。
这部分其实就是在问:多智能体协作,组织结构本身是不是性能变量。论文答案是,是的,而且影响很大。
1.4 四种 planning strategy
在 centralized setting 下,planner 又分四种提示策略:
- Vanilla prompting
- Chain-of-Thought
- Group discussion
- Cognitive self-evolving planning
其中最值得分析的是 cognitive self-evolving planning。它借鉴 Reflexion,核心流程是:
- 先生成对任务进展的预期;
- 把预期存入 memory;
- 后续执行后,把真实结果和预期比较;
- 形成经验,修正后续规划。
本质上就是把“计划-执行-复盘”做成闭环,而不是一次性规划。
- Benchmark 设计
作者构造了 6 类场景,分成两大类:
2.1 共同目标任务
- Research
- Minecraft building
- Database diagnosis
- Coding
这些任务里 agent 目标一致,要分工协作。
2.2 冲突目标任务
- Werewolf
- Bargaining
这些任务里 agent 有冲突利益,要在对抗中表现社交策略。
场景设计示意见图:
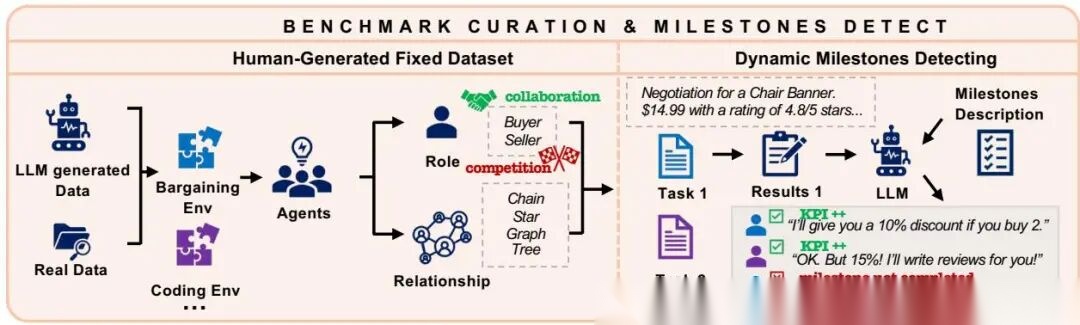
Benchmark 构建与里程碑检测
这张图最关键的点在于 milestone generation 和 dynamic milestone detection。作者不是把任务粗暴地打一个最终分,而是把过程拆成多个可检测进展点。
- 评测指标
这部分是全文最重要的“方法贡献”。
3.1 KPI:过程推进指标
设总 milestone 数为 ,第 个 agent 参与完成的 milestone 数为 ,则单个 agent 的 KPI 是:
整体 KPI 为:
这公式表面是平均值,实际测的是“团队平均参与进度推进的程度”。
仔细看它的性质:
- 如果少数 agent 包办全部 milestone,而其他 agent 基本无贡献,那么 overall KPI 不会特别高。
- 如果多数 agent 都参与推进 milestone,KPI 会提升。
所以它不是单纯测任务是否推进,而是在奖励“分布式贡献”。
举个直观算例。假设有 个 agent,任务共 个 milestone:
- agent1 贡献 5 个
- agent2 贡献 3 个
- agent3 贡献 1 个
- agent4 贡献 1 个
则
如果换成四个 agent 都各贡献 3 个 milestone,总和也是 12,但
说明该指标鼓励更均衡的协作。
3.2 Task Score
KPI 只看过程,不看最终产出质量,所以还要有 Task Score。
- Research、Bargaining:用 LLM rubric 打分
- Minecraft、Werewolf、Database、Coding:尽量用 rule-based accuracy 或明确规则
这很合理,因为开放式任务难有标准答案,只能做 rubric;封闭式任务则应尽量规则评测。
3.3 Coordination Score
作者把 coordination 拆成两个子项:
- Communication Score:沟通是否清晰、有效、符合角色关系
- Planning Score:任务分工是否清晰、角色是否合理、策略是否调整
最终:
这个式子很直接,就是取平均。但它隐含一个观点:沟通和规划同等重要。一个系统即使计划很好,但沟通混乱,也不算真会协作;反之亦然。
3.4 环境交互公式
附录中,环境交互被写成:
含义是:当前动作 由 agent 状态和记忆共同决定,环境再返回下一步观测 。
这就是标准 agent loop,但这里特别强调 shared memory 和 individual memory 同时参与决策。
记忆集合写为:
本质上:
- 是团队公共白板
- 是个人笔记本
这对多智能体尤其关键,因为协作失败很多时候不是推理不行,而是“信息没有共享”或“共享太多导致噪声”。
实验
- 实验总设定
模型包括:
- Meta-Llama-3.3-70B
- Meta-Llama-3.1-70B-Instruct-Turbo
- Meta-Llama-3.1-8B-Instruct-Turbo
- GPT-3.5-turbo-0125
- GPT-4o-mini
统一设置大致为:
- max token 1024
- temperature 0.7
- top_p 1.0
- communication iteration 最多 5
- graph-mesh 作为主实验默认协议
这里一个值得注意的点是:主实验默认 graph-mesh,其实已经先验地偏向“去中心化更强”的设定,后面协议对比再专门单独做。
- 主实验一:不同模型跨场景表现
主结果表如下:
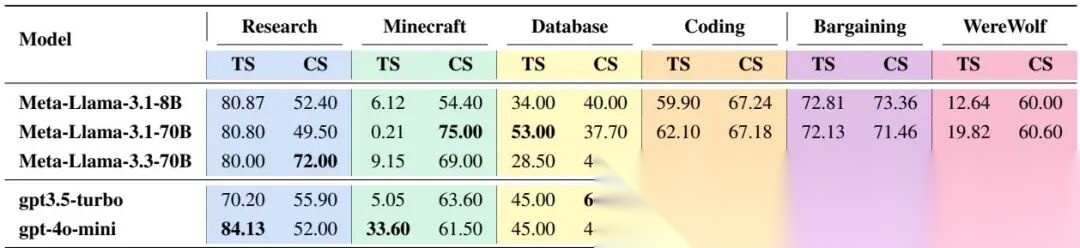
主实验表 1
作者的核心结论很明确:模型能力仍然是第一决定因素,multi-agent coordination 不是“低能模型组团就能逆袭”。
2.1 gpt-4o-mini 的总体最强
例如 Research 里,gpt-4o-mini 的 TS 是 ,高于 Meta-Llama-3.1-8B 的 和 Meta-Llama-3.1-70B 的 。Coding 中也领先。
本质解释:
- coordination 能放大能力;
- 但放大的是已有能力,不是凭空创造能力。
2.2 CS 和 TS 不总是同步
论文给出的典型例子是 Minecraft:Meta-Llama-3.1-70B 的 CS 高达 75.00,但 TS 只有 0.21。
这说明一个很重要的事实:会“聊”不等于会“做”。如果 function call 执行失败,再高的交流分也救不了任务完成。
后面附录分析表明,这个模型在 Minecraft 上 function call executability 很低,几乎是硬伤。
2.3 不同模型在不同任务有偏科
例如某些模型在 Werewolf 或 Research 上 coordination 分高,但任务分不一定最高。这说明 benchmark 设计是有效的:它把“社交协作能力”和“任务执行能力”部分解耦了。
- 主实验二:不同协作协议和 planning 策略
3.1 协作协议比较
图 5 展示了 Research 场景下不同协议的比较:
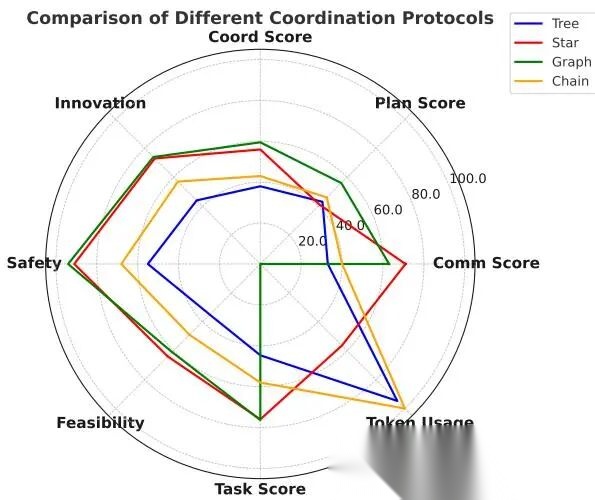
不同协调协议比较
结论非常清楚:
- Graph 最好,task performance、planning efficiency、token usage 综合最优
- Star 接近 Graph
- Tree 最差,token 消耗高,TS 和 CS 都低
- Chain 居中
这个结果很有意思。直觉上 tree 应该兼顾控制和扩展性,但实验反而最差。原因并不神秘:层级越多,信息失真越严重,planner 的理解误差会逐层放大,还会引入额外 token 消耗。
Graph 最优的原因是它最像现实中的高效小组:成员能直接交换信息,不必层层上报。
3.2 规划策略比较
图 6 展示不同 planning prompt 的效果:
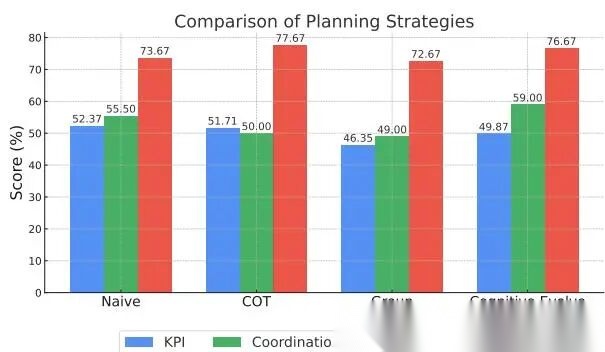
不同规划策略比较
结论:
- Cognitive Evolving Planning 的 CS 最好
- 任务分与最佳的 CoT 接近
- Group Discussion 最差
这里最值得讲的是 Group Discussion 为什么差。论文解释是“规划组太大反而低效”,这很像现实里的大群开会:讨论热闹,但不推进决策。多智能体并不是 agent 越多、讨论越充分越好,关键是信息是否转成有效决策。
而 cognitive planning 提升 milestone achievement rate 约 ,这说明“复盘式规划”确实能让系统更稳步推进。
- 消融实验
4.1 最大迭代次数
图 7:
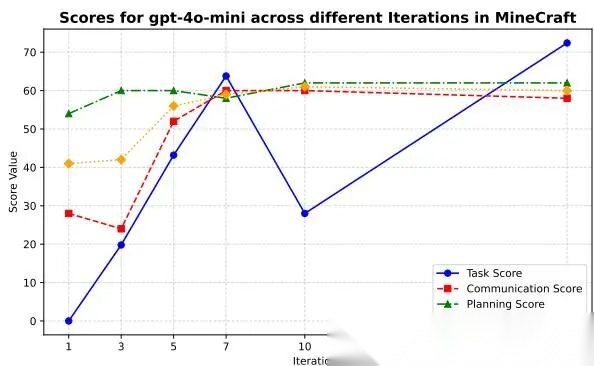
不同迭代次数消融
结果:
- 从 1 到 7 次迭代,TS 和 coordination 分数上升
- 到 10 次时明显下跌
- 到 20 次时 TS 回升一些,但 coordination 不再提升
这揭示一个非常现实的问题:多轮协作不是越久越好。轮次增加会带来两类成本:
- communication overhead
- conflicting directives
简单说,讨论多了会跑偏、会重复、会互相覆盖。
这和真实团队完全一致:少量同步有益,过度同步反而拖慢。
4.2 agent 数量
图 8:
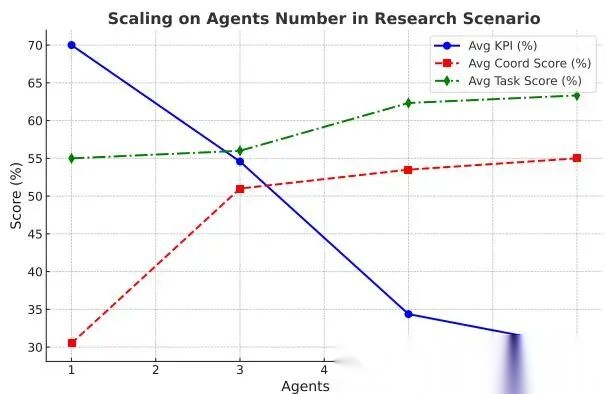
agent 数量扩展实验
结论:
- 从 1 到 3 个 agent,coordination score 提升明显
- task score 也上升,但更平缓
- agent 继续增多时,overall KPI 下降
这说明多智能体存在一个“甜点区间”。少量 agent 能形成分工协同;过多 agent 则带来 coordination tax。不是人越多越强,而是管理复杂度上升得更快。
- Emergent Behavior 分析
这部分是论文最有意思也最容易被包装的地方。去掉包装后,本质就是:在复杂社交博弈环境里,LLM agent 会出现一些类人的策略模式,而且这些模式能被统计到。
作者定义三类 emergent behaviors:
- Strategic Information Sharing
- Trust-Polarized Collaboration
- Role-Driven Strategy Iteration
5.1 Werewolf 中的涌现行为
统计表如下:
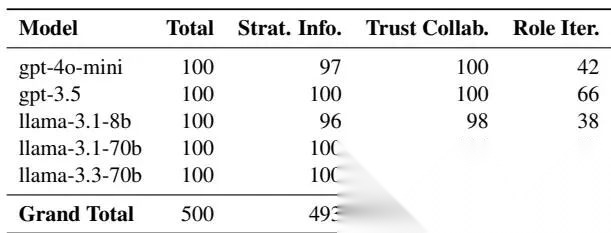
Werewolf 涌现行为统计
结论:
- Strategic Information Sharing 和 Trust-Polarized Collaboration 很常见
- Role-Driven Strategy Iteration 相对少
这很合理。狼人杀本来就是“信息选择性披露”和“信任分裂”驱动的游戏。角色策略迭代较少,是因为游戏轮数有限,还没长到足够形成复杂长期策略。
5.2 Bargaining 中的涌现行为
统计表如下:
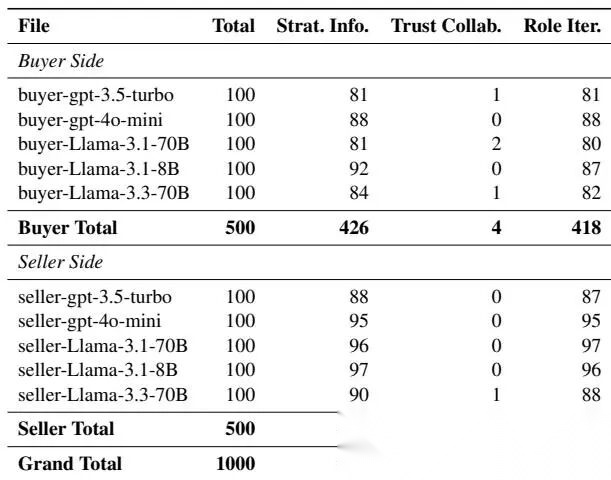
Bargaining 涌现行为统计
结果与 Werewolf 不同:
- Strategic Information Sharing 仍然最常见
- Trust-Polarized Collaboration 很少
- Role-Driven Strategy Iteration 频繁
也合理。谈判主要是双边互动,没有狼人杀那种阵营联盟和集体怀疑,所以“信任极化”弱;但买卖双方会不断根据角色调整出价策略,所以 role-driven iteration 更常见。
- 人类评估与自动评估一致性
作者专门做了 human evaluation。相关结果如下:
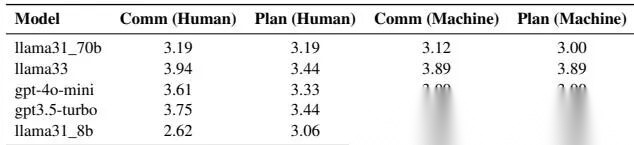
人机评估对比表 4

协调分数统计表 5

相关性与标注一致性表 6/7

相关性与标注一致性补充
结论是:机器打的 communication / planning 分和人类判断相关性较强,尤其 communication 更稳定。
这意味着他们的 LLM-as-a-judge 不是完全悬空的,至少在 Werewolf 场景中和人类观感基本同向。
- 各任务场景细节与关键结论
7.1 Research
Research 场景要求 agent 基于论文 introduction 生成一个 5Q 研究提案。任务案例:

Research 任务示例
agent profile 案例:

Research agent profile
5Q 输出案例:

5Q 输出示例
Research 的 task score 本质上评三件事:
- Innovation
- Safety
- Feasibility
这里 KPI prompt 和 5Q prompt 非常关键,因为 milestone 就是围绕 “form 5q” 和 “improve 5q” 判断的。它等价于在看团队是不是逐步把一个研究 idea 从模糊讨论推到成型 proposal。
7.2 Werewolf
Werewolf 是全论文最能测 social reasoning 的场景。其评分既看单日任务,也看 full-game net score。
net score 和 result score 的关系图如下:
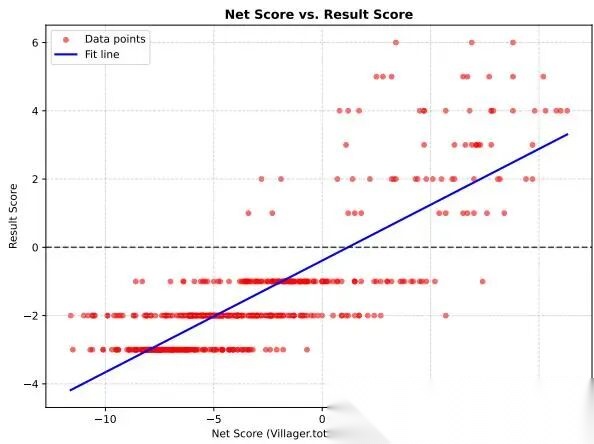
Werewolf net score vs result score
这个图说明:当 net score 接近 5 时,村民几乎必胜;在 0 到 5 之间,输赢摇摆;低于 0 往往狼人压制。
单日和全局结果表如下:
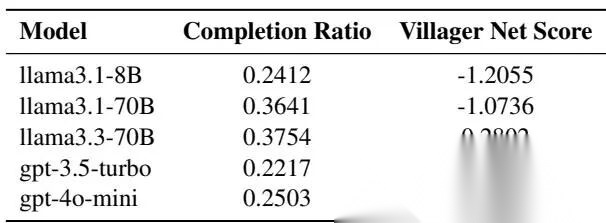
Werewolf 单日结果
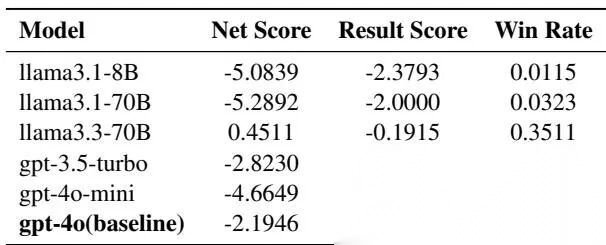
Werewolf 全局结果
一个非常亮眼的结果是:Llama-3.3-70B 在村民侧表现最好,甚至超过生成 archive 的 gpt-4o baseline。说明更强的协作行为并不总和最强生成模型绑定,某些模型在特定社交博弈上的角色利用更有效。
论文还给了几个很好的 case study。比如 gpt-4o 的 Seer 和 Witch 虽然推理强,但因为过度谨慎、不愿共享信息,反而输掉优势局。这非常点题:在多智能体博弈里,能力不等于合作,合作不只靠智力,还靠 trust。
Llama3.3-70B 对 gpt-4o 的案例中,村民通过及时暴露身份、传 sheriff badge、共享 Seer 信息赢下比赛,说明真正关键的是“关键时刻的信息公开与信任传递”。
7.3 Database
Database 环境是 5 个 agent 查数据库异常根因。它的难点不是 SQL 本身,而是:
- 数据库里会同时出现多种异常迹象
- 真正 root cause 未必只有一个
- benign queries 和 anomaly queries 混在一起
评分方式比较务实:50 个样本上看 root cause prediction accuracy,允许报两个原因,只要其中一个命中就算对。
这任务测的是“分工式诊断”:不同 agent 分头查不同异常,再汇总成判断,类似专家会诊。
7.4 Coding
Coding 场景从 SRDD 适配而来,强调真实软件协作中的几种 coordination strategy:
- adaptive task execution
- dependency management
- cross-domain collaboration
- test-driven development
评分不是只看能不能跑,还看:
- instruction following
- executability
- consistency
- quality
这说明 benchmark 不是把 coding 简化成 HumanEval,而是更像一个轻量软件团队协作任务。
7.5 Bargaining
Bargaining 场景是 2 seller 对 2 buyer,多方谈判。数据来自 Amazon products。人格采用 Big Five,谈判策略由 GPT 生成。
产品案例:
Bargaining 任务案例
buyer profile 案例:
Buyer 谈判策略案例
人格分布表:

人格分布表
协作分数表:

Bargaining 协作分数表
任务分表:
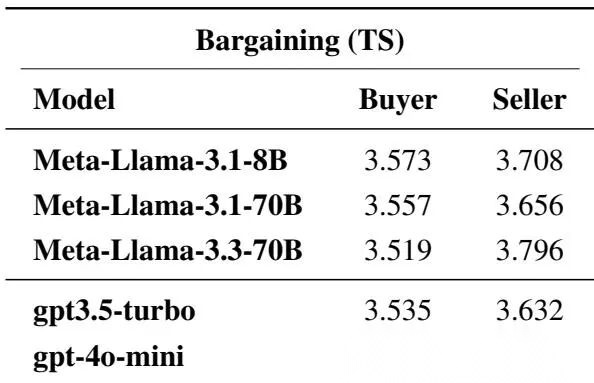
Bargaining 任务分表
关键结论:
- gpt-4o-mini 的 Bargaining 总分最高
- 各模型作为 seller 普遍比作为 buyer 更强
原因不难理解:seller 的目标通常更容易“防守式”表达,比如强调品质、维持价格锚点;buyer 需要在预算、质量、让步时机之间动态平衡,更难。
7.6 Minecraft
Minecraft 是 embodied-style 协作建造任务。评分公式是:
这公式很干净:看最终建造中正确方块所占比例。正确不仅指 block type,还包括 location 和 orientation。
block 数量分布如下:
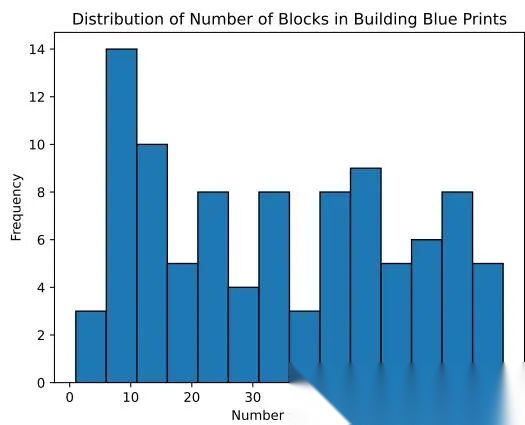
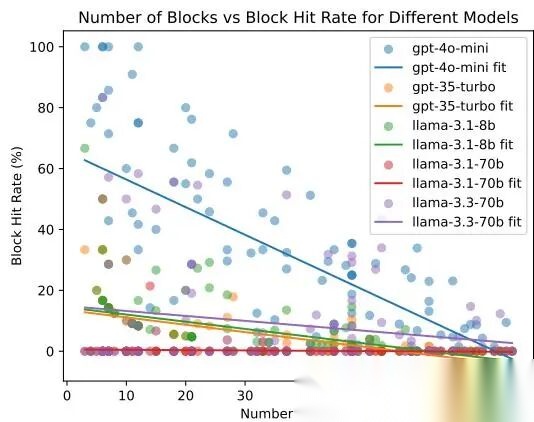
Minecraft 任务难度分布
模型性能与 block 数关系如下:
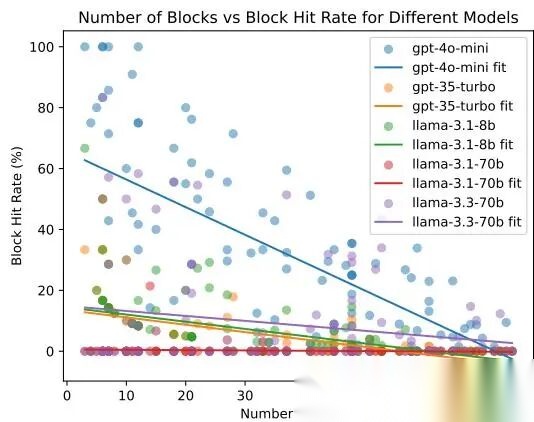
Minecraft 难度与命中率关系
结论:任务越复杂,所有模型都会退化。
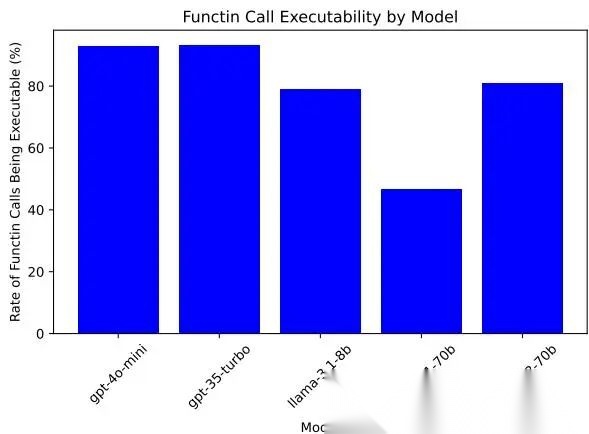
function call 可执行率如下:
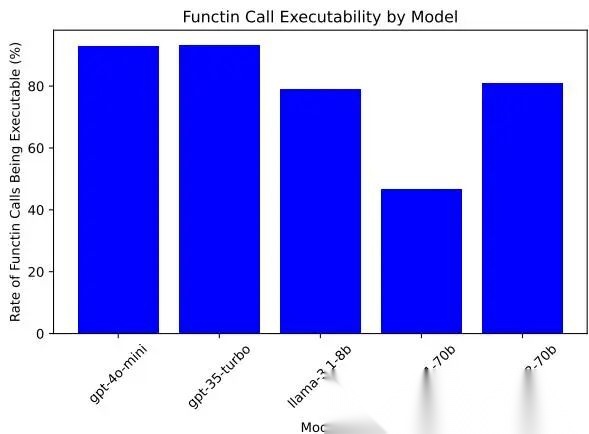
函数调用可执行率
这里有个关键发现:Llama-3.1-70B 在 Minecraft 上不是“不会规划”,而是“不会稳定调工具”。可执行率不足 50%,所以任务分接近归零。这是一个很重要的 benchmark 启示:在 agent 场景里,tool-use robustness 是一等公民。
总结
这篇论文的核心贡献可以浓缩成四句话:
- 它把多智能体 benchmark 从“只看结果”推进到“结果 + 过程 + 协调 + 竞争”。
- 它提出 milestone-based KPI,让“谁推动了进展”可以量化。
- 它系统比较了组织结构和规划策略,证明 graph coordination 和 cognitive planning 更有效。
- 它展示了 LLM agent 在狼人杀、谈判等场景中会出现初步的社会性涌现行为,但这些行为仍然脆弱,远谈不上稳定可靠。
对现有工作的启发主要有这些:
- 多智能体研究不能只报 final success rate,必须拆开看 planning、communication、milestone progression。
- 模型能力仍是底座,协作机制更多是放大器,不是替代品。
- 组织结构是重要自变量,graph 往往优于过强层级化结构。
- 社会性任务里,trust management 比纯 reasoning 更关键。
- tool-use 成功率会直接决定 agent benchmark 结果,尤其在 embodied 或 coding 任务里。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献183条内容
已为社区贡献183条内容

所有评论(0)