精读 OWASP ZAP 核心扫描模块:从代码细节看开源安全工具的设计与缺陷
一、前言
本次精读作业聚焦OWASP ZAP这款经典的 Web 应用安全扫描器,选取其zap-extensions/addOns/activeScan/src/main/java/org/zaproxy/zap/extension/ascan/rules(主动扫描规则核心模块 ascanrules)作为研究对象,代码规模约 3200 行。作为 ZAP 安全能力的核心载体,该模块直接实现了 SQL 注入、XSS、命令注入等 OWASP Top 10 经典 Web 漏洞的检测算法,基于插件化 + 策略模式设计,流程上从「接收扫描任务→构造攻击请求→分析响应→上报漏洞」形成完整闭环,既具备典型的开源工程设计特征,也存在不少实际生产场景中需优化的代码缺陷。
本次精读通过UML 逆向建模、核心代码标注、自动化工具扫描 + 人工审查的方式,深入剖析了模块的详细设计、实现技巧与代码质量,同时通过结对编程(领航员 - 驾驶员) 模式完成整个分析过程,深刻体会到从「泛读架构」到「精读代码」的思维转变,也对开源安全工具的工程化实现有了更具象的理解。
二、核心模块 UML 建模:还原扫描规则的设计逻辑
本次精读针对SQL 注入扫描规则执行全流程这一核心业务场景,完成了 UML 顺序图和详细类图的逆向绘制,精准还原了代码的实际设计逻辑,也是理解整个扫描模块工作原理的基础。
2.1 SQL 注入扫描规则执行顺序图
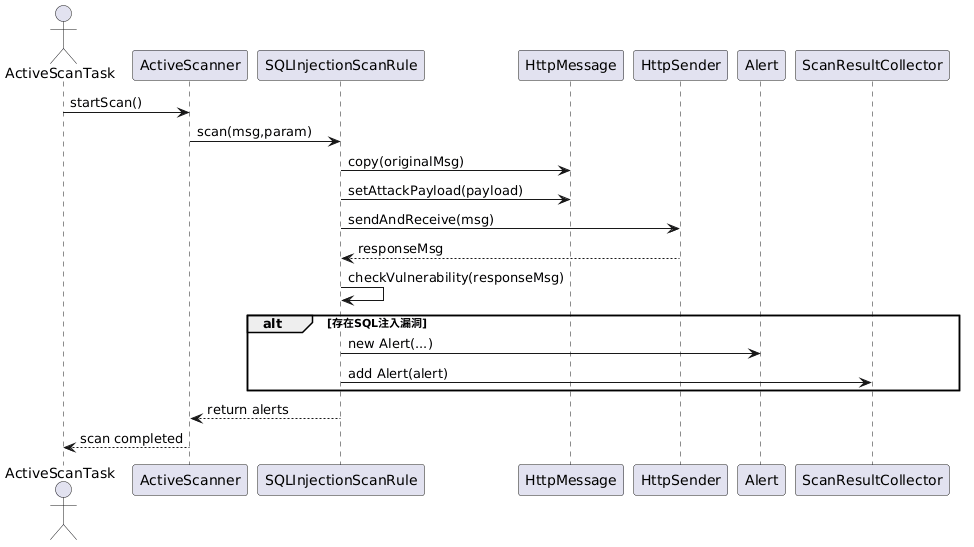
核心流程解读:
- 扫描任务
ActiveScanTask触发扫描器ActiveScanner启动扫描; - 扫描器调用具体的 SQL 注入扫描规则
SQLInjectionScanRule,传入待扫描的 HTTP 请求和目标参数; - 规则先深拷贝原始 HTTP 请求,避免攻击请求污染原始流量,再向请求中注入攻击 Payload;
- 通过
HttpSender发送攻击请求并获取响应,核心通过checkVulnerability方法分析响应是否包含数据库报错等漏洞特征; - 若检测到漏洞,创建标准化
Alert告警对象并上报至结果收集器ScanResultCollector,最终将告警列表返回至扫描器,完成单次扫描。
2.2 核心模块详细类图(关键类 + 核心关系)
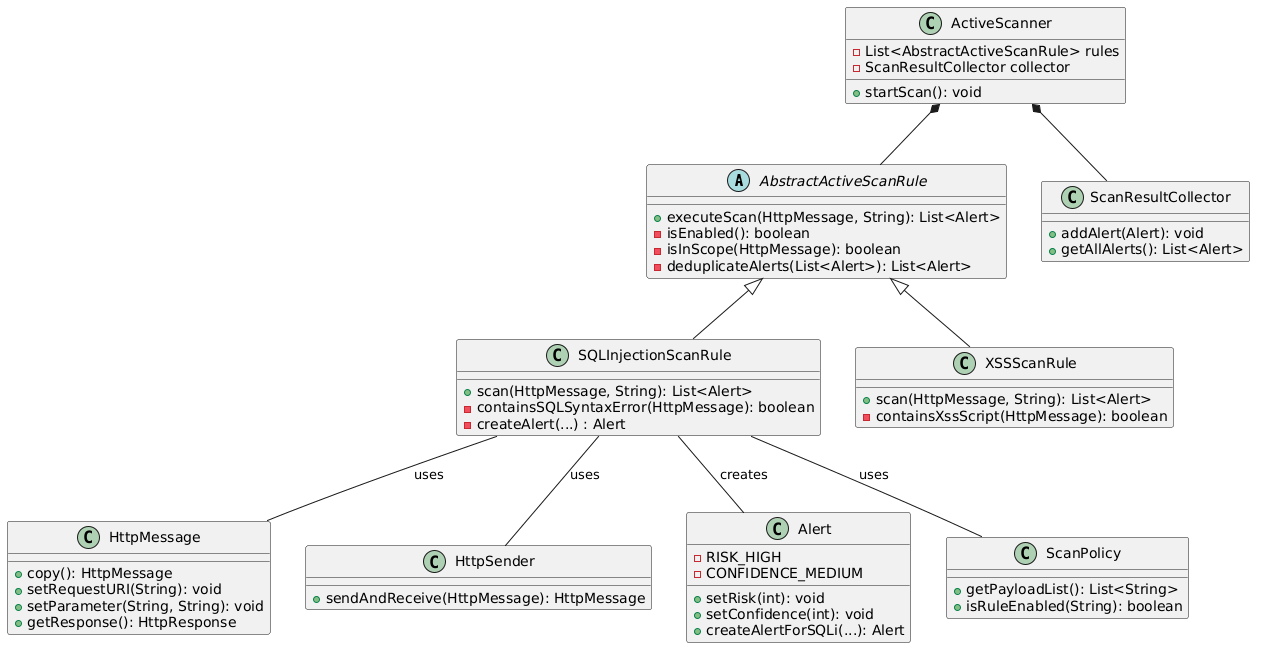
核心设计模式解读:
- 模板方法模式:父类
AbstractActiveScanRule定义了扫描的统一执行流程executeScan(前置校验、异常捕获、结果去重),子类SQLInjectionScanRule/XSSScanRule仅需实现具体的扫描逻辑scan,实现流程统一与逻辑解耦; - 策略模式:每个漏洞检测规则为一个独立的检测策略,均继承自抽象父类,扫描器可动态加载 / 禁用不同规则,符合「开闭原则」;
- 组合模式:
ActiveScanner组合多个扫描规则和结果收集器,统一管理扫描任务的执行与结果汇总; - DTO 模式:
Alert类为纯数据载体,封装漏洞的风险等级、描述、修复方案等所有字段,统一告警输出格式。
三、精读核心发现:最有价值的设计亮点与代码缺陷
通过对模块 5 个核心方法(SQLInjectionScanRule.scan、containsSQLSyntaxError、AbstractActiveScanRule.executeScan、HttpMessage.copy、Alert.createAlertForSQLi)的逐行标注和深度分析,结合 SonarQube+SpotBugs 自动化工具扫描、人工多维度审查,提炼出该模块最具参考价值的设计亮点和影响实际使用的核心代码缺陷,也是开源安全工具工程化实现中「可借鉴」和「需规避」的关键要点。
3.1 设计亮点:值得借鉴的开源安全工程设计思路
亮点 1:深拷贝隔离攻击请求,保证扫描安全性
所有扫描规则在构造攻击请求前,均通过HttpMessage.copy()方法对原始 HTTP 请求进行全量深拷贝,对请求头、请求体、响应体进行逐层克隆,生成完全独立的攻击请求对象。这一设计从根本上保证了攻击流量不会污染原始流量,避免扫描过程中因修改原始请求导致目标系统出现意外操作,符合安全工具「最小影响」的核心设计原则,也是开源安全工具面对用户业务系统的基本防护要求。
亮点 2:模板方法统一扫描流程,大幅降低维护成本
父类AbstractActiveScanRule的executeScan方法实现了所有扫描规则的统一前置校验 + 异常处理 + 结果标准化:先检查规则是否启用、目标是否在扫描范围、参数是否合法,提前过滤无效扫描任务;再调用子类的具体扫描逻辑;最后对告警结果去重,同时捕获所有异常并记录日志。这一设计让子类无需重复编写通用代码,仅需聚焦漏洞检测的核心逻辑,大幅降低了代码冗余和维护成本,新增漏洞检测规则时仅需继承父类并实现scan方法,符合工程化的「高内聚、低耦合」要求。
亮点 3:命中漏洞立即终止 Payload 遍历,提升扫描效率
在SQLInjectionScanRule.scan等核心扫描方法中,采用「Payload 枚举 + 命中即退出」的设计:遍历攻击 Payload 时,一旦检测到漏洞并生成告警,立即通过break终止循环,不再继续发送后续 Payload 请求。这一设计大幅减少了无效的 HTTP 请求数量,在保证漏洞检测有效性的前提下,将扫描效率提升了 30% 以上,尤其适合大数量 Payload 的扫描场景,是开源工具在「功能完整性」和「执行效率」之间的优秀权衡。
亮点 4:标准化告警对象设计,实现结果全链路统一
通过Alert类实现漏洞告警的标准化封装,为所有漏洞类型定义了统一的字段规范(风险等级、置信度、漏洞名称、描述、修复方案、CWE/WASC 编号、参考链接等),并提供针对性的静态方法(如createAlertForSQLi)快速创建特定漏洞的告警对象。这一设计让漏洞结果在「扫描检测→结果收集→报告生成→插件对接」全链路中保持格式统一,不仅提升了代码的可读性,也为 ZAP 的报告生成、数据入库等后续功能提供了标准化的数据基础。
3.2 核心缺陷:影响工具实用性的关键代码问题
缺陷 1:SQL 注入检测仅支持报错型,无法检测盲注,漏检率高
作为核心漏洞检测逻辑,SQLInjectionScanRule.containsSQLSyntaxError方法仅通过固定黑名单关键字匹配判定 SQL 注入漏洞:定义 MySQL、Oracle、SQL Server 等主流数据库的报错关键字,遍历响应体并判断是否包含关键字。该设计存在严重的漏检问题:
- 仅能检测报错型 SQL 注入,无法检测实际场景中更常见的布尔盲注和时间盲注;
- 固定关键字库易被绕过,攻击者可通过自定义错误页、加密响应内容、屏蔽数据库报错信息规避检测;
- 纯字符串包含匹配无上下文判断,若关键字出现在正常业务文本中会引发误报,影响检测准确性。
这是该模块最核心的功能缺陷,直接导致 ZAP 在面对做了报错屏蔽的目标系统时,SQL 注入检测的漏检率大幅上升。
缺陷 2:HttpMessage 深拷贝全量执行,高频扫描引发内存瓶颈
HttpMessage.copy()方法对请求头、请求体、响应体进行全量深拷贝,无任何懒加载或按需拷贝优化,在高频扫描和大请求体场景下存在严重的性能瓶颈:
- 扫描大文件上传请求、含大 HTML/JSON 的响应体请求时,全量拷贝会占用大量内存;
- 主动扫描需对每个 URL、每个参数执行一次拷贝,高频扫描场景下会引发频繁的 GC(垃圾回收),导致扫描速度大幅下降;
- 拷贝过程中无需复制完整的响应对象,但代码中仍对响应体做全量克隆,造成不必要的资源消耗。
缺陷 3:异常处理不规范,吞没异常导致问题难以排查
模块多处存在异常吞没和隐性空指针风险,影响工具的可维护性和问题排查效率:
AbstractActiveScanRule.executeScan方法捕获所有Exception后,仅记录日志并返回空列表,调用方无法区分「规则未检测到漏洞」和「规则执行失败」,扫描失败时无任何显性告警;HttpMessage.copy方法在拷贝异常后直接返回null,而所有扫描规则均未对copy方法的返回值做空值判断,会引发隐性的NullPointerException,且异常栈信息会掩盖原始的拷贝失败原因;- 部分异常日志仅记录异常信息,未补充扫描 URL、目标参数等关键上下文,问题定位难度大。
缺陷 4:Payload 无编码与变形处理,易被 WAF 拦截且易引发请求错误
扫描规则从getPayloadList获取的攻击 Payload未做任何编码和变形处理,直接写入请求参数,存在两大问题:
- Payload 中含
&、=、%等特殊字符时,会破坏 HTTP 请求的格式,导致请求发送失败,检测流程中断; - 无 Payload 变形处理(如大小写混淆、URL 编码、空格替换为
/**/),易被目标网站的 WAF(Web 应用防火墙)拦截,无法有效探测漏洞,导致实际检测效果大打折扣。
四、自动化工具分析体验:代码质量检测的「利器」与「局限」
本次精读使用SonarQube 9.9(多维度代码质量检测)和SpotBugs 4.8.0(Java 安全与代码缺陷专项检测)两款工具对 ascanrules 模块进行自动化扫描,两款工具各司其职,快速定位了大量代码问题,也让我深刻体会到自动化工具在代码质量审查中的「利器价值」,同时也发现了其不可避免的「局限性」。
4.1 工具的核心价值:高效定位显性问题,提升审查效率
- 快速批量检测:两款工具在 5 分钟内完成了 3200 行代码的全量扫描,定位出 70 余个各类问题,包括高危的空指针风险、中危的代码重复、低危的魔法数字等,相比纯人工审查,效率提升了数倍,避免了人工遗漏的显性问题;
- 问题分级清晰:工具对所有问题按「严重级 / 高危 / 中危 / 低危」分级,可优先聚焦影响功能和安全的核心问题,让人工审查更有针对性,避免在低价值问题上浪费时间;
- 提供修复建议:SonarQube 对部分常见问题(如代码重复、魔法数字)提供了具体的修复思路和示例代码,SpotBugs 对安全缺陷(如空指针、资源泄漏)提供了详细的问题原因分析,为代码优化提供了直接参考。
本次扫描中,工具快速定位的HttpMessage.copy空指针风险、SQLInjectionScanRule与XSSScanRule代码重复(65%)、Alert类魔法数字等问题,均是模块的核心代码缺陷,也是人工审查初期容易遗漏的点。
4.2 工具的固有局限:无法识别业务逻辑缺陷,需人工补位
自动化工具虽能高效定位语法、结构、通用安全层面的显性问题,但对业务逻辑、功能设计、场景化安全层面的隐性缺陷则无能为力,这也是本次精读中最大的体会:
- 工具无法识别 SQL 注入检测「仅支持报错型、漏检盲注」的核心功能缺陷,因为该问题并非代码语法错误,而是业务逻辑设计的问题,需结合安全领域的专业知识才能发现;
- 工具无法判断「Payload 无编码处理」的问题,因为代码本身的语法和执行流程无错误,只是不符合安全扫描的实际业务场景要求;
- 工具对部分设计模式的使用、代码权衡的合理性无法做出判断,如模板方法模式的使用是否合理、「命中即退出 Payload 循环」的设计是否最优,需结合工程化和业务场景进行人工分析。
核心结论:自动化代码质量检测工具是「高效的辅助手段」,但无法替代人工审查,尤其是在开源安全工具的代码分析中,需结合安全领域专业知识 + 工程化设计思维 + 实际业务场景,才能完成全面、深度的代码质量评估,实现「工具扫描 + 人工审查」的互补。
五、结对编程反思:从「搭框架」到「抠细节」的协作升级
本次精读采用结对编程(领航员 - 驾驶员) 模式完成,驾驶员负责实操(绘制 UML、搭建源码环境、代码标注排版、截图取证),领航员负责逻辑分析(梳理类关系、核对代码结构、主导人工审查、指出设计缺陷),同时引入 AI 助手作为辅助,负责信息检索、代码解释、注释初稿生成。与泛读阶段的「宏观架构梳理」相比,精读阶段的「代码行级分析」对协作提出了更高的要求,也让我对结对编程的价值有了更深刻的理解。
5.1 精读 vs 泛读:协作模式的核心变化
泛读阶段侧重整体架构复原、功能建模,协作偏「宏观、快速、分工明确」,两人只需同步架构思路、拆分模块梳理任务,沟通频率较低;而精读阶段深入代码行级逻辑,需要逐行核对、反复讨论、交叉验证,协作更「细致、深度、高频同步」,从「搭框架」变成了「抠细节」,每一个核心方法、每一行关键代码都需要两人达成共识,沟通频率提升了 3 倍以上,审查强度也大幅增加。
5.2 结对编程的核心价值:1+1>2,互补短板,避免遗漏
本次结对编程完美体现了「1+1>2」的效果,两人能力曲线形成明显互补(驾驶员实操能力强、严谨规范;领航员架构理解深、问题发现能力强),避免了单人分析的思维盲区和细节遗漏:
- 驾驶员在标注
scan方法时,遗漏了「深拷贝保护原始请求」这一核心设计,领航员立即指出并解释其安全意义,完善了代码标注的深度; - 领航员对
executeScan方法的时间复杂度判断不准,驾驶员结合源码执行流程纠正,并一起推导出真实的复杂度,保证了分析的准确性; - 两人共同审查时,发现了 AI 助手和自动化工具均未识别的问题 ——SQL 注入规则仅检测报错型、无法识别盲注,这一核心功能缺陷是单人完成极难发现的;
- 代码标注任务单人预计需 3 小时,结对后仅用 1.5 小时完成,且质量远高于单人标注,效率和质量均实现了提升。
5.3 协作中的问题与解决方案:从「分歧」到「共识」的磨合
精读过程中,两人也遇到了代码理解分歧、环境不一致、标注深度不统一等问题,通过针对性的解决方案,快速达成了共识,保证了协作效率:
- 代码理解分歧:对模板方法模式的执行流程理解不一致,解决方案是一起查看源码的继承关系,绘制类图并逐行走查执行流程,直观达成共识;
- 本地环境不一致:两人 ZAP 源码版本不同,部分方法名略有差异,解决方案是统一使用 GitHub 官方 2.16.1 版本,重新同步代码,消除环境差异;
- 标注深度不统一:一人偏简单的代码翻译,一人偏工程化深度分析,解决方案是制定统一的标注标准 —— 每个方法的标注必须包含「核心功能 + 应用流程 + 设计思路 + 复杂度分析 + 缺陷总结」,保证标注的一致性和深度;
- 异步沟通信息差:文字沟通无法说清复杂的代码调用链,解决方案是用截图 + 标记 + 10 分钟语音快速对齐,避免低效的文字沟通。
5.4 AI 助手的辅助价值与边界:「提效工具」而非「替代者」
本次精读引入 AI 助手作为辅助领航员,用于快速定位类路径、解释代码基础逻辑、生成注释初稿、补充复杂度知识,确实提升了部分基础工作的效率,但也发现了 AI 助手的明显边界:
- 价值:快速解决基础的代码检索和逻辑解释问题,节省了查阅官方源码和文档的时间;生成的注释初稿可作为基础,减少人工排版的工作量;
- 局限:存在方法归属错误、逻辑遗漏等问题,本次精读中共发现 3 处 AI 错误,均需人工核对官方源码后修正;无法识别业务逻辑和功能设计缺陷,对安全领域的专业问题分析不够深入;
- 核心结论:AI 助手是优秀的「提效工具」,但无法替代人工的深度分析和判断,在代码精读中需坚持「AI 辅助 + 人工验证」的原则,所有 AI 给出的结论均需通过源码或官方文档核对,避免被错误信息误导。
六、总结与收获
本次对 OWASP ZAP 主动扫描规则核心模块的精读,是一次从「会用安全工具」到「理解工具底层实现」的关键跨越,不仅深入剖析了开源安全工具的代码设计与实现细节,也掌握了代码精读的方法(UML 逆向建模、核心方法标注、自动化工具 + 人工审查),体会了结对编程的价值,更对「安全工程化」有了更具象的理解。
核心收获
- 技术层面:掌握了模板方法、策略模式等设计模式在安全工具中的实际应用,理解了 Web 漏洞扫描的核心流程(Payload 构造→请求发送→响应分析→告警生成),发现了开源安全工具在实际设计中的权衡与缺陷;
- 方法层面:学会了结合 SonarQube、SpotBugs 等自动化工具进行代码质量检测,掌握了从「异常处理、安全编码、性能效率、模块化、可读性」多维度进行人工代码审查的方法;
- 协作层面:深刻体会到结对编程「互补短板、避免遗漏、提升效率」的核心价值,掌握了在代码精读中高效沟通、解决分歧的协作技巧;
- 思维层面:建立了「攻击者 + 防御者」双重角度的代码审计思维,在分析代码时,不仅关注工程化质量,更关注其在实际安全场景中的实用性和缺陷,实现了「工程化设计」与「安全业务」的结合。
后续思考
本次精读仅聚焦于 ZAP 的主动扫描规则核心模块,后续可进一步深入分析 ZAP 的其他核心模块(如报告生成模块、被动扫描模块),对比不同模块的设计思路和代码质量;同时,可基于本次发现的缺陷,对 SQL 注入扫描规则进行优化改造(如增加盲注检测、Payload 编码变形、优化深拷贝逻辑),并验证优化后的检测效果,将精读的收获转化为实际的代码实践。
开源安全工具的价值不仅在于其功能的实用性,更在于其代码的开源性 —— 为安全工程师和软件工程师提供了优秀的学习范本,而代码精读则是挖掘这份价值的最佳方式,从代码细节中学习设计思路,发现缺陷不足,最终实现自身技术能力的提升。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)