大模型“闭卷“VS RAG“开卷“,谁才是知识王?深度解析RAG技术如何逆袭!
本文深入解析了RAG(检索增强生成)技术,将其比喻为让AI学会"开卷考试"的关键。文章指出传统大模型如同"闭卷考试"的学霸,存在知识盲区、信息滞后、可能产生幻觉等问题。RAG通过结合检索与生成,让AI在回答问题时能实时调取最新资料,解决知识过时、不懂内部信息等痛点。文章详细阐述了RAG的工作原理、五代演进历程、技术栈全景图,并展望了未来趋势,强调RAG正推动AI从"检索"向"思考"进化。
如果说大模型是"闭卷考试"的学霸,那RAG就是让它学会"开卷考试"
本文约4200字,预计阅读10分钟

开篇:当AI遇到"知识盲区"
接上篇[5分钟理解 315 GEO"投毒"原理:3天让AI推荐不存在的产品],这里分上下两篇介绍下RAG相关技术。
过去一年,在落地RAG过程中,发现一个有意思的现象:很多人把AI当成了"万能百科全书",结果一问企业内部数据就抓瞎。
你有没有遇到过这样的情况:
问ChatGPT:“我们公司去年的销售额是多少?”
它回答:“抱歉,我无法获取您公司的内部数据…”
再问它:“帮我总结一下最新的行业政策变化。”
它又说:“我的知识截止到训练时间,无法获取最新信息…”
这不是AI不够聪明,而是它"不知道"这些信息。
传统大模型就像一个只能靠"脑子里的记忆"答题的学生——知识有截止日期、不知道企业内部信息、可能还会"编"答案。
RAG(检索增强生成)就是为了解决这个问题而生的。
简单说:RAG = 让AI学会"翻书"再答题
一、什么是RAG?用3分钟讲清楚
1.1 一句话定义
RAG = Retrieval(检索)+ Augmented(增强)+ Generation(生成)
用人话说:先从知识库里找到相关资料,再让AI基于这些资料回答问题。
1.2 一个形象的比喻

传统大模型 = 闭卷考试
├─ 只能靠脑子里记住的内容
├─ 记不住的就没法答
└─ 记不清的可能会瞎编
RAG系统 = 开卷考试
├─ 可以先翻书找资料
├─ 找到相关内容再答题
└─ 答案有据可查
1.3 RAG能解决什么问题?
| 痛点 | 传统大模型 | RAG方案 |
|---|---|---|
| 知识过时 | 训练数据有截止日期 | 实时检索最新资料 |
| 会"胡说" | 可能产生幻觉 | 答案有据可查 |
| 不懂内部信息 | 无法访问私有数据 | 企业知识库随时更新 |
| 不够专业 | 通用知识为主 | 专业知识精准检索 |
1.4 RAG能做什么?
场景1:智能客服
用户:我的订单怎么还没到?
RAG:让我查一下...您的订单12345目前在上海转运中心,
预计明天上午送达。
场景2:企业知识库
员工:公司的差旅报销流程是什么?
RAG:根据《员工手册》第5章,差旅报销需要:
1. 提前在OA系统申请
2. 保存好发票原件
3. 回来后7天内提交...
场景3:法律助手
律师:类似案件法院一般怎么判?
RAG:我检索到3个相似案例:
- (2023)京01民终1234号:判决支持原告
- (2022)沪02民终5678号:部分支持
根据这些案例,法院通常会考虑...
二、RAG是怎么工作的?
2.1 三步核心流程
RAG的工作原理可以概括为三个步骤:检索 → 增强 → 生成
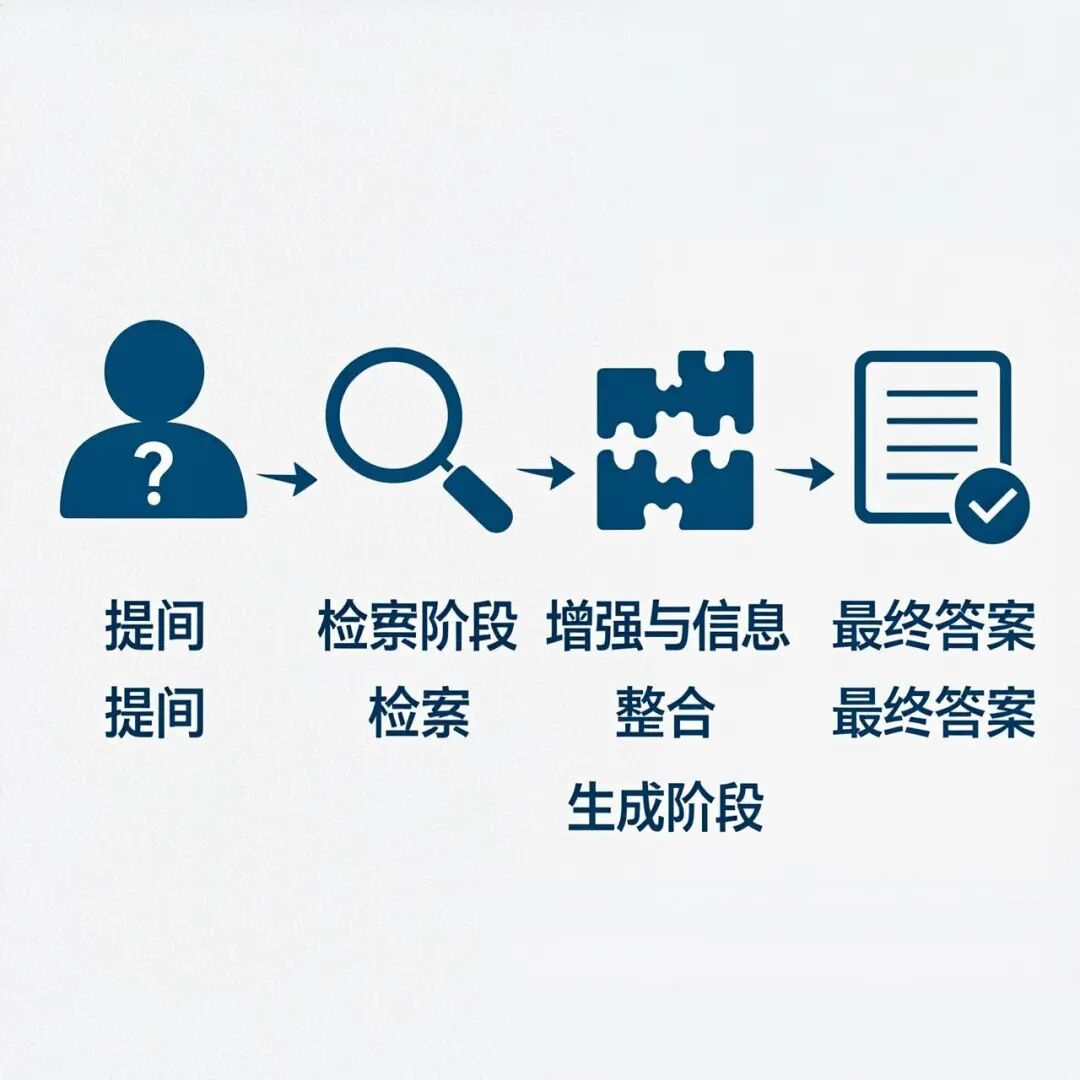
| 步骤 | 输入 | 处理过程 | 输出 |
|---|---|---|---|
| 第一步:检索 | 用户问题:“怎么退款?” | 转换成向量 [0.23, 0.87, …] → 在知识库中搜索 | Top 5相关片段 |
| 第二步:增强 | 检索结果 + 用户问题 | 把资料和问题组装成Prompt | “参考资料:[退款需7天内…] 问题:怎么退款?” |
| 第三步:生成 | 增强后的Prompt | 大模型基于上下文生成回答 | “退款流程:1. 7天内申请 2. 3-5工作日返回…” |
2.2 几个关键概念
① 向量化(Embedding)
把文字变成一串数字(向量),让计算机能"理解"文字的含义。
"退款" → [0.82, 0.15, 0.93, ...]
"退货" → [0.78, 0.18, 0.89, ...] ← 和"退款"很接近
"吃饭" → [0.12, 0.95, 0.33, ...] ← 和"退款"差很远
② 向量数据库
专门存储和搜索向量的数据库,能快速找到"最相似"的内容。
常见的有:Milvus、Pinecone、Chroma
③ 分块(Chunking)
把长文档切成小块,方便检索。
一份100页的PDF → 切成200个小块(每块500字)
用户提问时 → 只检索最相关的5-10块
三、RAG技术的演进:从"大海捞针"到"顺藤摸瓜"
RAG技术这几年发展非常快,已经经历了五代演进。
3.1 第一代:朴素RAG(2020-2022)
特点:最简单的"检索+生成"
用户问题 → 向量检索 → 取Top 5 → 扔给LLM → 生成答案
优点:实现简单,上手快
缺点:
- • 检索质量差,经常找不准
- • 无法处理复杂问题
- • 没有"思考"能力
3.2 第二代:进阶RAG(2022-2023)
改进:加入查询改写和重排序
用户问题 → 改写问题 → 向量检索 → 重排序 → 取Top 5 → 生成
↑ ↑
"怎么退"→"退款流程" 精筛最相关的
关键技术:
- • HyDE:让AI先"猜"一个答案,用这个猜测去检索
- • Rerank:用更精确的模型对检索结果重新排序
效果:准确率提升15-30%(据行业实践数据)
3.3 第三代:模块化RAG(2023-2024)
特点:把RAG拆成多个可插拔的模块,像搭积木一样组合
┌─ 知识库A
用户问题 → 路由判断 ─┼─ 知识库B → 检索 → 融合 → 生成
└─ 网络搜索
优势:
- • 可以根据问题类型选择不同检索源
- • 支持多路召回、结果融合
- • 更灵活、可扩展
3.4 第四代:GraphRAG(2024-2025)
这是当前最火的方向!

核心创新:用知识图谱替代单纯的向量检索
标准RAG的三大盲区:
| 问题类型 | 例子 | 为什么标准RAG失败 |
|---|---|---|
| 多跳推理 | “GPT-4的底层技术是谁提出的?” | 需要多步推理:GPT-4→Transformer→Google |
| 全局总结 | “这些文档的主要主题是什么?” | 没有单一目标块可检索 |
| 关系发现 | “TensorFlow和PyTorch有什么联系?” | 两者在不同文档,无直接关联 |
GraphRAG解决方案:
知识图谱结构:
[深度学习] ──属于──→ [机器学习]
│
使用
│
[神经网络] ──实现──→ [TensorFlow] [PyTorch]
当用户问"TensorFlow和PyTorch有什么联系?"
- • 标准RAG:找不到(没有文档同时讨论两者)
- • GraphRAG:顺着图谱"顺藤摸瓜",发现它们都是深度学习框架
3.5 第五代:Agentic RAG(2025-2026)
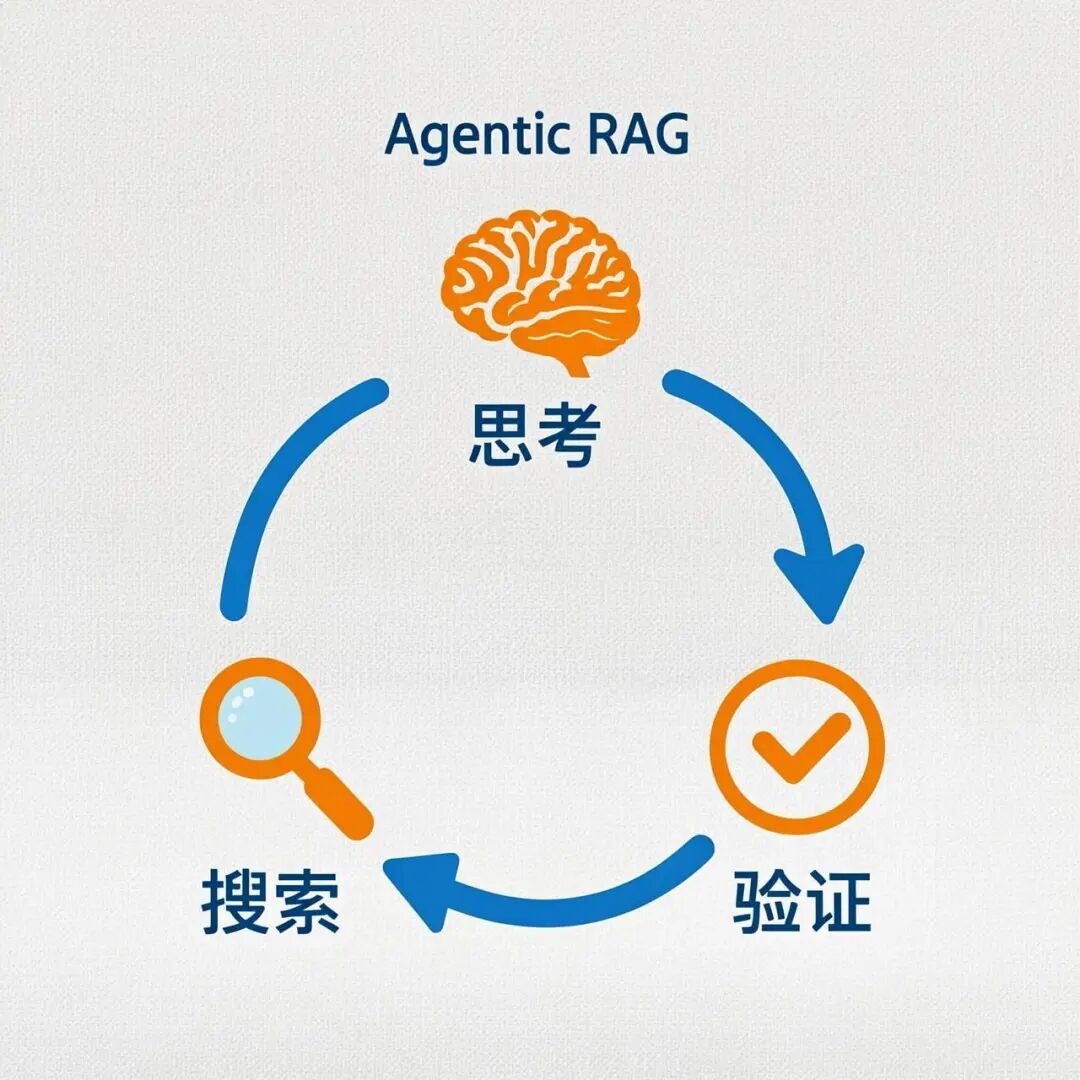
特点:让AI像人一样"思考-行动-验证"
传统RAG:检索 → 生成(一次性)
Agentic RAG:
思考 → 检索 → 验证 → 不满意?
↑______________|
再检索
实际例子:
用户:帮我分析一下这家公司的财务风险
Agent思考:
1. 先检索财务数据...
2. 数据不够完整,再检索行业对比...
3. 需要法律风险信息,调用法律数据库...
4. 整合分析,生成报告...
5. 发现矛盾,重新验证...
6. 输出最终结论
这就像一个真正的分析师在工作,而不是简单的问答。
四、RAG技术栈全景图
4.1 技术栈分层
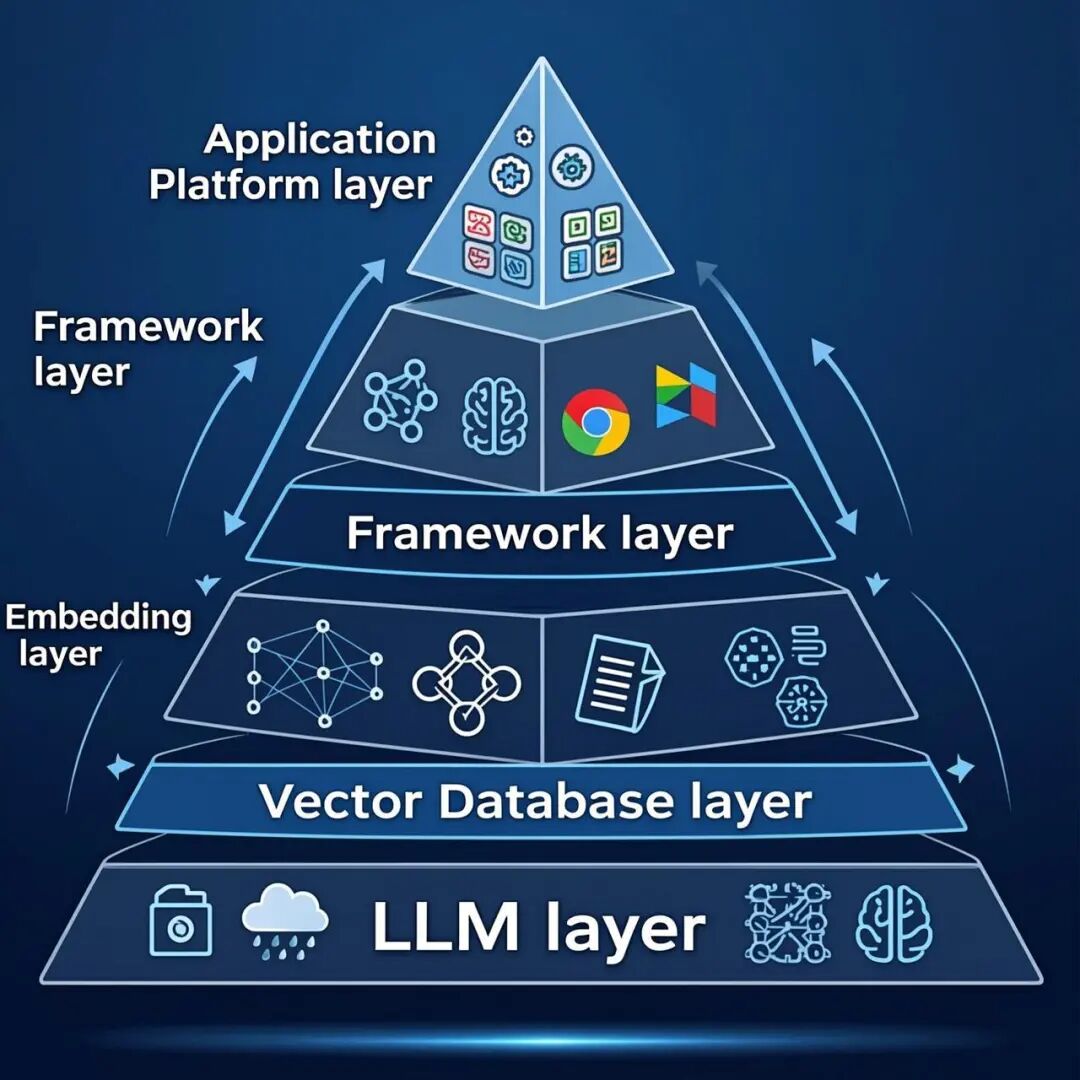
| 层级 | 类型 | 代表产品 |
|---|---|---|
| 应用层 | 开箱即用的平台 | Dify、RAGFlow、FastGPT、MaxKB、Coze、百炼、千帆 |
| 编排层 | 开发框架 | LangChain、LlamaIndex、Haystack、LangGraph |
| 检索层 | Embedding + Rerank | OpenAI、BGE、M3E、Cohere |
| 存储层 | 向量数据库 | Milvus、Pinecone、Qdrant、Weaviate、Chroma |
| 基础层 | 大模型 | GPT-4、Claude、Gemini、DeepSeek、Qwen |
4.2 如何选择?
30秒快速选型:
Q: 你是什么角色?
【个人/小团队】
└─ 想快速体验 → Coze、Kimi(免费、零门槛)
【企业IT部门】
├─ 数据可上云 → 百炼、千帆(大厂托管)
└─ 必须私有化 → Dify、FastGPT(开源自建)
【开发者】
├─ 快速开发 → Dify、LangFlow
└─ 深度定制 → LangChain、LlamaIndex
【技术决策者】
├─ 重视文档解析 → RAGFlow(OCR、表格强)
├─ 重视企业级 → Dify、百炼
└─ 重视成本 → DeepSeek + 开源方案
五、RAG的未来:从"检索"到"思考"
5.1 2025-2026趋势
趋势1:Agentic RAG成为主流
AI不再是简单的"问答机器",而是能自主规划、主动检索、自我验证的智能体。
趋势2:GraphRAG规模化落地
知识图谱与LLM深度融合,让AI具备复杂推理能力。
趋势3:多模态RAG
不只是文字,还能处理图片、视频、音频。
趋势4:实时RAG
从"秒级响应"到毫秒级响应,支持实时数据流。
5.2 一句话总结
RAG正在从"检索-生成"简单管道,进化为具备"思考-验证"能力的智能系统。
这是一场从"Search"到"Think"的革命。
六、小结
6.1 核心要点回顾
- RAG是什么:让AI学会"翻书"再答题
- 三步流程:检索 → 增强 → 生成
- 五代演进:朴素 → 进阶 → 模块化 → GraphRAG → Agentic
- 技术栈:从平台到框架到数据库,生态完善
- 未来趋势:更智能、更快、更多模态
6.2 给不同角色的建议
| 角色 | 建议 |
|---|---|
| 产品经理 | 先明确场景边界,从POC开始验证 |
| 技术决策者 | 重视评估体系,考虑长期运维成本 |
| 开发者 | 先用成熟平台,再考虑自研 |
| 普通用户 | 体验Coze、Kimi,感受RAG能力 |
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献128条内容
已为社区贡献128条内容

所有评论(0)