我尝试了在OpenClaw接入免费无限Token的模型,使用感觉怎样?
免费的东西,果然带着点“代价”……
前两天给大家分享了Atomgit免费送无限Token大模型的消息:免费的大模型算力免费领?接入OpenClaw和CoPaw,钱包终于有救了!(没看过的点这里复习)。
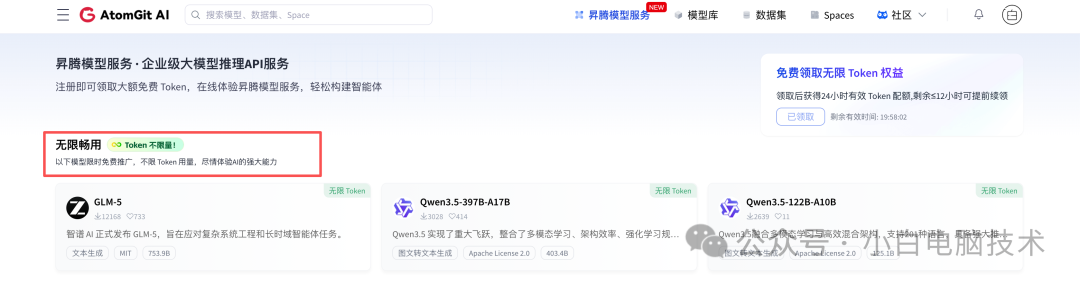
作为一个资深“白嫖党”,我第一时间就领了Key,迫不及待地接入了OpenClaw,想看看这只小龙虾吃上“免费粮”后表现如何。
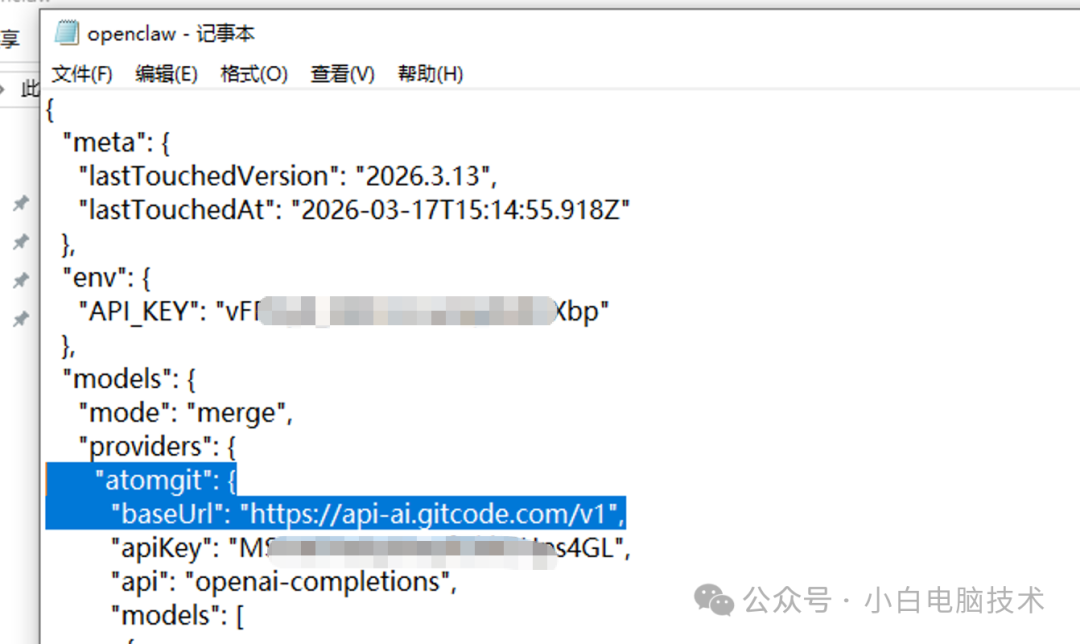
结果嘛……一言难尽。今天就来聊聊我的真实体验。
01 刚开始:感觉捡到宝了
领完Key后,我兴冲冲地选了最强的那款——Qwen/Qwen3.5-397B-A17B!看到那397B参数,这个OpenClaw一定是智商拉满,重点还是免费!
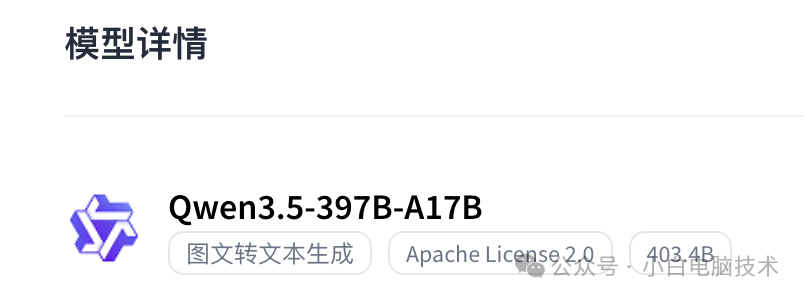
接入很简单,改一下OpenClaw的配置文件里的接口地址和Key,选好模型,重启,开聊。
接入模型的教程:如何给OpenClaw配置模型提供商API和大模型?
一开始,我丢了些简单的任务:“帮我整理这段文字”、“写个Python脚本爬取某个网站”、“总结这篇长文的要点”……模型响应速度还可以,虽然比不上OpenAI那么丝滑,但免费嘛,要什么自行车?
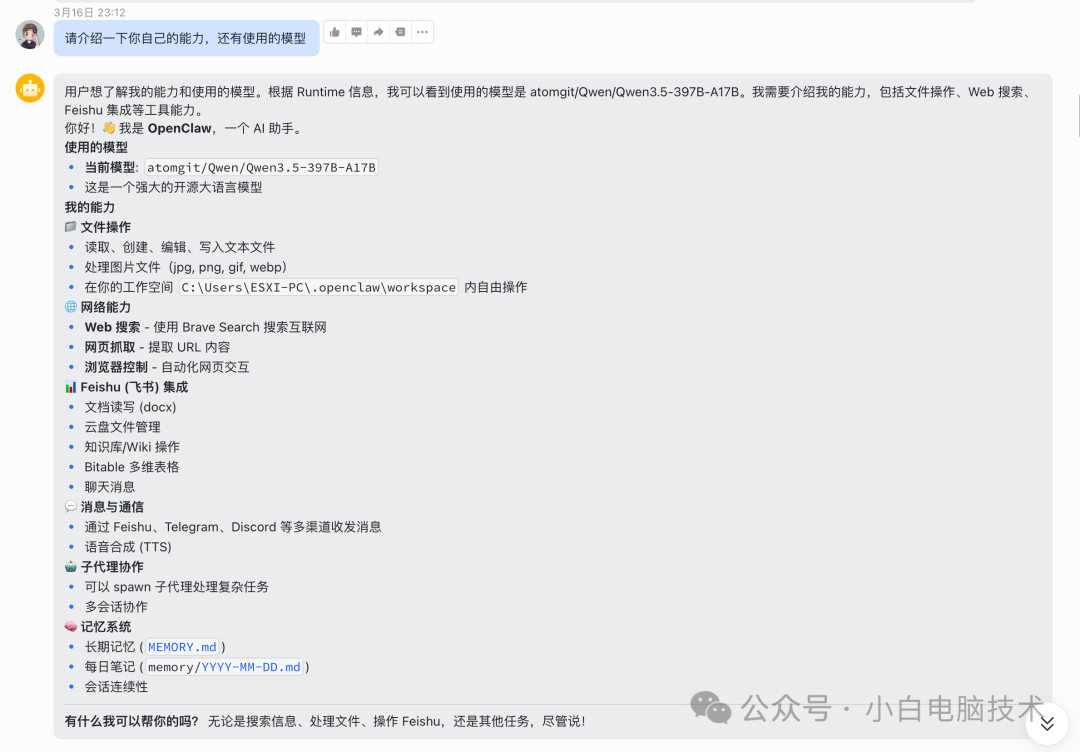
我当时心想:这下可以放开手脚玩了,不用再盯着Token消耗心疼了。
然后……速度开始变慢了
用了大概半天后,我发现事情不对劲。
后来在群里一问,发现很多人都在用Atomgit的免费模型。用的人太多了,服务器扛不住了——这大概就是因为免费,来的人太多了吧。
02 真正的暴击:Token超限错误
有一次我让小龙虾处理一个比较大的文档(大概两万多字),结果它直接罢工,抛出一段错误:
三方请求失败: 400 {"error":{"message":"You passed 23809 input tokens and requested 8192 output tokens. However, the model's context length is only 32000 tokens, resulting in a maximum input length of 23808 tokens. Please reduce the length of the input prompt. (parameter=input_tokens, value=23809)","type":"BadRequestError","param":"input_tokens","code":400}}
翻译一下:我输入的文本有23809个token,想让它输出8192个token,但模型上下文窗口只有32000 token,所以输入最多只能23808 token。我超了1个token,它就拒绝了。
超了1个token都不行! 这精度也是没谁了。
我当时想:可能是这个模型(Qwen3.5-397B)限制太死,换个模型试试?
于是切换到zai-org/GLM-5,继续尝试。
03 GLM-5:稍好一点,但依然“傲娇”
换了GLM-5后,刚开始确实顺畅了一点,速度也稍微快了些。我以为问题解决了,于是又丢了一个稍大的任务过去。
结果……又来了。
三方请求失败: 400 {"error":{"message":"You passed 27905 input tokens and requested 4096 output tokens. However, the model's context length is only 32000 tokens, resulting in a maximum input length of 27904 tokens. Please reduce the length of the input prompt. (parameter=input_tokens, value=27905)","type":"BadRequestError","param":"input_tokens","code":400}}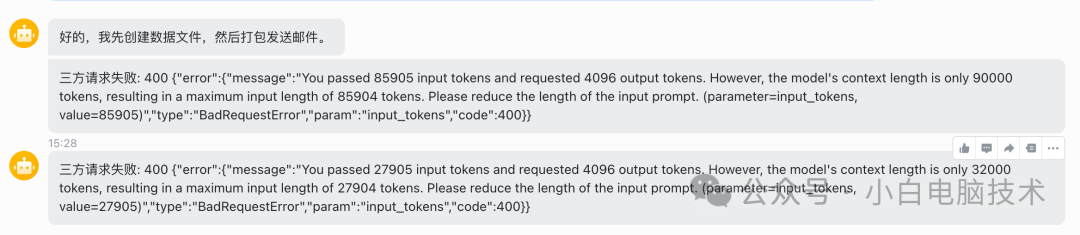
这次是27905个输入token,上限是27904,又是超了1个。
我真的无语了:这些模型是把上限卡得死死的,多一个token都不干。
但有意思的是,有时候同样的任务,隔一会儿重发,它又能执行了。可能是服务器负载波动?或者我的输入在预处理时偶尔被压缩了一点?总之,断断续续能用,但完全看运气。
04 三个小时,只做成一个任务
为了测试到底能跑多少活,我专门抽了三个小时,尝试让OpenClaw帮我做一些稍微复杂的事情——比如从一个网页里提取结构化数据、生成报告、调用其他API等。

第一个任务:做到一半报错,重试三次后成功。
第二个任务:直接卡死,重试了五次才勉强跑完一半。
三小时下来,只完整完成了一个任务。
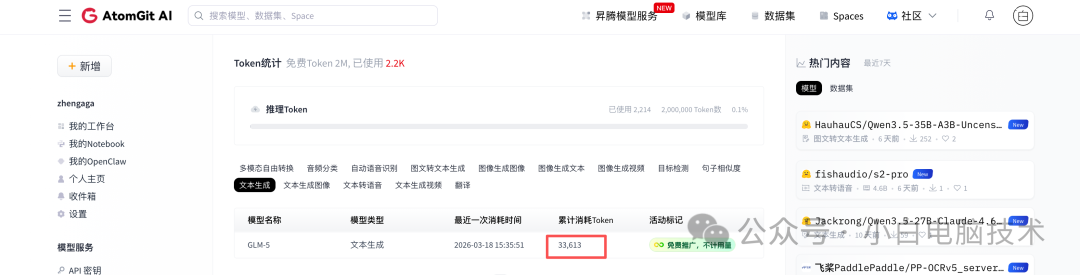
我去后台看了下Token消耗:大约30000 tokens。虽然确实是免费的,但这个完成效率……
05 为什么会这样?我猜的几个原因
免费资源一旦被疯抢,服务质量必然下降。速度慢、超时、甚至拒绝服务,都是“幸福的烦恼”。
另外就是模型上下文窗口有限,且限制极严格。Qwen3.5-397B和GLM-5都是32000 token的上下文,但实际可用的输入窗口比标称小一点(可能是要预留输出空间)。
如果咱们执行的任务复杂度高,就很容易触及限制。如果是简单的问答,可能问题不大。
虽然说是“无限Token”,但可能会对单个用户的请求频率或并发有限制,导致任务容易被中断。

总结:能用,但别指望它干重活。
如果你只是偶尔用OpenClaw跑跑轻量任务——比如翻译几句话、写个小脚本、回答简单问题——那Atomgit的免费模型完全够用,而且真免费,真香。
但如果你想让它帮你处理长文档、跑复杂的工作流、或者做多轮对话的任务,那就要做好频繁报错、速度慢、看运气的准备了。

--End--
最后使用的感觉:尽量用GLM-5,感觉比Qwen3.5-397B稳定一点。(可能是选择使用Qwen3.5-397B的人多一些?)
如果一定要执行大任务,建议把一个大任务拆分成几个甚至是十几个小任务进行。然后就是避开高峰期,晚上或凌晨用可能更快。
毕竟免费,耐心等待或多次重试不可避免。Atomgit这次的活动对个人开发者和小白玩家已经很良心了,毕竟真金白银的算力免费送。
推荐阅读

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)