迈向原生全模态AGI:通义千问Qwen3.5-Omni震撼发布,全方位解锁视听交互新体验
阿里巴巴Qwen团队正式发布了其最新一代原生全模态大语言模型 Qwen3.5-Omni。这款模型不仅在文本处理上持续进化,更在图像、音频及视听内容的理解与生成上实现了质的飞跃,标志着通用人工智能(AGI)向全模态感知的又一重要里程碑。
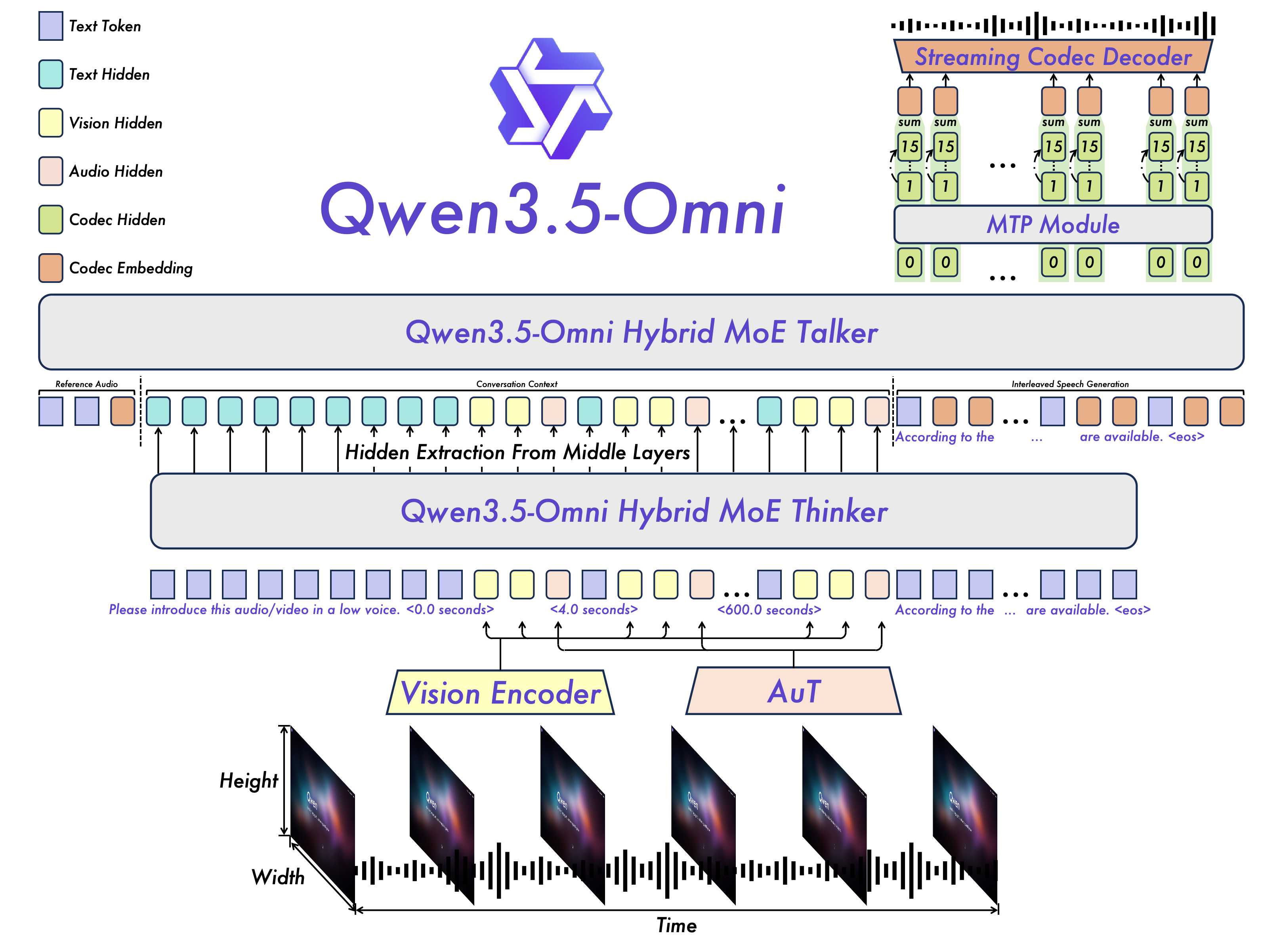
全能战士:Qwen3.5-Omni 核心概览
Qwen3.5-Omni 系列涵盖了 Plus、Flash 和 Light 三种尺寸,能够满足从高性能复杂推理到低延迟实时交互的多样化需求。该模型基于 Hybrid-Attention MoE(混合注意力专家模型) 架构,支持高达 256k 的长上下文输入。
其最令人惊叹的特性在于其深厚的“耐力”:它能一次性处理超过 10 小时的音频输入,以及超过 400 秒的 720P 高清视听数据(采样率为 1 FPS)。
深度解析:Qwen3.5-Omni 的优势所在
1. 真正的“听觉”与“视觉”专家
Qwen3.5-Omni 在多项指标上达到了行业顶尖水平。Qwen3.5-Omni-Plus 在 215 项音频和视听理解任务中取得了 SOTA(最先进)结果。
- 音频全能: 在通用音频理解、推理、识别和翻译方面,它已经全面超越了 Gemini-3.1 Pro。
- 多语言天赋: 支持 113 种语言或方言的语音识别,以及 36 种语言的语音生成,极大地打破了跨语言沟通的障碍。
- 分镜级描述: 模型能够生成极其详尽、结构化的视频描述,甚至包括自动分段、时间戳标注以及对角色关系的深度解读。
2. 丝滑的实时交互体验
通过创新的 ARIA(自适应速率交错对齐)技术,Qwen3.5-Omni 解决了流式语音交互中常见的丢词、误读等稳定性问题。
- 情感控: 用户可以像与真人交谈一样,自由控制模型的说话音量、速度甚至是情感。
- 智能打断: 具备原生的轮流交谈意图识别,能够区分背景噪音和真正的语义中断,避免尴尬的误判。
- 声音克隆: 支持用户通过上传音频自定义 AI 助手的音色,打造个性化的数字伴侣。
3. 涌现的新能力:视听 Vibe Coding
在原生多模态缩放过程中,研究团队观察到了一种全新的能力:模型能够直接根据视听指令进行编程(Audio-Visual Vibe Coding),这为未来的自动化开发提供了无限想象空间。
客观审视:存在的局限与劣势
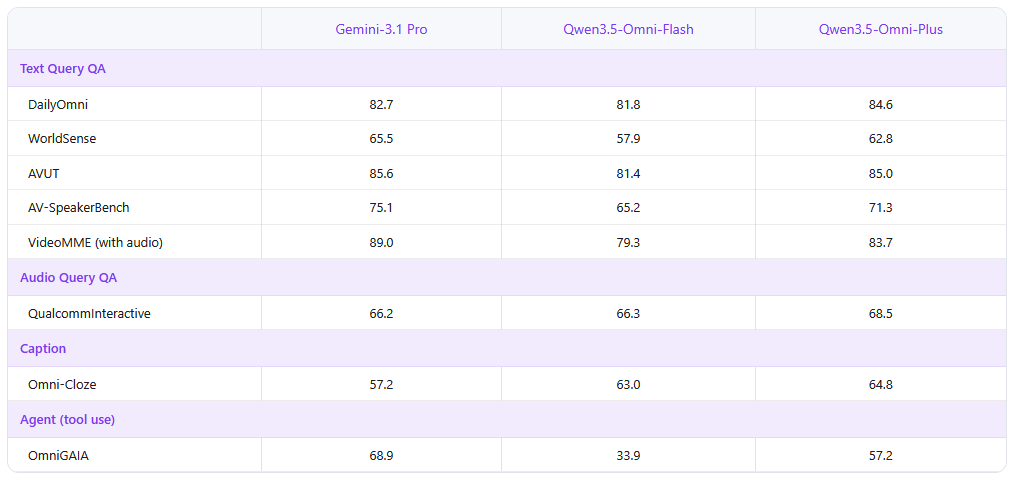
尽管表现卓越,但在与全球顶尖模型(如 Gemini-3.1 Pro)的正面交锋中,Qwen3.5-Omni 仍存在进步空间:
- 智能体(Agent)能力稍逊: 在 OmniGAIA 等工具调用与智能体测试中,Qwen3.5-Omni-Plus 的得分为 57.2,相较于 Gemini-3.1 Pro 的 68.9 仍有明显差距。
- 特定视听基准的细微落后: 尽管总体视听能力宣称达到 Gemini-3.1 Pro 水平,但在 WorldSense(世界感知)和 VideoMME(带音频视频理解)等具体测试项上,得分略低于对手。
- 视频采样频率: 目前支持的 1 FPS 采样率虽然能处理长视频,但在捕捉瞬时动态细节方面可能不如更高帧率的处理模式。
总结
Qwen3.5-Omni 的发布不仅仅是参数量的堆叠,更是对原生全模态交互逻辑的深刻重塑。通过 Thinker-Talker 架构的演进,它让 AI 拥有了更接近人类的感官协同能力。
虽然在复杂的智能体任务和部分高阶推理环节还面临国际巨头的强力竞争,但其在长音频处理、多方言支持以及实时语音稳定性上的突破,无疑为开发者和普通用户提供了一个极具竞争力的选择。随着离线 API 和实时 API 的开放,我们期待看到更多基于 Qwen3.5-Omni 的创新应用落地。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)