语音识别本地部署:企业级AI转写的破局之路与实战解析
在人工智能技术爆发的今天,语音识别(ASR)已经从消费级的“尝鲜玩具”演变为企业生产力工具的基础设施。从会议记录、客服质检到医疗问诊、法律取证,语音数据正在以前所未有的速度转化为核心商业资产。
然而,当企业真正准备将AI语音转写全面接入业务流时,一个尖锐的矛盾浮出水面:公有云API带来的便捷,正在与企业对数据绝对安全、成本可控的底线要求发生激烈碰撞。 对于B2B企业而言,仅仅解决“能不能转写”已经不够,“在安全可控的前提下高效转写”才是真正的刚需。这正是“语音识别本地部署”正在重塑行业格局的根本原因。
一、 云端语音识别的隐秘痛点
客观来看,公有云语音识别服务降低了早期接入的门槛,但在深度商业应用中,它的短板同样致命:
-
数据安全与隐私泄露的“达摩克利斯之剑”
企业的语音数据往往包含极其敏感的商业机密、客户隐私或内部战略决策。将这些音频文件上传至公有云进行处理,不可避免地存在数据截留、泄露或被用于训练第三方模型的风险。在金融、医疗、公检法等强监管行业,这种数据出境(出企业内网)的行为更是触碰了合规红线。
-
网络依赖与不稳定的处理时效
云端服务的核心瓶颈在于带宽。当企业需要处理海量、长时间的音频文件时,上传和下载的耗时往往超过了转写本身的时间。一旦遇到网络波动或断网环境,整个工作流就会彻底瘫痪,这对于追求极致效率的企业来说是不可接受的。
-
长期使用的“无底洞”成本
公有云通常采用按时长或调用次数计费的SaaS模式。在小规模测试时,这种成本看似低廉;但随着企业业务扩张,每天需要处理的音频量达到数百小时甚至更多时,SaaS订阅费将呈指数级上升,最终成为一笔极其沉重的持续性运营开销。

二、 本地部署:将核心数据与算力牢牢握在手中
面对上述痛点,语音识别技术的本地化部署(On-Premises Deployment)成为了必然的破局之路。它并非简单的技术倒退,而是在算力下沉趋势下,企业重塑数字主权的战略选择。
1. 物理隔离,实现100%数据安全
本地部署意味着整个语音识别引擎、语言模型以及处理过程全部在企业内部的局域网或私有服务器上完成。音频数据“可用不可见”,彻底斩断了数据外泄的物理路径,完美契合企业级B2B场景的严苛保密需求。
2. 消除网络瓶颈,释放极致效率
离线环境下的本地转写,完全摆脱了对外部带宽的依赖。企业可以通过内网实现千兆级别的数据传输,让批量音频的处理如同处理本地文档一样迅速。这种零延迟的数据流转,极大地提升了生产效率。
3. 成本的“边际递减”效应
与SaaS模式无止境的计费不同,本地部署往往是一次性买断软件授权,配合企业现有的硬件资源或一次性硬件投入。随着使用频率的增加和转写时长的累积,单小时的音频处理成本将无限趋近于零,具有极高的长期投资回报率(ROI)。
三、 实战解析:以“灵声智库”为例的本地化重构
理论的优势需要产品的落地来支撑。观察目前市场上的优秀企业级离线语音解决方案,我们可以从 灵声智库 这一产品中看到本地部署技术栈的成熟应用与创新。
“灵声智库”没有走消费级SaaS的老路,而是精准定位B2B市场,将核心能力深度整合在离线私有化环境中,其产品逻辑完全契合了现代企业对“安全+效率+智能”的三角需求:
-
基于先进开源架构的底层重构
该系统底层融合了如阿里FunASR等顶尖开源模型的能力,并进行了深度的本地化工程优化。这意味着企业在无需联网的前提下,就能在本地服务器上获得不输于一线公有云的极高语音识别准确率。
-
企业级的并发与离线批量处理
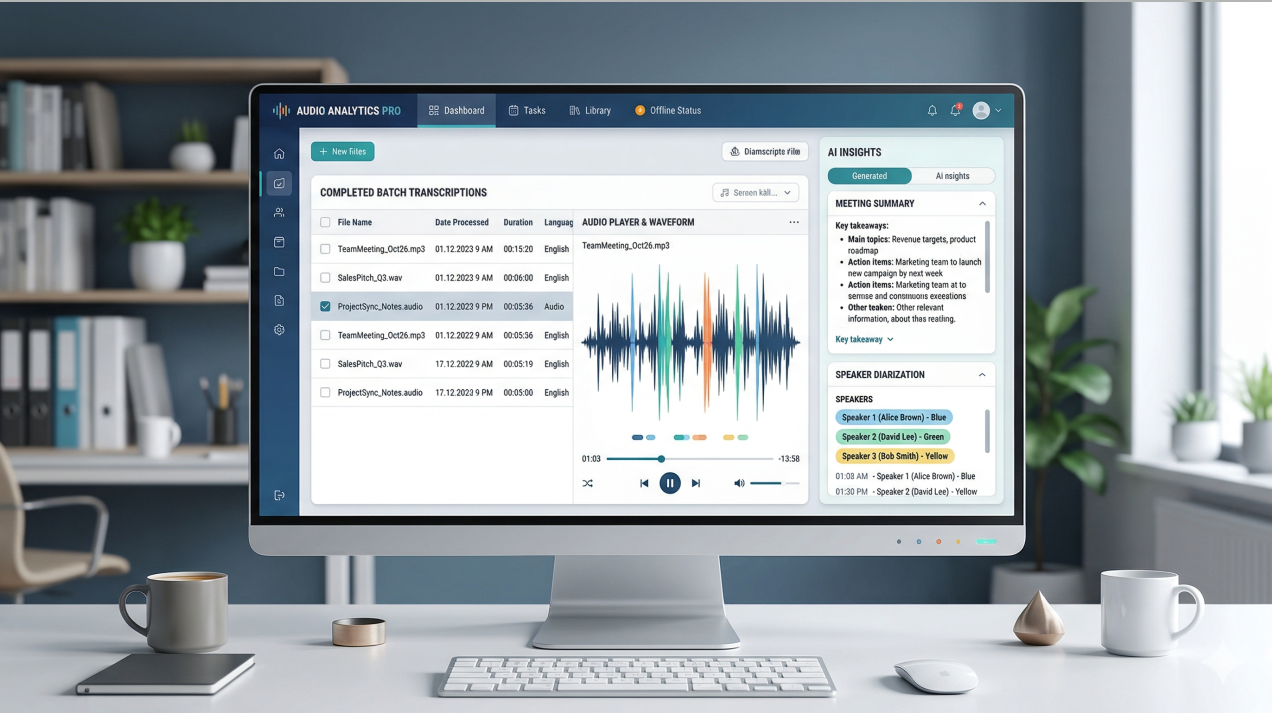
针对企业日常产生的大量会议录音、采访音频,“灵声智库”提供了一键式的离线批量转写功能。它能够充分压榨本地硬件算力,实现多个长音频文件的并发处理,彻底告别了云端上传时的漫长等待。
-
说话人分离(Speaker Diarization)的精准落地
在真实业务场景中,知道“谁说了什么”往往比仅仅知道“说了什么”更重要。系统内置的说话人分离技术,能够在复杂的本地多场景下,精准切分和识别不同的发言者,为后续的整理工作省去大量人工干预的时间。
-
与大语言模型(LLM)的深度联动
语音转文字只是第一步,“灵声智库”展示了更高维度的产品思考:将转写后的结构化文本,无缝对接大语言模型。在本地或安全可控的环境下,系统可以一键生成会议纪要、提取核心摘要、分析对话重点。这种“ASR + LLM”的组合拳,真正完成了从“数据”到“信息”,再到“业务决策”的闭环。
-
四、 拥抱本地部署:企业的行动指南
当然,本地部署也对企业的IT基础设施提出了一定要求。客观而言,要想获得极速的转写体验,配备适度的GPU算力(如NVIDIA系列显卡)是必要的。但随着硬件成本的逐年下降和软件端推理框架(如ONNX、TensorRT)的极致优化,如今部署一套企业级语音AI系统的门槛已大幅降低。
对于以下类型企业,尽早布局本地语音识别系统不仅是提升效率的手段,更是建立行业壁垒的战略决策:
-
公检法与律所:对证据链的保密性有绝对要求的机构。
-
媒体与出版机构:每天产生海量无剪辑采访素材,对批量处理时效极度敏感的团队。
-
金融与医疗企业:受限于严格的数据合规审查(如客户身份信息、病历隐私),严禁数据上云的单位。
-
大型集团企业:内部会议频繁,希望建立自有数字资产库及内部知识管理系统的组织。
在AI大模型狂飙突进的时代,我们必须保持冷静的商业判断。对于B2B企业而言,盲目追求云端的前沿API并非万能药,数据的安全性、系统的稳定性和长期的成本控制才是企业生存发展的基本盘。
语音识别技术的本地部署,正是将前沿AI技术“平民化”、“私有化”的关键一步。像“灵声智库”这样专注于离线、批量、智能化的解决方案,正在为企业搭建起一座安全的数据护城河。掌握自有数据,驾驭本地算力,企业才能在未来的智能化浪潮中,握紧真正属于自己的数字利刃。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)