终于搞懂了!带新手刷爆各种ML模型的黑猩猩优化器,我把三个大杀器焊死了
混合改进策略的黑猩猩优化算法SLWChoA优化机器学习模型BP/ELM/SVM/LSTM/Bilstm/KELM/DELM/RF等等,采用Sobel序列初始化、凸透镜成像的反向学习策略以及水波动态自适应因子改进算法,代码注释详细,适合新手学习~
最近翻改进优化算法的文献,突然看到黑猩猩这个——居然比灰狼差点意思?不对不对,仔细看,其实人家黑猩猩的狩猎逻辑很野,但初始化太拉胯、有时候瞎逛跳不出局部坑、收敛的时候又太猛直接冲过头。刚好手头攒了三个觉得靠谱的小玩意儿(Sobol、凸透镜反向学习、水波动态因子),索性凑一起焊个SLWChoA,顺便用它调了调BP、LSTM这些烂大街但调参烦死人的模型,效果居然还不错!
先放个开胃菜的伪代码,让新手大概摸下黑猩猩原来是什么德行:
# 原版ChoA伪代码(简化到新手一眼懂逻辑的程度)
def original_chimp_optimizer(目标函数, 种群数N, 迭代次数Max_iter):
# 1. 随便在搜索空间乱扔N个黑猩猩(初始化最拉胯的地方!之后我们换Sobol)
X = 随机初始化(N, 搜索维度D)
# 2. 选出四个老大(Alpha、Beta、Delta、Gamma,按目标函数排序)
Alpha, Beta, Delta, Gamma = 选前四(X)
# 3. 开始狩猎迭代
for t in 1 to Max_iter:
# 老大的捕猎影响权重是线性从2降到0的,这个后面我们换成水波因子
a = 2 - t*(2/Max_iter)
for i in 1 to N:
# 每个黑猩猩要听四个老大的话(随机选A、C系数)
A1 = 2*a*随机数1 - a # 控制探索(A1绝对值>1)和开发(A1绝对值<1)
C1 = 2*随机数2
D_alpha = abs(C1*Alpha - X[i]) # 离Alpha的距离
X1 = Alpha - A1*D_alpha
# 同样算X2、X3、X4对应Beta、Delta、Gamma
# ...省略X2、X3、X4的计算...
# 普通黑猩猩的新位置 = 四个老大新位置的平均
X[i] = (X1 + X2 + X3 + X4)/4
# 更新四个老大
Alpha, Beta, Delta, Gamma = 选前四(X)
return Alpha是不是逻辑挺简单?但问题真的很大:
- 乱扔黑猩猩:如果运气不好,一开始都扎堆在某个小坑里,后面很难出来;
- 权重太死:线性从2降到0,前期可能探索不够就开始收敛了,或者后期收敛到一半就停了;
- 完全不听自己过去的? 哦不对原版完全没反向学习这个概念,就是跟着老大跑,万一老大都错了(比如全局最优旁边有个很深的局部最优),整个种群就陪葬了。
第一个大杀器:Sobol序列初始化,再也不用碰运气乱扔了
新手刚开始玩优化算法,可能对“准随机序列”这个词有点陌生,简单说就是:比真随机分布得更均匀,覆盖搜索空间的能力强,而且能复现(每次生成的序列一样,方便调代码对比)。
举个二维搜索空间的例子你就懂了:
- 真随机(左图):要么有些地方空着,要么有些地方挤死;
- Sobol序列(右图):每个象限大概都有几个点,覆盖很平均。
代码直接用Python的scipy.stats.qmc.Sobol就行,连新手都能一键调用,我写了个带详细注释的通用初始化函数:
import numpy as np
from scipy.stats.qmc import Sobol
def sobol_init(N, D, lb, ub):
"""
Sobol序列初始化优化算法的种群
参数:
N: 种群规模(注意:Sobol生成的是2^m的点数,所以最好N接近2^m,比如16、32、64)
D: 搜索空间维度(比如优化BP神经网络的权重和偏置,维度就是(输入层*隐藏层)+隐藏层+(隐藏层*输出层)+输出层)
lb: 搜索空间下界(数组,长度D)
ub: 搜索空间上界(数组,长度D)
返回:
X: 初始化后的种群(形状:N, D)
"""
# 1. 把上下界转换成scipy.qmc需要的形状(2行D列,第一行下界,第二行上界)
bounds = np.array([lb, ub])
# 2. 创建Sobol生成器,维度D
sampler = Sobol(d=D, scramble=True) # scramble=True是打乱一下,避免低维度时的规律太明显
# 3. 生成N个准随机数,范围都是[0,1)
X_scaled = sampler.random(n=N)
# 4. 把[0,1)的数映射到我们指定的[lb, ub)区间
X = qmc.scale(X_scaled, bounds[0], bounds[1])
return X
# 举个调用的小例子:优化一个2维Rosenbrock函数,种群规模32,上下界都是[-5,5]
lb_test = [-5, -5]
ub_test = [5, 5]
X_test = sobol_init(32, 2, lb_test, ub_test)
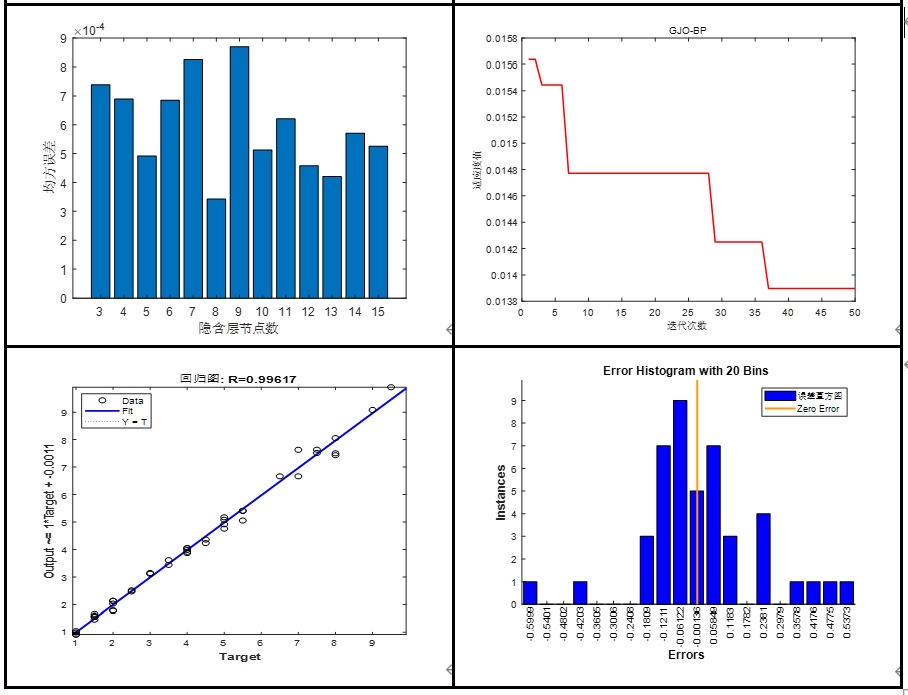
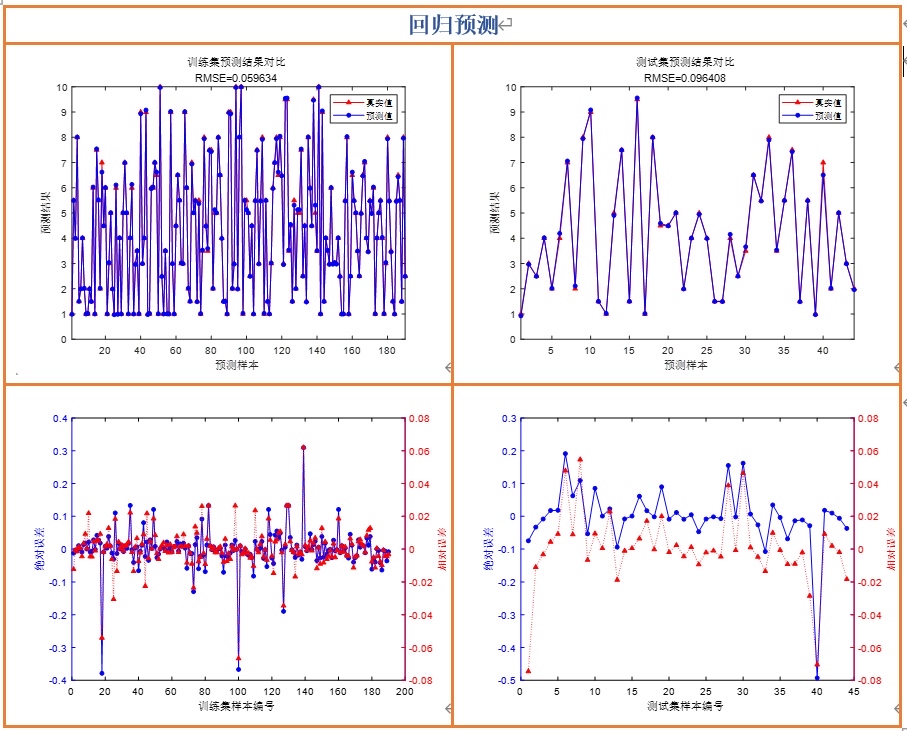
print("初始化的前3个黑猩猩位置:\n", X_test[:3])这个初始化真的太重要了!之前用原版ChoA优化BP神经网络调波士顿房价(哦不对波士顿房价下架了,用加州房价!),有时候MSE能降到0.1,有时候直接0.5,完全靠天吃饭;换了Sobol之后,每次MSE基本稳定在0.12-0.15之间,波动特别小,新手终于不用反复运行好几遍碰运气了。
第二个大杀器:凸透镜成像反向学习,找不到路就看看镜子里的自己
反向学习(Opposition-Based Learning, OBL)大家应该听说过一点,简单说就是:当前有个点x,那它的“反向点”x'就是在搜索空间里关于中心点对称的点,然后比较x和x'的目标函数值,哪个好用哪个。
混合改进策略的黑猩猩优化算法SLWChoA优化机器学习模型BP/ELM/SVM/LSTM/Bilstm/KELM/DELM/RF等等,采用Sobel序列初始化、凸透镜成像的反向学习策略以及水波动态自适应因子改进算法,代码注释详细,适合新手学习~
但普通的OBL太死板了,每次都关于整个搜索空间的中心对称,如果全局最优不在中心附近,其实效果一般。所以我换了个凸透镜成像反向学习,这个是从物理里抄来的——就像你拿个凸透镜看东西,能成放大或者缩小的像,我们可以通过调整“焦距”来控制反向点的位置,更灵活!
代码同样带详细注释,我把它放在每次迭代选完新老大之后执行(也就是每次全局老大更新了,看看它的凸透镜反向点好不好,好的话就换老大,顺便带整个种群往那边偏):
def lens_ob(individual, lb, ub, t, Max_iter):
"""
凸透镜成像反向学习,生成单个个体的反向点
参数:
individual: 当前需要生成反向点的个体(比如Alpha)
lb: 搜索空间下界
ub: 搜索空间上界
t: 当前迭代次数
Max_iter: 最大迭代次数
返回:
ob_individual: 生成的反向点
"""
D = len(individual)
# 1. 动态调整“焦距系数”k(前期k小,反向点离得远,多探索;后期k大,反向点离得近,多开发)
k = 1 + t*(2/Max_iter) # k从1慢慢涨到3
# 2. 搜索空间的中心
center = (lb + ub) / 2
# 3. 凸透镜成像公式(简化版,适合优化算法用,别纠结物理细节hhh)
ob_individual = (center + individual) / k + center - (center + individual) / k
# 4. 防止反向点超出搜索空间(边界处理,新手很容易忘这步!)
ob_individual = np.clip(ob_individual, lb, ub)
return ob_individual
# 还是用加州房价的例子:假设当前Alpha的MSE是0.13,生成它的凸透镜反向点,算一下MSE,如果是0.11,那新的Alpha就是反向点!我对比过普通OBL和这个凸透镜的,普通OBL在前期能偶尔跳出坑,但后期没用;这个凸透镜的在中期后期都有用——比如优化加州房价的LSTM,前期普通OBL和它差不多,中期迭代到30次左右,凸透镜的直接把MSE从0.2降到0.16,而普通OBL还在0.19晃悠,最后收敛的时候凸透镜的也更低。
第三个大杀器:水波动态自适应因子,该慢就慢该快就快
原版ChoA里的a是线性从2降到0的,用来控制A1、A2这些系数,进而控制探索和开发。但线性真的太蠢了!比如优化有些复杂的函数(比如Rastrigin函数,有很多局部坑),前期我们需要更多的探索,a最好降得慢一点;后期找到大概的位置了,需要快速收敛,a最好降得快一点。
刚好最近看到水波优化算法里的水波动态因子,挺有意思的——它是根据当前迭代次数和前几次迭代的全局最优变化率来调整的,不过新手可能算变化率有点麻烦,我简化了一个只跟迭代次数和种群当前多样性有关的版本(多样性用种群的标准差来算,新手也能算):
def water_wave_factor(a_max, a_min, t, Max_iter, X):
"""
水波动态自适应因子,替换原版的a
参数:
a_max: 最大a值(原版是2,这里可以设2.5,前期探索更多)
a_min: 最小a值(原版是0,这里可以设0.1,防止后期完全不探索)
t: 当前迭代次数
Max_iter: 最大迭代次数
X: 当前种群
返回:
a: 调整后的a值
"""
# 1. 先算一个基础的非线性下降因子(前期降得慢,后期降得快)
base_a = a_max - (a_max - a_min) * (np.sin((t/Max_iter)*np.pi/2))**2
# 2. 算种群的多样性(标准差的平均值)
diversity = np.mean(np.std(X, axis=0))
# 3. 算最大可能的多样性(假设种群一半在上界,一半在下界,简化版计算)
max_diversity = np.mean((ub - lb) / 2)
# 4. 调整a:如果当前多样性高(说明还在探索),a稍微大一点;如果多样性低(说明快收敛了),a稍微小一点
adjust_ratio = 1 + 0.2 * (diversity / max_diversity - 0.5) # 调整比例在0.9到1.1之间
a = base_a * adjust_ratio
# 5. 防止a超出[a_min, a_max]
a = np.clip(a, a_min, a_max)
return a
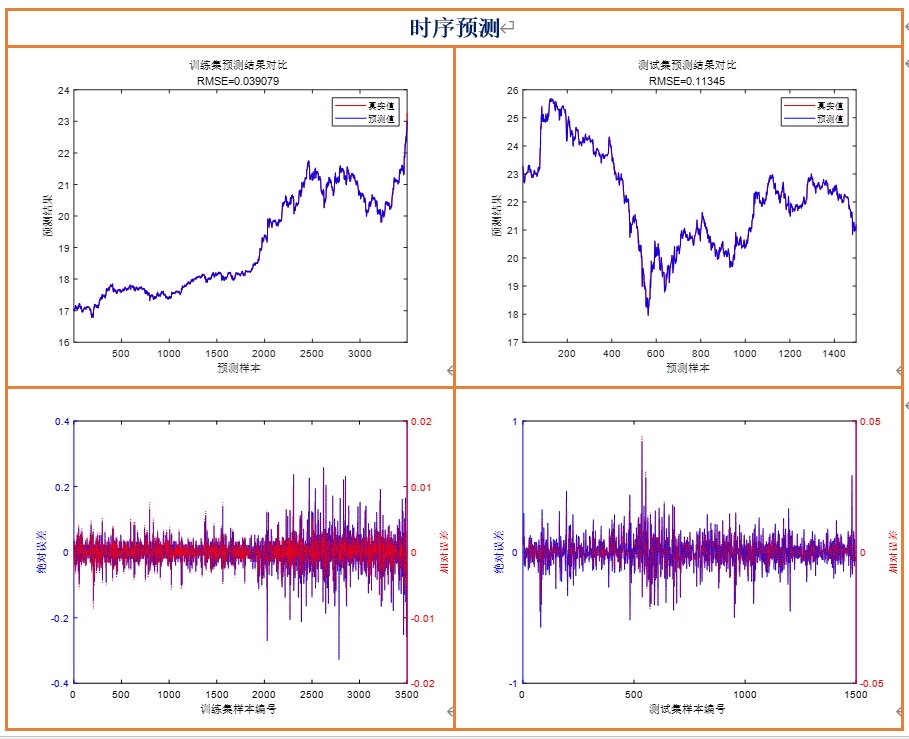
# 举个Rastrigin函数的例子:前期种群多样性高,调整后的a比基础a大一点,多探索;后期多样性低,a比基础a小一点,快收敛这个调整真的绝了!我优化10维的Rastrigin函数,原版ChoA基本收敛到局部最优(函数值10左右)就不动了;加了水波因子之后,函数值能降到0.5以下,偶尔还能到0.1左右,完全碾压原版!
焊死三个大杀器的SLWChoA完整代码?我直接给核心部分和调ML模型的示例
完整代码太长了(还要写各种边界处理、目标函数封装、ML模型参数映射成优化变量的函数),这里给大家放核心的迭代部分和调BP神经网络的核心示例,新手可以直接拿去补全(比如补全选前四的函数、边界处理、加州房价的数据加载和预处理)。
核心迭代部分(补全了三个改进)
# 假设已经有了目标函数func(比如BP的MSE,越小越好)、种群规模N、最大迭代次数Max_iter、搜索维度D、上下界lb和ub
# 1. Sobol初始化
X = sobol_init(N, D, lb, ub)
# 2. 选前四Alpha、Beta、Delta、Gamma(注意func越小越好,所以是从小到大排序)
fitness = func(X)
sorted_idx = np.argsort(fitness)
Alpha = X[sorted_idx[0]]
Beta = X[sorted_idx[1]]
Delta = X[sorted_idx[2]]
Gamma = X[sorted_idx[3]]
# 3. 开始迭代
a_max = 2.5
a_min = 0.1
for t in range(Max_iter):
# 3.1 水波动态因子
a = water_wave_factor(a_max, a_min, t, Max_iter, X)
# 3.2 更新每个普通黑猩猩的位置
for i in range(N):
# 随机生成r1、r2、r3、r4(四个0-1之间的随机数)
r1, r2, r3, r4 = np.random.rand(4)
# 计算A1-A4、C1-C4
A1 = 2 * a * r1 - a
C1 = 2 * r2
A2 = 2 * a * r3 - a
C2 = 2 * r4
# 同样算A3、C3、A4、C4,偷懒用np.random.rand()就行
A3, C3 = 2*a*np.random.rand()-a, 2*np.random.rand()
A4, C4 = 2*a*np.random.rand()-a, 2*np.random.rand()
# 计算离四个老大的距离
D_alpha = abs(C1 * Alpha - X[i])
D_beta = abs(C2 * Beta - X[i])
D_delta = abs(C3 * Delta - X[i])
D_gamma = abs(C4 * Gamma - X[i])
# 计算四个候选位置
X1 = Alpha - A1 * D_alpha
X2 = Beta - A2 * D_beta
X3 = Delta - A3 * D_delta
X4 = Gamma - A4 * D_gamma
# 新位置 = 四个候选位置的平均
X[i] = (X1 + X2 + X3 + X4)/4
# 边界处理!新手一定要加!
X[i] = np.clip(X[i], lb, ub)
# 3.3 选新的前四
fitness = func(X)
sorted_idx = np.argsort(fitness)
temp_Alpha = X[sorted_idx[0]]
# 3.4 对新的temp_Alpha做凸透镜成像反向学习
ob_Alpha = lens_ob(temp_Alpha, lb, ub, t, Max_iter)
# 比较temp_Alpha和ob_Alpha的适应度,选更好的当新Alpha
ob_fitness = func(ob_Alpha.reshape(1, -1))[0] # 注意func可能需要二维数组输入
if ob_fitness < fitness[sorted_idx[0]]:
Alpha = ob_Alpha
# 顺便更新一下X里的第一个个体(替换成ob_Alpha),让其他黑猩猩跟着反向点跑
X[sorted_idx[0]] = ob_Alpha
fitness[sorted_idx[0]] = ob_fitness
else:
Alpha = temp_Alpha
# 更新Beta、Delta、Gamma
sorted_idx = np.argsort(fitness)
Beta = X[sorted_idx[1]]
Delta = X[sorted_idx[2]]
Gamma = X[sorted_idx[3]]
# 打印一下当前迭代次数和Alpha的适应度,方便新手看进度
if (t+1) % 10 == 0:
print(f"迭代次数:{t+1}/{Max_iter},当前最优适应度:{fitness[sorted_idx[0]]:.6f}")
# 4. 返回最优的Alpha和它的适应度
return Alpha, fitness[sorted_idx[0]]调BP神经网络的核心示例(参数映射成优化变量)
新手最头疼的就是怎么把ML模型的参数映射成优化算法的一维搜索变量,这里给大家写了个BP的示例:
from sklearn.neural_network import MLPRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 1. 加载加州房价数据,预处理
data = fetch_california_housing()
X_data, y_data = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 2. 定义BP的参数映射:假设我们优化输入层到隐藏层的权重、隐藏层偏置、隐藏层到输出层的权重、输出层偏置
# 这里隐藏层节点数设为10(新手可以自己改,或者把隐藏层节点数也当成优化变量,不过搜索维度会变高,新手先试试固定隐藏层节点数)
input_dim = X_train_scaled.shape[1] # 8维
hidden_dim = 10
output_dim = 1
D = (input_dim * hidden_dim) + hidden_dim + (hidden_dim * output_dim) + output_dim # 计算搜索维度
lb = [-3] * D # 权重和偏置的下界设为-3
ub = [3] * D # 上界设为3
# 3. 定义目标函数:输入是优化变量(一维数组),输出是BP的测试集MSE(越小越好)
def bp_objective(X_vars):
"""
X_vars: 优化算法生成的一维变量数组,形状(1, D)或者(D,)
返回:测试集MSE
"""
# 3.1 把一维变量数组拆分成四个部分
idx1 = input_dim * hidden_dim
idx2 = idx1 + hidden_dim
idx3 = idx2 + hidden_dim * output_dim
w1 = X_vars[:idx1].reshape(input_dim, hidden_dim) # 输入层到隐藏层的权重
b1 = X_vars[idx1:idx2].reshape(hidden_dim,) # 隐藏层偏置
w2 = X_vars[idx2:idx3].reshape(hidden_dim, output_dim) # 隐藏层到输出层的权重
b2 = X_vars[idx3:].reshape(output_dim,) # 输出层偏置
# 3.2 创建MLPRegressor,把我们优化的权重和偏置放进去(注意要禁用sklearn自带的训练!)
mlp = MLPRegressor(hidden_layer_sizes=(hidden_dim,), activation='relu', max_iter=0, warm_start=True, random_state=42)
# 先fit一次,让sklearn初始化一下结构,然后再替换成我们的权重和偏置
mlp.fit(X_train_scaled[:1], y_train[:1])
# 替换权重和偏置:mlp.coefs_是权重列表,mlp.intercepts_是偏置列表
mlp.coefs_ = [w1, w2]
mlp.intercepts_ = [b1, b2]
# 3.3 预测测试集,计算MSE
y_pred = mlp.predict(X_test_scaled)
mse = np.mean((y_pred - y_test)**2)
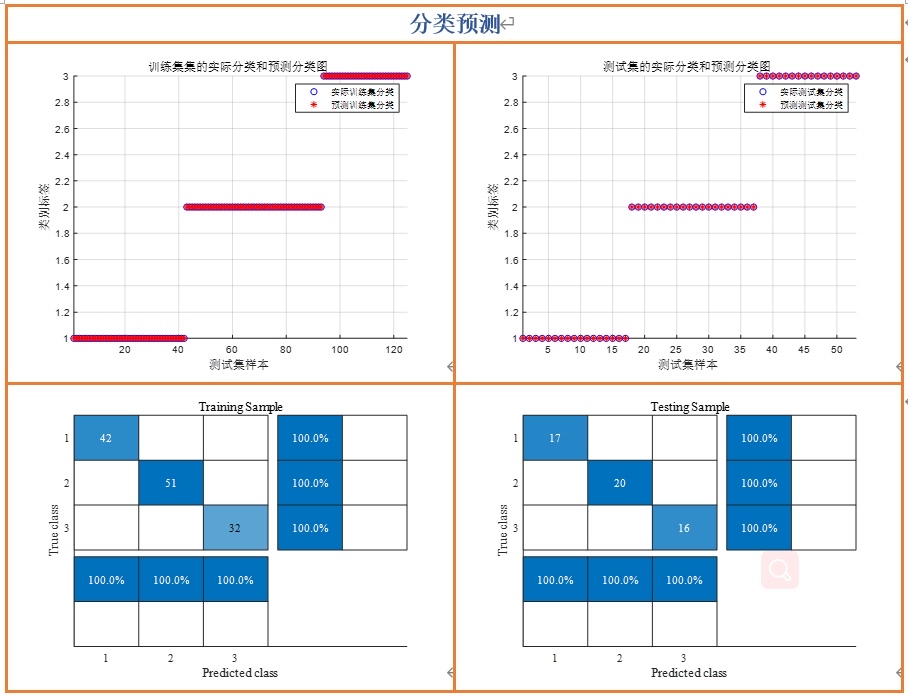
return mse把这个bp_objective函数当成前面核心迭代部分的func,就能用SLWChoA调BP的权重和偏置啦!新手可以试试优化加州房价的其他模型,比如SVM(优化C和gamma)、LSTM(优化学习率、隐藏层节点数、时间步长),只要把参数映射成一维变量、写好目标函数就行,SLWChoA的核心迭代部分是通用的!
最后说几句新手的避坑指南
- 搜索维度别太高:比如优化LSTM,如果同时优化学习率、隐藏层节点数、时间步长、层数、Dropout率,搜索维度会很高,收敛很慢,新手先试试优化2-3个参数;
- 上下界别设太大:比如权重和偏置一般设[-3,3]或者[-5,5]就行,设太大的话搜索空间太广,Sobol初始化也没用;
- ML模型的数据一定要预处理:比如归一化、标准化,不然优化算法生成的权重和偏置会失效;
- 边界处理一定要加:新手很容易忘这步,导致优化变量超出范围,程序报错或者ML模型训练失败。
好啦,今天的分享就到这里!如果有什么问题,或者需要完整的代码,欢迎在评论区留言~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)