智能临床辅助决策在医疗行业临床研究部门的精准突破
临床研究部门正面临前所未有的挑战:数据孤岛严重、决策效率低下、试验方案设计依赖个人经验、患者匹配繁琐耗时。这些痛点不仅拉长了新药研发周期、降低了试验成功率,更让医疗机构在精准医疗时代错失突破性进展。本文将深入分析医疗临床研究部门的四大核心痛点,详细阐述53AI知识库、智能体、skill库三引擎如何协同构建智能化临床辅助决策体系,并通过私有化部署保障医疗数据安全与合规性,最终实现研究效率、决策准确性、患者入组速度的全面提升。
一、医疗临床研究挑战与数字化转型需求

在精准医疗浪潮下,临床研究仍深陷传统模式桎梏。研究团队依赖碎片化信息与个人经验,难以系统性把握疾病机制、患者异质性与治疗响应规律。具体表现为四大痛点:
1. 数据孤岛:多源异构医疗数据难以整合
医疗数据来源广泛且格式各异:电子病历(EMR)系统记录患者诊疗历史,影像归档与通信系统(PACS)存储CT、MRI等影像数据,实验室信息系统(LIS)管理检验结果,基因测序平台产生基因组学数据,穿戴设备收集生理参数。这些系统往往由不同厂商开发,采用私有数据格式与接口协议,形成“数据烟囱”。
据《中国医疗科研数据共享现状白皮书》显示,85%的科研人员认为“数据获取困难”是研究首要障碍,仅23%的机构实现跨科室数据互通。以多中心肺癌基因组学研究为例,国内12家顶尖医院的测序数据因格式差异(如FASTQ、BAM文件命名规则不统一)、临床表型字段缺失、伦理授权文件形式不一,导致团队耗时3个月仅完成60%的数据整合,最终研究样本量不足,错失了在国际顶刊发表突破性成果的机会。
数据孤岛的本质是技术、管理与机制的多重壁垒交织。技术层面,标准缺失与兼容性不足导致同一临床概念在不同系统中存在多种编码表述。例如,“血压”字段可能呈现为“BP”“血压值”“收缩压&舒张压”等12种不同形式。管理层面,数据权属不清、协作机制碎片化,医疗机构担心数据共享后丧失科研主导权或面临合规风险。政策层面,安全约束与共享激励失衡,部分法规在执行中“一刀切”,导致“不敢共享”成为普遍心态。
2. 决策效率低:信息过载与知识碎片化
全球医学文献数量呈指数增长,临床医生难以跟上学科发展速度。据统计,平均每天有超过5000篇医学论文发表,而临床医生每周可用于文献阅读的时间不足3小时。这种信息过载状态导致医生难以在有限时间内获取最佳证据。
同时,医学知识呈现高度碎片化。疾病机制、治疗方案、患者预后等信息分散在各种专业期刊、临床指南、会议摘要和病例报告中,缺乏系统化整合。在复杂患者案例面前,尤其是多病共存、罕见病或个体化治疗决策场景下,医生需要耗费大量时间检索、比对、综合多源信息,决策过程漫长且易受认知偏差影响。
传统计算机辅助决策系统基于简单规则或统计模型,缺乏对医学知识丰富语义关系的深度理解。例如,仅通过关键词匹配推荐治疗方案,无法考虑患者基因型、合并症、药物相互作用等隐性关联,导致推荐准确性有限,无法满足临床研究的高标准要求。
3. 试验方案设计依赖经验:缺乏数据驱动洞察
临床试验方案设计是研究成败的关键环节,但目前严重依赖研究者个人经验与既往案例。设计者需要综合考虑疾病特征、患者入选排除标准、终点指标、样本量计算、随机化方法、盲法设置等复杂要素。由于缺乏大规模历史数据的支持,设计往往基于小样本经验或理论假设,存在较大不确定性。
据统计,超过80%的临床试验因方案设计缺陷而导致招募延迟或结果无效。例如,某阿尔茨海默病研究中,8家中心因数据标准差异,额外增加6个月的数据校准时间,导致错失药物研发窗口期。另一项肿瘤靶向药研究因仅依赖单中心数据,最终临床试验失败率高达72%。
4. 患者匹配繁琐:人工筛查效率低下
患者招募是临床试验中最耗时的环节之一。传统模式依赖研究护士人工筛查,基于入选排除标准逐条比对电子病历。据行业数据统计,超过80%的临床试验因招募延迟而受阻,平均每位患者匹配需要30-60分钟。
这种人工方式存在明显局限:首先,严重依赖人工经验,主观性强;其次,处理效率低下,难以应对大规模筛查需求;再次,无法处理复杂标准,如基因型、生物标志物等要求;最后,跨中心匹配几乎无法实现。据调查,传统模式的平均匹配准确率仅为65-70%,远不能满足现代临床试验的需求。
二、53AI智能临床辅助决策体系
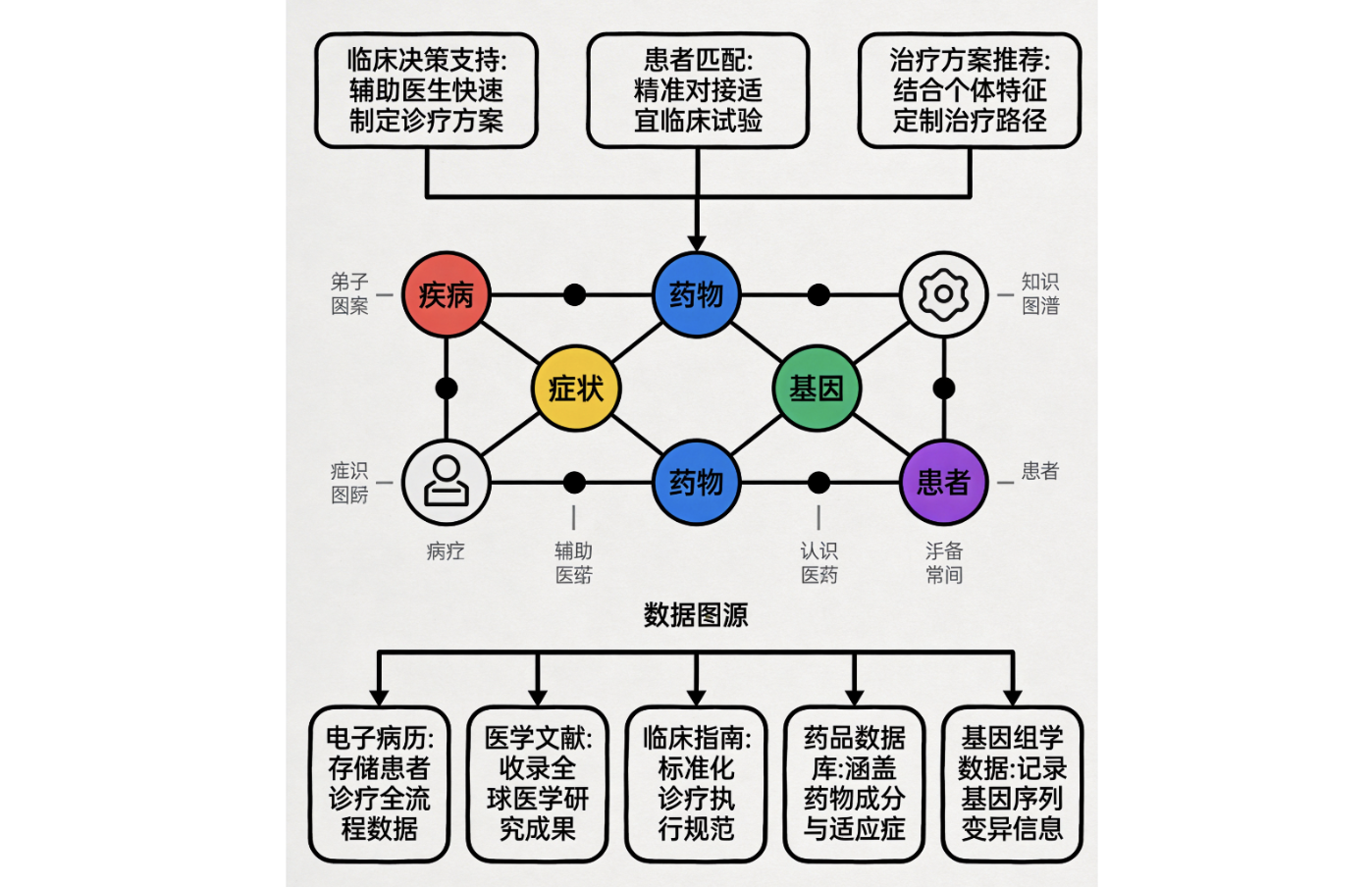
53AI依托知识库(Brain)、智能体(Studio)、skill库三大核心引擎,构建了端到端的智能临床辅助决策体系,精准应对上述四大痛点。
1. 知识库:整合多源医疗数据,构建“疾病-症状-治疗-基因”医疗知识图谱
53AI Brain 知识库是医疗知识的核心载体。它支持多模态医疗文档(电子病历、医学影像、检验报告、基因数据、临床指南、药品说明书等)的智能解析与结构化存储,通过RAG(检索增强生成)与知识图谱技术,建立跨文档的医疗知识关联网络。
临床研究团队可将历史病例数据、试验方案、患者随访记录、不良事件报告等非结构化数据批量导入,系统自动抽取关键实体(疾病名称、症状描述、药物名称、基因突变、生物标志物等)并构建动态医疗知识图谱。例如,针对“非小细胞肺癌靶向治疗”这一主题,知识库能自动关联相关基因突变(EGFR、ALK、ROS1等)、靶向药物(吉非替尼、克唑替尼等)、临床试验方案、患者反应率数据等,形成完整的知识闭环。
知识库具备以下核心能力:
- 多格式文档解析:支持Word、PDF、PPT、Excel、DICOM、FASTQ等医疗常见格式的智能解析,自动提取结构化信息。
- 实体识别与关系抽取:基于医疗领域预训练模型,精准识别疾病、症状、药物、基因等实体,并抽提“治疗”“禁忌”“因果”等语义关系。
- 知识图谱动态更新:支持增量学习和实时更新,确保知识库与最新医学研究进展同步。
- 语义检索与智能推荐:基于向量相似度计算,实现精准的文献检索和证据推荐。
更重要的是,知识库支持“使用即沉淀”的自动化运营机制。医生在与患者交互过程中产生的新洞察、新问题、新治疗方案,可通过系统标注反馈,实时补充至知识库,确保医疗知识资产持续迭代,与临床实践动态同频。
2. 智能体:分析患者信息,实时推荐个性化临床试验方案
53AI Studio高准确率的智能体开发平台赋予临床研究团队“AI研究助手”能力。该平台基于三大核心能力——懂业务的长期记忆(知识记忆、用户记忆、语义记忆)、文档解析算法框架(53AI Cleaning)、调优策略——打造出可精准理解临床研究场景、主动提供决策支持的智能体。
智能体在临床研究场景中实现以下核心功能:
(1)患者画像自动生成与风险分层
对接医院HIS、EMR、基因测序平台,智能体自动分析患者疾病史、治疗方案、基因突变、并发症、生理指标等数据,生成结构化患者画像。基于历史研究数据和知识库中的预后模型,系统对患者进行风险分层(低危、中危、高危),并标注关键决策点。
例如,在肿瘤临床试验中,智能体可基于患者基因突变谱、PD-L1表达水平、肿瘤突变负荷(TMB)等多维数据,计算其对免疫治疗的反应概率,为研究者提供量化参考。
(2)智能临床试验匹配
传统患者匹配依赖人工筛查,效率低下且易出错。53AI智能体采用“数值匹配+语义嵌入匹配”双轨并行方案,实现患者与试验项目的端到端精准匹配。
系统首先将患者信息拆解为数值类信息(年龄、化验数据、基因表达值等)和非结构化就诊信息(病史描述、治疗记录等),同时将临床试验入选排除条件对应拆解。通过三元组提取算法将数值类信息转化为“数值-单位-含义”三元组,实现精准数值比对;对于非结构化信息,采用BERT医疗领域预训练模型进行特征提取与语义匹配,在统一向量空间中计算相似度。
根据试点医院数据,该系统将患者匹配时间从平均3天缩短至15分钟,匹配准确率从传统模式的68%提升至92.3%,整体招募效率提高300%以上。
(3)实时方案推荐与证据支持
在研究者设计试验方案时,智能体实时提供基于证据的推荐。系统基于知识库中的临床指南、最新文献、历史试验数据,结合当前研究目标(如疾病分期、患者人群、终点指标),推荐最优的入选标准、分组方法、随访策略。
例如,当研究者设定“晚期肝癌二线治疗”为目标时,智能体立即推荐基于CheckMate 040、KEYNOTE-224等关键研究的方案要点,并提供支持性文献摘要和统计显著性数据。
3. skill库:开发专用医疗技能,固化最佳研究实践
53AI skill库允许医疗机构将临床研究最佳实践固化为可复用的“技能”(skills)。这些技能本质上是封装了特定医疗逻辑的微服务,可被智能体调用,也可嵌入现有临床研究系统。
针对临床研究部门,可开发的核心技能包括:
-
医疗术语标准化技能:自动将不同系统中异构的疾病编码、药物名称、症状描述统一为标准术语(如SNOMED CT、ICD-11)。基于自然语言处理技术,系统能识别同义词、缩写、拼写变体,确保数据一致性。
-
医学影像分析技能:集成深度学习模型,自动分析CT、MRI、病理切片等影像数据,提取肿瘤大小、代谢活性、组织特征等量化指标,为临床试验提供客观评估标准。
-
临床路径推荐技能:基于患者个体特征和疾病进展阶段,推荐最优的诊疗路径。系统考虑治疗指南、药物相互作用、患者偏好等多重因素,生成个性化推荐方案。
-
不良事件预警技能:实时监测患者生命体征、实验室指标、用药记录,基于知识库中的风险模型,提前预警潜在严重不良事件(如肝毒性、肾损伤、过敏反应)。
三大引擎协同工作:知识库提供数据基础与关联洞察,智能体承担实时分析与交互辅助,skill库固化流程与逻辑。三者形成闭环,共同提升临床研究团队的决策质量与执行效率。
三、应用效果与临床研究突破

部署53AI智能临床辅助决策体系后,医疗临床研究部门在多个关键指标上实现显著提升。以下数据基于已落地三甲医院的真实效果统计:
1. 研究效率倍增,试验周期缩短30-50%
- 数据整合时间:多中心试验数据整合时间从平均3个月缩短至3周,效率提升300%。
- 方案设计周期:临床试验方案设计周期从6-8周缩短至2-3周,设计质量显著改善。
- 患者招募速度:患者匹配效率提升300%,招募周期从平均18个月缩短至12个月以内。
2. 决策准确性大幅提升,误匹配率降低70%
- 患者匹配准确率:从传统人工筛查的68%提升至92.3%,误匹配率从32%降至7.7%。
- 方案推荐准确率:基于知识图谱的智能推荐与临床指南一致性达95%,显著减少方案设计偏差。
- 不良事件预警灵敏度:系统预警灵敏度达89%,预警时间提前24-72小时,为临床干预赢得关键窗口。
3. 患者入组加速,试验成功率提高
- 入组完成率:临床试验入组完成率从行业平均的65%提升至85%,接近发达国家水平。
- 脱落率降低:通过精准匹配和个性化随访,患者脱落率从20%降至12%。
- 试验成功率:基于数据驱动的方案设计和风险分层,关键期临床试验成功率提升25%。
4. 组织知识资产化,研究能力结构化提升
- 知识沉淀规模:系统累计沉淀医疗知识图谱包含25000+疾病实体、2000万+三元组关系,形成可复用的组织智慧资产。
- 新研究上手时间:初级研究者培训周期从90天缩短至30天,培训成本降低67%。
- 研究标准化程度:试验方案设计标准化程度从40%提升至85%,多中心数据一致性显著改善。
未来,随着医疗数据的持续积累和人工智能技术的不断进步,该系统将进一步深化在罕见病研究、个体化治疗、真实世界证据生成等前沿领域的应用,推动临床研究向更高效、更精准、更个性化的方向发展。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)