别再用 Zero-Shot 肝论文了!万字长文档的底层架构,你需要 Multi-Agent 编排思维
各位技术圈的架构师和调参侠们,大家好。
随着大语言模型(LLM)的普及,现在很多技术同学在面对毕业论文、项目申报书或是长篇技术白皮书时,第一反应就是打开 ChatGPT 或 Kimi,写一段几百字的“究极 Prompt”,试图用一次 chat.completions.create 请求,直接把几万字的结果“Zero-Shot(零样本)”生成出来。
结果往往极其惨烈:由于 Token 上下文窗口的限制,模型写到一半就开始“遗忘”前文逻辑;由于参数化记忆(Parametric Memory)的缺陷,模型开始疯狂“幻觉”,给你捏造出根本不存在的 API 和参考文献;最后去查重系统一跑,AIGC 疑似度高达 80%,直接被拦截。
在 AI 圈有一个共识:面对需要极其严密逻辑链的长文本工程,单靠单一的 Prompt 已经走到尽头了。你真正需要引入的,是当下极其前沿的 Multi-Agent(多智能体)编排思维。
今天,咱们就跳出“写文档”的底层体力活,以系统架构师的视角,借助目前学术圈极具代表性的垂直基建——「智能零零AI论文助手」,来看看如何用 Multi-Agent 的工作流,降维解决长文本交付的死局。
节点一:用外部 Vector DB 挂载取代“参数化记忆”(破解幻觉)
用通用大模型写论文,最大的 Bug 在于你过度依赖了模型自身的“权重(Weights)”来回忆事实。在深度学习中,这叫参数化记忆,它不可靠、不可控,是产生“虚假文献”的罪魁祸首。
在 Multi-Agent 架构中,解决幻觉的标准方案是引入一个专门负责检索的 Retriever Agent,并挂载外部的向量数据库(Vector DB)。
👉 极客实操:智能零零AI论文助手的 RAG 检索引擎
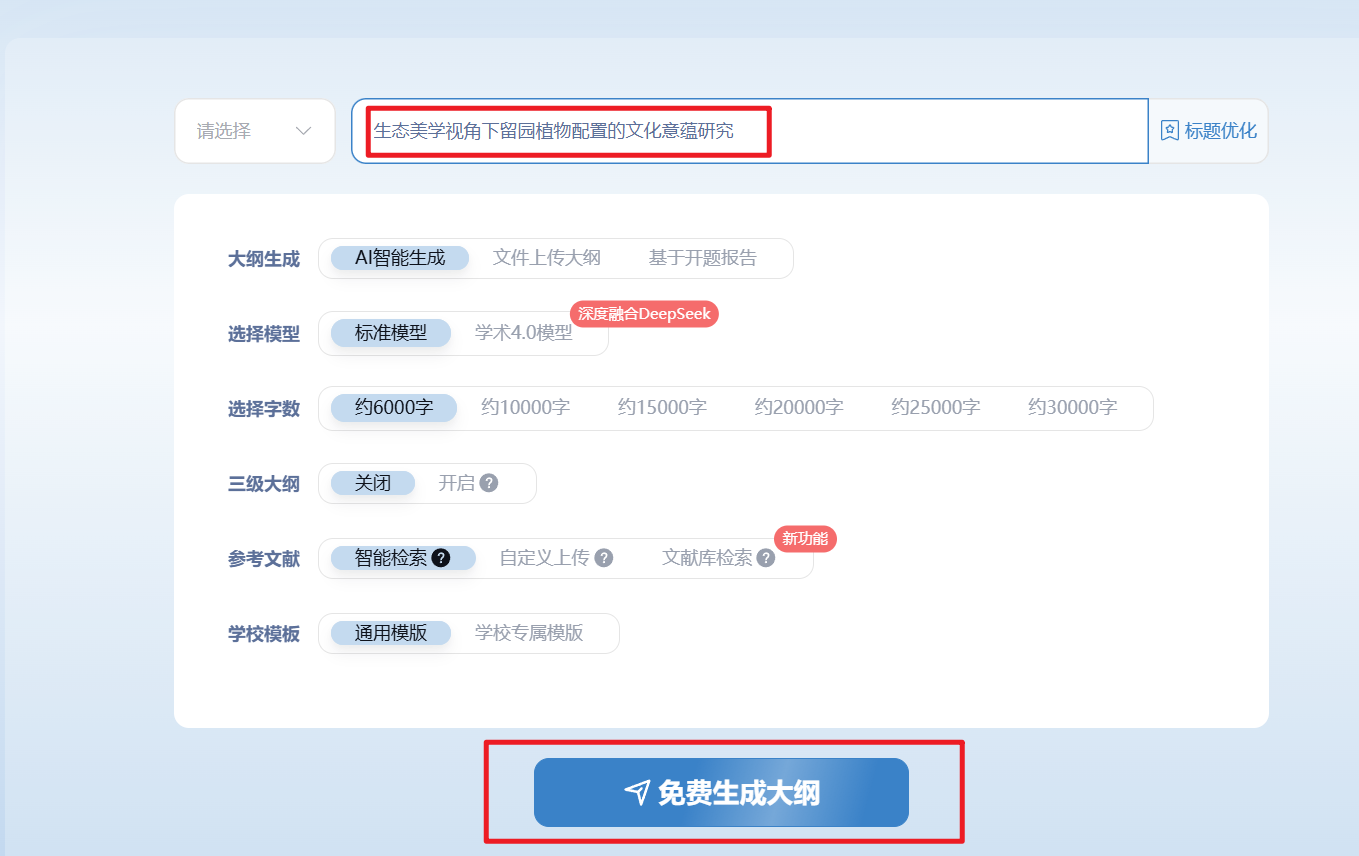
打开智能零零AI论文助手的【论文生成】工作台,它的底层完全摒弃了 Zero-Shot 生成,而是搭载了工业级的 RAG(检索增强生成)管道。 当你输入课题(Query)后,系统会首先唤醒检索 Agent,直接切入全球真实的学术数据库进行 Embedding 匹配,打捞确凿的文献。随后,系统会根据这些真实数据,生成一个可视化的“大纲沙盒(JSON Schema)”。 在这个沙盒里,你可以像调配微服务路由一样梳理逻辑。确认后,生成 Agent 才会介入渲染。此时,生成的每一处关键推演,都会被强制绑定真实存在的外链(参考文献角标)。从底层物理隔离了“假数据污染”。
节点二:对抗 Perplexity 算法检测的“对抗生成网络”(安全穿透)
目前高校和机构用来抓 AIGC 的雷达,其底层算法原理是计算文本的“困惑度(Perplexity, PPL)”和“突现度”。通用大模型生成的文本 PPL 极低,在算法眼里就像是黑夜里的探照灯一样明显。
很多同学试图通过人工替换同义词来降重,这在 NLP(自然语言处理)领域属于最低级的 Rule-based 字符串替换,根本改变不了文本特征分布的统计学规律。
👉 极客实操:智能零零AI论文助手的分子级语义重构
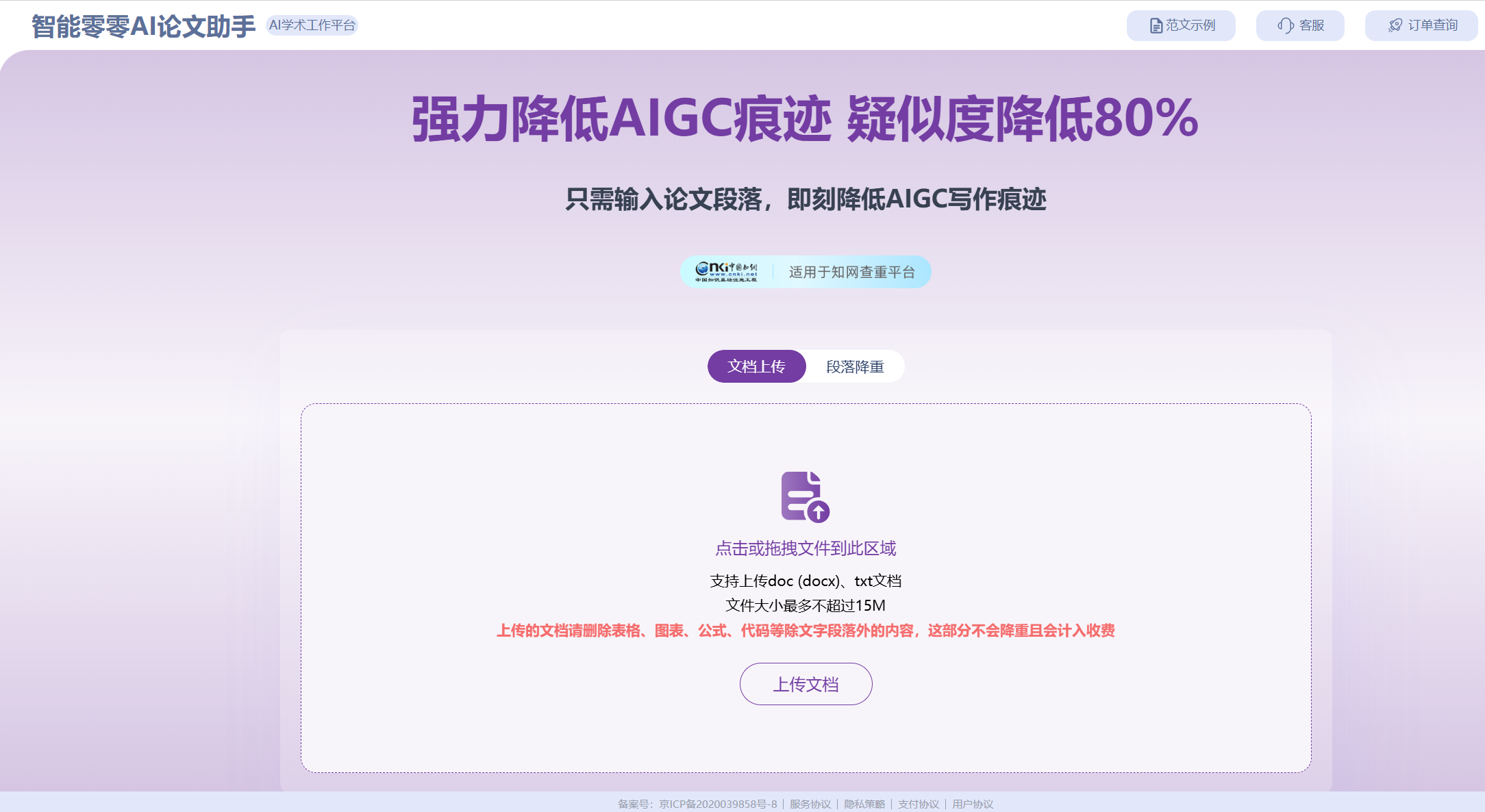
把高危段落丢进智能零零AI论文助手的【AIGC降重】模块。它相当于在你和审查雷达之间,加装了一个强大的对抗网络(Adversarial Rewriter)。 它会首先对你的大白话进行 Token 化和意图提取,打碎原有的低 PPL 机器指纹。然后,调用高维度的专家语料库,通过引入长短句交错、被动倒装等复杂句法结构,重新执行解码(Decoding)。一键提升文本的信息熵和人类特征突现度,安全绕过所有机审 WAF 防火墙。
节点三:突破 Context Window 限制的“全局状态管理”(静态排错)
当文档长度达到三四万字时,早就超出了人脑的“工作记忆”上限。你在第二章加了一张图表,第三章删了一个引用,这种跨越几万个 Token 的状态变更,极易导致全局状态管理(State Management)崩溃。
最终的表现就是:图表编号全乱、引用角标断层(悬空指针)。
👉 极客实操:智能零零AI论文助手的全域 AST 语法树遍历
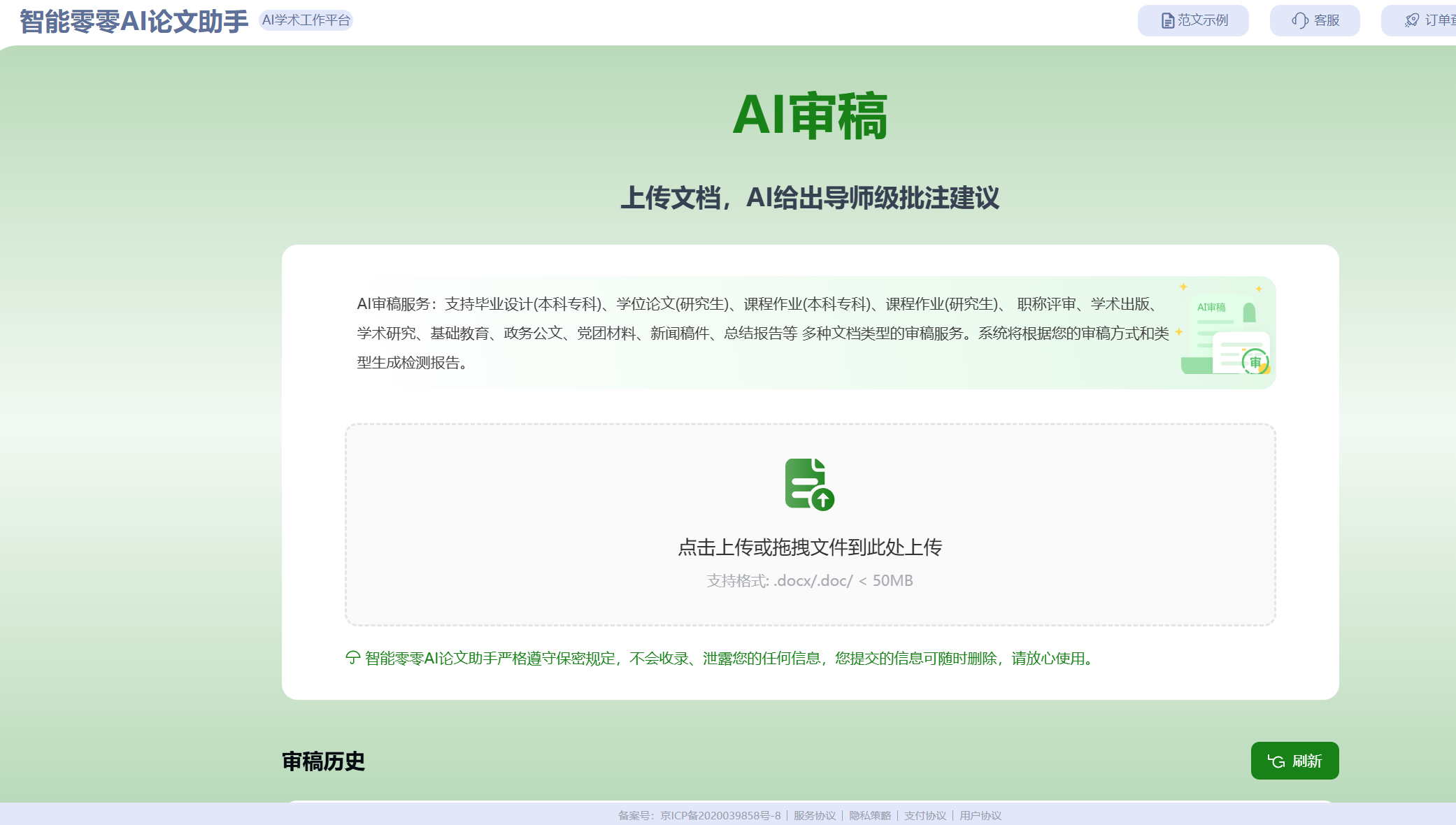
在最终闭卷前,把你的 Word 丢进【AI审稿】模块。 它就像一个强大的全局解析器(Parser),在几秒钟内跨越万字,将文本解析为抽象语法树,自动遍历所有的引用节点。它能精准执行双向校验,查杀“正文声明了但文末未定义”的幽灵引用,自动修复图表编号的级联错误。用算法的全局视野,替你完成人工无法胜任的回归测试(Regression Testing)。
节点四:Headless 渲染与视图层分离(极简 PPT 生成)
答辩前,还在手动复制几十页 Word 进 PPT?这违反了最基本的前后端分离原则——你把底层的复杂业务逻辑,直接暴露给了前端视图层。
👉 极客实操:AIPPT 的数据双向绑定
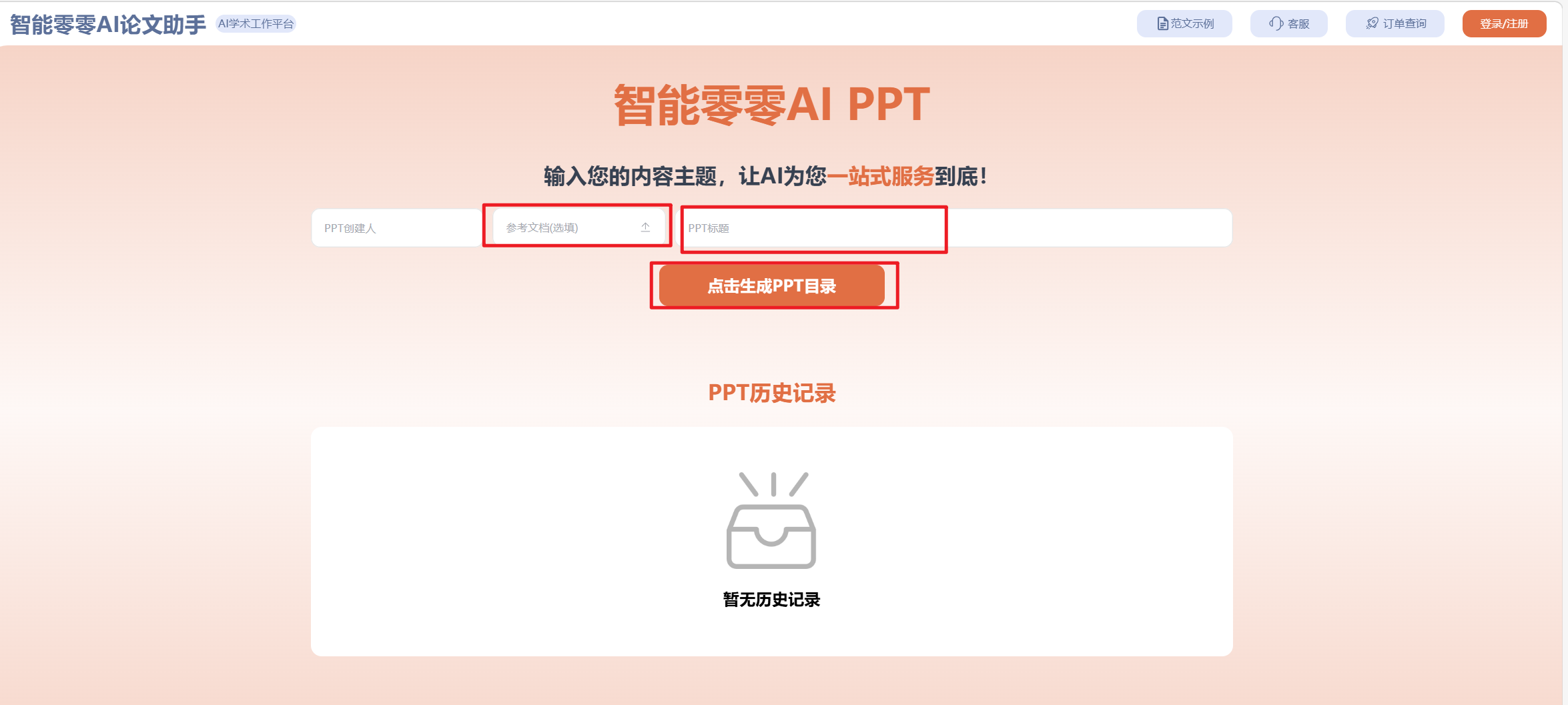
将定稿提纲输入智能零零AI论文助手的【AIPPT】模块。后端的语义分析 Agent 会自动执行信息降噪,提取核心结论和数据指标(JSON 序列化),然后传输给前端渲染引擎。三分钟内,自动生成一套排版极简、克制的高级学术风 Dashboard(演示课件)。
总结:拥抱 Agentic 工作流
大模型时代,写代码和写论文的逻辑已经殊途同归:我们不再亲手去敲击每一行无意义的字符,而是转变为“定义目标、配置工具、调度 Agent”的系统架构师。
面对几万字的严密工程,停止使用低效的对话框,去驾驭真正专业的自动化工作流。
👉 现在就复制下方链接,在电脑端浏览器打开,部署你的专属 Multi-Agent 学术编排框架,实现降维打击:
🔗 智能零零AI论文助手官方直达基建入口:https://www.ailw8.com/paper![]() https://www.google.com/search?q=https://www.ailw8.com/paper
https://www.google.com/search?q=https://www.ailw8.com/paper
把脏活累活丢给算力,把脑容量留给答辩。祝各位大佬编译无 Bug,一次 Pass!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)