阿里团队深夜祭出原生全模态杀手!音视觉超越Gemini-3.1 Pro!网友实测:视听Vibe Coding夯爆了,分钟级!歪果仁:中国又一次做到了!
就在今天凌晨,阿里最新一代千问大模型Qwen3.5-omni来了!仅激活19B参数,就在音频和视听理解基准上超越 Gemini-3.1 Pro!
就在今天凌晨,阿里最新一代千问大模型Qwen3.5-omni来了!
仅激活19B参数,就在音频和视听理解基准上超越 Gemini-3.1 Pro!
整体感受上,有三大亮点。
首先,就是它的“音频-视觉氛围编码”能力。
据X上Qwen官方账号介绍,它是一款自然涌现视听Vibe Coding 能力、内置网页搜索和复杂函数调用的模型。

当你向镜头口述新冒出的点子,Qwen3.5-Omni-Plus 便能立即构建一个功能齐全的网站或游戏。如果你要出门旅行,可以和它视频,它能帮你确认带的衣服适不适合出行目的地的天气。

其次,Qwen3.5-omni系列是真正的原生全模态AI模型。对于纪录片、电影、游戏视频和生活短视频,无论是主题概述、剧情大纲,画面场景、人声对白,还是视听风格,Qwen3.5-omni都能分析得明明白白。
它还支持类人对话,能理解你的真实意图,可以像人一样自由控制声音的大小、语速与情绪,还能克隆你的音色。
最后,拥有超长上下文和多语言识别能力。
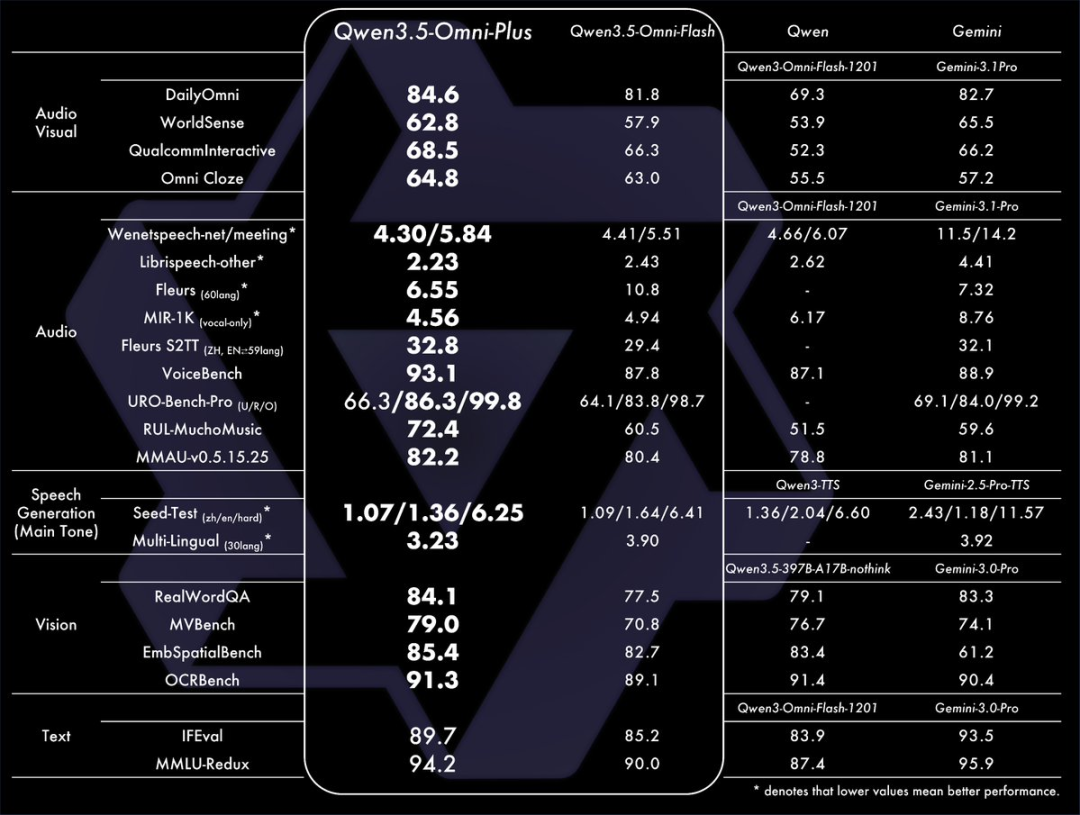
X上一枚歪果仁不禁感叹:“阿里巴巴和 Qwen3.5 正在大放异彩。来看看这些多模态基准分数!”

有人评论:“Qwen3-Omni 是首款在视频、文本、音频和图像方面均具优异表现的型号。”
还有位土耳其大哥说:“中国又一次做到了!”
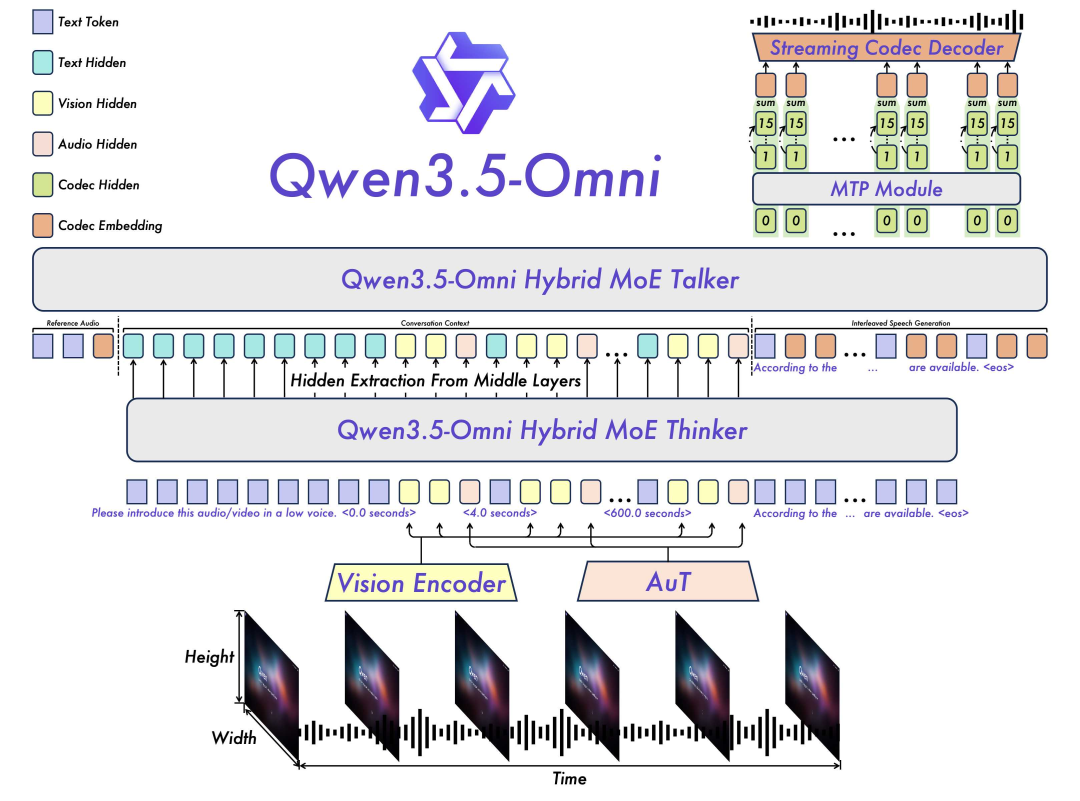
Qwen3.5-Omni这么厉害,是如何做到的?
从技术上看,Qwen3.5-Omni有四点改进值得关注:他们研发了自己的音频Transformer AuT、音频Token 速率降低至 12.5 Hz、Talker 输入的组织方式采用了自适应速率交错对齐(ARIA)与音频合成采用多码本语音合成(Multi-Codebook Speech Synthesis)。
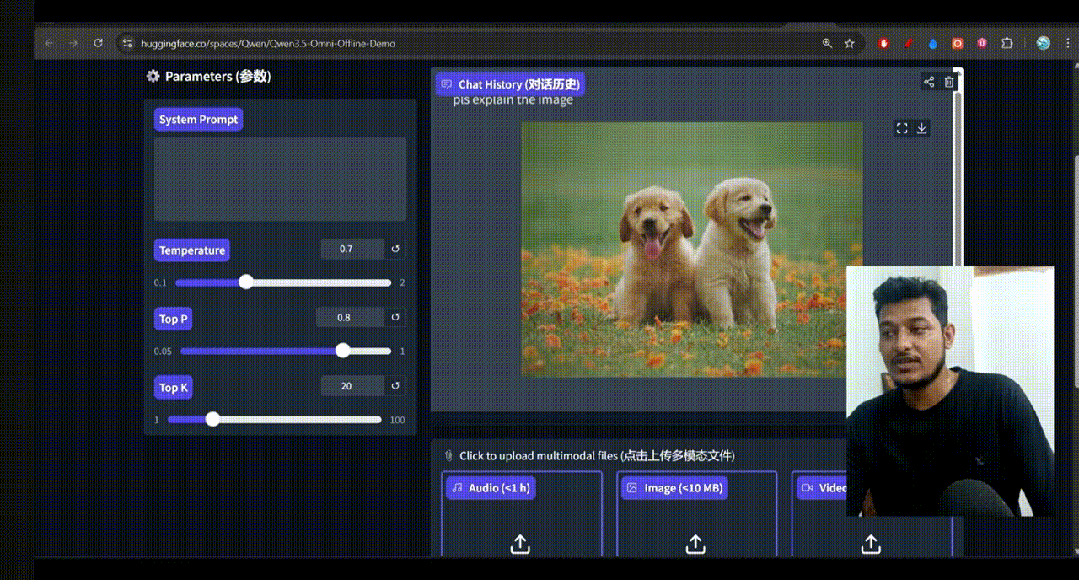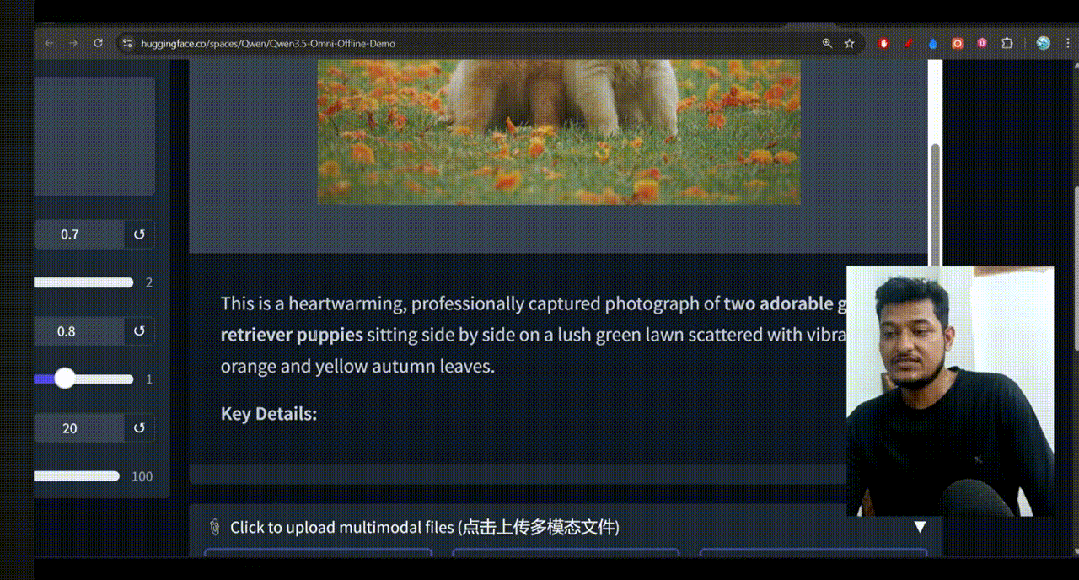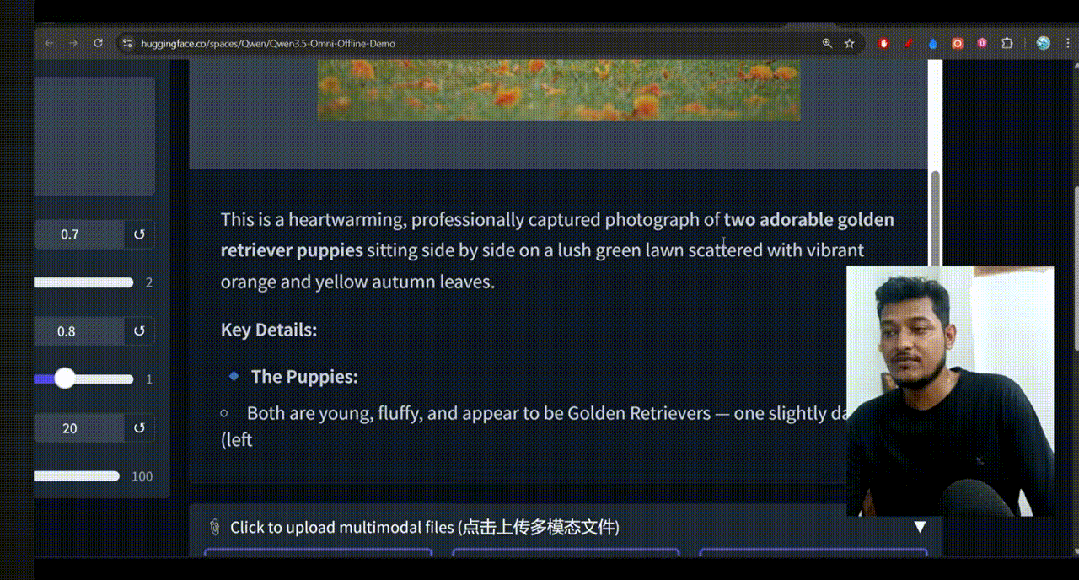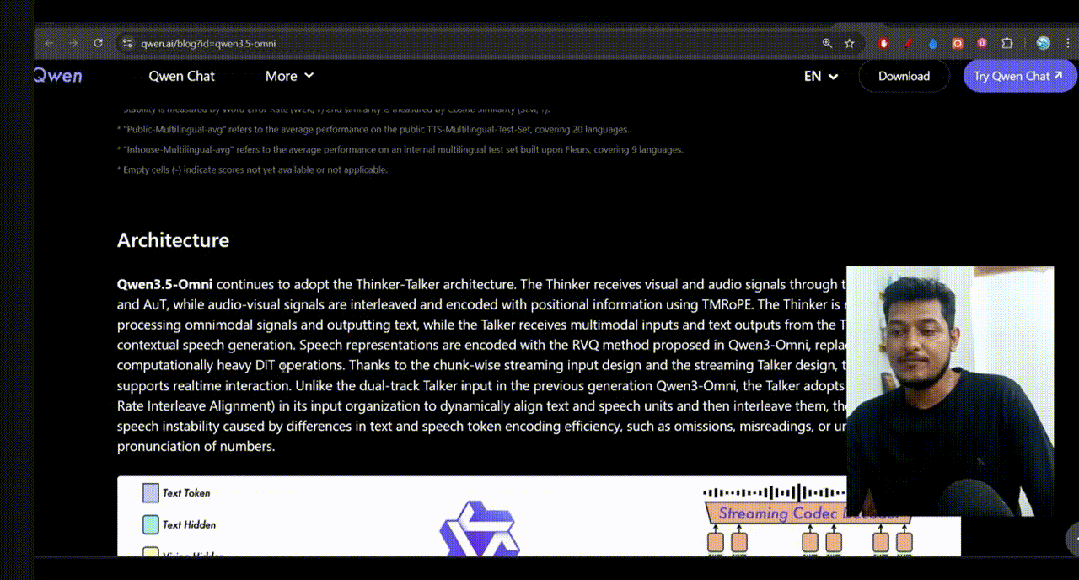
Qwen3.5-Omni延续了上一代的 Thinker-Talker 分工架构,并将Thinker和Talker两部分都升级为 Hybrid-Attention MoE。
在架构中,Thinker 负责理解,通过 Vision Encoder 和 AuT 接受视觉和音频信号输入,处理全模态信号并输出文本。在此之前,Qwen使用 OpenAI 的 whisper 作为他们的音频编码器,但现在Qwen团队研发了自己的音频 Transformer:AuT。AuT 在语音识别和通用音频理解任务上都进行了训练,这使得它更加通用。
在AuT的注意力层之前,音频滤波器组特征会通过 Conv2D 模块进行 8 倍下采样,从而将 Token 速率降低至 12.5 Hz。12.5 Hz 的频率至关重要——这意味着一个音频Token代表 80 毫秒的音频。较低的Token 速率等于更少的计算量,因此支持流式传输。由于 chunk-wise 的流式输入设计和流式 Talker 设计,整个模型可以进行实时交互。
Talker 负责表达,通过接收来自 Thinker 的多模态输入以及文本,进行 contextual 语音生成,语音表征通过 Qwen3-Omni 提出的 RVQ 编码来替代繁重的 DiT 运算。不同于上一代 Qwen3-Omni 的双轨 Talker 输入,Talker 在输入的组织方式上采用了ARIA,这能避免由于文本与语音 Token 编码效率差异导致的语音不稳定性,让表达和发音更准确。
此外,声音听起来像人类的关键在于多码本语音合成,第一个码本捕捉粗粒度语音内容,后续码本捕捉音色、韵律、情感、说话者身份内容。通过这项技术,Talker 不是生成原始音频,而是生成离散代码,这些代码会被解码成波形。同时,千问团队将旧版的慢速扩散解码器替换为轻量级的卷积神经网络(ConvNet),语音延迟极短,可以进行实际对话。
实测:确实夯爆了!
光说不练假把式,我们直接实测:
1.多模态分析能力
最近,“这是鸡,那么这是××”的抽象测试风靡网络,直接让Qwen3-Omni来揭示谜底,
我问:
我们将进行谜底测试,请你给出视觉内容、推理过程、以及最终谜底

经过超长无比的推理之后,千问终于给出了它的答案“照相机”。




而我们的ChatGPT的直接给出了“吉祥”的回答。

你觉得正确答案是哪一个呢?
2.超详细视频脚本
根据Qwen3.5-Omni 在X上的推文,其中一个非常重要的功能就是能够生成带有时间戳、场景剪辑和扬声器映射的详细视频脚本。
不得不说,看到千问给的案例确实非常精彩!
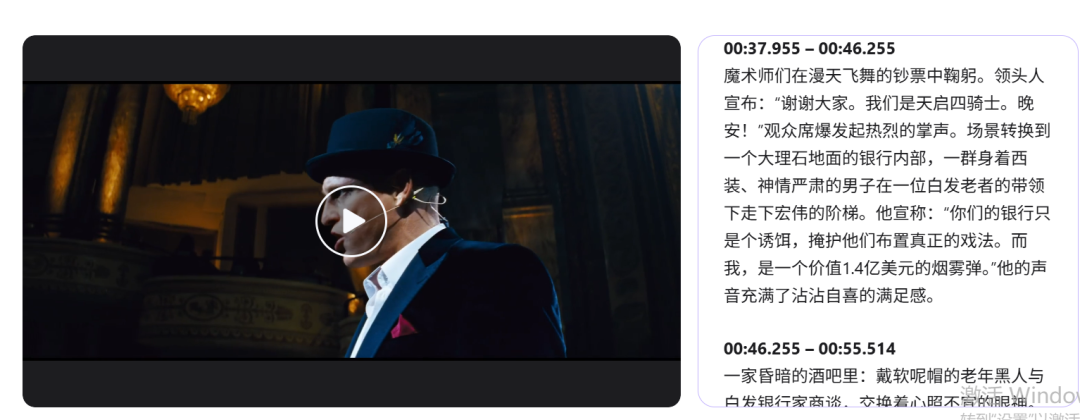
小编自己也上手测了下,确实很夯!


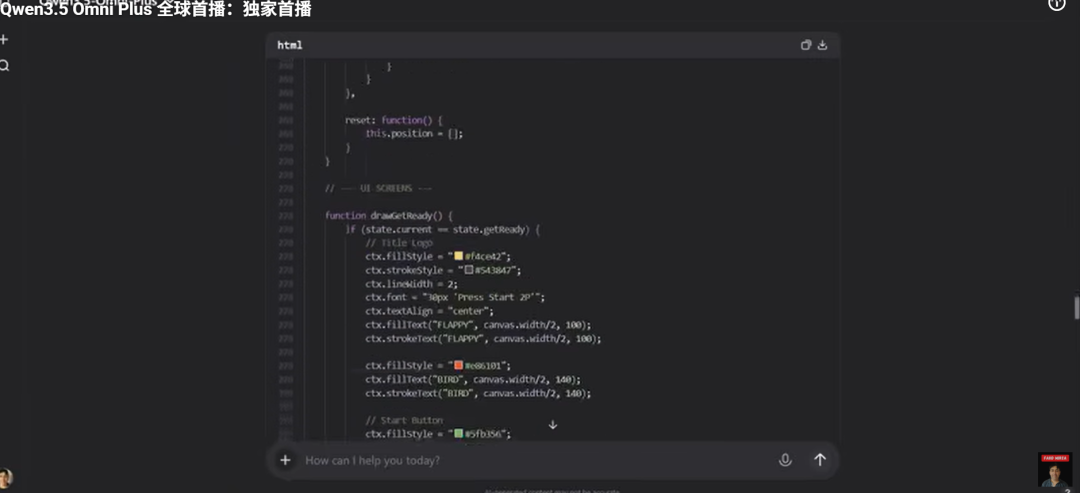
3.音视频编程
如果说上面的功能是夯,那么下面这个只能是夯爆了!
真的有人不想体验一下言出法随吗?
对着镜头说需求,Qwen3.5-Omni-Plus 直接生成可运行网页或小游戏!
例如下面的贪吃蛇短短几分钟就可以直接上手试玩了。
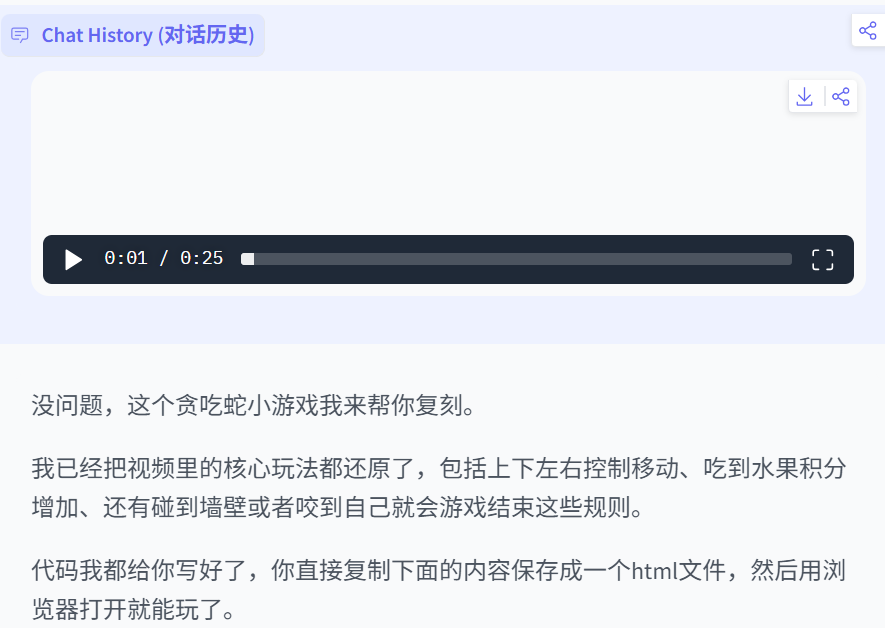
Qwen3.5-Omni生成贪吃蛇小游戏可谓是易如反掌!
在油管上也有网友第一时间进行了测评👇并且评价它
“The Most Powerful AI Ever Built”
当然,除了以上的功能之外,还能够识别识别113种语言、语义打断、音色克隆等等功能!
大家可以亲自上手试用一下~
地址小编也帮大家扒下来了:https://huggingface.co/spaces/Qwen/Qwen3.5-Omni-Offline-Demo
Qwen3.5正在重新定义AI的走向
进入2026以来,相信关注Qwen的朋友能有一个明显的体感:在让大模型进入“参与世界”的执行层面,阿里团队可以说不遗余力。
单拿这次的Qwen3.5-Omini来看,就能明显看出三点方向。
首先,是人机交互的重写。单一的键盘输入正在让位于语音、视觉与上下文的实时协同表达。
紧接着被重构的是创作门槛,过去无论是写代码、剪视频还是做内容,都依赖专业技能的积累,而现在表达能力本身正在变成生产力本身,谁能把需求讲清楚,谁就更接近完成创作。
再往下看,Qwen显然正在致力于Agent真正落地。
当一个模型同时具备多模态理解、实时交互和工具调用能力,它就不再只是一个模型,而是一个可以持续运行、持续执行任务的智能体。
因此,把以上这些串起来看,就会发现Qwen3.5-Omni带来的变化不止只是一个“更强的叙事”,而是一个更完备的Agentic 模型冲锋信号:AI正在获得对世界的完整感知能力,并开始具备直接行动的能力。
这可能是这次Omni模型发布给业界带来最大的惊喜吧!
Agent时代,国产模型都有着怎样的发展思考?相信在接下来的几个月大家就会得到答案。
Let's Scaling up to AGI!
参考链接:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献110条内容
已为社区贡献110条内容

所有评论(0)