【说话人日志】从 BLSTM 到 Self-Attention:SA-EEND
论文:End-to-End Neural Speaker Diarization with Self-Attention
简称:SA-EEND
作者:Yusuke Fujita, Naoyuki Kanda, Shota Horiguchi, Yawen Xue, Kenji Nagamatsu, Shinji Watanabe
时间:2019
任务:Speaker Diarization,回答“谁在什么时候说话”
一、前言
这篇论文(SA-EEND)是提升 EEND 的性能,可以看做 EEND 的补丁包。
原始 EEND 的核心思想、PIT 损失、DPCL 辅助损失、以及为什么 diarization 可以改写成逐帧多标签任务,可参见 EEND 2019
SA-EEND 说明以下 3 个方面:
- self-attention 比 BLSTM 更适合 diarization
- SA-EEND 结构
- 实验说明 attention 学到了更合适的表示
二、BLSTM → \rightarrow → self-attention
SA-EEND 继承原始 EEND 的根本设定:
- diarization 仍然是逐帧多标签分类
- 训练仍然用permutation-free loss
改动的地方只有一个:
把原始 EEND 里的 BLSTM 编码器,替换成了 self-attention 编码器。
speaker diarization (SD) 任务,本质上同时依赖两类信息:
- 局部信息:当前帧附近有没有语音、边界在哪、是否进入或退出说话状态
- 全局信息:第 3 秒和第 53 秒那两段声音,是不是同一个人
原始 EEND 里的 BLSTM 更擅长前一类。
而 SA-EEND 这篇论文要论证的是:
self-attention 更适合把“全局 speaker characteristic”和“局部 speech activity dynamics”一起建模。
三、SA-EEND 结构
Log-Mel 特征
-> 线性投影
-> 多层 self-attention encoder block
-> 线性层 + sigmoid
-> 每一帧每个 speaker 的说话概率
论文结构图如下: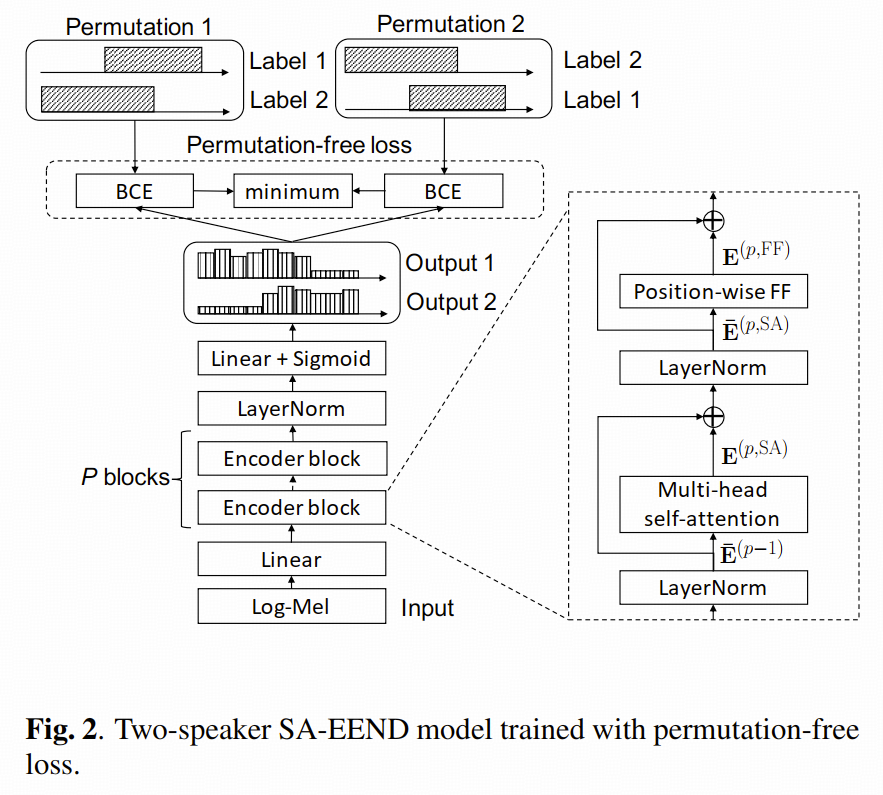
和原始 EEND 相比,这里最大的变化就是中间的编码器。
原始 EEND:
输入特征 -> BLSTM -> 输出层
SA-EEND:
输入特征 -> Self-Attention Encoder -> 输出层
需要注意的是,论文的自注意力机制没加位置编码。作者更在意帧与帧之间的说话人相似关系,而不是严格的绝对位置编码。有关 Transformer 结构可以参考笔记。
四、实验结果
论文的逻辑非常朴素:
- SD 需要建模长距离 speaker 一致性
- BLSTM 对长距离依赖的建模不够直接
- self-attention 能直接比较任意两帧
- 所以它更可能学到全局 speaker 特征
实验结果需要论证:
- DER 是否真的更低
- attention 图是否真的反映了“全局 speaker characteristic + 局部 speech activity dynamics”的分工
4.1 数据准备
论文一共准备了两类训练集、五类测试集。
4.1.1 训练集
| 训练集 | mixture 数量 | 平均时长 | overlap ratio |
|---|---|---|---|
| Simulated ( β = 2 ) (\beta = 2) (β=2) | 100,000 | 87.6 s | 34.4% |
| Real (SWBD+SRE) | 26,172 | 304.7 s | 3.7% |
模拟训练集的构造方式和原始 EEND 一脉相承:
- 从
Switchboard-2、Switchboard Cellular、NIST SRE中取电话语音 - 总 speaker 数
6,381 - 划分为
5,743个训练 speaker 和638个测试 speaker - 每个 mixture 固定是
2-speaker - 每个 speaker 取
10~20个 utterances - 用平均间隔参数 β \beta β 控制重叠程度
- 加背景噪声和 RIR
4.1.2 测试集
| 测试集 | 数量 | 平均时长 | overlap ratio |
|---|---|---|---|
| Simulated ( β = 2 ) (\beta = 2) (β=2) | 500 | 87.3 s | 34.4% |
| Simulated ( β = 3 ) (\beta = 3) (β=3) | 500 | 103.8 s | 27.2% |
| Simulated ( β = 5 ) (\beta = 5) (β=5) | 500 | 137.1 s | 19.5% |
| CALLHOME | 148 | 72.1 s | 13.0% |
| CSJ | 54 | 766.3 s | 20.1% |
CALLHOME 双人对话随机划分为两部分:
155条录音用于 domain adaptation148条录音用来测试
4.2 模型配置
4.2.1 输入特征
和原始 EEND 一样,输入特征是:
23维 log-Mel filterbank- 帧长
25 ms - 帧移
10 ms - 前后各拼接
7帧上下文 - 再做
10倍下采样
最终是每 100 ms 输入一个 23 × 15 = 345 维向量。
4.2.2 SA-EEND 配置
SA-EEND 用的是:
P = 2个 encoder blocksD = 256H = 4个 attention heads- d f f = 1024 d_{\mathrm{ff}} = 1024 dff=1024
- 训练时序列长度限制为
500帧,也就是50秒
训练阶段把长录音切成不重叠的 50 秒片段,这是因为 self-attention 吃显存;
但推理阶段还是用整段录音。
4.3 结果分析
Table 2 :
| 方法 | Sim β = 2 \beta=2 β=2 | Sim β = 3 \beta=3 β=3 | Sim β = 5 \beta=5 β=5 | CALLHOME | CSJ |
|---|---|---|---|---|---|
| i-vector clustering | 33.74 | 30.93 | 25.96 | 12.10 | 27.99 |
| x-vector clustering | 28.77 | 24.46 | 19.78 | 11.53 | 22.96 |
| BLSTM-EEND, trained with sim. | 12.28 | 14.36 | 19.69 | 26.03 | 39.33 |
| BLSTM-EEND, trained with real | 36.23 | 37.78 | 40.34 | 23.07 | 25.37 |
| SA-EEND, trained with sim. | 7.91 | 8.51 | 9.51 | 13.66 | 22.31 |
| SA-EEND, trained with real | 32.72 | 33.84 | 36.78 | 10.76 | 20.50 |
4.3.1 在模拟重叠语音上,SA-EEND 显著优于 BLSTM-EEND
看 simulated 三列:
- BLSTM-EEND(sim):
12.28 / 14.36 / 19.69 - SA-EEND(sim):
7.91 / 8.51 / 9.51
4.3.2 SA-EEND 对 overlap ratio 变化更稳
BLSTM-EEND 在 β = 2 → 5 \beta=2 \rightarrow 5 β=2→5 时,从 12.28 退化到 19.69。
而 SA-EEND 只从 7.91 退化到 9.51。
4.3.3 在真实数据上,SA-EEND 也明显优于 BLSTM-EEND
看 CALLHOME:
- BLSTM-EEND(sim) + adapt:
26.03 - SA-EEND(sim) + adapt:
13.66
看 CSJ:
- BLSTM-EEND(sim):
39.33 - SA-EEND(sim):
22.31
4.3.4 SA-EEND 甚至超过了 x-vector clustering
尤其在真实训练集 + 真实测试集条件下:
- CALLHOME:
10.76,优于 x-vector 的11.53 - CSJ:
20.50,优于 x-vector 的22.96
这在 2019 年是很强的结果,因为它意味着:
端到端 diarization 不仅概念上成立,而且已经可以在一些真实测试集上超过当时强势的 x-vector clustering。
4.3.5 为什么“trained with real”在模拟集上效果很差
SA-EEND trained with real在 CALLHOME/CSJ 上最好- 但它在 simulated 三列上很差
这说明:
EEND 类模型仍然对训练数据分布很敏感。
论文给出的训练集统计是:
- simulated 训练集 overlap ratio
34.4% - real 训练集 overlap ratio
3.7%
所以:
- 用 simulated 训练,更适合模拟重叠条件
- 用 real 训练,更适合真实域
这也是后来很多工作一直在做 domain adaptation、数据混合训练、可变说话人数训练的根源。
4.4 attention 可视化
论文给了第二层 encoder block 的 attention 权重图: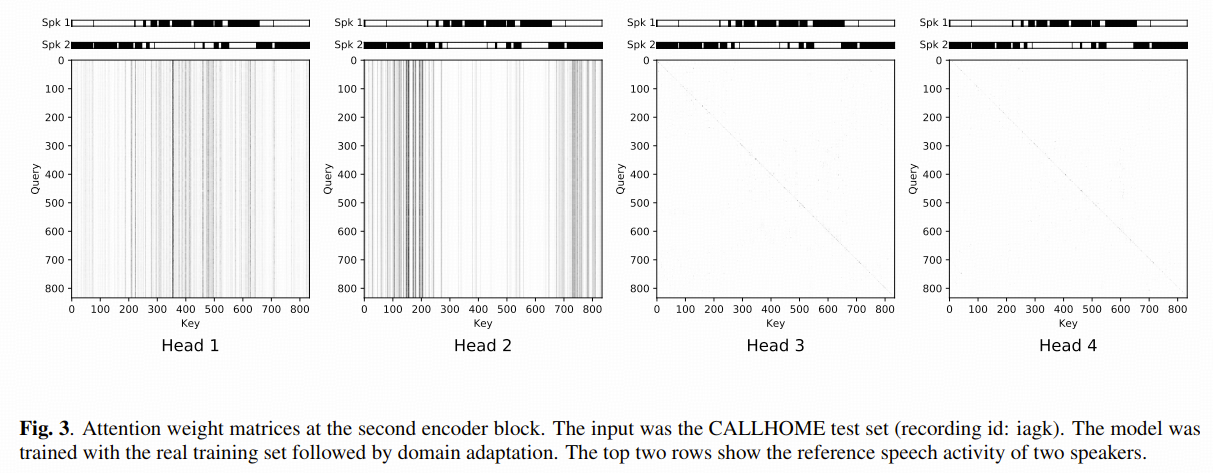
4.4.1 Head 1 和 Head 2 出现明显的竖线
这些竖线对应某个 speaker 活跃的关键帧。
这意味着当前帧会把注意力集中到“同一个 speaker 的其他帧”上。
换句话说,这两个 head 做的事情很像:
在整段录音里抽取某个 speaker 的全局原型。
4.4.2 Head 3 和 Head 4 更像单位矩阵
这说明它们更关注当前位置附近的信息,表现得更像局部时序处理。
作者把它解释为:
- 一部分 heads 在学全局 speaker characteristic
- 另一部分 heads 在学局部 speech/non-speech dynamics
论文一开始就声称 self-attention 适合同时建模全局 speaker 信息和局部活动动态。
而这张图是想说明 模型内部真的出现了这种功能分工。
五、总结
SA-EEND 用 self-attention 替换了 BLSTM,降低了 DER,说明 SD 任务依赖整段录音上的全局关联建模。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)