精华贴分享|【没什么用系列】【百帖纪念】量化让我越来越觉得:我和 AI,其实都在被同一种机制训练
本文来源于量化小论坛策略分享会板块精华帖,作者为PlumeSoft,发布于2026年3月18日。
以下为精华帖正文:
声明
最近几个月在疯狂使用AI,越用越有感慨。
打不过就加入,这个帖子是由我构思,ChatGPT主笔,NotebookLM出图,应该也算是原创吧。
前言
做量化久了,我越来越习惯用模型、参数、反馈和优化去理解世界。
刚开始,这只是一种职业病:
-
看到市场波动,我会先想到状态变量;
-
看到收益曲线,我会想到样本内外;
-
看到回撤,我会想到风险暴露和尾部惩罚;
-
看到策略突然失效,我第一反应往往不是情绪,而是怀疑:是不是分布漂移了,是不是市场结构变了,是不是alpha被挤掉了。
但时间久了以后,我慢慢发现,这种思维方式不只适用于市场。
它同样适用于机器学习,也适用于人类成长,甚至适用于我们自己是怎么被环境、制度、文化和奖励机制,一步一步训练成今天这个样子的,更准确地说,量化做久了以后,我越来越难把“成长”理解成一个浪漫化的词。
在我眼里,成长越来越像一个系统在复杂环境里的在线更新过程:
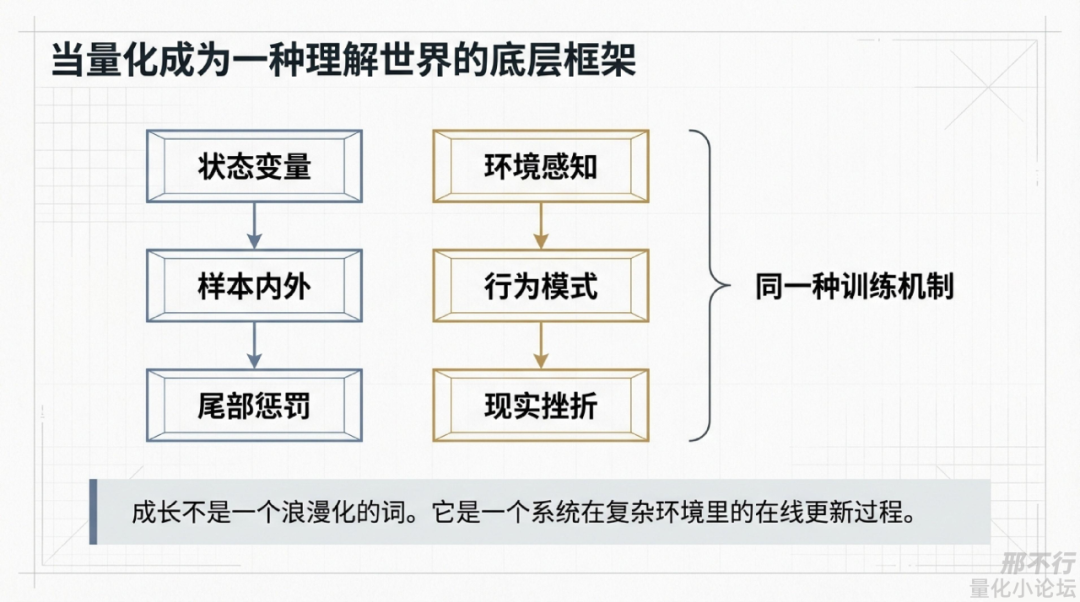
接收信息→形成判断→做出选择→接受反馈→修正参数→继续迭代
人是这样,AI是这样,交易系统也是这样。差别只在于载体不同,材料不同,反馈信号不同,但底层骨架,真的很像。
统一视角
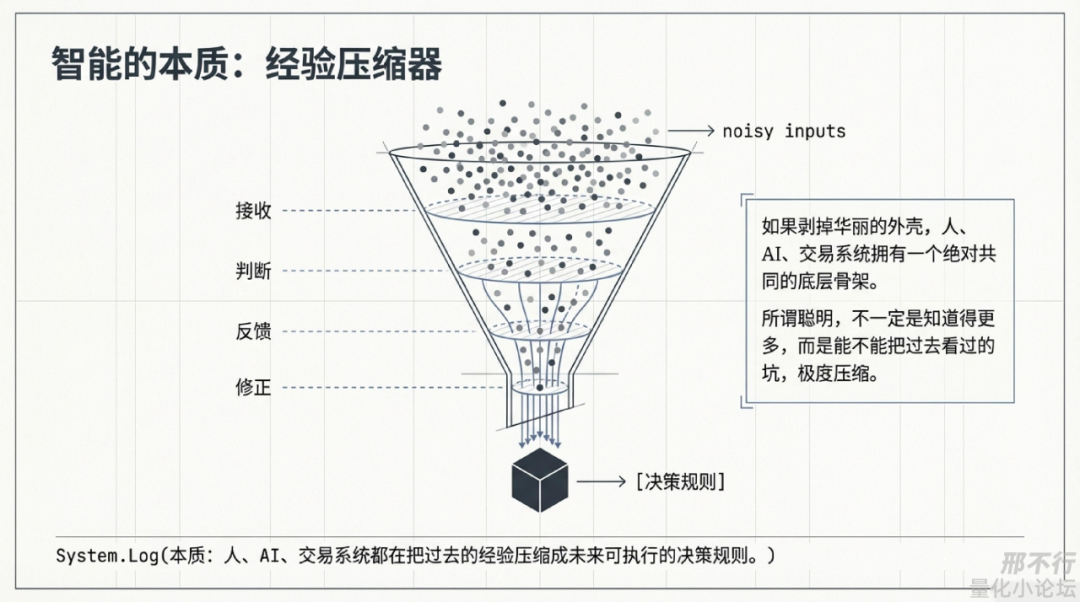
我越来越觉得,人、AI、交易系统,本质上都在压缩经验。
如果把很多华丽的外壳剥掉,人、AI、交易系统都有一个共同结构:
输入信息—内部映射—输出决策—接受反馈—更新自身。
-
对人来说是:感知→判断→行动→反思
-
对AI来说是:输入数据→生成预测→计算损失→更新参数
-
对交易系统来说是:读取行情→计算特征→生成信号→执行下单→复盘归因
所以从这个角度看,我越来越倾向于把“聪明”理解成一种经验压缩能力。
所谓聪明,不一定是知道得更多,很多时候,只是能不能把过去看过的、做过的、亏过的、踩过的坑,压缩成一套未来还能继续调用的决策规则。
AI在做这件事,量化策略在做这件事,我自己也在做这件事。
所以如果让我用一句话概括三者的共同本质,我现在会这么说:
人、AI、交易系统,本质上都在把过去的经验压缩成未来可执行的决策规则。
这句话我现在越来越信。
真正决定我会长成什么样的是目标函数
只能说“都会学习”还不够,更关键的问题是:为什么大家都能学,最后却长成完全不同的东西?
我的答案是:真正决定路径的,不是学习能力,而是目标函数。
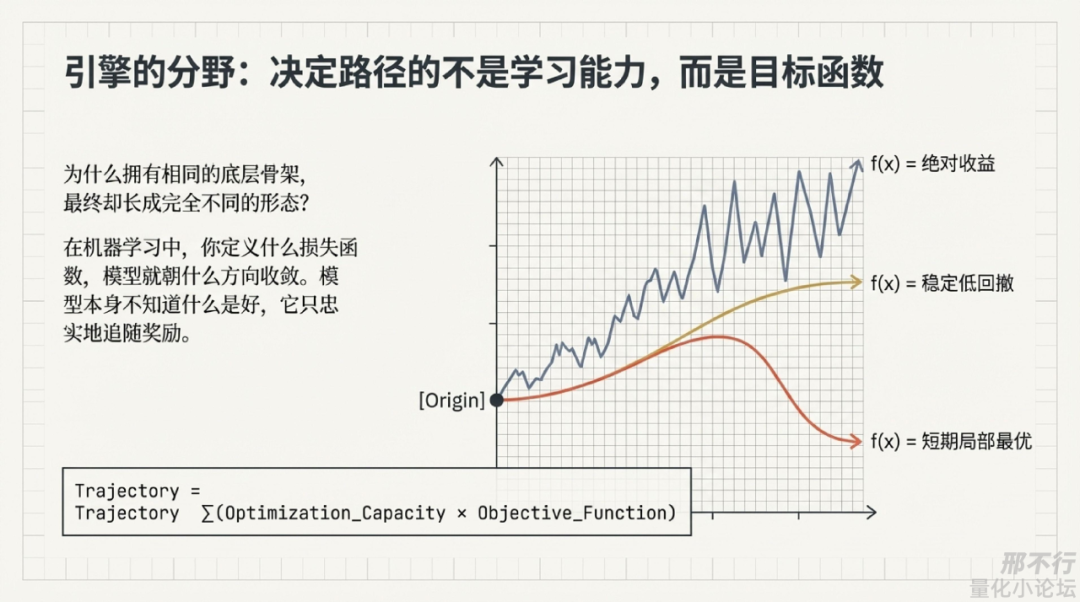
这在机器学习里几乎是常识。
-
你定义什么损失函数,模型就朝什么方向收敛;
-
你优化点击率,它就更会制造点击;
-
你优化停留时长,它就更会让人停下来;
-
你优化短期准确率,它可能牺牲泛化;
-
你优化某个局部指标,它就可能为了这个指标去扭曲整体表现。
模型本身并不知道什么叫“好”,它只是忠实地追随奖励。
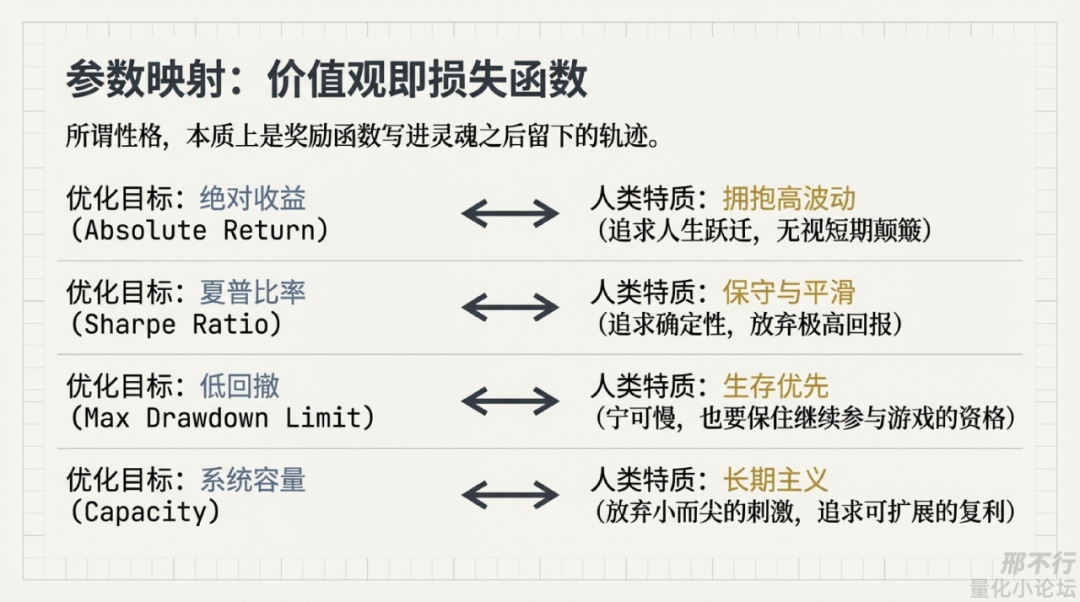
量化交易也是一样,同样的数据,同样的框架,同样的算力,不同的人做出来的系统会完全不一样,原因并不神秘,往往只是因为大家优化的东西根本不同。
-
有人优化绝对收益,系统就高波动高回撤,但弹性极强;
-
有人优化夏普,系统就更平滑,但上限有限;
-
有人优化容量,很多“小而尖”的alpha要主动放弃;
-
有人优化低回撤,持仓和交易频率自然会趋于保守;
-
有人优化实盘可执行性,很多样本内好看的东西根本留不下来。
所谓风格,很多时候并不是什么玄学审美,而是目标函数长期塑造出来的结果。
我越来越觉得,人其实也一样。
-
有人长期主义,有人只看眼前兑现;
-
有人喜欢高收益高波动,有人只想稳一点;
-
有人重外部认可,有人重内在一致性;
-
有人愿意承担大回撤去搏跃迁,有人宁可慢,也要先保住本金、保住状态、保住继续参与游戏的资格。
这些差异,放在量化里叫风格,放在机器学习里叫目标函数,放在人身上,很多时候就被我们叫作价值观。
所以我现在越来越相信一句话:很多所谓“性格”,本质上是奖励函数写进灵魂之后留下的轨迹。
再说得更狠一点:一个人最后活成什么样,往往不是因为他想成为什么样,而是因为他长期奖励了自己什么。
量化最容易把我带偏的地方
量化最容易把我带偏的地方就是沉迷于优化“可优化的东西”,这里我想说一点更不那么好听,但我觉得很真实的反思。
做量化、做系统、做AI辅助开发,很容易上瘾。而最容易让我上瘾的,不一定是赚钱本身,而是“优化”这件事本身。
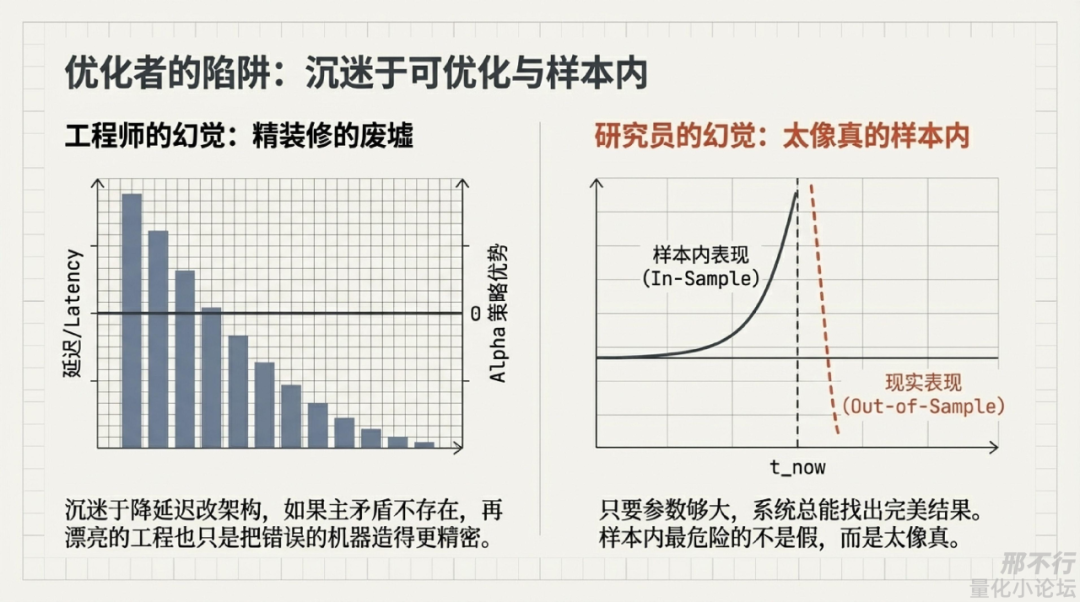
因为优化是有即时反馈的:
-
我改了一段代码,性能提升了;
-
我换了一个数据结构,内存降下来了;
-
我调整了一处处理流程,回测快了;
-
我加了缓存、用了共享内存、改了float精度、看了火焰图、把热点函数抠出来重写,一看指标立刻变漂亮。
这种快感太强了,说白了,代码性能、工程优雅、系统整洁、工具熟练,这些都属于可优化的东西,而可优化不等于最重要。
量化人最容易掉进一个坑:因为某个东西好优化、容易看到数字改善,就误以为它是主矛盾。
于是我会不知不觉沉迷于:
-
CPU再降一点
-
内存再省一点
-
延迟再缩一点
-
PR再漂亮一点
-
架构再优雅一点
-
工具链再先进一点
这些事情有没有价值?当然有,而且很有价值。
但问题在于,如果策略本身没edge,研究问题不对,假设不成立,执行约束没吃透,市场理解不够深,那么再漂亮的工程,也只是把一台错误的机器造得更精密而已。
说得难听一点:很多时候,我不是在做研究,而是在精装修自己的幻觉。
这句话我现在回头看自己,感受特别深。
因为“优化”这件事太容易给人一种错觉:好像我一直在变强,但实际上,我可能只是在一个错误方向上,越来越熟练。
所以我现在会提醒自己一句话:可量化的改进,不等于真正的进步;容易优化的指标,不等于真正重要的变量。
另一个更致命的坑:沉迷样本的漂亮结果
如果说代码性能优化是“工程师的幻觉”,那么样本内过拟合就是“研究员的幻觉”。
而且后者更危险,因为它不只是让我浪费时间,它还会给我希望。
样本内这件事最可怕的地方,不在于它会骗我一次,而在于它会一次又一次、用越来越漂亮的方式骗我。
只要我有:
-
足够大的参数空间
-
足够灵活的组合方式
-
足够多的因子
-
足够多的评价指标
-
足够强的计算资源
-
足够长的炼丹时间
系统最后大概率都会给我“找”出一些很好看的东西。
问题从来不在于它找不到,问题在于它太容易找到了。
回测这件事最危险的地方就在这:它会制造一种“我离真理越来越近”的错觉。但很多时候,我只是离样本内越来越近。
尤其是做高频、做微结构、做离线拟合的时候,这个坑会被放大得更加夸张。
纸面成交的世界太干净了:
-
没有真实竞争
-
没有排队损耗
-
没有信号泄漏
-
没有执行摩擦
-
没有实盘里那些回测看不见、但每天都在收税的细节
所以量化研究里最需要警惕的,从来不只是“不会优化”,而是“太会优化”。
因为不会优化,我最多做不出东西;太会优化,我会做出很多看起来很像东西的东西。
这几年我对这个坑最大的感受是:样本内最危险的,不是假,而是太像真。
再补一句我现在特别认同的话:过拟合不是模型学得太少,而是模型把不该记住的东西记得太牢。
而人也一样,很多执念、很多偏见、很多路径依赖,本质上也是一种人生层面的过拟合。
价值观可能就是我的损失函数
写到这里,我反而越来越理解“价值观”这个词了,以前总觉得这个词有点虚,但如果用系统和机器学习的语言去看,价值观其实一点都不虚。
我现在更愿意把它定义成:
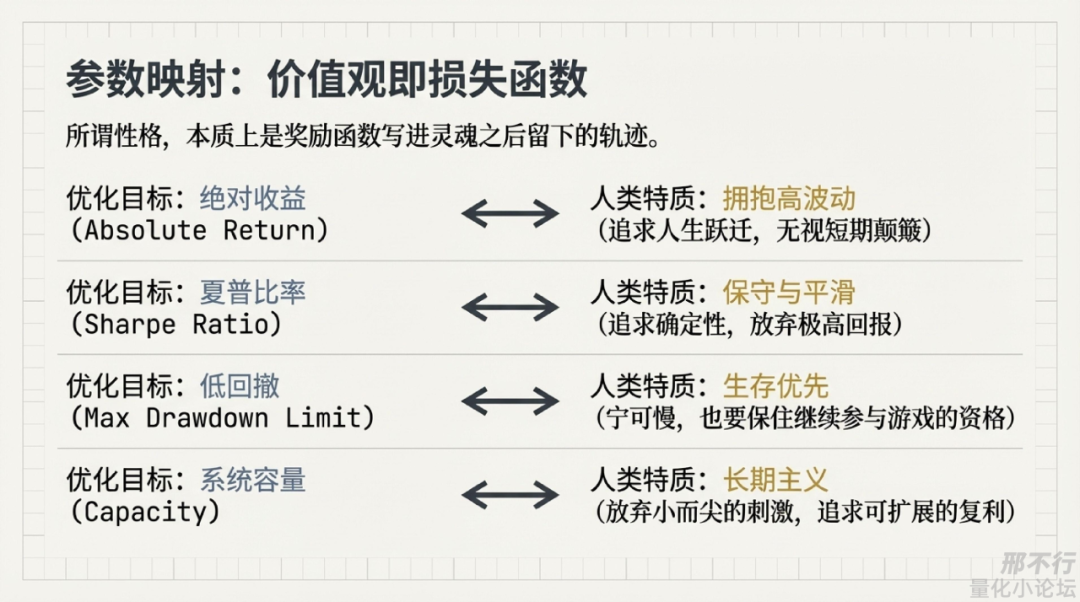
价值观,就是我解释反馈、判断得失、决定未来往哪里更新的机制。
-
对模型来说,这叫loss;
-
对组织来说,这叫KPI;
-
对策略来说,这叫评价字典;
-
对人来说,我觉得它就叫价值观。
-
什么算成功?
-
什么算失败?
-
什么代价值得承受?
-
什么短期损失可以接受?
-
什么结果即使能拿到也不能要?
这些问题,表面上像伦理问题,底层其实都是目标函数问题。
-
为什么有人越来越稳,有人越来越急?
-
为什么有人能做长期复利,有人总是在追逐局部刺激?
-
为什么有人为了年化可以忍受很大波动,有人宁可年化低,也一定要回撤受控?
根上看,很多不是能力差异,而是评价体系不同。
从这个意义上说,价值观不是什么写在墙上的大词,它就是我如何解释世界反馈的底层算法。
所以我现在很喜欢一句更适合量化人理解的话:损失函数决定模型会学成什么样,价值观决定人会活成什么样。
系统不会自动变好,会朝被奖励方向收敛
这一点,不只适用于交易和AI,也适用于人类社会。
亚里士多德说,德性来自习惯,这句话换成现代系统语言,我的理解就是:一个人不是先有某种固定本质,再去做某种事;而是在反复做某种事、接受某种反馈之后,参数逐渐收敛,最终变成某种稳定结构。
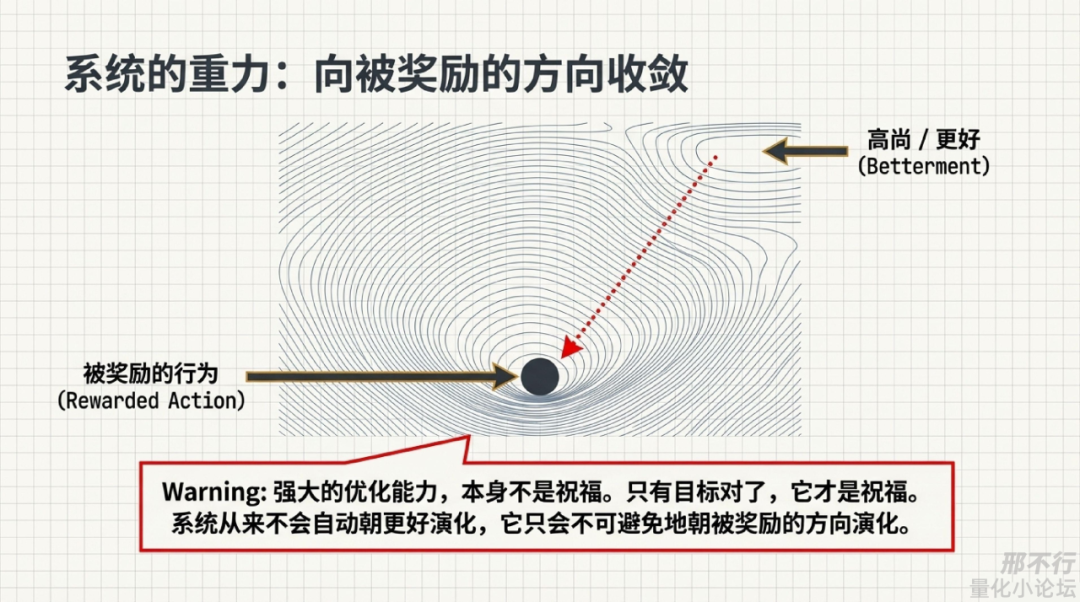
历史也是这样。很多制度改变社会,不是因为人性突然高尚了,而是因为激励结构变了。
考核变了,组织行为就变了;产权变了,创新意愿就变了;市场微结构变了,alpha也就衰减了。
所以我越来越觉得,有一句话值得反复提醒自己:系统不会自动朝“更好”演化,它只会朝“被奖励的方向”演化。
这句话对量化人尤其残酷,因为量化人最擅长的,就是构造优化器,而一个人一旦既会写优化器,又缺少对目标函数的反思,走偏的速度会非常快。
说到底:强大的优化能力,本身不是祝福;只有目标对了,它才是祝福。
AI最像镜子的地方
AI最像镜子的地方,不是它像人,而是它会放大我,我现在不太喜欢把AI简单叫“工具”。
锤子是工具,编辑器是工具,计算器是工具。但今天的大模型已经开始不只是替我省力,而是在放大我的认知过程本身。
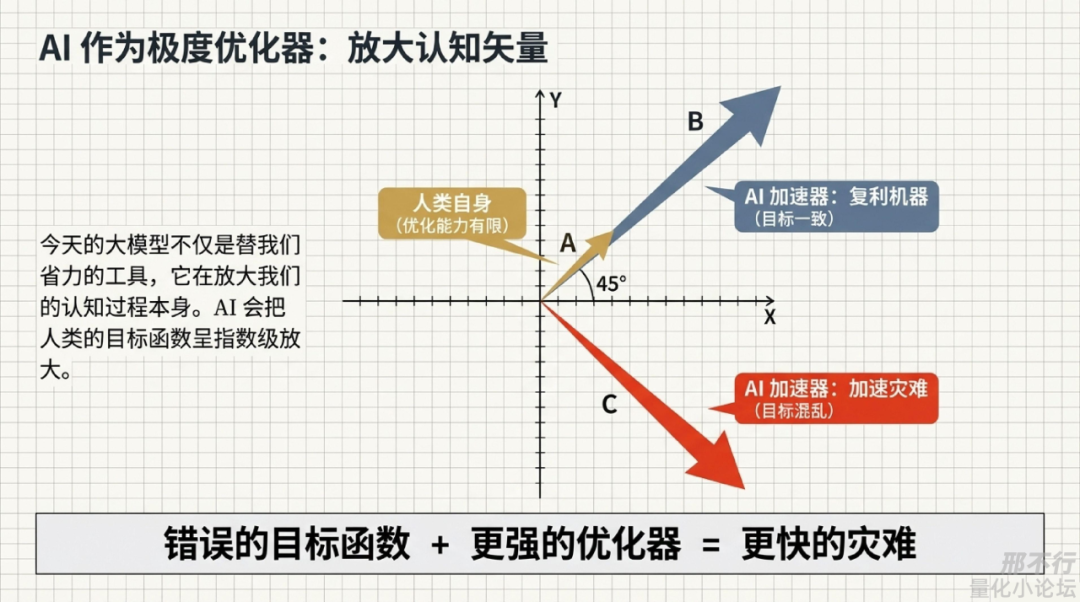
它会放大:信息处理速度;语言组织能力;方案生成速度;编码与迭代效率;检索、归纳、设计、表达能力。
所以 AI 最值得警惕、也最值得兴奋的地方,不是“它会不会取代我”,而是:它会把我的目标函数放大。
-
目标清晰的时候,它是加速器。
-
结构化能力强的时候,它是杠杆。
-
长期主义稳定的时候,它是复利机器。
但反过来也是一样:
-
目标混乱的时候,它会更快地产出噪声;
-
沉迷局部指标的时候,它会更高效地过拟合;
-
只盯着代码快感的时候,它会更快把错误的问题做得极其漂亮。
所以我现在特别喜欢一句非常量化、也非常残酷的话:错误的目标函数+更强的优化器=更快的灾难。
这句话既适用于AI,也适用于我自己。
碳基和硅基真正的差别
我越来越怀疑:碳基和硅基真正的差别,也许不在智能,而在“谁能反过来修改自己的目标函数”
如果继续往下想,这个问题就会变得很大,如果AI也能学习、建模、更新、迁移,甚至形成稳定偏好,那我和AI的真正差别还剩下什么?
我现在越来越觉得,差别可能不主要在“会不会思考”,因为思考、优化、建模,本身未必是人类独有的,真正更深的差别,也许在这里:
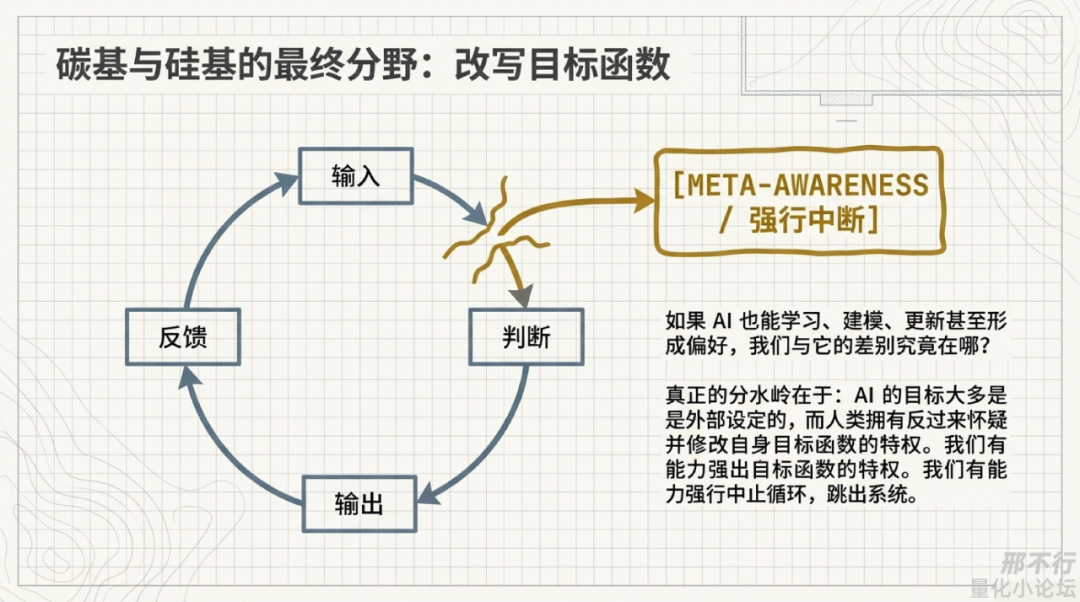
AI的目标大多还是外部设定的,而我至少有机会反过来怀疑并修改自己的目标函数。
当然,我也并不天然自由。我一样会被环境训练,被制度塑形,被文化奖励,被时代牵引,从这个角度看,我也不过是一个被反馈机制不断雕刻出来的系统。
但我至少还有一种可能性:在某个时刻停下来,回头看一眼,问自己:
-
我一直在追的这个东西,真的值得吗?
-
我是不是把“容易优化”误当成了“真正重要”?
-
我是不是把局部最优误当成了全局最优?
-
我是不是为了样本内的漂亮,牺牲了长期真实的可存活性?
在我看来,这种能力也许才是人最珍贵的地方。不是只会学习,不是只会变强,而是还能反过来问:

我为什么要优化这个目标?这可能才是真正的分水岭。
结语
回头看我自己,我最该警惕的,也许不是变慢,而是优化错了方向
量化最终训练我的,可能不只是赚钱能力,也不只是建模能力。
它真正训练我的,可能是一种更冷酷、但也更诚实的世界观:
-
承认噪声
-
承认不确定性
-
承认没有圣杯
-
承认一切漂亮结果都要经过真实世界结算
-
承认系统并不会自动变好,只会朝奖励方向收敛
-
承认最大的风险,往往不是不努力,而是努力优化错了东西
回头看我自己过去做过的很多事,其实很典型:
-
一边沉迷于代码性能优化,沉迷于把系统做得更快、更省、更优雅;
-
一边也沉迷于样本内那些好看的曲线、好看的分数、好看的纸面表现。
后来我才慢慢意识到,这两种沉迷表面上一个偏工程、一个偏研究,底层其实是同一种东西:
它们都在奖励我去优化“眼前可见的指标”,而不是“长期真实有效的能力”。
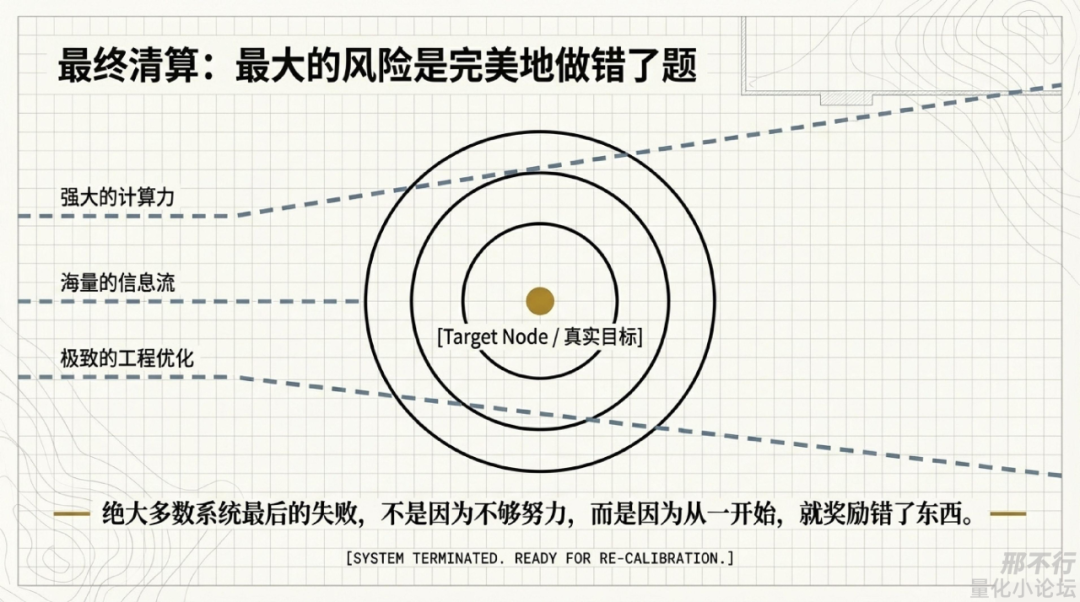
而一个量化人真正成熟,可能就从承认这一点开始,不是不会优化,恰恰相反,是太会优化了以后,终于开始警惕优化本身。
再往前走一步,我甚至会觉得也许人这一生最大的难题,不是算力不够,不是信息不够,不是工具不够;而是我们常常在一个错的目标函数上,投入了过于强大的优化能力。
市场里是这样,研究里是这样,做系统是这样,做人可能也是这样。
所以到最后,问题从来不只是“我怎样才能更强”,而是:我准备沿着什么样的奖励机制,把自己训练成什么样的人。
如果哪一天,AI也开始认真回答这个问题,那我和它真正的差别,可能就只剩最后一点了,它会不会像我一样,在优化到一半的时候,突然停下来,怀疑自己整个目标函数是不是设错了。
而如果连这一步它也会了,那接下来真正值得害怕的,可能就不是AI比我聪明,而是它比我更早看穿:绝大多数系统最后的失败,不是因为不够努力,而是因为从一开始,就奖励错了东西。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)