JVM 底层彻底理解
JVM 底层彻底理解
- 一、JVM 到底解决了什么问题(先理解本质)
- 二、JVM 整体架构(为什么要分这些模块)
- 三、运行时数据区(JVM 运行时内存结构)
- 四、对象从创建到回收的完整生命周期
- 五、垃圾回收机制(GC 底层原理)
- 六、内存泄漏
- 七、逃逸分析(JIT 的核心优化能力)
- 八、JVM 调优与问题排查
- 九、总结
- 十、JVM高频问题
-
- 10.1 对象为什么优先分配在 Eden,而不是一上来就进老年代?
- 10.2 什么对象会直接进入老年代?
- 10.3 对象晋升老年代的依据到底是什么?
- 10.4 为什么 Minor GC 频繁不一定危险,而 Full GC 频繁通常很危险?
- 10.5 什么情况下会触发 Full GC?
- 10.6 Stop-The-World 为什么不可避免?
- 10.7 G1 为什么能控制停顿时间?
- 10.8 JVM 为什么会出现“GC 很努力,但内存就是回不下来”?
- 10.9 类加载器为什么会导致内存泄漏?
- 10.10 ThreadLocal 为什么在线程池里特别危险?
- 10.11 为什么线上 CPU 飙高时,不能只盯着 GC?
- 10.12 频繁 Full GC 时,第一反应应该看什么?
- 10.13 JVM 调优为什么不能一上来就改参数?
- 10.14 为什么说“GC 问题很多时候不是 GC 本身的问题”?
- 10.15 本章总结
一、JVM 到底解决了什么问题(先理解本质)
在 JVM 出现之前:
-
C / C++ 需要手动管理内存
-
内存泄漏、野指针问题频发且难排查
-
程序强依赖操作系统,跨平台成本高
这些问题的共同点只有一个:
复杂、易错、不可控。
JVM 的本质目标只有三点
一句话先记住:隔离、托管、优化。
-
屏蔽底层操作系统差异
程序不再直接依赖操作系统,而是运行在 JVM 之上,实现“一次编写,到处运行”。
-
自动内存管理(GC)
对象创建、回收由 JVM 统一管理,开发者只关心“是否还在使用”,不再和内存细节纠缠。
-
通过运行期优化获得接近原生的性能
JVM 会在运行过程中识别热点代码并进行编译优化,长期运行下性能接近甚至等同原生程序。
核心结论
JVM 不是为了“极限快”,而是为了稳定、可控、可长期运行。
它本质上是一个:
以空间换安全、以运行期分析换性能
的工程系统。
二、JVM 整体架构(为什么要分这些模块)
JVM 不是一个黑盒,而是一个高度分层、职责清晰的系统:
ClassLoader → Runtime Data Area → Execution Engine
一句话理解这条链路:
先把类弄进来 → 给数据找地方 → 把代码跑起来
JVM 为什么要分这三层?
因为 JVM 要同时解决三类完全不同的问题:
加载、存储、执行。
-
类加载器(ClassLoader)
核心职责:把 class 文件变成 JVM 能用的 Class 对象
- 负责类的加载、校验、链接、初始化
- 支持按需加载,而不是一次性全部加载
- 通过双亲委派机制保证核心类安全
一句话记忆:
类加载器决定“类从哪来、能不能用”
高频点:
-
为什么需要双亲委派?
一句话答案:
防止核心类被篡改,保证类加载的安全性和一致性。
关键点:
- 优先由父加载器加载,避免自定义类覆盖
java.lang.* - 保证同一个类在 JVM 中的唯一性
- 优先由父加载器加载,避免自定义类覆盖
-
自定义 ClassLoader 的典型场景?
一句话答案:
隔离、扩展、动态加载。
典型场景:
- 插件化系统(不同插件使用不同依赖)
- 热加载 / 热部署
- 应用隔离(如 Tomcat、多应用容器)
-
运行时数据区(Runtime Data Area)
核心职责:给程序运行中的数据分配内存
- 方法区:类元数据、常量、静态变量
- 堆:对象实例
- 虚拟机栈 / 本地方法栈:方法调用、局部变量
- 程序计数器:线程执行位置
一句话记忆:
运行时数据区决定“数据放哪、生命周期多长”
高频点:
-
堆和栈的区别?
一句话答案:
堆存对象,栈存方法调用。
关键点:
- 堆:线程共享,GC 管理,对象实例
- 栈:线程私有,方法栈帧,自动回收
-
哪些区域线程私有,哪些线程共享?
一句话答案:
栈、程序计数器是私有的;堆和方法区是共享的。
记忆口诀:
“对象共享,调用私有”
-
OOM 和 StackOverflowError 的根源?
一句话答案:
OOM 是内存不够,SOF 是调用太深。
对应关系:
- OOM:堆、方法区内存耗尽
- StackOverflowError:递归或方法调用层级过深
-
执行引擎(Execution Engine)
核心职责:把字节码真正跑起来
- 解释执行:启动快
- JIT 编译:热点代码转为机器码
- 运行期优化:内联、逃逸分析、锁消除
一句话记忆:
执行引擎决定“怎么跑、跑得快不快”
高频点:
-
解释执行 vs JIT?
一句话答案:
解释执行启动快,JIT 执行快。
关键点:
- 解释执行:逐条解释字节码
- JIT:热点代码编译为机器码
-
什么是热点代码?
一句话答案:
被频繁执行、值得编译优化的代码。
关键点:
- JVM 通过计数器识别
- 热点才会触发 JIT
-
为什么 Java 能越跑越快?
一句话答案:
因为 JVM 会对热点代码持续做运行期优化。
核心逻辑:
- 先解释执行
- 再 JIT 编译
- 最终稳定在高性能状态
JVM 为什么一定要“拆模块”?
如果不拆,会出现三个致命问题:
- 类加载和内存强耦合,无法支持热加载
- 内存和执行强耦合,无法做运行期优化
- 执行逻辑固化,JIT、GC 无法演进
而拆分之后,JVM 获得了三种能力:
- 解耦:加载、存储、执行互不干扰
- 可扩展:ClassLoader、GC、JIT 都可替换
- 运行期优化:边跑边分析,动态决策
一句话总结
ClassLoader 负责“引入”
Runtime Data Area 负责“承载”
Execution Engine 负责“执行”
JVM 的所有高级特性(GC、JIT、热加载),
都建立在这三层解耦之上。
三、运行时数据区(JVM 运行时内存结构)
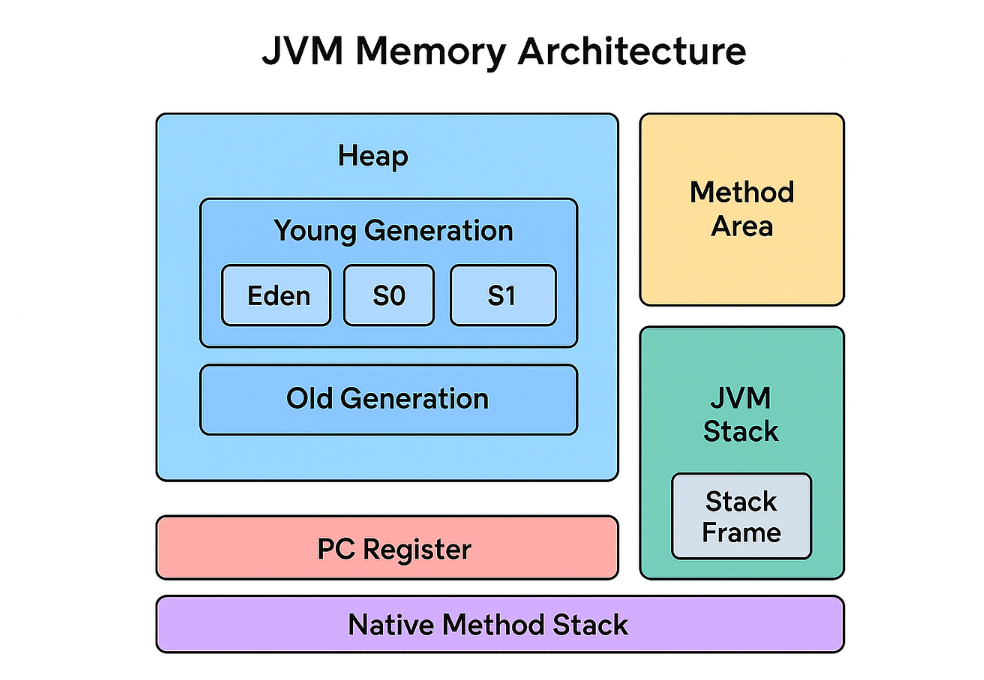
JVM 的运行时数据区不是随便划的,它直接决定了:
-
GC 怎么做
-
多线程是否安全
-
OOM 和 StackOverflowError 从哪来
JVM 内存只分两大类
一句话先记住:
-
线程私有:只和当前线程有关
-
线程共享:所有线程共同使用
这是理解 GC、并发安全、内存异常 的根本前提。
1. 程序计数器(最小,但不可或缺)
本质
- 记录当前线程正在执行的字节码位置
- 线程切换后能从正确位置继续执行
关键特点
- 线程私有
- 唯一不会发生 OOM 的内存区域
高频速答
-
为什么 Java 多线程切换不会乱?
一句话答案:
每个线程都有独立的程序计数器,保存自己的执行位置。
2. 虚拟机栈(排错最常见)
栈的基本单位:栈帧
每一次方法调用都会创建一个栈帧,包含:
-
局部变量表
-
操作数栈
-
动态链接
-
方法返回地址
局部变量表里有什么?
- 基本数据类型
- 对象引用(reference)
关键认知点:
对象在堆中,栈中只保存引用
两类典型异常(必须能区分)
-
StackOverflowError
-
方法递归过深
-
栈帧不断入栈,空间耗尽
-
-
OutOfMemoryError(与栈相关)
-
线程创建过多
-
每个线程都要分配栈空间
-
高频速答
-
栈为什么是线程私有的?
一句话答案:
方法调用链不能被多个线程共享,否则执行状态会混乱。
3. 本地方法栈(补充点)
-
为
native方法服务 -
HotSpot 中通常与虚拟机栈合并实现
主要存储 native 方法执行过程中使用的:
- 参数
- 局部变量
- 返回值
- JNI 调用相关的上下文信息
- 底层平台的调用状态。
一般不单独深挖,但要知道它属于线程私有。
native 方法是指:方法的实现不在 Java 代码中,而是由 Java 以外的语言(通常是 C / C++)实现的方法。
4. 堆(GC 的主战场)
堆的核心职责
-
存放对象实例
-
线程共享
-
GC 管理的主要区域
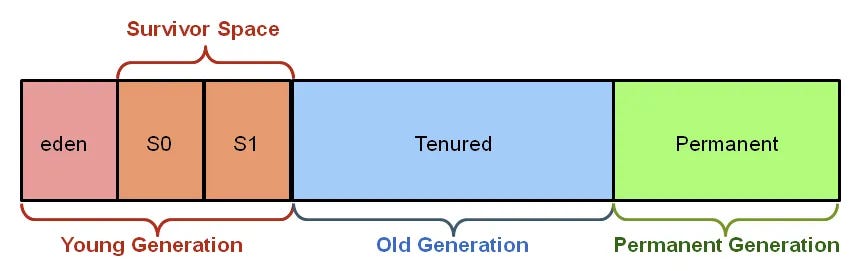
为什么堆要“分代”?
不是拍脑袋设计,而是基于一个长期统计结论:
绝大多数对象,存活时间非常短
因此 JVM 才采用分代模型来降低 GC 成本。
新生代结构与流转
新生代分为:
- Eden
- Survivor From
- Survivor To
对象流转路径:
Eden → S0 → S1 → Old
每次 Minor GC:
-
存活对象复制到 Survivor
-
年龄加 1
-
达到阈值后晋升老年代
老年代的特点
-
对象存活时间长
-
GC 次数少,但代价高
-
Full GC 的主要区域
高频速答
-
为什么 Minor GC 快,Full GC 慢?
一句话答案:
新生代对象少且易回收,老年代对象多且存活时间长。
5. 方法区 / 元空间(类的存储区)
JDK 8 的关键变化
-
移除永久代(PermGen)
-
引入 Metaspace(元空间)
为什么要这样改?
永久代的问题:
-
空间固定
-
容易 OOM
-
与堆强耦合
元空间的优势:
-
使用本地内存
-
可动态扩展
-
更适合大量类加载(如 Spring、动态代理)
高频点
-
为什么永久代被移除?
一句话答案:
避免固定大小限制,提升类加载场景下的稳定性。
总结
计数器保执行,切线程不乱
栈管调用,堆管对象
新生代快收,老年代慢清
类信息不进堆,进元空间
这套内存模型,直接支撑了:
- GC 设计
- 并发模型
- JVM 性能优化
四、对象从创建到回收的完整生命周期
常态:
“你 new 一个对象,JVM 到底干了什么?”
1. 对象创建全过程
标准五步,一步不能少:
-
类是否已加载
没加载先触发类加载(加载、链接、初始化)
-
分配内存
在堆中为对象分配空间
-
初始化零值
实例字段设置默认值(保证对象可用)
-
设置对象头
包含类指针、GC 信息、锁信息等
-
执行构造方法
按代码逻辑完成初始化
高配点
-
对象创建的完整过程?
一句话答案:
检查类 → 分内存 → 清零 → 设对象头 → 调构造方法
2. 内存分配方式(为什么有两种)
对象分配的前提是:
堆内存是否连续。
-
指针碰撞
适用场景:
- 堆内存连续
- 如 Serial、ParNew 收集器
做法:
- 维护一个指针
- 分配时指针向前移动
特点:
- 实现简单
- 分配速度快
-
空闲列表
适用场景:
- 堆内存不连续
- 如 CMS、G1
做法:
- 维护可用内存块列表
- 从合适位置分配
特点:
- 灵活
- 维护成本更高
高频点
-
指针碰撞和空闲列表的区别?
一句话答案:
是否要求堆内存连续。
3. 对象创建为什么是线程安全的?
因为对象创建发生在多线程并发环境下。
JVM 主要提供两种方案:
-
方案一:CAS + 重试
- 通过原子操作更新内存指针
- 失败则重试
优点:通用
缺点:高并发下有性能损耗 -
方案二:TLAB(线程本地分配缓冲区)(默认)
Thread Local Allocation Buffer
核心思想:
- 每个线程在堆中预分配一小块内存
- 线程内对象分配无需加锁
特点:
- 无锁
- 分配速度快
- 大多数对象直接在 TLAB 中完成分配
高频点
-
JVM 默认是否开启 TLAB?
一句话答案:
是的,默认开启,用于提升对象分配效率。
五、垃圾回收机制(GC 底层原理)
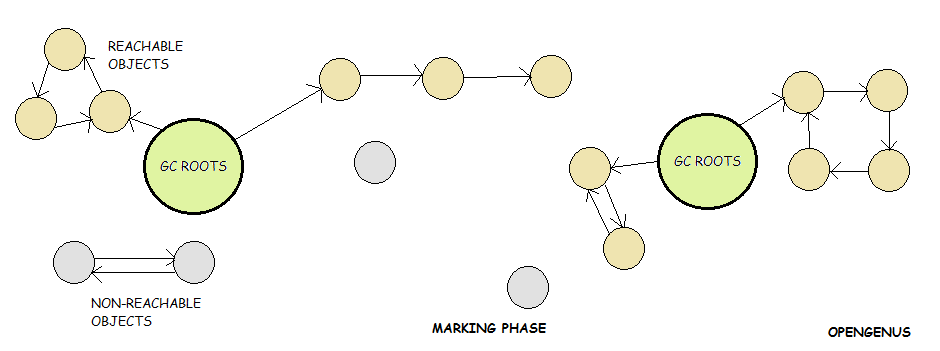
GC 的核心只解决三件事:
对象死没死 → 怎么回收 → 何时回收得更优
1. 如何判断对象已死?
为什么不用引用计数?
引用计数的问题只有一句话:
循环引用无法回收
两个对象互相引用,但外部已不可达,
引用计数不为 0,却早该被回收。
JVM 的标准答案:可达性分析
核心思想:
从一组“必然存活”的对象出发,看能不能走到目标对象。
这组起点,叫 GC Roots。
常见 GC Roots
- 虚拟机栈中的引用
- 类静态变量
- 常量池中的引用
- JNI(本地方法)引用
结论规则:
从 GC Roots 不可达的对象,才是可回收对象
高频点
-
JVM 如何判断对象是否可回收?
一句话答案:
通过 GC Roots 做可达性分析,不可达即回收。
2. GC 算法为什么要“组合使用”?
因为不同区域的对象特性完全不同。
-
新生代:复制算法
特点:
-
对象存活率低
-
回收频繁
优势:
- 只复制存活对象
- 回收速度快
代价:
- 需要额外空间(Survivor)
-
-
老年代:标记-整理算法
特点:
- 对象存活率高
- 不能频繁移动
优势:
- 避免内存碎片
- 适合长期存活对象
代价:
- 回收成本高
核心结论
没有万能 GC 算法,只有场景最优组合。
高频点
-
为什么新生代和老年代用不同算法?
一句话答案:
因为对象存活率不同,回收策略必须不同。
3. G1 垃圾回收器(主流)
G1 的出现,本质是为了解决一个问题:
在大堆内存下,如何控制 GC 停顿时间?
G1 的核心设计思想
- 把整个堆拆成多个 Region
- Region 可以是新生代,也可以是老年代
- 不再固定按代整体回收
一句话理解:
不按“代”收,按“价值”收
什么是“回收价值”?
综合考虑:
-
Region 中垃圾比例
-
回收收益
-
回收成本
优先回收 性价比最高 的 Region。
为什么 G1 停顿时间可控?
核心原因只有两点:
-
每次只回收部分 Region
-
可以根据目标停顿时间做回收计划
这也是 G1 名字的来源:
Garbage First(优先回收垃圾最多的区域)。
高频点
-
G1 为什么能控制停顿时间?
一句话答案:
通过 Region 化和按回收价值选择回收范围。
总结
-
死没死看 Roots
-
算法选型看存活率
-
G1 不按代,按价值收
六、内存泄漏
1. 内存泄漏的本质定义
一句话定义:
对象已经没有业务意义,但仍然被 GC Roots 间接或直接引用。
关键点要说清楚:
-
不是“内存不够”
-
而是引用关系断不开
-
GC 按规则工作,但规则失效于设计错误
高频点
-
什么是内存泄漏?
一句话答案:
对象该死但没死,因为还在 GC Roots 引用链上。
2. 常见泄漏场景的底层原因
-
静态引用(最基础)
为什么会泄漏?
- 静态变量生命周期 = JVM 生命周期
- 天然属于 GC Roots
一旦静态集合、静态缓存不断增长:
对象永远不可回收
高频点
-
为什么静态变量容易导致内存泄漏?
一句话答案:
因为它们是 GC Roots,生命周期过长。
-
ThreadLocal 泄漏
问题不在 ThreadLocal,而在线程池。
底层结构:
- key:ThreadLocal(弱引用)
- value:业务对象(强引用)
当:
- ThreadLocal 被回收
- 线程长期存活(线程池)
结果:
value 仍被线程引用,无法回收
正确姿势(必须说)
- 使用后 finally 中调用 remove()
高频点
-
ThreadLocal 为什么会内存泄漏?
一句话答案:
线程不结束,value 强引用还在。
-
连接、流未关闭
典型对象:
- JDBC 连接
- Socket
- IO 流
问题本质:
- 不仅占 JVM 堆
- 还占用 操作系统资源
这种泄漏,往往比 OOM 更危险。
高频点
-
为什么流不关闭问题严重?
一句话答案:
既泄漏内存,又泄漏系统资源。
3. 内存泄漏与 OOM 的关系
一句话因果关系:
内存泄漏是原因,OOM 是最终结果。
- 少量泄漏 → 系统还能撑
- 长期泄漏 → 必然 OOM
高频点
OOM 往往不是“突然发生”,
而是泄漏长期积累的必然结果。
七、逃逸分析(JIT 的核心优化能力)
让 JVM 判断“对象需不需要进堆”。
1. 什么是逃逸?
标准定义:对象是否可能被方法之外访问。
不逃逸的典型特征
-
只在方法内部使用
-
不作为返回值
-
不赋值给外部变量
一句话记忆:
出不了方法的对象,就是不逃逸。
高频点
-
什么是逃逸分析?
一句话答案:
JVM 判断对象作用域是否超出方法范围。
2. JVM 为什么关心“逃逸”?
因为一旦确认 不逃逸:
对象就没必要进堆。
直接收益:
-
减少堆内存分配
-
减少 GC 压力
-
提升整体性能
高频点
-
逃逸分析的核心目的是什么?
一句话答案:
减少对象进入堆,从而减少 GC。
3. 三大核心优化
1. 栈上分配
结论型描述:
- 对象直接分配在栈上
- 方法结束自动销毁
- 不参与 GC
适用前提:
- 对象不逃逸
高频点
-
什么是栈上分配?
一句话答案:
不逃逸对象直接在栈上分配。
JVM 在逃逸分析后,不再创建对象, 而是把对象字段拆成标量,可能分布在栈帧、操作数栈甚至寄存器中。
2. 标量替换(优化力度最大)
核心思想:
对象可以拆,就没必要存在。
做法:
- 把对象拆成多个基本类型变量
- 对象本身彻底消失
效果:
- 零对象创建
- 零 GC 压力
高频点
-
什么是标量替换?
一句话答案:
把对象拆成基本类型,彻底消除对象。
3. 锁消除
适用场景:
-
锁对象不逃逸
-
没有多线程竞争
JIT 判断后:
直接移除 synchronized 锁。
高频点
-
JVM 为什么能安全地消除锁?
一句话答案:
因为逃逸分析确认不存在并发访问。
总结
逃不逃,看范围
不进堆,GC 少
栈分配、标量换、锁直接消
八、JVM 调优与问题排查
1. 常见 OOM 类型(先会分类)
-
Java heap space一句话含义:
堆中对象过多,GC 回收不过来。
常见原因:
- 内存泄漏
- 大对象加载
- 缓存无限增长
-
Metaspace一句话含义:
类加载太多,元空间被打满。
常见原因:
- 动态代理 / CGLIB 过多
- 类加载器无法回收
- 热部署、插件化使用不当
-
GC overhead limit exceeded
一句话含义:
GC 拼命干活,但几乎回收不到内存。
本质判断:
系统已经处在“濒死状态”
高频点
-
OOM 常见有哪些类型?
一句话答案:
堆、元空间、GC 过载。
2. 排查 OOM 的标准流程
这一步比“调参”重要十倍。
标准四步法
-
确认 OOM 类型
先判断是堆、元空间,还是 GC 问题
-
Dump 内存快照
OOM 时或手动触发 Heap Dump
-
分析对象引用链
找出占用最多、不可回收的对象
-
定位代码根因
回到代码,解决引用问题,而不是只扩容
高频点
-
线上 OOM 你怎么排查?
一句话答案:
先定类型,再看 Dump,最后回到代码。
3. 常用 JVM 排查工具
不要求你精通,但必须知道用来干什么。
-
jps-
查看 JVM 进程
-
快速确认目标进程 ID
一句话:
找 JVM 进程用的。
-
-
jstack-
查看线程栈
-
排查死锁、线程阻塞
一句话:
看线程状态。
-
-
jmap- Dump 堆内存
- 查看对象分布
一句话:
看堆里的对象。
-
jvisualvm- 图形化监控
- 内存、线程、GC 情况
一句话:
本地/测试环境快速分析。
-
arthas- 线上诊断
- 方法调用、参数、返回值
- 无需重启
一句话:
线上救火神器。
总结
OOM 先分型
排查四步走
jstack 看线程,jmap 看对象,arthas 救线上
九、总结
-
JVM 不是简单的虚拟机,而是一个持续做运行期优化的系统
-
GC 的本质不是“回收内存”,而是分析对象之间的引用关系
-
内存泄漏不是没 GC,而是对象仍在 GC Roots 引用链上
-
逃逸分析是 JIT 性能优化的前提,没有它就没有高效优化
-
G1 通过 Region 化和按价值回收,成为当前服务端主流选择
十、JVM高频问题
10.1 对象为什么优先分配在 Eden,而不是一上来就进老年代?
问题:
既然对象最终都可能进入老年代,为什么 JVM 不直接把对象放到老年代?
解答:
因为 JVM 的一个核心经验假设是:
绝大多数对象,生命周期都很短
也就是说,很多对象只是:
- 方法里临时创建
- 请求处理中短暂使用
- 一轮计算后立刻失效
如果这些对象一开始就进入老年代,会带来两个问题:
- 老年代膨胀过快
- Full GC 压力明显增大
而新生代恰恰就是为“短命对象”设计的:
- 分配快
- 回收频繁
- 大量对象可以一次性清掉
所以对象优先进入 Eden,本质上是在做一件事:
让短命对象尽量死在便宜的区域里
这就是分代回收的价值。
重点结论:
对象优先进入 Eden,不是流程规定,而是因为“先放在便宜、适合快速回收的地方”成本最低。
10.2 什么对象会直接进入老年代?
问题:
是不是所有对象都必须经历 Eden → Survivor → Old 的过程?
解答:
不是。
虽然大多数对象都会先进入新生代,但在某些场景下,对象可能直接进入老年代。
常见情况有三类:
-
大对象
比如特别大的数组、超大的字节缓冲区。
因为这类对象如果先放到 Eden,再复制多次,成本太高。 -
长期存活对象晋升
对象经过多次 Minor GC 仍然存活,达到晋升年龄阈值后进入老年代。 -
Survivor 放不下
如果 Survivor 区空间不足,部分对象可能提前晋升。
所以对象进入老年代,不一定代表“它很老”,有时只是:
继续在新生代折腾成本更高
重点结论:
老年代不只是“老对象存储区”,也可能是“大对象”或“提前晋升对象”的承载区。
10.3 对象晋升老年代的依据到底是什么?
问题:
对象什么时候会从新生代进入老年代?
解答:
最常见的依据是:
年龄
每次对象在 Minor GC 后仍然活着,年龄就会加 1。
当年龄达到阈值时,就会晋升到老年代。
这个阈值并不是死板固定地只看一个参数,因为 JVM 还可能做:
- 动态年龄判断
也就是说,如果 Survivor 里某个年龄及以上的对象总大小,已经超过 Survivor 一半,那么这批对象可能提前晋升。
这样做的目的,是避免 Survivor 区反复挤压、复制成本过高。
重点结论:
对象晋升不只是“活够次数”,还取决于 Survivor 的空间压力和整体复制成本。
10.4 为什么 Minor GC 频繁不一定危险,而 Full GC 频繁通常很危险?
问题:
GC 一多是不是就说明 JVM 有问题?
解答:
不能一概而论。
Minor GC
新生代回收,本来就会比较频繁。
如果:
- 回收时间短
- 回收后空间释放明显
- 对业务线程影响可控
那 Minor GC 多一点并不一定是坏事。
Full GC
Full GC 通常意味着:
- 回收范围更大
- 停顿更长
- 代价更高
如果 Full GC 频繁,通常意味着以下几类问题:
- 老年代压力过大
- 对象晋升过快
- 大对象太多
- 内存泄漏
- 配置不合理
- 元空间压力过高
所以 JVM 调优里,一个非常关键的判断是:
不是看 GC 有没有,而是看它回收得值不值、停顿重不重、频率高不高
在压测引擎实践中也明确提到,Full GC 频繁会直接导致压测曲线波动、QPS 压不上去。
重点结论:
Minor GC 频繁不一定有问题,但 Full GC 频繁通常说明内存结构或对象生命周期已经失衡。
10.5 什么情况下会触发 Full GC?
问题:
线上一旦出现 Full GC,通常意味着什么?
解答:
Full GC 不会无缘无故出现,常见触发条件通常有这些:
- 老年代空间不足
- 大对象或晋升对象放不下
- 显式调用
System.gc() - 元空间不足
- 某些收集器在回收失败后退化为 Full GC
- 老年代碎片严重,无法分配连续空间
对于 G1 来说,还要特别注意一种情况:
- 本来希望做可控停顿回收
- 但回收赶不上分配速度
- 最后可能退化为 Full GC
这也是很多线上服务最怕的场景之一。
重点结论:
Full GC 通常不是“正常回收动作”,而是 JVM 在告诉你:某个区域已经撑不住了。
10.6 Stop-The-World 为什么不可避免?
问题:
GC 为什么一定要 Stop-The-World?不能边跑业务边完全无停顿回收吗?
解答:
因为 GC 要先回答一个前提问题:
哪些对象还活着?
而对象引用关系在多线程程序里是持续变化的。
如果你在回收过程中,业务线程还在不断修改对象图,就会出现两个问题:
- 刚判断完对象可达性,引用关系又变了
- 回收结果可能不一致,甚至误删活对象
所以 JVM 必须在某些关键阶段让用户线程停下来,至少保证:
- 对象图在这一刻是稳定的
- Roots 枚举是可靠的
- 某些关键标记阶段可以安全完成
不同收集器只是:
- 缩短 STW
- 拆散 STW
- 把更多工作挪到并发阶段
而不是“完全消灭 STW”。
Oracle 的 G1 调优文档也强调,G1 的目标是控制停顿时间,不是让停顿彻底消失。
重点结论:
STW 不是 JVM 设计得不够先进,而是垃圾回收要获得一致对象视图时必须支付的代价。
10.7 G1 为什么能控制停顿时间?
问题:
为什么大家常说 G1 “停顿可控”?
解答:
因为 G1 不再像传统分代收集器那样,固定对一整块区域做统一回收。
它的核心变化是:
把堆拆成很多 Region,再按收益优先选择回收集合
这带来两个关键能力:
- 每次不必回收整个新生代或整个老年代
- 可以根据目标停顿时间,控制本轮回收多少 Region
所以 G1 的“可控”不是说:
- 它一定很快
- 它一定没有长停顿
而是说:
它会尽量按照你给的停顿目标做回收计划
当然,这只是“尽量”,不是绝对保证。
如果分配速度太快、活对象太多、回收赶不上分配,G1 也可能失控,甚至退化。
重点结论:
G1 的核心优势不是“绝对低延迟”,而是“基于 Region 和收益模型,尽量把停顿控制在目标范围内”。
10.8 JVM 为什么会出现“GC 很努力,但内存就是回不下来”?
问题:
有时候 GC 很频繁,但堆占用还是居高不下,这说明什么?
解答:
这通常意味着两种可能。
第一种:对象真的还活着
比如:
- 缓存还在引用
- 会话对象还在引用
- 线程池任务链还在引用
- 静态集合持续持有对象
GC 不能回收,不是因为它没工作,而是因为:
这些对象从 GC Roots 出发仍然可达
第二种:发生了内存泄漏或接近泄漏
典型特征是:
- Full GC 后内存回落很少
- 老年代占用一直升高
- 时间越久越严重
这时经常会出现:
GC overhead limit exceeded- Full GC 越来越频繁
- 最终 OOM
重点结论:
GC 回不下来,不代表 GC 差,往往意味着对象生命周期设计出了问题。
10.9 类加载器为什么会导致内存泄漏?
问题:
通常说内存泄漏,大家先想到的是“某个对象没被释放”。
那类加载器为什么也会导致内存泄漏?它泄漏的到底是什么?
解答:
类加载器当然也是对象,但它特殊在于:它不是一个普通对象,而是很多运行时资源的“入口”和“归属者”。
一个类一旦被某个 ClassLoader 加载,和这个类相关的一整套运行时数据,通常都会跟这个类加载器绑定在一起,例如:
Class元数据- 方法元数据
- 静态变量
- 运行时常量池
- 反射缓存
- 注解信息
- 动态生成的代理类
Thread ContextClassLoader关联资源- 某些框架内部缓存
所以一旦类加载器本身回收不掉,它加载过的这一批类及其关联资源往往也很难释放,最终就形成了内存泄漏。
为什么会“泄漏一大片”?
因为 GC 判断对象能不能回收,看的是引用链是否还连着。
只要还有某个地方强引用着这个类加载器,比如:
- 某个静态集合里还存着它加载的对象
- 某个线程还在跑,线程上下文 ClassLoader 还是旧的
- 某个
ThreadLocal没清理 - 某个 JDBC Driver、SPI 实现、日志组件还注册着
- 某个缓存框架把旧类的
Class或实例缓存住了
那么这个类加载器就不能回收。
而类加载器不能回收,就意味着:
- 它加载的类不能回收
- 这些类的静态字段不能回收
- 这些类关联的反射信息、代理类、元数据也不能回收
所以类加载器泄漏最麻烦的地方就在于:
泄漏的不是一个对象,而是一整批类和它们背后的资源。
常见发生场景
这类问题最常出现在“类会被反复加载”的场景里:
- 热部署
- Tomcat / Spring Boot DevTools 反复重启
- OSGi / 插件化架构
- 脚本引擎、动态模块加载
- 动态代理或字节码增强频繁生成类
- 应用服务器反复发布/卸载 Web 应用
这些场景里,系统往往会创建新的类加载器来加载新版本代码。
如果旧类加载器因为某些引用没断开,就会一直残留在内存里。
随着反复部署:
- 旧类加载器保留一份旧类
- 新类加载器再加载一份新类
- 一轮轮叠加
最终就会出现:
Metaspace持续增长- Full GC 频繁但回收效果差
- 多次重启后内存越来越高
- 最后出现
OutOfMemoryError: Metaspace
为什么它不只是元空间问题?
很多人会觉得类加载器泄漏只会影响 Metaspace,其实不止。
因为类加载器加载的类可能还关联着堆里的对象,比如:
- 静态缓存中的大对象
- 单例 Bean
ThreadLocal中的业务数据- 连接池、线程池、监听器等资源对象
所以类加载器泄漏经常会表现为:
Metaspace增长- Java 堆也增长
- GC 压力变大
- 卸载类效果很差
也就是说,它既可能拖住类元数据,也可能拖住普通堆对象。
一个典型例子
比如 Web 容器里部署了一个应用,容器给它分配了一个独立的 WebAppClassLoader。
应用停止时,本来这个类加载器应该被回收。
但如果应用里有一个线程池中的线程一直没停,而且线程的 contextClassLoader 还指向这个旧的 WebAppClassLoader,那么:
- 线程活着
- 线程引用着旧类加载器
- 旧类加载器引用着它加载的所有类
- 所有这些类的静态数据和相关资源也一起活着
结果就是:应用虽然“卸载”了,但内存里的那一套东西其实还在。
重点结论
类加载器导致内存泄漏,本质上不是因为“类很多”,而是因为:
旧类加载器本该随着旧应用一起回收,但由于引用链没有断开,导致它以及它加载的整套类和资源都无法释放。
所以排查这类问题时,真正要看的不是“哪个对象大”,而是:
- 哪个类加载器还活着
- 谁在引用它
- 哪些线程、静态变量、缓存、注册表没有清理
10.10 ThreadLocal 为什么在线程池里特别危险?
问题:
ThreadLocal 明明是线程隔离工具,为什么却经常和内存泄漏一起出现?
解答:
因为 ThreadLocal 最大的问题不是“线程本地”,而是:
线程活得太久
在线程池场景里,线程通常不会结束。
而 ThreadLocalMap 的结构特点又是:
- key 是弱引用
- value 是强引用
如果:
- ThreadLocal 对象本身没了
- 但线程还活着
- 又没有及时
remove()
那 value 就可能继续留在这个线程里。
于是你会看到:
- 单次请求看不出问题
- 长时间运行后内存慢慢涨
- Full GC 也回不掉
这也是很多线上服务里特别常见的隐性问题。
重点结论:
ThreadLocal 真正危险的不是“线程隔离”,而是“线程池线程长期存活,导致 value 被长期挂住”。
10.11 为什么线上 CPU 飙高时,不能只盯着 GC?
问题:
服务 CPU 一高,很多人第一反应就是“是不是 GC 出问题了”,这为什么不够?
解答:
因为 CPU 飙高可能来自很多地方,GC 只是其中一种。
常见来源包括:
- GC 线程忙
- 业务线程死循环
- 锁竞争导致自旋
- JIT 编译线程活跃
- 日志刷太猛
- 第三方库异常行为
- 频繁异常创建和堆栈打印
所以排查 CPU 飙高时,正确顺序通常是:
- 先看进程级 CPU
- 再看线程级 CPU
- 用
jstack对高 CPU 线程做栈分析 - 再判断是 GC、业务线程还是其他后台线程
这也是为什么很多大厂线上排障并不是一上来就看堆,而是:
先分清楚“谁在烧 CPU”
重点结论:
CPU 飙高不等于 GC 异常,真正关键的是先定位“高 CPU 的线程是谁”。
10.12 频繁 Full GC 时,第一反应应该看什么?
问题:
线上如果频繁 Full GC,最先应该检查什么?
解答:
不要一上来就调参数。
更有效的顺序通常是:
- 看老年代占用是否持续上升
- 看 Full GC 后内存是否明显回落
- 看是否存在大对象、缓存堆积、静态集合
- 看是否有长事务、长生命周期对象
- 看是否发生类加载膨胀或元空间压力
- 结合 Heap Dump 找真正的大对象引用链
其中最关键的判断是:
Full GC 后到底回没回下来
如果回得下来,说明更多是对象分配和代际配置问题。
如果回不下来,说明更像:
- 内存泄漏
- 生命周期过长
- 不合理缓存
- ThreadLocal / ClassLoader 问题
重点结论:
频繁 Full GC 最重要的不是“次数多”,而是“回收之后到底释放了多少”。
10.13 JVM 调优为什么不能一上来就改参数?
问题:
很多人一看到 GC 问题就开始改 -Xmx、改收集器、改暂停目标,这为什么经常没用?
解答:
因为 JVM 参数只是放大器,不是根因修复器。
如果真正的问题是:
- 内存泄漏
- ThreadLocal 没清
- 缓存无限增长
- 类加载器泄漏
- 业务对象生命周期设计错误
那你把堆调大,只会让问题晚一点爆。
所以 JVM 调优真正正确的顺序通常是:
-
先确认现象
是 OOM、频繁 GC、长停顿,还是 CPU 飙高 -
再确认区域
是堆、元空间、直接内存、线程栈,还是 Code Cache -
再找对象或线程证据
Heap Dump、线程栈、NMT、GC 日志 -
最后才考虑调参数
用参数去适配业务,而不是拿参数掩盖问题
重点结论:
JVM 调优不是“会背参数”,而是“先找根因,再决定参数有没有必要动”。
10.14 为什么说“GC 问题很多时候不是 GC 本身的问题”?
问题:
线上一旦出现 GC 抖动,为什么很多有经验的人第一反应不是换 GC?
解答:
因为 GC 常常只是结果,不是根因。
GC 抖动背后的真实来源,往往是这些:
- 对象创建过快
- 缓存设计失控
- 大对象太多
- 长生命周期对象过多
- ThreadLocal 没清
- 类加载器泄漏
- 业务流量模型变化
也就是说:
GC 只是把“对象分配和生命周期问题”表现出来了
如果你只是换收集器,而不处理对象模型问题,那么通常只会:
- 暂时缓解
- 不会根治
在 CMS 和 ZGC 的实践文章里,也都强调了一个共同点:
真正影响停顿和 GC 表现的,不只是回收器本身,更是业务对象分布、存活比例和分配速率。
重点结论:
很多 GC 问题表面上是“回收器表现差”,本质上其实是“对象生命周期设计失衡”。
10.15 本章总结
JVM 相关问题看起来很多,但本质上都可以归纳为几类:
- 对象分配首先是生命周期问题,不是单纯内存空间问题
- Minor GC 和 Full GC 的意义完全不同,不能混着看
- STW 不是异常,而是 GC 获得一致对象视图的必要代价
- G1 的核心不是“绝对低延迟”,而是“按 Region 收、尽量控停顿”
- 内存泄漏不是 GC 失效,而是对象引用链没有断开
- ThreadLocal 和类加载器泄漏,是线上最隐蔽也最常见的两类 JVM 问题
- CPU 飙高、频繁 GC、内存上涨,背后根因往往不是 JVM 参数,而是对象生命周期和引用关系设计问题
- JVM 调优真正难的地方,不在参数,而在根因定位
JVM 真正难的地方,不在于:
- 会不会背 Eden、Survivor、Old
- 会不会说 G1、CMS、ZGC
- 会不会列几条调优参数
而在于你能不能真正看清:
- 对象为什么活得太久
- GC 为什么回不动
- Full GC 为什么会发生
- 停顿为什么会拉长
- 类和线程为什么把内存拖住
- 线上现象背后到底是谁在制造压力
最终核心结论:
JVM 的使用难点,不在概念,而在于你能不能站在“对象分配、对象存活、GC 回收、类加载、线程生命周期”这几个层面,真正理解它为什么快、为什么慢、以及为什么会出问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)