一文看懂 Transformer
序言
我们平时和计算机打交道,很多时候都离不开文本,比如聊天、搜索、问答、写总结。
可是计算机其实并不真正懂“字”的意思,它看到的只是符号和数据。
于是,人们就会想:
能不能让机器像人一样去处理语言,理解一句话在说什么,甚至自己生成一段话?
围绕这个问题,就逐渐形成了一个专门的研究领域,叫做 自然语言处理(NLP)。
在 NLP 的发展过程中,人们提出过很多模型来让机器更好地处理文本,比如 RNN、LSTM 和 Transformer。
其中,Transformer 可以说是近些年最重要的模型之一。
今天的大语言模型,比如 GPT、BERT、ChatGPT,背后都和 Transformer 有非常深的关系。
那么,Transformer 到底是什么?它为什么会出现?又为什么这么重要?
这篇文章我们就从头梳理一遍。
为什么处理文本比想象中更难?
计算机处理文本和处理图片是不一样的。
图片更多是空间上的信息,而文本天然带有顺序。
比如下面两句话:
- 我喜欢你
- 你喜欢我
它们用到的字几乎一样,但因为顺序不同,表达的意思却完全不一样。
所以,机器在处理文本时,不仅要知道“有哪些词”,还要知道:
- 这些词出现的顺序
- 它们之间的上下文关系
- 哪些词和哪些词联系更紧密
基于这个想法,早期人们提出了 RNN(循环神经网络)。
RNN:最早的顺序建模方式
RNN 的核心思路很直观:
按照文本的顺序,一个词一个词地处理,并把前面读到的信息传递给后面。
比如这句话:
我今天去公司上班
RNN 的处理顺序大致就是:
我 → 今天 → 去 → 公司 → 上班
这样一来,模型在处理当前词时,就不再只是孤立地看这个词,而是会结合前面已经读过的内容一起理解。
这种方式让机器第一次真正具备了“按顺序理解文本”的能力,因此在很长一段时间里,RNN 都是自然语言处理中的重要模型。
但是,RNN 也有明显的问题:
- 训练速度慢,并行能力差
因为它必须一个词一个词按顺序处理,后面的计算要等前面的计算结束之后才能开始。 - 长距离依赖建模困难
当句子很长时,前面的一些重要信息在不断传递的过程中可能会逐渐减弱。 - 训练时容易出现梯度消失或梯度爆炸
这也会影响模型对长文本的学习能力。
于是,人们又提出了 LSTM(长短期记忆网络)。
LSTM:对 RNN 的改进
LSTM 可以看成是 RNN 的改进版。
它在 RNN 的基础上加入了记忆控制机制,可以决定:
- 哪些信息需要保留
- 哪些信息可以遗忘
- 哪些信息应该传递到后面
因此,相比普通 RNN,LSTM 更擅长处理长文本,也能在一定程度上缓解长距离信息丢失的问题。
但是,LSTM 虽然改进了记忆能力,却没有解决一个根本问题:
它仍然是按顺序一个词一个词往后处理的。
这就意味着,它的并行能力依然不强,训练效率依然受限。
为什么会出现 Transformer?
前面我们说到,RNN 让机器第一次能够按顺序处理文本,LSTM 又在 RNN 的基础上增强了记忆能力。
但是,它们始终没有摆脱一个核心限制:
处理方式仍然是串行的。
这会带来两个明显问题。
第一,并行能力差,训练速度慢
因为模型在处理第 2 个词时,要先等第 1 个词处理完;处理第 3 个词时,又要等第 2 个词处理完。
当数据量很大、模型很深的时候,这种串行方式会让训练效率明显下降。
第二,长文本中的远距离关系不容易捕捉
虽然 LSTM 比普通 RNN 更擅长记忆,但当句子特别长时,前面的一些关键信息在不断传递的过程中仍然可能逐渐减弱。
比如一句很长的话里,前面出现的人名、地点或者主语,到后面就不一定还能被准确关联上。
于是,人们开始思考一个新的问题:
我们可不可以不再一个词一个词慢慢传递信息,而是让句子里的每个词直接去看和自己相关的其他词呢?
基于这个想法,Transformer 出现了。
Transformer 最核心的变化是:
不再依赖循环结构,而是把注意力机制(Attention)作为核心计算方式。
需要说明的是,Attention 并不是 Transformer 首次提出的。
Transformer 真正的重要之处在于:
- 抛弃了 RNN 的循环结构
- 用 Self-Attention 作为核心
- 更适合并行训练
- 更擅长建模长距离依赖
注意力机制到底是什么?
注意力机制可以先简单理解成一句话:
模型在处理一个词的时候,可以同时去关注句子中的其他词,并判断哪些词更重要。
生活里也有点像这样:
老师说了一整句话,当你听到某个词时,你不会只盯着这个词本身,而是会自然地联系前后文,看看它和哪些词最相关。
比如这句话:
小明没去上学,因为他发烧了。
这里的“他”指的是谁?
如果模型只能按顺序一个一个传递信息,理解起来会比较吃力;
但如果用注意力机制,当模型看到“他”这个词时,它就可以去看前面的词:
- 是“小明”更相关?
- 还是“上学”更相关?
- 还是“发烧”更相关?
最后模型会发现,“他”和“小明”的关系最强,于是就更容易理解这句话。
所以,注意力机制最核心的思想就是:
不是平均地看所有词,而是有重点地关注和当前词最相关的内容。
在 Transformer 中,最关键的不是普通的注意力,而是一种作用在同一句子内部的注意力机制,也就是 Self-Attention(自注意力机制)。
什么是 Self-Attention?
Self-Attention 可以简单理解成:
一句话里的每个词,在理解自己时,都会去看看这句话里的其他词。
也就是说,模型在处理某个词的时候,不会只盯着这个词本身,而是会结合整句话里和它有关的词,一起理解它的意思。
比如这句话:
我今天在公司开会。
当模型处理“开会”这个词时,它可能会去关注:
- “我”,表示是谁在开会
- “今天”,表示什么时候开会
- “公司”,表示在哪里开会
这样一来,“开会”这个词在模型里的表示,就不再只是“开会”两个字本身,而是带上了整句话里的上下文信息。
所以,自注意力机制本质上可以理解成:
让每个词都能站在全句的角度,重新理解自己。
Self-Attention 到底是怎么计算的?
要理解 Self-Attention,首先要知道它的三个核心概念:
- Query(查询向量)
- Key(键向量)
- Value(值向量)
1. Query、Key、Value 是什么?
Transformer 会把每个词映射成三个向量:
- Query:我现在想找什么信息
- Key:我身上有什么特征,适不适合被关注
- Value:如果你关注我,我能提供什么信息
你也可以这样理解:
- Query 是“我要找谁”
- Key 是“我适不适合被你找到”
- Value 是“如果你找到我,我能给你什么内容”
2. 计算过程是什么?
当模型处理某个词时,会拿这个词的 Query 去和句子中所有词的 Key 做匹配,得到一个相关性分数。
这个分数越高,说明当前词和那个词越相关。
然后,模型会把这些分数归一化,变成权重,再对所有词的 Value 做加权求和,最后得到当前词新的表示。
所以,Self-Attention 的本质就是:
先算“我该关注谁”,再按关注程度把信息加权汇总。
如果用公式表示,就是:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q, K, V)=\text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dkQKT)V
这条公式可以拆开理解。
QKTQK^TQKT 是什么?
它用来计算 Query 和 Key 之间的匹配程度,也就是每个词对其他词的关注分数。
在矩阵形式下,它得到的是一个“词与词之间相关性”的分数矩阵。
为什么要除以 dk\sqrt{d_k}dk?
这里的 dkd_kdk 表示 Key 向量的维度。
之所以要除以 dk\sqrt{d_k}dk,是因为如果向量维度太大,点积结果可能会很大,导致 softmax 后的分布过于极端,不利于训练稳定。
softmax 的作用是什么?
softmax 会把相关性分数归一化成一组权重,这些权重加起来等于 1。它表示当前词应该把多少注意力分配给其他词。
最后的 VVV 是什么作用?
最后再用这些权重对所有 Value 做加权组合,得到当前词融合上下文后的新表示。
所以,Self-Attention 的整个过程可以概括成一句话:
算相关性 → 分配权重 → 聚合信息
为什么还需要 Multi-Head Attention?
前面我们讲的 Self-Attention,可以理解成:
每个词都会去看看句子里的其他词,判断谁和自己更相关,然后把这些信息加权汇总起来。
但是,这里会出现一个新的问题:
如果只做一次注意力计算,模型是不是就只能从一个角度去理解句子?
答案是:是的。
一句话里的词和词之间,通常不只存在一种关系。
有的关系是“谁做了什么”,有的关系是“时间和动作的关系”,有的关系是“地点和事件的关系”,还有的关系是“代词指代谁”。
比如这句话:
小明今天在公司给客户发邮件,因为他要确认方案。
当模型看到“他”这个词时,它可能需要同时关注很多不同的信息:
- “小明”是谁,解决指代关系
- “今天”表示时间信息
- “公司”表示地点信息
- “确认方案”表示动作目的
如果只有一个注意力头,模型一次只能学到一种偏重点;但现实中,一个词往往需要同时从多个角度理解上下文。
这就是 Multi-Head Attention(多头注意力机制) 出现的原因。
什么是 Multi-Head Attention?
Multi-Head Attention 可以理解成一句话:
让模型从多个不同角度,同时去看一句话里的关系。
它的本质大致可以分成四步:
- 把原来的Q、K、VQ、K、VQ、K、V通过不同的线性变换映射到多组不同的子空间中
- 每一组都独立做一次 Self-Attention
- 每个头学习不同类型的关系
- 最后把这些结果拼接起来,形成更丰富的表示
也就是说,不再只有一个“观察者”在看句子,而是多个“观察者”同时在看。
有的头更关注主语和谓语的关系,有的头更关注时间和地点,有的头更关注代词指代,有的头更关注句法结构。
多头注意力的公式可以写成:
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO\text{MultiHead}(Q,K,V)=\text{Concat}(head_1,head_2,\dots,head_h)W^OMultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
多头注意力的结果,等于把第 1 个头、第 2 个头、……、第 hhh个头的结果先拼接起来,再乘一个矩阵做一次线性变换。
其中,每一个头都可以表示为:
headi=Attention(QWiQ,KWiK,VWiV)head_i=\text{Attention}(QW_i^Q,KW_i^K,VW_i^V)headi=Attention(QWiQ,KWiK,VWiV)
第 iii个头,其实就是做了一次普通的 Attention,只不过它不是直接拿原始的 Q,K,VQ,K,VQ,K,V去算,而是先各自乘上自己这一头专属的参数矩阵,主要就是为了把原始输入投影到不同的子空间里。
- 每个头都有自己的一套参数矩阵
- 同一个输入,在不同头里会被投影成不同的表示方式
- 因此,不同头就能从不同角度学习词与词之间的关系
所以,Multi-Head Attention 的核心价值就在于:
不是只让模型看一次,而是让模型从多个角度同时理解整句话。
Transformer Block 是怎么工作的?
Transformer 并不是把很多零散模块随便拼起来的,它其实是由一个个重复堆叠的标准结构块组成的,这个标准结构块通常就叫做 Transformer Block。
一个典型的 Transformer Block 一般包含四个部分:
- Multi-Head Self-Attention
- Add & Norm(残差连接 + 层归一化)
- Feed Forward Network(前馈神经网络)
- Add & Norm(残差连接 + 层归一化)
如果把它看成一个处理流程,那么它的节奏就是:
先做上下文信息融合,再做特征提炼。
具体来说:
- Multi-Head Self-Attention 负责让每个词和整句话里的其他词建立联系,完成信息交互
- 第一次 Add & Norm 负责保留原始输入,同时让训练更稳定
- 前馈神经网络 负责对已经融合上下文的信息再做一次更深层的特征加工
- 第二次 Add & Norm 继续保证信息传递顺畅,并让数值分布保持稳定
所以,一个 Transformer Block 的整体节奏可以概括为:
$ \text{Attention} \rightarrow \text{Add & Norm} \rightarrow \text{FFN} \rightarrow \text{Add & Norm} $
而且这样的 Block 不会只用一层,而是会堆很多层。
随着层数不断增加,模型对句子的理解也会越来越深入。
Transformer 里的几个关键模块
1. 残差连接(Residual Connection)
残差连接可以理解成:
把输入直接“绕一条近路”加到输出上。
某一层在完成计算后,不会只保留新的结果,而是会把原来的输入也一起加回来。
这样做的好处是,模型在学习新信息的时候,不会把旧信息完全丢掉,而是把“原来的内容”和“新学到的内容”结合起来。
通常可以表示为:
y=x+F(x)y = x + F(x)y=x+F(x)
其中:
- xxx 表示输入
- F(x)F(x)F(x) 表示这一层学到的新结果
- x+F(x)x + F(x)x+F(x) 表示把原始信息和新信息加在一起
它的核心作用是:
保留原始信息,让信息传递更顺畅。
2. 层归一化(Layer Normalization)
层归一化的作用是:
把每一层输出的数据调整到更稳定的范围,让后续训练更平稳。
在神经网络训练过程中,不同层输出的数据分布可能变化很大,这会让训练变得不稳定。
层归一化就是用来缓解这个问题的。
你可以先把它理解成一种“数值整理机制”,它主要帮助模型做到:
- 让每一层输出不要忽大忽小
- 让后面的网络更容易继续学习
- 让整体训练过程更稳定
3. 前馈神经网络(Feed Forward Network)
前馈神经网络的作用是:
对每个词已经融合上下文后的表示,再做一次更深入的特征加工。
注意力机制解决的是“词和词之间如何交流信息”,而前馈网络解决的是“交流完之后,如何把信息进一步加工得更好”。
所以它主要负责:
- 对每个位置的表示单独做非线性变换
- 提升表达能力
- 提炼更高层次的特征
Transformer 处理一句话时会经历什么?
从整体流程上看,Transformer 在处理一句话时,大致会经历下面几个步骤。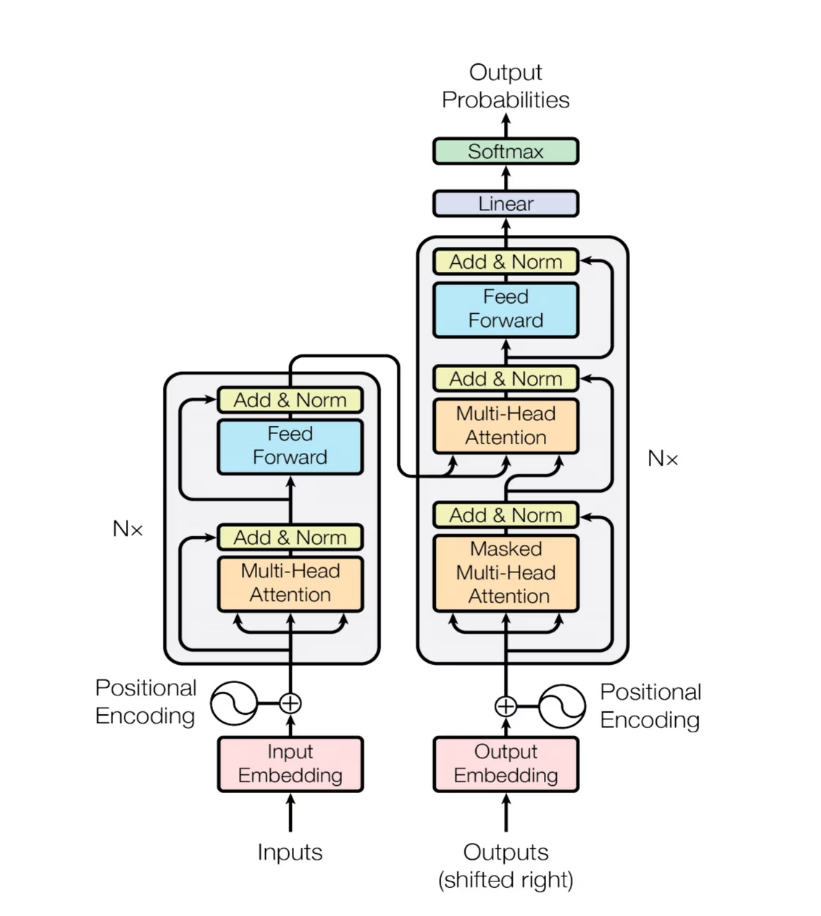

1. 先把每个词变成向量
模型不能直接处理文字,所以会先把句子里的每个词转换成数字表示,也就是词向量。
2. 加入位置信息
Self-Attention 很擅长判断“谁和谁相关”,但它本身并不知道词的顺序。
所以 Transformer 会给每个词加入位置编码(Positional Encoding),让模型知道哪个词在前,哪个词在后。
3. 进入 Multi-Head Self-Attention
这一步里,每个词都会去看整句话里的其他词,判断:
- 谁和我最相关
- 我应该重点吸收谁的信息
然后把这些信息按权重汇总,得到新的表示。
4. 进行第一次 Add & Norm
注意力计算完成后,模型不会直接进入下一步,而是会先把原始输入和新结果加在一起,再做层归一化。
这样既能保留原始信息,也能让训练更稳定。
5. 进入前馈神经网络
接下来,模型会对已经融合上下文的信息再做一次非线性特征加工,让表示能力更强。
6. 进行第二次 Add & Norm
前馈网络之后,Transformer 会再次执行残差连接和层归一化,保证信息传递顺畅,同时保持训练稳定。
7. 多层重复
上面这一整套流程不会只做一次,而是会一层层堆叠。
随着层数增加,模型对句子的理解会越来越深入,最终就能完成文本理解、翻译、问答和生成等任务。
Encoder 和 Decoder 是什么?
原始的 Transformer 结构其实分成两大部分:
- Encoder(编码器)
- Decoder(解码器)
你可以先简单理解成:
- Encoder 负责理解输入
- Decoder 负责生成输出
比如在机器翻译任务中:
- Encoder 会先把输入句子编码成一组带有上下文信息的表示
- Decoder 再根据这些表示,一步一步生成目标语言
为什么 Decoder 里需要 Mask?
Decoder 在生成文本时,是一个词一个词往后生成的。
这就意味着,模型在生成当前词时,不能提前看到后面的词,否则就等于“作弊”。
所以,Decoder 中的 Self-Attention 会加入一个 Mask(掩码),把未来位置遮住。
这样模型在生成当前词时,只能看到前面的内容,而不能看到未来的信息。
这就是 Masked Self-Attention。
它的作用可以概括为:
保证模型在生成当前词时,只能基于已有内容继续往后预测。
Transformer 为什么影响了 GPT 和 BERT?
Transformer 的影响非常大,后来很多经典模型其实都是基于它发展出来的。
其中:
- BERT 主要使用的是 Transformer 的 Encoder 部分,更擅长做文本理解任务
- GPT 主要使用的是 Transformer 的 Decoder 部分,更擅长做文本生成任务
所以可以简单理解成:
- BERT 更像“读懂文本”
- GPT 更像“持续往下写”
也正因为这样,Transformer 才成为后来大语言模型的重要基础。
Transformer 为什么这么重要?
Transformer 之所以如此重要,主要有几个原因。
- 并行能力更强
和 RNN 那种一步一步串行处理不同,Transformer 在训练阶段更适合并行计算,因此效率更高。
- 更擅长建模长距离依赖
一个词可以直接和句子中的其他任意词建立联系,不需要像 RNN 那样经过很长的传递路径。
- 可扩展性非常强
无论是做翻译、问答、分类,还是做今天的大语言模型,Transformer 都能作为统一底座不断扩展。
- 更适合大规模训练
Transformer 能更好地利用大规模数据和大规模参数,这也是它后来能够支撑 GPT、BERT 以及各种大模型的重要原因。
当然,Transformer 也不是没有代价。
由于 Self-Attention 需要计算词与词之间的两两关系,当序列特别长时,计算和显存开销会明显增大。
总结
回过头来看,Transformer 的核心思想其实可以概括成一句话:
不再依赖循环一步一步传递信息,而是让每个词直接和其他词建立联系。
在这个基础上,它通过:
- Self-Attention
- Multi-Head Attention
- 位置编码
- 前馈神经网络
- 残差连接
- 层归一化
- Encoder / Decoder
构成了一个完整而强大的深度学习架构。
也正因为这样,Transformer 才成为后来 BERT、GPT 以及大语言模型的基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)