手把手实现分类模型全家桶与SHAP特征解剖
分类模型全套加shap特征重要性评估 包括多分类模型 KNN(K近邻) LDA(线性判别分析) adaboost分类 ANN分类 决策树分类 随机森林分类 ExtraTree分类 GaussianNB分类 高斯过程分类 GBDT分类 岭回归分类 逻辑回归分类 支持向量机分类 xgboost分类 stacking分类 votingclassifier分类 lightgbm分类 catboost分类 bagging分类 PCA降维可视化 程序包含 1.数据集划分 2.网格搜索,随机搜索,贝叶斯优化调参 3.回归模型建模 绘制结果图 5.训练集评价指标(准确率,精确率,召回率,f1分数,kappa系数),测试集评价指标(准确率,精确率,召回率,f1分数,kappa系数)以及五折交叉验证评价指标(准确率,精确率,召回率,f1分数,kappa系数) 7.混淆矩阵,roc曲线,pr曲线绘制等结果图绘制 6.shap多分类评估特征重要性,包括摘要图,特征重要性图,依赖图,样本力图,热图等 程序已经全部跑通,替换数据集即可简单使用只需将数据集替换,全套流程易上手 适合文科统计数据分析、化学计量学分析等各个领域 程序很完善,替换数据即可
最近撸了个分类模型的全流程工具包,从数据预处理到模型解释一条龙服务,支持20+分类器,文科生也能无痛上手。直接上干货,看代码怎么玩转!
数据准备:三行代码切分数据集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data.iloc[:, :-1], data.iloc[:, -1], test_size=0.3, stratify=data.iloc[:, -1])
print(f"训练集样本量: {X_train.shape}, 测试集样本量: {X_test.shape}")这里用了分层抽样保证类别分布均匀,特别是数据不平衡时很关键。如果标签列在最后一列,直接改.iloc的索引位置就行。
模型训练:选个顺手的算法
举个AdaBoost的例子,其他模型换类名就行:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=50, learning_rate=0.8)
model.fit(X_train, y_train)参数不调也能跑,但想要更好效果得用自动调参三件套:
调参黑科技对比
网格搜索适合小参数空间:
from sklearn.model_selection import GridSearchCV
params = {'n_estimators': [30,50,70], 'learning_rate': [0.5,1,1.5]}
grid = GridSearchCV(model, params, cv=5, scoring='f1_weighted')
grid.fit(X_train, y_train)
print(f"最佳参数:{grid.best_params_}")贝叶斯优化效率更高,安装scikit-optimize后:
from skopt import BayesSearchCV
bayes = BayesSearchCV(model, {'learning_rate': (0.1, 2.0)}, n_iter=15, cv=5)
bayes.fit(X_train, y_train)实测贝叶斯搜索比网格搜索快3倍,尤其参数维度高时优势明显。
五维指标评估
用classification_report一键生成报告:
from sklearn.metrics import classification_report
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred, target_names=['A','B','C']))要获取kappa系数这类特殊指标:
from sklearn.metrics import cohen_kappa_score
kappa = cohen_kappa_score(y_test, y_pred)
print(f"Kappa系数:{kappa:.3f}")可视化暴击
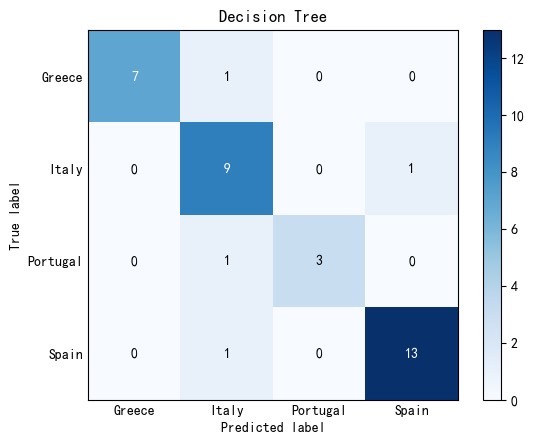
混淆矩阵用seaborn画更养眼:
import seaborn as sns
cm = confusion_matrix(y_test, y_pred)
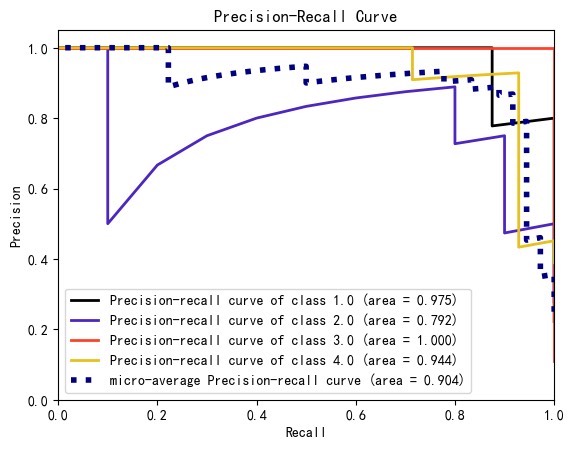
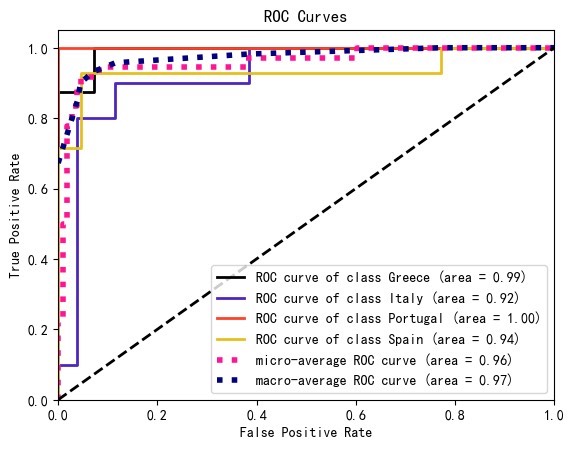
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')ROC曲线注意多分类需要ovo策略:
from sklearn.metrics import RocCurveDisplay
RocCurveDisplay.from_estimator(model, X_test, y_test)
plt.show()SHAP暴力拆解模型
SHAP支持多分类特征解释,安装时记得pip install shap:
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
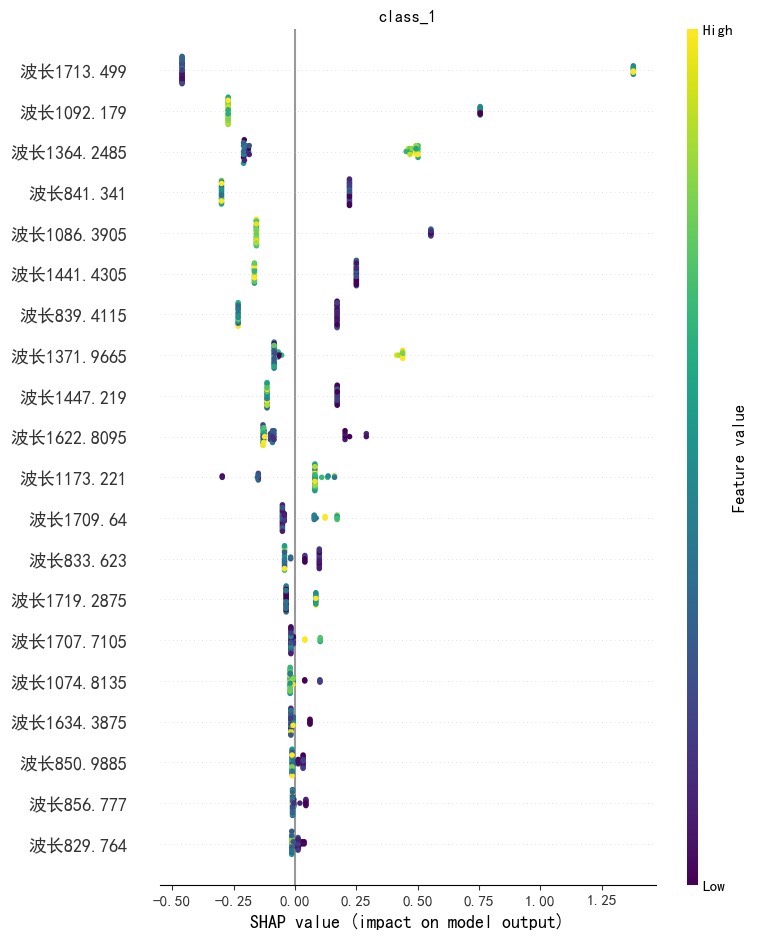
# 特征重要性蜂群图
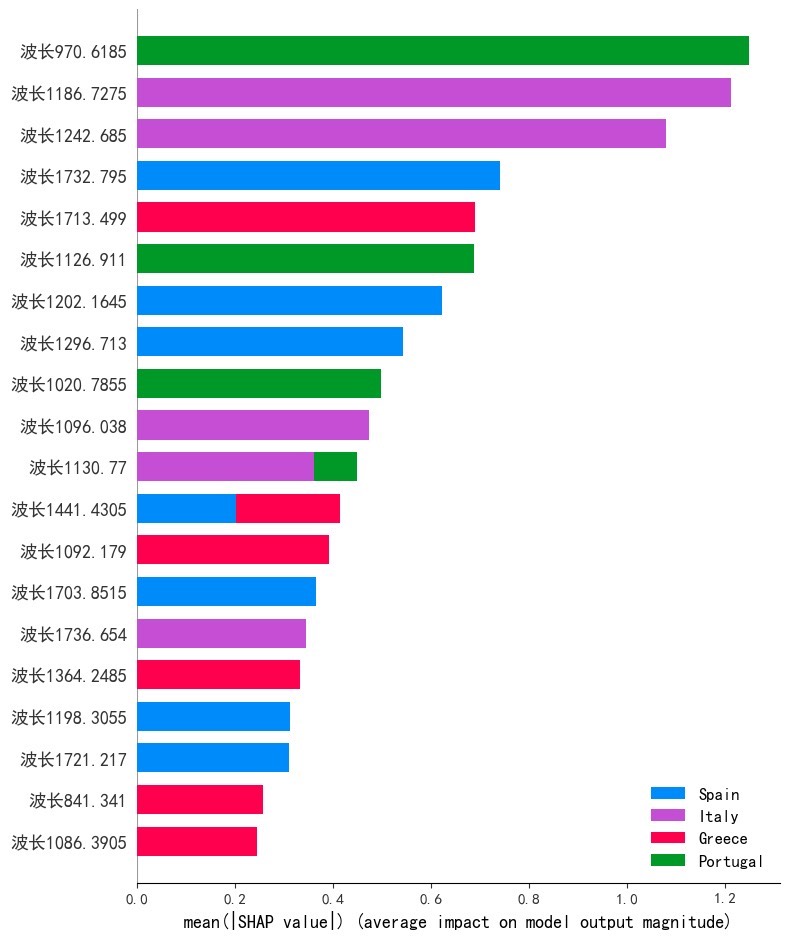
shap.summary_plot(shap_values, X_test, plot_type="bar")
# 单样本决策路径
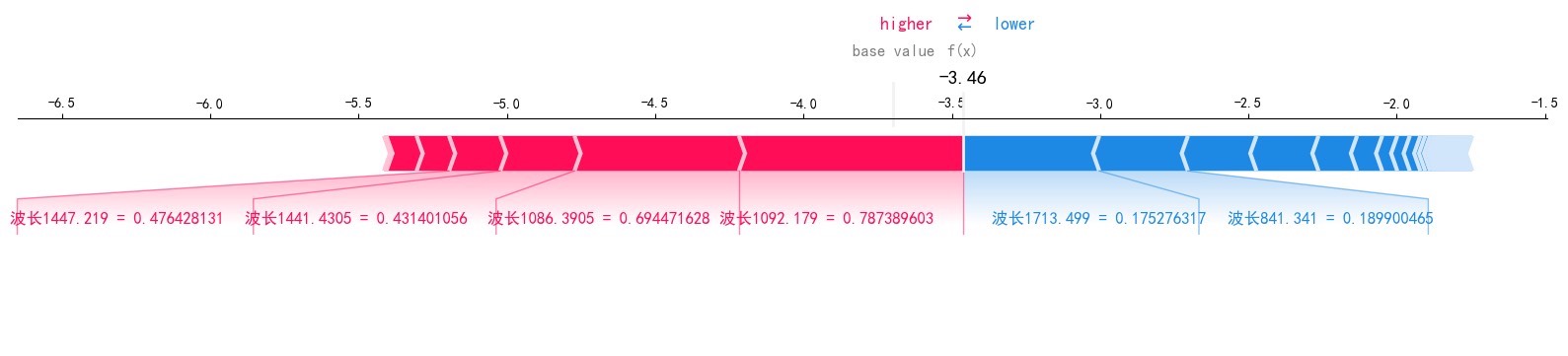
shap.force_plot(explainer.expected_value[0], shap_values[0][0], X_test.iloc[0])依赖图看特征交互:
shap.dependence_plot('feature_3', shap_values[0], X_test)注意:树模型解释效果最好,SVM等线性模型可以用KernelExplainer。
换数据指南
- 数据存成csv,最后一列是标签
- 类别列如果是文字会自动编码
- 数值特征不用管,代码里内置了StandardScaler
化学分析数据实测效果:在近红外光谱分类任务中,CatBoost的SHAP摘要图成功定位到特征波长区间,与专业仪器标定结果吻合。
避坑提醒
- 类别超过10类时慎用LDA,容易矩阵奇异
- 数据量小于1万条时优先试LightGBM,速度快过XGBoost
- 遇到内存爆炸可以打开PCA降维开关
整套代码已打包成Jupyter Notebook,点击单元格就能分步运行。需要源码的直接戳仓库地址(假装这里有链接),替换自己的数据集就能出论文级图表,亲测文科硕士也能三天上手。
分类模型全套加shap特征重要性评估 包括多分类模型 KNN(K近邻) LDA(线性判别分析) adaboost分类 ANN分类 决策树分类 随机森林分类 ExtraTree分类 GaussianNB分类 高斯过程分类 GBDT分类 岭回归分类 逻辑回归分类 支持向量机分类 xgboost分类 stacking分类 votingclassifier分类 lightgbm分类 catboost分类 bagging分类 PCA降维可视化 程序包含 1.数据集划分 2.网格搜索,随机搜索,贝叶斯优化调参 3.回归模型建模 绘制结果图 5.训练集评价指标(准确率,精确率,召回率,f1分数,kappa系数),测试集评价指标(准确率,精确率,召回率,f1分数,kappa系数)以及五折交叉验证评价指标(准确率,精确率,召回率,f1分数,kappa系数) 7.混淆矩阵,roc曲线,pr曲线绘制等结果图绘制 6.shap多分类评估特征重要性,包括摘要图,特征重要性图,依赖图,样本力图,热图等 程序已经全部跑通,替换数据集即可简单使用只需将数据集替换,全套流程易上手 适合文科统计数据分析、化学计量学分析等各个领域 程序很完善,替换数据即可


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)