大模型框架——第三节:神经网络基础
神经网络的基本组成元素
人工神经元 (Neuron)简称神经元
受生物神经网络启发。生物神经元通过树突接收信号,经细胞体处理,再由轴突输出。
输入与权重
神经元接收多个输入,每个输入都有一个对应的权重
(代表这个信号的重要程度)。
求和与偏置
神经元将它们加权求和,并加上一个偏置项( ):
激活函数 (Activation Function)
如果只有线性组合,多层神经网络和单层没有区别。必须通过激活函数引入非线性能力。
从单层到多层 (From Single to Multilayer)
单层神经网络
由多个神经元并行排列组成。
矩阵化表示
为了计算效率,将多个神经元的计算合并为矩阵运算:。此时权重由向量变为矩阵
,偏置和输出变为向量。
多层神经网络 (MLP)
将多层神经元进行堆叠。
层级结构
输入层 :接收特征(如词向量)。
隐藏层 :在输入之上添加的多层网络
输出层 h:隐藏层的输出
前馈计算 (Feedforward)
信号从输入层开始,逐层向后传递直至输出。
为什么需要非线性激活函数?
理论核心:如果不使用激活函数(即 f 是线性的),那么无论叠加多少层,多层网络在数学上都可以合并为一个单层的线性变换。
作用:引入非线性激活函数使网络能够拟合更复杂的非线性函数,这是深度神经网络强大能力的根本来源。
常见的激活函数
Sigmoid:将输出压缩到 (0, 1) 之间,常用于二分类或表示概率。输入0,得到0。
Tanh:将输出压缩到(-1, 1)之间。
ReLU (Rectified Linear Unit):公式为。正数输出本身,负数为零。在正数区导数为 1,计算简单且能有效缓解梯度消失,是目前最常用的激活函数。
输出层 (Output Layer) 的设计
根据任务需求,输出层会有不同的形式:
线性输出
直接输出 ,常用于回归问题(预测连续值)。
Sigmoid 输出
输出值 表示属于某一类的概率,则
为属于另一类的概率。用于二分类问题。
Softmax 输出
公式:用于多分类问题。
特点:保证所有输出项均为正数且总和为 1,形成一个概率分布。模型选取概率最大的项作为分类结果。
如何训练神经网络?—— 神经网络训练与反向传播
一、 训练目标:损失函数 (Loss Function)
训练神经网络的本质是寻找一组参数 ,使得模型的预测值与真实标签之间的差异最小化。
1. 均方误差 (Mean Squared Error, MSE)
适用场景:回归问题(如预测房价、电脑价格),根据输入输出拟合一个特定的值。
公式:
逻辑:为均方差,衡量预测值
与真实值
之间的几何距离。
判断:的值越小,我们神经网络的学习越准确
2. 交叉熵损失 (Cross-entropy Loss)
适用场景:分类任务(如文本情感分类、图像识别)。
例题:给定 N 个训练样本 {(xi,yi)}i=1N,其中 xi 是句子,yi 是其情感标签。我们希望训练一个神经网络 Fθ(⋅),它以句子 x 作为输入,并预测其情感标签 y。一个合理的训练目标是交叉熵
h X X +1
y 0.6 0.3 0.1
如果真实标签为 y=1(第一类),则该样本的损失为:−logPmodel(Fθ(x)=1)=−log(0.6)=0.74.
如果 y=2 ...−logPmodel(Fθ(x)=2)=−log(0.3)=1.74.
如果 y=3 ...−logPmodel(Fθ(x)=3)=−log(0.1)=3.32.
逻辑:衡量模型输出的概率分布与真实分布的差异。(最小化模型参数 θ,使得模型对所有样本预测正确标签的对数概率的平均值的相反数最小)其中 θ 是神经网络 Fθ(⋅) 中的参数。
计算:交叉熵其实是用来衡量模型正确分类能力的损失函数。若真实类别为 ,则损失为该类预测概率的负对数
。概率越接近 1,损失越小。
二、 优化算法:随机梯度下降 (SGD)
损失函数确定后,我们需要一种方法来更新参数 。
核心比喻:下山。在当前位置寻找坡度最陡(梯度最大)的方向,沿着反方向迈出一小步。
更新公式:
:梯度,代表函数增长最快的方向。
:学习率 (Learning rate),决定了更新的步长。
三、 数学基础:梯度与雅可比矩阵
为了处理神经网络中的多维向量和矩阵运算,需要将标量求导扩展到高维。
梯度 (Gradient):
给出一个函数,有1个输出,n个输入。
它的梯度是一个偏导数的向量:
雅可比矩阵 (Jacobian Matrix):
当函数有 n 个输入、m 个输出时,拆分成m个具有n个输入的单个输出函数。
其导数构成一个 的矩阵。
矩阵中的元素 表示第
个输出对第
个输入的偏导数。它是链式法则在向量化运算中的基础。
单变量函数:导数相乘
设 ,
多变量函数:雅可比矩阵相乘
设,
四、 核心机制:反向传播 (Backpropagation)
反向传播是深度学习框架(如 PyTorch, TensorFlow)自动计算梯度的核心算法。
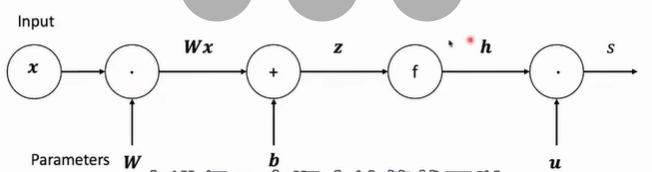
1. 计算图 (Computational Graphs)
节点 (Node):表示变量或操作(如 ,
,
)。
边 (Edge):表示数据的传递方向。
前向传播:从输入开始,按顺序计算出损失值 。
反向传播:从损失值开始,沿着计算图逆向应用链式法则。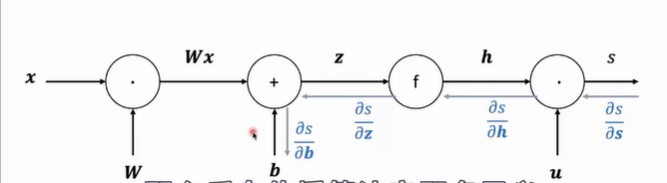
2. 链式法则 (Chain Rule)
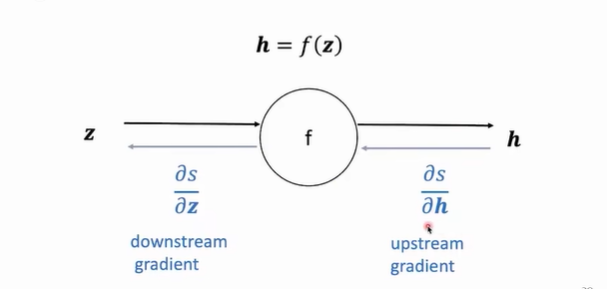
反向传播的本质是链式法则的重复应用。对于每一个节点,梯度的计算遵循:
下游梯度 (Downstream Gradient) = 上游梯度 (Upstream Gradient) 本地梯度 (Local Gradient)
本地梯度:当前操作节点对其直接输入的导数。
示例: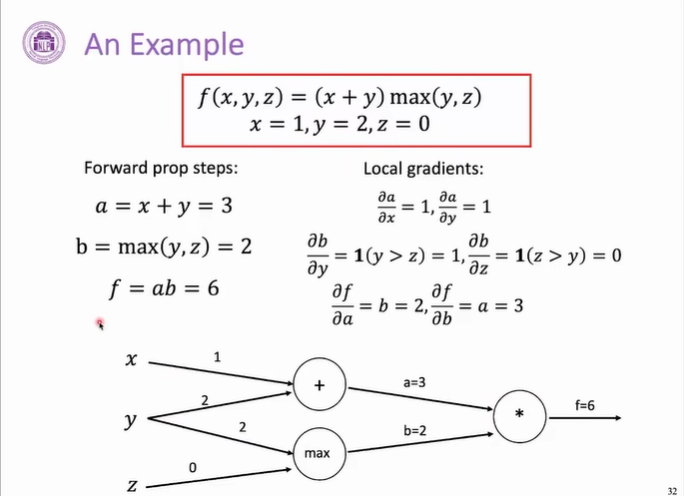
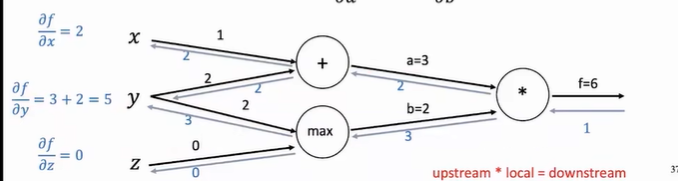 若
若 且
,求
时,需先求
,再乘以
。
问题
已知:,
,
求:
。
链式法则应用
各部分导数为:
(激活函数导数构成的对角矩阵)
(单位矩阵)
所以
五、 总结:训练全流程
-
前向传播:输入数据,通过网络各层计算,得到预测概率及损失值。
-
反向传播:从损失函数出发,利用计算图和链式法则,计算出每个权重和偏置的梯度。
-
参数更新:利用 SGD 等优化器,根据梯度调整参数 $\theta$。
-
循环迭代:重复以上步骤,直到模型收敛。
词向量:Word2Vec
Word2Vec 核心概念与语言规律
Word2Vec 利用浅层神经网络将单词关联到分布式表示(Distributed Representations),即词向量。它的核心优势在于能够捕捉语言中的语义规律。
语义类比:在向量空间中,词与词之间的关系可以通过向量运算体现。例如,“King - Man + Woman ≈ Queen”。
多维捕捉:它不仅能处理性别(男-女)关系,还能捕捉动词时态(Walking-Walked)、国家与首都(China-Beijing)等逻辑规律。这意味着相似语义或逻辑关系的词对,在空间中构成的向量往往是近似平行的。
典型模型架构
Word2Vec 主要包含两种训练架构,旨在生成单词的分布式表示:
1. 滑动窗口(Sliding Window)机制
在处理文本时,系统使用固定大小的滑动窗口沿句子移动。
Target Word(目标词):窗口中间的单词。
Context Words(上下文词):目标词周围的单词。
窗口大小:例如窗口设为 5,则包含 1 个目标词和前后各 2 个上下文词。当窗口位于句子边缘时,上下文词可能是不完整的。
2. CBOW 与 Skip-gram 的区别
CBOW (Continuous Bag-of-Words):根据给定的上下文词来预测中间的目标词。
Skip-gram:与 CBOW 相反,它利用中间的一个目标词来预测周围的多个上下文词。
模型运行原理详解
CBOW (连续词袋模型)
CBOW 基于“词袋假设”,即上下文词的顺序不影响预测结果。
输入与投影:将上下文词的 One-hot 向量通过嵌入矩阵(词表)找到对应的词向量。
向量融合:将这些上下文词向量进行累加并取平均(Average),得到一个融合向量。
预测输出:通过线性变换和 Softmax 层,输出一个维度等于词表大小的概率分布。模型的目标是使目标词对应的概率值最大。
Skip-gram (跳跃模型)
由于神经网络很难直接一个输入对应多个输出,Skip-gram 将预测任务拆解为多个训练样本对(如:目标词-上下文 1,目标词-上下文 2)。
结构:输入目标词,通过词向量矩阵找到其表示,再预测每一个特定的上下文词。
效率:虽然拆分了任务,但当词表巨大时,全量 Softmax 的计算开销仍然极高。
计算效率优化
全量 Softmax 的局限性
当词表规模达到万级以上时,Softmax 的分母需要对所有词进行求和,且每次反向传播都要更新海量参数,计算上极其低效。
负采样 (Negative Sampling)
负采样的核心思想是不对整个词表进行 Softmax,而是每一步只更新一小部分权重。
原理:将多分类问题转化为二分类问题。对于给定的词对,模型判断它们是否为真实的上下文关系(正例 vs 负例)。
负例采样公式:
其中 是词频。引入 3/4 次方是为了适度提升低频词被采样作为负例的概率,防止它们被模型忽视。
效率提升:假设词向量维度 300,词表 10,000。全量更新需要处理 的矩阵;若只采样 5 个负词,则仅需更新
的权重,计算量仅为原来的 0.05%。
训练小技巧
子采样 (Sub-sampling):高频词(如“the”、“a”)通常携带的语义信息较少。通过特定概率随机丢弃部分高频词,可以平衡高低频词的训练效果,让模型更关注罕见但信息丰富的词。
软滑动窗口 (Soft sliding window):距离目标词越远的词,相关性通常越低。在实践中,可以为远距离词分配更小的权重,或者在 1 到 $S_{max}$ 之间随机抽取窗口大小,从而实现对近距离词的动态加权采样。
循环神经网络 (RNN)
RNN 的核心特征是处理序列数据(Sequence Data),如文本、音频或时间序列。
核心概念:顺序记忆 (Sequential Memory)
定义:一种使大脑更容易识别序列模式数据的机制。
人类示例:顺着背字母表很简单,但倒着背却很难,因为大脑习惯了顺序记忆。
RNN 的应用:通过递归地更新顺序记忆,对序列数据进行建模。
RNN 结构
一个典型的 RNN 包含:
输入层 (Inputs):(如一句话中的单词)。
隐藏层 (Hidden States):。
表示不同时间步的状态变量。
它存储了过去的信息和当前的输入。
输出层 (Outputs):(对应每个输入的输出)。
数学表达 (RNN Cell)
隐藏状态的计算公式:
输出的计算公式:
:输入到隐藏层的权重矩阵。
:上一时刻隐藏层到当前时刻的权重矩阵。
参数共享:在整个序列的处理过程中,权重 是共享的。
RNN 语言模型案例
通过输入前面的词来预测下一个词(例如输入 "never too late" 预测 "to"):
独热向量 (One-hot vectors):将单词转化为向量 $w_i$。
词嵌入 (Word embeddings):转化为更丰富的语义向量 $x_i = Ew_i$。
计算隐藏状态:每个 $h_i$ 都包含了前面所有词的信息。
输出分布:通过 Softmax 层计算每个词出现的概率,选择概率最大的词作为预测值。
应用场景
序列标注 (Sequence Labeling):如词性标注。
序列预测 (Sequence Prediction):如天气预报。
图片描述 (Photograph Description):给图片生成描述文字。
文本分类 (Text Classification):如情感分析(判断正面/负面)。
优缺点分析
优点
-
可以处理任意长度的输入。
-
模型大小不会随输入长度增加而增大。
-
计算第 $i$ 步时可以利用多步之前的信息。
缺点
-
计算速度慢:因为是顺序计算,必须先算前一步。
-
长期依赖问题:在实际中很难获取太久之前的信息。
梯度问题与改进方案
梯度消失与梯度爆炸 (Gradient Vanish/Explode)
在反向传播(BPTT)过程中,由于链式法则的多次连乘:
若梯度大于 1,随层数增加呈指数级增长,导致梯度爆炸。
若梯度小于 1,随层数增加呈指数级衰减,导致梯度消失(更为常见)。
改进变体:更复杂的隐藏单元
为了解决梯度消失并捕捉长距离依赖,引入了门控机制:
GRU (Gated Recurrent Unit, 门控循环单元):包含更新门(Update gate)和重置门(Reset gate)。
LSTM (Long Short-Term Memory, 长短期记忆网络):通过更复杂的门控结构保持长期记忆。
门控循环单元 (GRU)
为了解决传统 RNN 的梯度消失问题,引入了门控机制来平衡过去信息与当前输入的影像。
核心组件
GRU 引入了两个关键的“门”:
更新门 ():控制前一时刻的状态信息有多少保留到当前状态。
重置门 ():控制前一时刻的状态信息有多少写入到当前的候选集
中。
特殊情况分析
当重置门 时:当前激活状态
几乎只取决于当前输入,忽略过去信息。这适用于新文章开头等场景。
当更新门 时:可以长距离地“复制”信息,直接跳过当前步的计算,保留旧状态。
应用场景
序列标注:如给定句子,标注每个词的词性。
序列预测:如根据过去一周气温预测未来天气。
图片描述 (Image Captioning):根据图片生成描述性句子。
文本分类:识别句子的情感倾向(正面/负面)。
长短期记忆网络 (LSTM)
核心概念:细胞状态 ( )
)
作用: 是 LSTM 的关键,它像一条传送带穿过整个序列,能够捕获并传递长期依赖信息。
特点:只有少量微小的线性交互,信息很容易在其中流转,不易丢失。
门控机制 (Gating Mechanism)
LSTM 通过三个“门”来控制细胞状态信息的遗忘、输入和输出:
遗忘门 ():决定从上一个细胞状态
中丢弃哪些信息。
输出一个 0 到 1 之间的值,0 表示“完全遗忘”,1 表示“完全保留”。
输入门 ():决定当前输入中有哪些新信息需要存入细胞状态。
配合一个 层生成候选细胞状态
。
输出门 ():基于当前的细胞状态,决定最终输出(隐藏状态
)的内容。
LSTM 的优势
多层堆叠:每一层内部都是深度网络结构,堆叠后建模能力极强。
缓解梯度消失:由于引入了门控机制和细胞状态,LSTM 能更有效地处理长距离的序列信息。
动态控制:能根据输入动态调整信息的保留和流动,提高信息利用率。
双向循环神经网络 (Bi-RNN)
背景与动机
传统 RNN 的局限:在 时刻的状态
只能获取从过去(1 到 t-1)的信息。
需求场景:在很多应用中,当前时刻的预测不仅取决于过去,还取决于未来。
手写体识别:识别当前的字可能需要参考后面几个字的字形。
语音识别:理解当前的词可能需要结合后文的语境。
结构原理
双向 RNN 由两个独立的 RNN 组成:
正向 RNN:从序列开始向后处理(),捕获过去的信息。
反向 RNN:从序列末尾向前处理(),捕获未来的信息。
最终输出:每一个时刻的输出 会同时参考正向和反向的隐藏状态。
总结
信息量更大:Bi-RNN 能够同时利用上下文(Context)信息,通常比单向 RNN 表现更好。
变体:该思想可以应用于多种 RNN 变体,例如双向 LSTM。
RNN 家族总结
RNN:体现顺序记忆,但存在梯度问题。
GRU/LSTM:通过门控机制优化了长期记忆能力,性能显著提升。
Bi-RNN:进一步打破时间限制,实现上下文全方位的特征提取。
卷积神经网络 (CNN) 在 NLP 中的应用
核心优势
特征提取:CNN 擅长提取局部和位置无关的模式。
NLP 对应:在 CV 中提取颜色、边缘;在 NLP 中则提取 n-gram 短语和局部语法结构。
句子表示的提取方式
n-gram 提取:
Bigram:每 2 个相邻词组成短语(如 "the plane", "plane is")。
Trigram:每 3 个相邻词组成短语。
无需外部工具:不需要依赖句法分析器,直接通过滑动窗口学习特征表示。
CNN 网络架构
输入层 (Input):将句子通过词向量(Word Embeddings)转换为矩阵 $\mathbf{X} \in \mathbb{R}^{m \times d}$($m$ 是句长,$d$ 是维度)。
卷积层 (Convolution):
使用滑动卷积核(Filter/Kernel)在句子矩阵上移动。
参数共享:同一个卷积核在整个句子上重复使用,大幅减少参数量。
池化层 (Max-pooling):通常取局部区域的最大值,提取最显著的特征。
非线性层:如使用 $\tanh$ 等激活函数进行非线性变换。
CNN vs. RNN 对比
| 特性 | CNN | RNN |
| 擅长领域 | 提取局部、位置无关特征 | 建模长距离上下文依赖 |
| 参数量 | 较少(由于参数共享) | 较多 |
| 并行化 | 优(各窗口计算互不依赖) | 差(必须按顺序计算) |
| 应用场景 | 文本分类、情感分析 | 语言模型、机器翻译 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)