AI训练与推理:从零到精通的实战指南
一、AI是什么?三个圈的关系
首先理清三个经常混用的词:
-
人工智能:让机器模仿人类智能的学科/目标。比如让电脑“看懂”图片、“听懂”语言。
-
机器学习:实现AI的主要方法——不直接编写规则,而是让机器从数据中自己学习规律。
-
深度学习:机器学习的一个分支,使用“神经网络”这种结构,目前大模型(如ChatGPT)都属于它。
打个比方:
人工智能是“学会开车”这个目标;
机器学习是“通过大量练习来学会开车”这个方法;
深度学习是“用模拟人脑的神经网络来练习”这种具体技术。
二、模型是什么?
模型可以理解为一个“超级复杂的数学公式”,它有很多可调节的旋钮(参数)。
最初,这个公式输出的结果是随机的、毫无意义的。
训练就是不断调整这些旋钮,让公式的输出越来越接近我们想要的结果。
三、训练 —— 让模型“上学”
训练是消耗算力、数据、时间的阶段,目标是让模型从数据中学会知识。
1. 准备教材:数据
比如你想训练一个“识别猫”的模型,就需要准备成千上万张图片:
-
有些图片标着“这是猫”
-
有些标着“这不是猫”
2. 学习过程
-
前向传播:给模型看一张猫的图片,它随机猜一个结果(比如“60%是猫”)。
-
计算损失:对比正确答案(100%是猫),算出“错误有多大”。这个误差叫损失。
-
反向传播:把误差反向传回模型,告诉每个“旋钮”:“你该往左拧一点,还是往右拧一点”。
-
优化:实际拧动旋钮(更新参数),让下次预测更准。
这个过程重复几百万甚至几十亿次,模型慢慢从“胡猜”变成“一眼认出猫”。
3. 训练的关键要素
-
数据:质量比数量更重要。垃圾进,垃圾出。
-
算力:GPU(显卡)是主力,因为神经网络的计算非常适合并行处理。
-
算法:包括模型结构、优化方法等,决定了学习效率。
-
超参数:比如学习速度(每次拧旋钮的幅度),设置不当会导致学不会或学崩。
四、推理 —— 让模型“工作”
训练完成后,模型参数固定下来,不再变化。推理就是使用训练好的模型做实际预测。
-
训练:造一个“专家”(费时费力)
-
推理:请专家回答问题(快速、低成本)
比如ChatGPT:
-
训练阶段:用海量文本,花费几个月、数千万美元,训练出基础模型。
-
推理阶段:你输入一句话,模型几秒内生成回复。这个回复过程就是推理。
推理时,模型不再反向传播、不再学习,只是根据输入,快速计算一次输出。
五、直观类比:学骑自行车
| 阶段 | 类比 | AI对应 |
|---|---|---|
| 初始状态 | 从未骑过车,一上车就倒 | 随机初始化的模型 |
| 训练 | 一次次摔倒,根据摔倒方向调整身体平衡 | 计算损失,反向传播,更新参数 |
| 训练完成 | 已经形成肌肉记忆,不再需要刻意调整 | 模型参数固定,可以部署使用 |
| 推理 | 之后每次骑车出行,快速平稳地到达目的地 | 输入新数据,输出预测结果 |
六、为什么有时会搞混“训练”和“推理”?
因为在一些简单场景里,界限会模糊:
-
在线学习:模型边用边学(比如推荐系统实时更新),训练和推理交替进行。
-
微调:一个已经训练好的大模型,你用少量数据再稍微训练一下,让它适应你的场景。
但在主流的大模型应用中,绝大多数情况下:
-
训练是AI公司/实验室做的事
-
推理是普通用户使用AI时的体验
七、一个具体例子:让AI看懂数字
假设你要训练一个识别手写数字(0-9)的模型。
1.数据:几万张28x28像素的图片,每张已标好是哪个数字(MNIST数据集)。
2.模型结构:一个简单的神经网络,输入层784个像素,输出层10个数字。
3.训练:
-
输入一张“3”的图片
-
模型输出:[0.1, 0.05, 0.02, 0.6, 0.03, …] (表示认为可能是3的概率60%)
-
正确答案应该是:[0,0,0,1,0,…]
-
损失函数计算出差距,反向传播调整参数
-
重复几万次后,模型对“3”的识别准确率接近99%
4.推理:用户画一个潦草的数字,模型一次前向传播,输出概率最高的数字。
八、最简单的训练+推理代码
用Python和PyTorch识别手写数字的完整示例,可以实际运行看看训练时损失如何下降、推理时如何输出结果——这样会比纯理论更直观。
1.环境准备
如果你还没有安装 PyTorch,先运行:
pip install torch torchvision matplotlib2.完整代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# 1. 准备数据:下载 MNIST 手写数字数据集
transform = transforms.Compose([
transforms.ToTensor(), # 图片转为张量,像素值归一化到 [0,1]
transforms.Normalize((0.5,), (0.5,)) # 标准化到 [-1,1],加速收敛
])
# 训练集:60000张图片
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# 测试集:10000张图片(用于推理演示)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=1, shuffle=True) # batch_size=1 方便逐张推理
# 2. 定义模型:一个简单的全连接神经网络
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28*28, 128) # 输入层:28x28=784个像素 -> 隐藏层128个神经元
self.fc2 = nn.Linear(128, 64) # 隐藏层128 -> 64
self.fc3 = nn.Linear(64, 10) # 输出层10个神经元,对应数字0-9
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
x = x.view(-1, 28*28) # 将28x28图片展平成784维向量
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x) # 最后一层不用 softmax,因为损失函数会内部计算
return x
# 实例化模型
model = SimpleNN()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失,适合多分类
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 3. 训练阶段
print("开始训练...")
epochs = 5 # 训练5轮(可增加,但为了快速演示先用5轮)
for epoch in range(epochs):
running_loss = 0.0
for images, labels in trainloader:
# 前向传播:计算模型输出
outputs = model(images)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播 + 优化
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
running_loss += loss.item()
print(f"第 {epoch+1} 轮结束,平均损失: {running_loss / len(trainloader):.4f}")
print("训练完成!")
# 4. 推理阶段:随机取一张测试图片,让模型预测
print("\n开始推理演示...")
# 从测试集中取一张图片
dataiter = iter(testloader)
image, label = next(dataiter)
# 模型推理(不需要计算梯度,加快速度)
with torch.no_grad():
output = model(image)
predicted = torch.argmax(output, dim=1) # 取概率最高的类别
# 显示图片和预测结果
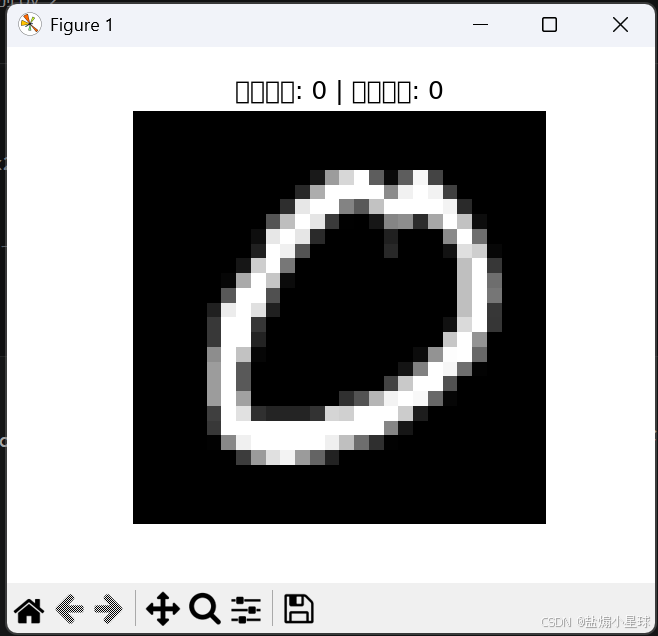
plt.imshow(image.squeeze(), cmap='gray')
plt.title(f"真实标签: {label.item()} | 模型预测: {predicted.item()}")
plt.axis('off')
plt.show()
# 额外:再测试几张,看看准确率
correct = 0
total = 0
with torch.no_grad():
for images, labels in testloader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"\n在测试集上的准确率: {100 * correct / total:.2f}%")3.代码流程解析
1. 数据准备
-
使用 MNIST 数据集,包含 0~9 的手写数字图片,每张 28×28 灰度图。
-
训练集 60000 张,测试集 10000 张。
-
数据加载器
DataLoader会将数据分批送入模型(batch_size=64)。
2. 模型定义
-
定义了一个 3 层全连接网络(也叫多层感知机 MLP):
-
输入层:784 个像素
-
隐藏层 1:128 个神经元
-
隐藏层 2:64 个神经元
-
输出层:10 个神经元(对应 0~9 的得分)
-
-
激活函数用 ReLU,让网络能学习非线性关系。
3. 训练过程(关键)
outputs = model(images) # 前向传播:输入图片,得到10个分数
loss = criterion(outputs, labels) # 计算预测分数与真实标签的差距
loss.backward() # 反向传播:计算每个参数的梯度
optimizer.step() # 根据梯度更新参数-
每看完一批图片(64 张),就更新一次参数。
-
训练 5 轮(epoch)后,损失会明显下降,模型学会识别数字。
4. 推理过程
-
with torch.no_grad():表示不记录梯度(推理时不需要反向传播,节省内存和计算)。 -
输入一张新图片,模型直接输出 10 个分数,取最大值对应的索引即为预测的数字。
-
最后统计了模型在 10000 张测试集上的准确率,通常在 95%~97% 左右。
5.运行结果
同时会弹出一张图片,显示模型对某张手写数字的预测结果,大概率与真实标签一致。
如下图所示:
感兴趣的小伙伴快去试试吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)