深度学习基础原理
一、重点要求掌握

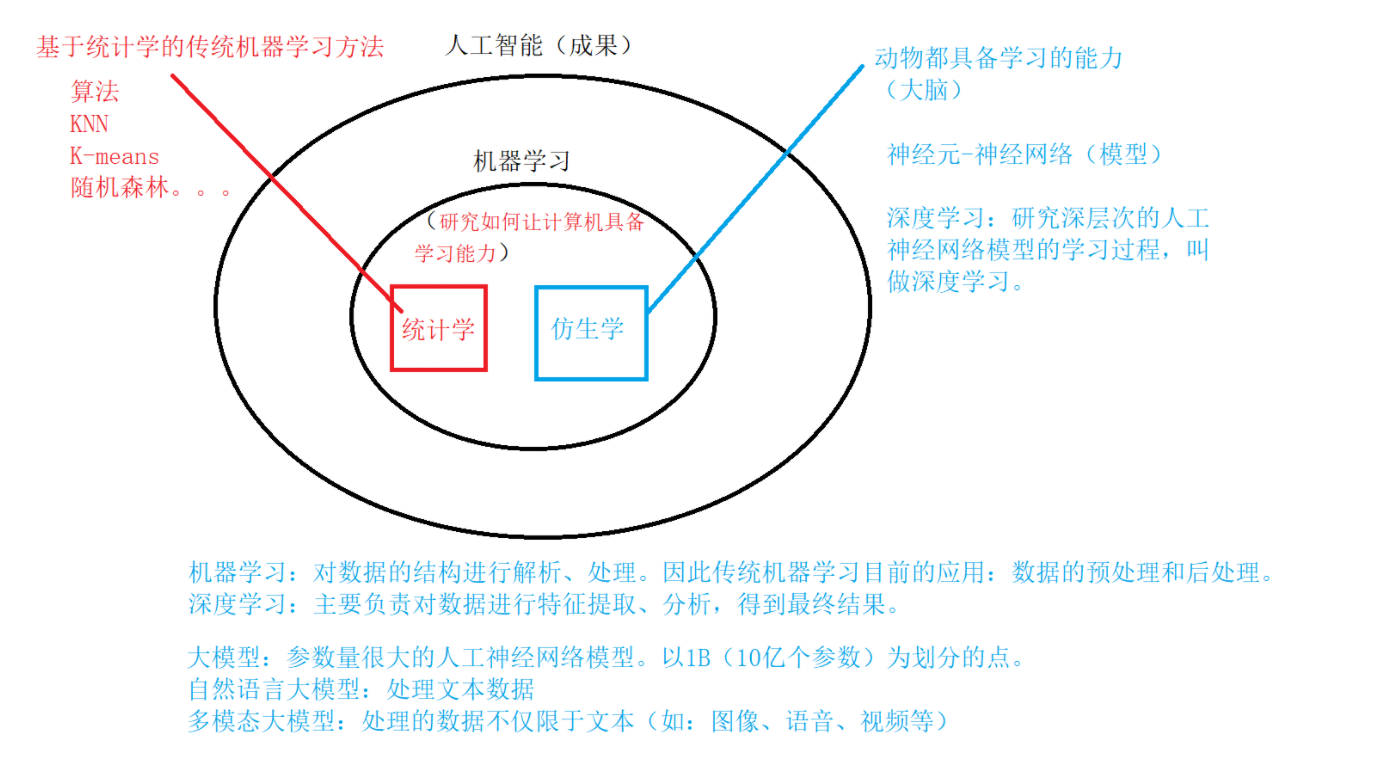
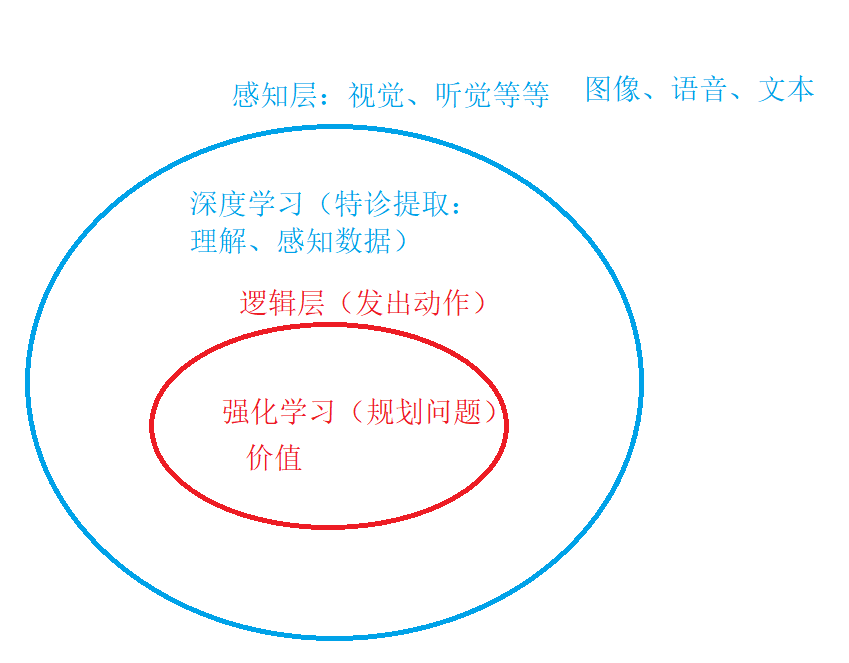
二、人工智能 机器学习 深度学习之间的关系
人工智能是机器学习之后的一个成果
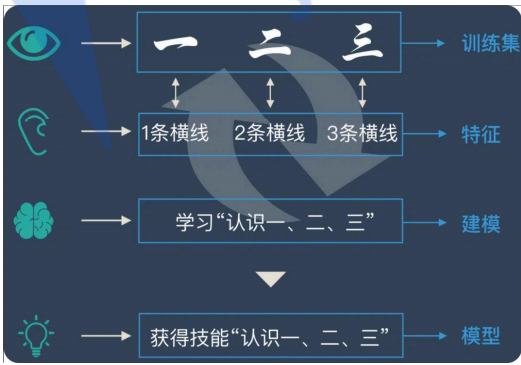
机器学习的流程
五大步骤: 数据处理 --> 特征工程 --> 建立模型 --> 评估迭代 --> 上线应用 --> 持续优化
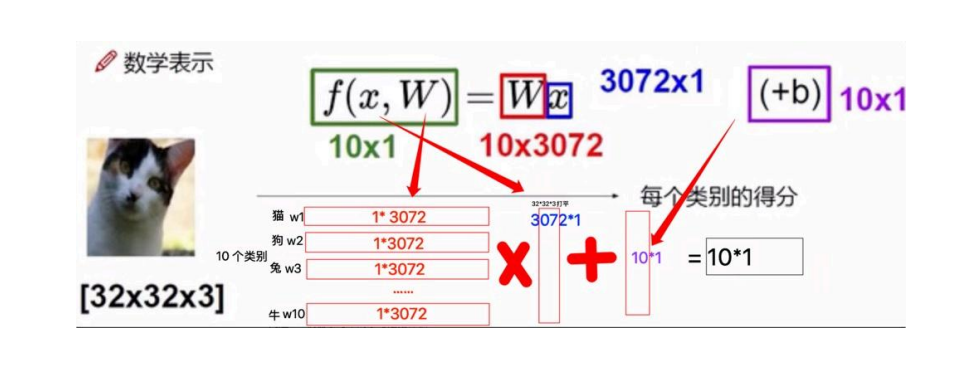
x·w+b=h
通过不断调整w和b的值,使它越来越接近
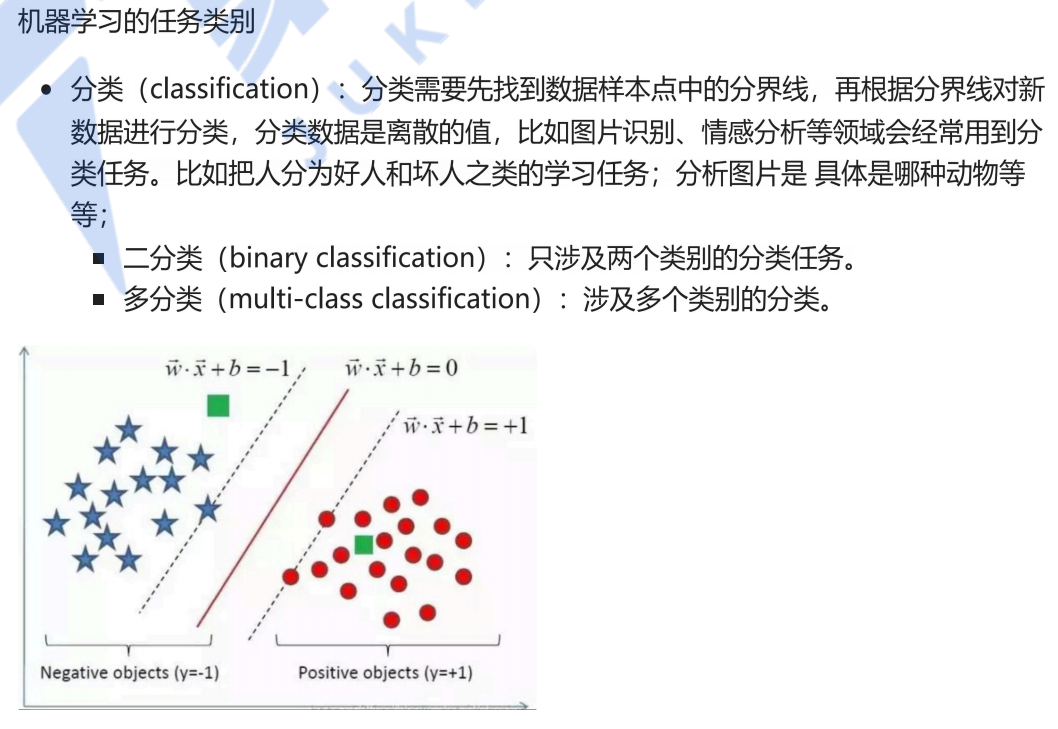
回归 定义:回归是对已有的数据样本点进行拟合,再根据拟合出来的函数,对未来进行预测。 特点:数据是连续的值,预测值也是连续值。 示例:房价预测、股价预测等。
聚类 定义:聚类是根据样本之间的相似度,将一批数据划分为N个组。 应用领域:用户分组、异常值检测等。
降维 定义:减少数据的维度,对数据进行降噪、去冗余,方便计算和训练。 应用场景: 数据预处理:减少对模型准确率影响很小的维度,以提高计算效率。 图表可视化:将高维模型降为三维或二维图表,便于直观分析。
三、机器学习系统编程模型的演进
机器学习系统编程模型的首要设计目标是:对开发者的整个工作流进行完整的编程支持。一个常见的机器学习任务一般包含数据处理、模型定义、优化器定义、训练、测试和调试等几大阶段。
• 数据处理:首先,用户需要数据处理API来支持将数据集从磁盘读入。
• 模型定义:用户需要模型定义API来定义机器学习模型。这些模型带有模型参数,可以对给定的数据进行推理。
• 优化器定义:模型输出需要和用户的标记进行对比,这个对比差异一般通过损失函数(Loss function)来进行评估。并根据损失来引入(Import)和定义各种优化算法(Optimisation algorithms)来计算梯度(Gradient),完成对模型参数的更新。
• 训练:给定一个数据集,模型,损失函数和优化器,用户需要训练API来定义一个循环(Loop)从而将数据集中的数据按照小批量(mini - batch)的方式读取出来,反复计算梯度来更新模型。
• 测试和调试:训练过程中,用户需要测试API来对当前模型的精度进行评估。当精度达到目标后,训练结束。
PyTorch是一种开源深度学习框架,以出色的灵活性和易用性著称。这在一定程度上是因为与机器学习开发者和数据科学家所青睐的热门Python高级编程语言兼容。
四、PyTorch
PyTorch 是一个由 Facebook 开源的深度学习框架,是目前市场上最流行的深度学习框架之一。应用领域:包括图像和语音识别、自然语言处理、计算机视觉、推荐系统等。核心特点:易于使用:使用 Python 编写,学习和使用相对简单。灵活性高,代码可读性好:成为深度学习研究和应用的首选框架之一。支持 GPU 加速:完全支持 GPU,提升计算性能。动态计算图:使用反向模式自动微分技术,可以动态修改计算图形,使其成为快速实验和原型设计的常用选择。
环境准备(重)
我们需要配置一个环境来运行 Python、Jupyter Notebook、相关库以及运行本书所需的代码,以快速入门并获得动手学习经验。
conda 安装
Miniconda 是一个轻量级的 Anaconda 发行版,专为需要灵活管理 Python 环境和包的用户设计。Miniconda 的特点:轻量级:仅包含 Conda 包管理和 Python 的最小安装包,占用空间小。灵活性:允许用户根据需要安装额外的库,避免不必要的依赖。跨平台:支持 Windows、macOS 和 Linux 系统。
安装 conda,Python工具大全,方便管理多个 Python 环境,必须选择跟自己环境配套的版本。
网速慢的,可以参考国内源,也可以去这里看看:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
PyTorch 安装
PyTorch的安装,结合自己想要安装的环境,动态选择即可。https://pytorch.org/
NOTE: Latest PyTorch requires Python 3.9 or later.
PyTorch Build
<pFig></pFig><quad><pos_0><pos_412><pos_498><pos_544></quad>
https://pypi.org/project/torch/
环境初始化
~/miniconda3/bin/conda init
创建虚拟环境
conda create --name deeplearning python=3.9
激活环境
conda activate deeplearning
安装插件
pip install torch==1.12.0 torchvision==0.13.0 numpy==1.21.5 matplotlib==3.5.1 requests==2.25.1 pandas==1.2.4
python -m pip install -U pip
python -m pip install -U matplotlib
退出环境
conda deactivate
列出当前有哪些环境
conda env list
删除环境
conda env remove deeplearning
总结:需要提取准备三个:1.anaconda 2.PyTorch 3.PyCharm

五、数学基础
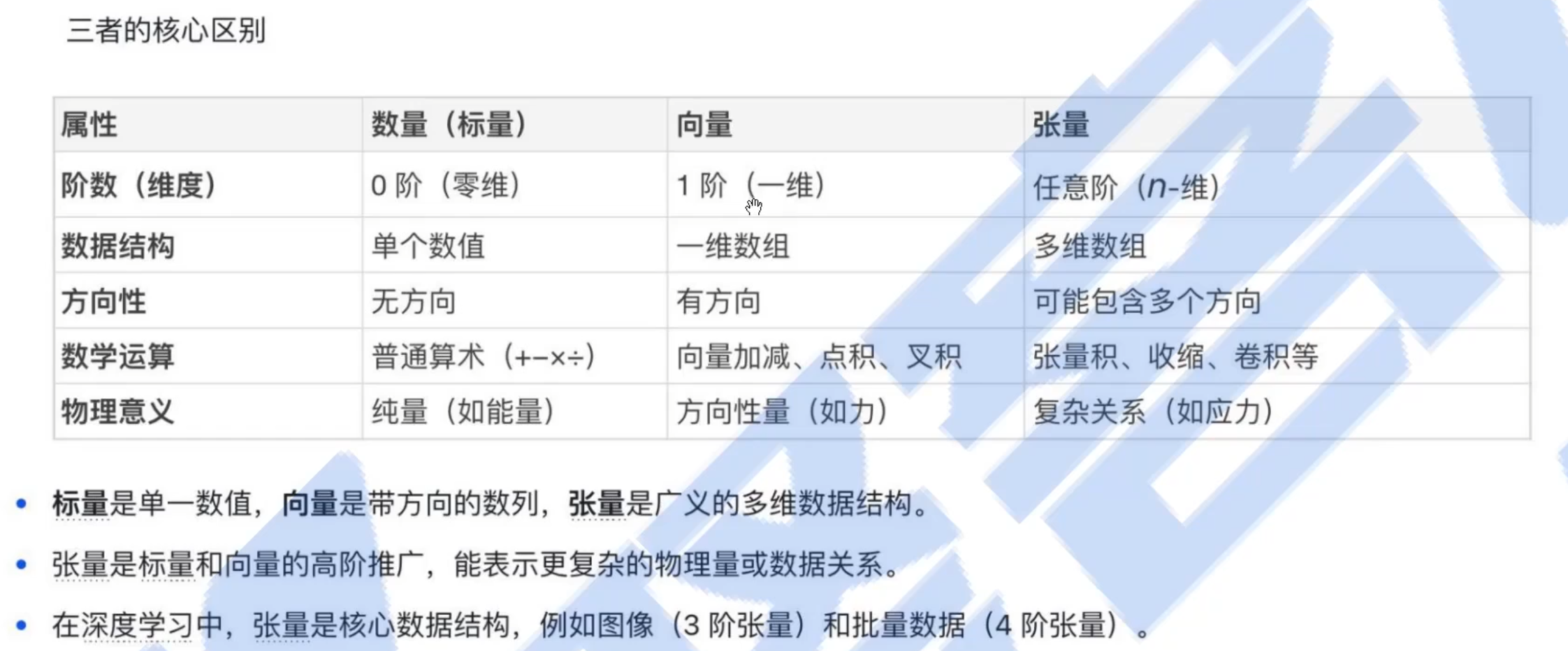
标量
定义:仅用单一数值即可完全描述的量,没有方向,只有大小(或“量级”)
数学表示:标量是零阶张量(0-dimensional),用单个实数或复数表示。
例子:温度(如25℃)、质量(如5kg)、时间(如10秒)
向量
定义:既有大小又有方向的量,可看作一维有序数组,是一阶张量。
特点:
可进行加减、标量乘法、点积、叉积等运算。
方向性体现在其分量随坐标系变化(如速度、力)。
机器学习中的特征向量(如用户画像的数值表示)
张量(Tensor)
定义:广义的多维数组,可表示任意阶数的数据。标量是0阶张量,向量是1阶张量,矩阵是2阶张量,更高维的数组为高阶张量。
六、PyTorch中的张量
首先,我们导入torch。请注意,虽然它被称为PyTorch,但是代码中使用torch而不是pytorch。
PyTorch 中张量Tensors定义
•张量表示一个由数值组成的数组,这个数组可能有多个维度。
•具有一个轴的张量对应数学上的向量(vector);
•具有两个轴的张量对应数学上的矩阵(matrix);
•具有两个轴以上的张量没有特殊的数学名称。
在PyTorch中,标量、向量、张量与数学界的标识基本一致。为了存储方便,在计算机上存储时,通常有不同的存储表达。
示例代码
import torch
# 张量的基本操作
# ==============================
# 1. 张量的基本操作
# ==============================
print("="*50)
print("1. 张量基本操作示例")
print("="*50)
# 创建张量
x = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.float32)
y = torch.randn(2, 3) # 正态分布随机张量
z = torch.zeros(3, 2)
print(f"创建张量:\n x={x}\n y={y}\n z={z}")
# 索引和切片
print("\n索引和切片:")
print("x[1, 2] =", x[1, 2].item()) # 获取标量值
print("x[:, 1:] =\n", x[:, 1:])
# 形状变换
reshaped = x.view(3, 2) # 视图操作(不复制数据)
transposed = x.t() # 转置
squeezed = torch.randn(1, 3, 1).squeeze() # 压缩维度
print(f"\n形状变换:\n 重塑后: {reshaped.shape}\n 转置后: {transposed.shape}\n 压缩后: {squeezed.shape}")
# 数学运算
add = x + y # 逐元素加法
matmul = x @ transposed # 矩阵乘法
sum_x = x.sum(dim=1) # 沿维度求和
print(f"\n数学运算:\n 加法:\n{add}\n 矩阵乘法:\n{matmul}\n 行和: {sum_x}")
# 广播机制
a = torch.tensor([1, 2, 3])
b = torch.tensor([[10], [20]])
print(a.shape)
print(b.shape)
print(f"\n广播加法:\n{a + b}")
# 内存共享验证
view_tensor = x.view(6)
view_tensor[0] = 100
print("\n内存共享验证(修改视图影响原始张量):")
print(f"视图: {view_tensor}\n原始: {x}")七、机器学习中的关键术语及其含义
神经元及神经网络
机器学习中的神经网络是一种模仿生物神经网络的结构和功能的数学模型或计算模型。它是指按照一定的规则将多个神经元连接起来的网络。
神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数。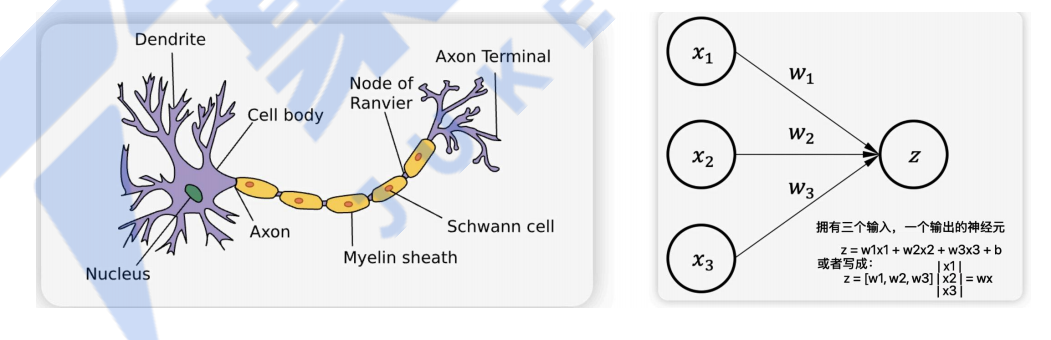
多层感知机
多个神经元可以组合一起,形成多层感知机。多层感知器(Multi-Layer Perceptron,MLP):通过叠加多层全连接层来提升网络的表达能力。相比单层网络,多层感知器有很多中间层的输出并不暴露给最终输出,这些层被称为隐含层(Hidden Layers)。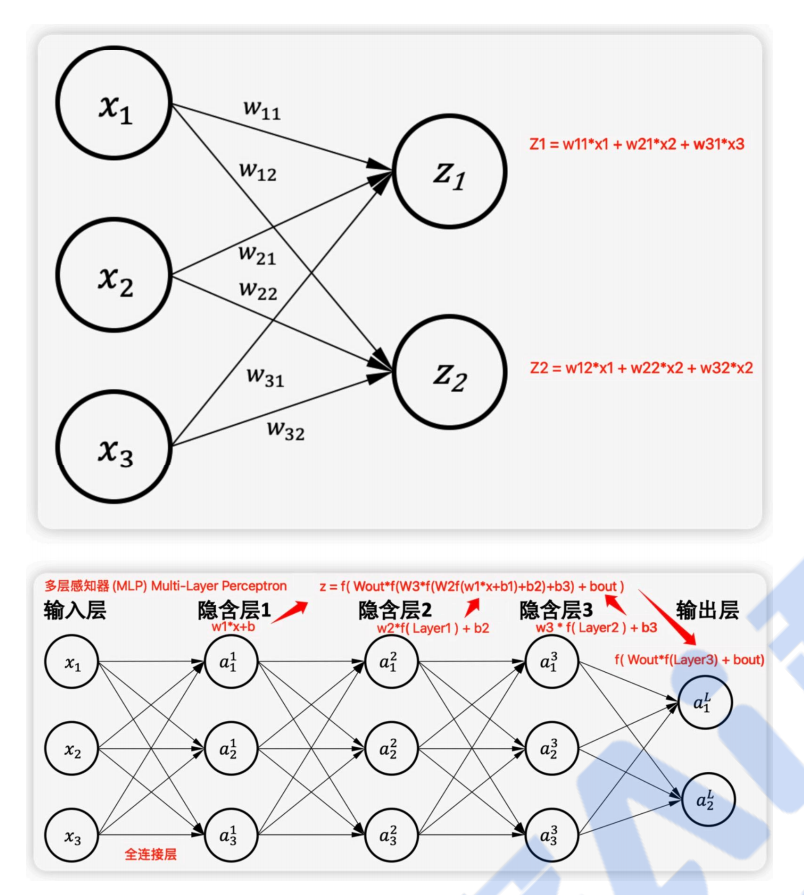
基类需要初始化训练参数、管理参数状态以及定义计算过程;神经网络模型需要实现对神经网络层和神经网络层参数管理的功能。
在机器学习编程库中,承担此功能有MindSpore的Cell、PyTorch的Module。Cell和Module是模型抽象方法也是所有网络的基类。现有模型抽象方案有两种,
一种是抽象出两个方法分别为Layer(负责单个神经网络层的参数构建和前向计算),Model(负责对神经网络层进行连接组合和神经网络层参数管理);
另一种是将Layer和Model抽象成一个方法,该方法既能表示单层神经网络层也能表示包含多个神经网络层堆叠的模型,Cell和Module就是这样实现的。
样本、目标函数、损失函数、特征及训练
样本(Sample)
定义:样本是数据集中的单个实例或数据点,通常由一组特征(自变量)和一个标签(因变量)组成。
举例:在房价预测中,一个样本可能包含房屋的面积、卧室数量、位置等特征,以及对应的房价标签。
标签(Label)
定义:标签是与样本关联的目标值或类别,用于监督学习中指导模型学习。
举例:在垃圾邮件分类中,标签可以是“垃圾邮件”或“非垃圾邮件”。
自变量(Independent Variable)
定义:自变量是用于预测或解释目标变量的输入特征,也称为特征或预测变量。
举例:在预测学生成绩时,自变量可以是学习时间、家庭收入等。
目标函数(Target Function)
定义:目标函数是模型训练过程中优化的目标,通常由损失函数构成,用于衡量模型性能。
举例:在线性回归中,目标函数是最小化均方误差(MSE)。
损失函数(Loss Function)
定义:损失函数用于量化模型预测值与真实值之间的差异,是目标函数的核心组成部分。用来衡量单个样本中计算值与标签值的差异。
举例:在分类问题中,常用的损失函数是交叉熵损失。
代价函数(Cost Function)
定义:代价函数是损失函数在所有样本上的平均值,用于衡量模型在整个数据集上的性能。损失函数与代价函数的区别在于,损失函数只适用于单个训练样本,而代价函数是参数的总代价。
举例:在逻辑回归中,代价函数是交叉熵损失的平均值。
特征(Feature)
定义:特征是描述样本的属性或变量,用于模型的输入。
举例:在图像分类中,特征可以是像素值或提取的边缘信息。
模型(Model)
定义:模型是通过机器学习算法从数据中学习到的数学表示,用于对新数据进行预测。
举例:决策树模型可以根据输入特征决定输出类别。
训练数据(Training Data)
定义:训练数据是用于训练机器学习模型的数据集,通常包含输入特征和对应的标签。
举例:在预测房价的模型中,训练数据可能包括房屋特征及其相应的价格。
测试数据(Testing Data)
定义:测试数据是用于评估模型在未知数据上表现的数据集。
举例:在训练垃圾邮件过滤器后,可以在以前从未见过的电子邮件上对其进行测试。
正则化(Regularization)
定义:正则化是一种技术,用于防止模型过度拟合,通过在损失函数中添加惩罚项来限制模型的复杂度。
举例:L2正则化通过在损失函数中添加权重平方和来限制权重的大小。
学习率(Learning Rate)
定义:学习率是一个超参数,控制模型权重相对于损失梯度的更新程度。
举例:在神经网络中,学习率决定了模型在训练期间从错误中学习的速度。
Epoch
定义:一个epoch是指在模型训练过程中对整个训练数据集进行一次完整的遍历。
举例:如果有1000个训练样本,1个epoch意味着模型已经看过所有1000个样本一次。
超参数(Hyperparameter)
定义:超参数是在训练之前设置的参数,用于控制学习过程和模型结构。
举例:学习率、批量大小(batch size)、神经网络的层数和每层的神经元数量等都是常见的超参数。
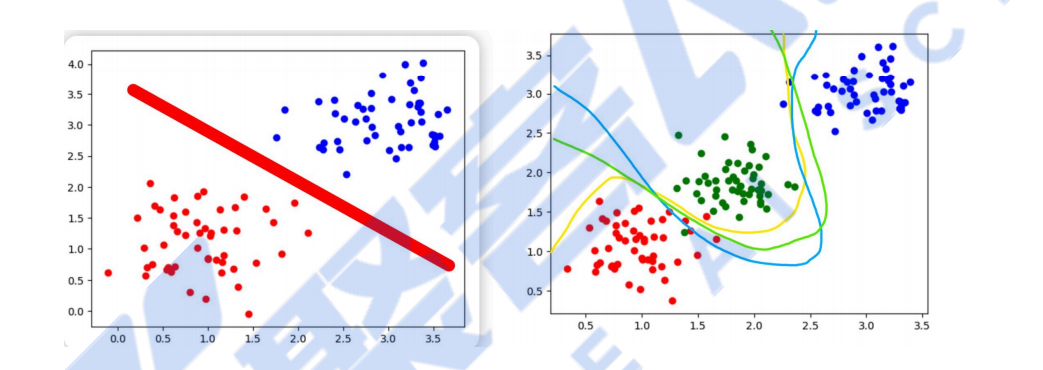
回归问题回归问题是机器学习中的一种任务,其目标是预测一个连续值作为输出。
目标变量:回归问题中的目标变量是连续的,可以取任何实数值。
特征:用于预测目标变量的输入变量,可以是连续的或离散的。
线性回归问题线性回归是一种回归模型,假设输入变量(特征)和输出变量(目标)之间存在线性关系。它通过找到一条最佳拟合直线来模拟这种关系。
逻辑回归问题逻辑回归是一种用于分类问题的统计方法,尽管名字中包含“回归”,但它实际上是一种分类算法。
定义:它通过逻辑函数(Sigmoid函数)将输入特征映射到0到1之间的概率值,表示属于某个类别的可能性。
训练找到一组参数值Weight(面积)、Weight(age)、b,能够使得在给定的训练数据集合上,所产生的集体误差最小。
预测当用户给定房屋面积、年龄后,能够给出对应的房价。这个房价越贴近于真实值,表示模型效果越好。
数据分布训练的过程就是找到一个函数,能够匹配数据的分布的过程。
示例代码
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader, TensorDataset
from torchvision import transforms
# ==============================
# 2. 数据预处理(将数据处理成模型可输入的形状)
# ==============================
print("\n" + "=" * 50)
print("2. 数据预处理示例")
print("=" * 50)
# 自定义数据集类
class CustomDataset(Dataset):
def __init__(self, data, targets, transform=None):
self.data = data
self.targets = targets
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data[idx]
label = self.targets[idx]
if self.transform:
sample = self.transform(sample)
return sample, label
# 创建模拟数据
num_samples = 100
data = np.random.randn(num_samples, 3, 32, 32) # 100张32x32的RGB图像
targets = np.random.randint(0, 10, num_samples) # 0-9的标签
# 定义转换管道
transform = transforms.Compose([
transforms.ToTensor(), # 转为张量
transforms.Normalize((0.5,), (0.5,)), # 标准化
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(15) # 随机旋转±15度
])
# 创建数据集和数据加载器
dataset = CustomDataset(data, targets, transform=transform)
dataloader = DataLoader(dataset, batch_size=16, shuffle=True, num_workers=0)
# 演示数据加载
print(f"数据集大小: {len(dataset)}")
batch = next(iter(dataloader))
print(f"批数据形状: 输入={batch[0].shape}, 标签={batch[1].shape}")
# 使用TensorDataset的简化方法
tensor_x = torch.randn(100, 5) # 特征
tensor_y = torch.randint(0, 2, (100,)) # 二分类标签
tensor_dataset = TensorDataset(tensor_x, tensor_y)
dataloader_simple = DataLoader(tensor_dataset, batch_size=10, shuffle=True)矩阵代码示例
import torch
# ==============================
# 3. 线性代数
# ==============================
print("\n" + "=" * 50)
print("3. 线性代数操作示例")
print("=" * 50)
# 矩阵运算
A = torch.tensor([[1, 2], [3, 4]], dtype=torch.float32)
B = torch.tensor([[5, 6], [7, 8]], dtype=torch.float32)
# 基本运算
print(f"矩阵加法:\n{A + B}")
print(f"元素乘法:\n{A * B}")
print(f"矩阵乘法:\n{torch.mm(A, B)}")
# 高级运算
print(f"\n行列式: {torch.det(A):.2f}")
print(f"逆矩阵:\n{torch.inverse(A)}")
# 使用新的特征值计算方法
eigenvalues = torch.linalg.eigvals(A)
print(f"特征值:\n{eigenvalues}")
# 解线性方程组
# AX = B → X = A^{-1}B
X = torch.mm(torch.inverse(A), B)
print(f"\n解线性方程组 AX=B:\n{X}")
# 奇异值分解
U, S, Vh = torch.linalg.svd(A)
print(f"\n奇异值分解:")
print(f"U:\n{U}\nS:\n{torch.diag(S)}\nVh (共轭转置):\n{Vh}")
# 矩阵范数
print(f"\nFrobenius范数: {torch.linalg.matrix_norm(A, ord='fro'):.2f}")
print(f"谱范数: {torch.linalg.matrix_norm(A, ord=2):.2f}")import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'、'Agg' 等
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# ==============================
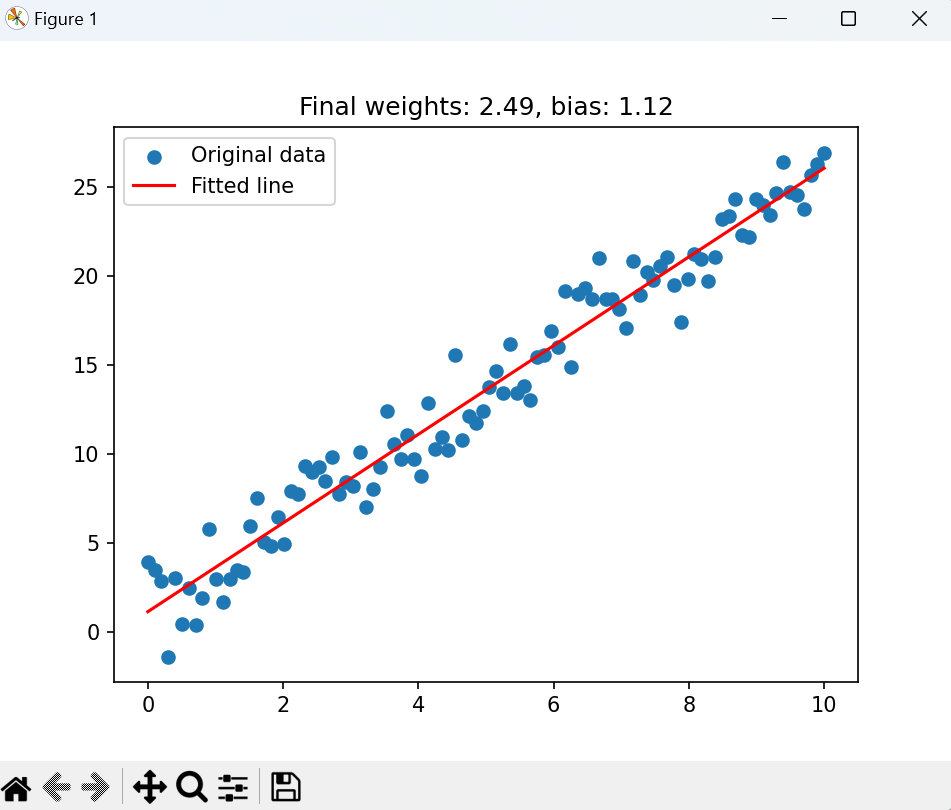
# 综合应用:线性回归
# ==============================
print("\n" + "=" * 50)
print("综合应用: 线性回归")
print("=" * 50)
# 生成数据
torch.manual_seed(42)
X = torch.linspace(0, 10, 100).reshape(-1, 1)
print(X.shape)
true_weights = 2.5
true_bias = 1.0
y = true_weights * X + true_bias + torch.randn(X.size()) * 1.5

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)