大模型 RAG 技术深度解析:原理架构、通俗解读与实战代码(大模型应用开发)
摘要:生成式大模型在实际落地中面临知识幻觉、实时性差、领域知识薄弱三大核心痛点,检索增强生成(Retrieval-Augmented Generation, RAG)作为轻量级、低成本、高可控的大模型落地方案,无需微调即可为模型注入外部私有知识与实时信息,成为企业级大模型应用的首选技术。本文从通俗化视角解构 RAG 核心逻辑,详解标准技术架构与关键模块,并提供可直接落地的工业级 Python 实战代码,覆盖从文档加载、向量存储、语义检索到答案生成的全流程,助力开发者快速掌握 RAG 工程化实践。
关键词:大模型;RAG;检索增强生成;向量数据库;LangChain;大模型落地
目录
一、引言
随着 GPT、LLaMA、Qwen 等大模型的快速迭代,通用对话能力已趋于成熟,但在企业私有数据问答、专业领域知识服务、实时信息检索等场景中,原生大模型存在显著缺陷:
- 知识幻觉:生成虚假、无依据的答案;
- 知识滞后:模型训练数据固定,无法获取最新信息;
- 数据安全:无法直接接入企业内部私有数据;
- 微调成本高:领域知识更新频繁,微调耗时耗力。
检索增强生成(RAG)完美解决上述问题,它通过外部知识库检索 + 大模型生成的范式,让大模型基于真实、可控的外部知识生成答案,是当前大模型产业化落地的核心技术底座。
二、通俗化解构:RAG 到底是什么?
我们用开卷考试的类比,彻底理解 RAG 的核心逻辑:
- 闭卷考试 = 原生大模型:模型依靠训练时记住的知识答题,会记错、记漏,无法获取新书知识;
- 开卷考试 = RAG 增强大模型:模型不强行记忆所有知识,而是先查阅指定的参考资料,再结合资料内容组织答案。
核心区别
表格
| 方案 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 原生大模型 | 依赖预训练知识 | 无需外部数据 | 幻觉、滞后、不可控 |
| 模型微调 | 重新训练注入知识 | 效果贴合 | 成本高、更新难、有遗忘 |
| RAG | 实时检索外部知识生成 | 零微调、低成本、易更新、安全可控 | 依赖检索精度 |
一句话定义 RAG:从外部私有 / 实时知识库中检索相关知识,将知识与用户问题拼接为提示词,输入大模型生成精准、可信的答案。
三、RAG 标准技术架构(核心模块)
工业级 RAG 系统分为离线构建知识库和在线问答生成两大流程,共 5 个核心模块:
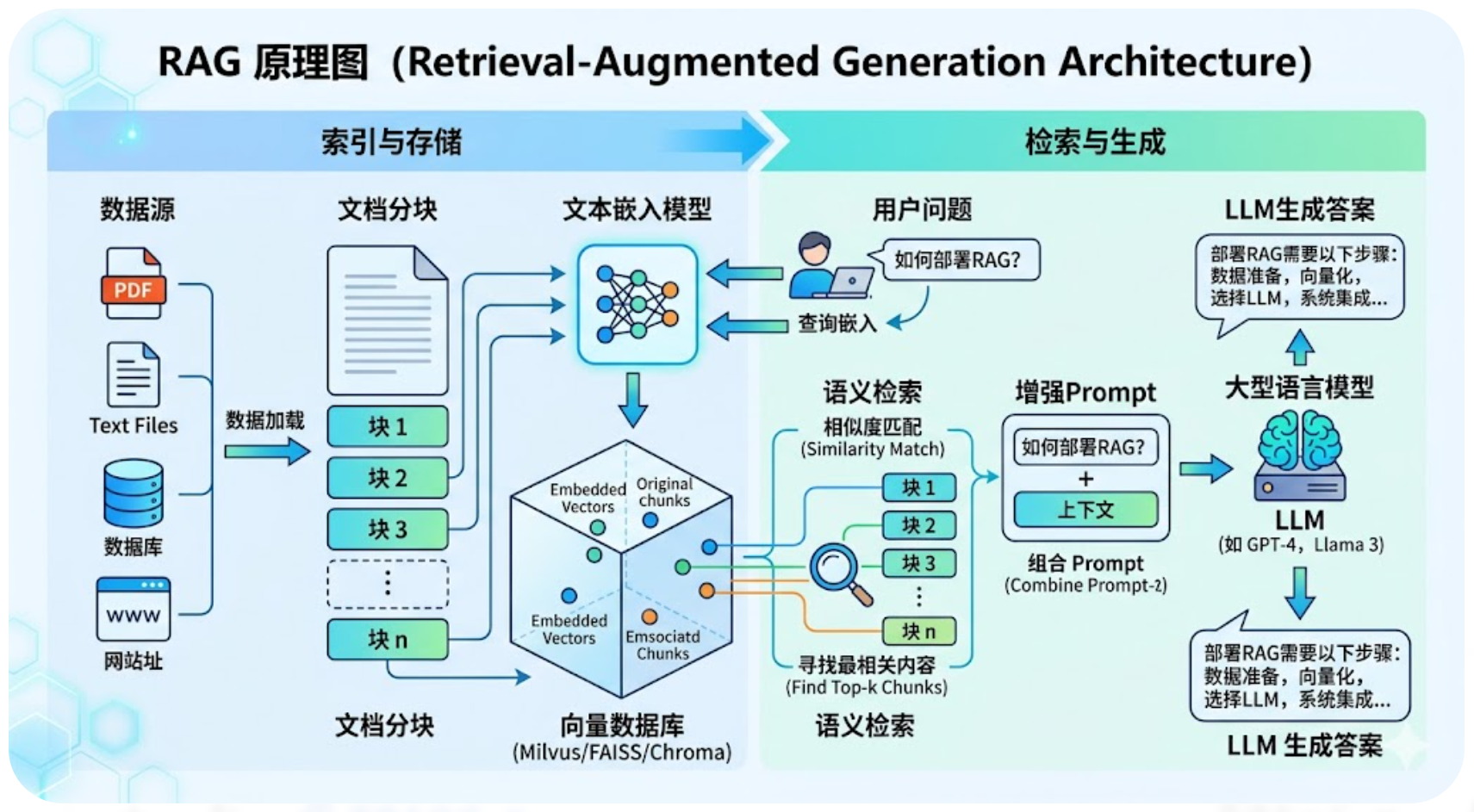
1. 离线流程:知识库构建
- 文档加载:读取 PDF/Word/Excel/ 网页 / 数据库等异构数据;
- 文本分块:将长文本切分为合适长度的片段(Chunk);
- 向量化:通过 Embedding 模型将文本转为向量(数值化表示语义);
- 向量存储:将向量与原文存入向量数据库(FAISS、Milvus、Chroma)。
2. 在线流程:检索增强生成
- 用户问题向量化:将用户查询转为同维度向量;
- 语义检索:向量数据库匹配最相似的文本片段;
- 提示词拼接:将检索结果 + 用户问题输入大模型;
- 答案生成:大模型基于检索知识生成最终回答。
四、核心技术选型(工业级标准)
- 向量模型:BGE-small、text2vec、m3e(中文开源最优);
- 向量库:FAISS(轻量本地)、Milvus(分布式生产);
- 大模型:Qwen、LLaMA、ChatGLM、通义千问、文心一言;
- 开发框架:LangChain(快速开发)、LlamaIndex(专注检索)。
五、RAG 工业级实战代码(完整可运行)
本实战基于 LangChain + FAISS向量数据库 + 向量模型 + 开源大模型 实现完整 RAG 流程,支持本地私有部署,无外部 API 依赖。
环境安装
pip install langchain==0.2.17 langchain-community==0.2.19 langchain-core==0.2.43 langchain-text-splitters==0.2.4
完整 RAG 代码实现
使用的是Ollama管理的本地模型qwen2.5:1.5b以及向量化模型mxbai-embed-large:latest
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.llms import Ollama
# from langchain.llms import HuggingFacePipeline
# from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
# ===================== 1. 配置参数 =====================
EMBEDDING_MODEL_PATH = "mxbai-embed-large:latest"
# 文本分块大小
CHUNK_SIZE = 300
CHUNK_OVERLAP = 50
# 本地大模型(可替换为Qwen-7B、ChatGLM3等)
LLM_MODEL_PATH = "qwen2.5:1.5b"
# ===================== 2. 加载向量化模型 =====================
print("正在加载 Embedding 模型...")
embeddings = OllamaEmbeddings(
model=EMBEDDING_MODEL_PATH
)
print("✅ Embedding 模型加载完成")
# ===================== 3. 加载并处理文档 =====================
# 支持TXT/PDF,替换为你的私有文档路径
print("正在加载文档...")
try:
loader = TextLoader("./rag_knowledge.txt", encoding="utf-8")
documents = loader.load()
print(f"✅ 文档加载完成,共 {len(documents)} 个文档")
except FileNotFoundError:
print("❌ 错误:找不到 rag_knowledge.txt 文件!")
print("请确保文件在当前目录,或修改为正确的文件路径。")
exit(1)
# 文本分块(RAG核心预处理步骤)
print(f"正在分割文本 (chunk_size={CHUNK_SIZE}, chunk_overlap={CHUNK_OVERLAP})...")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP
)
split_docs = text_splitter.split_documents(documents)
print(f"✅ 文本分割完成,共 {len(split_docs)} 个文本块")
# ===================== 4. 构建FAISS向量库 =====================
print("正在构建 FAISS 向量库...")
db = FAISS.from_documents(split_docs, embeddings)
print("✅ FAISS 向量库构建完成")
# 构建检索器(top_k=3:返回最相关的3条知识)
retriever = db.as_retriever(search_kwargs={"k": 4})
# ===================== 5. 加载本地大模型 =====================
# 使用 Ollama 加载 qwen2.5:1.5b 模型
print("正在加载 LLM 模型...")
llm = Ollama(
model="qwen2.5:1.5b",
temperature=0.1,
top_p=0.95,
repeat_penalty=1.1
)
print("✅ LLM 模型加载完成")
#如果使用的是从huggingface上下载的模型用以下的代码
# tokenizer = AutoTokenizer.from_pretrained(LLM_MODEL_PATH, trust_remote_code=True)
# model = AutoModelForCausalLM.from_pretrained(
# LLM_MODEL_PATH,
# torch_dtype="auto",
# device_map="auto",
# trust_remote_code=True
# ).eval()
#
# # 构建生成管道
# pipe = pipeline(
# "text-generation",
# model=model,
# tokenizer=tokenizer,
# max_new_tokens=512,
# temperature=0.1,
# top_p=0.95,
# repetition_penalty=1.1
# )
# llm = HuggingFacePipeline(pipeline=pipe)
# ===================== 6. RAG核心:检索+生成 =====================
def rag_chat(query: str):
print(f"\n🔍 正在处理问题:{query}")
# 1. 语义检索相关知识
print("正在检索相关知识...")
retrieved_docs = retriever.invoke(query)
#合并成上下文字符串
context = "\n".join([doc.page_content for doc in retrieved_docs])
# 2. 构造提示词
prompt = f"""
请根据以下参考知识回答用户问题,禁止编造答案。
参考知识:{context}
用户问题:{query}
回答:
"""
# 3. 大模型生成答案
answer = llm.invoke(prompt)
return answer, retrieved_docs
# ===================== 7. 测试RAG系统 =====================
if __name__ == "__main__":
if __name__ == "__main__":
print("=" * 60)
print("🤖 物流行业信息咨询智能问答系统")
print("=" * 60)
print("💡 提示:输入问题后按回车提交,输入'退出'结束程序\n")
# 多轮对话循环
while True:
# 获取用户输入
user_query = input("📝 请输入您的问题:").strip()
# 检查是否退出
if user_query.lower() in ["退出", "exit", "quit", "q"]:
print("\n👋 感谢使用,再见!")
break
# 跳过空输入
if not user_query:
print("⚠️ 问题不能为空,请重新输入\n")
continue
try:
# 调用 RAG 系统
answer, docs = rag_chat(user_query)
# 打印结果
print("\n" + "=" * 60)
print("📚 检索到的参考知识:")
for i, doc in enumerate(docs, 1):
print(f"\n【知识{i}】:{doc.page_content}")
print("=" * 60)
print("💡 RAG 生成答案:")
print(answer)
print("=" * 60)
print() # 空行,便于阅读
except Exception as e:
print(f"\n❌ 回答失败:{str(e)}")
print("请检查 Ollama 服务是否正常启动\n")测试用文档(rag_knowledge.txt)
RAG全称Retrieval-Augmented Generation,即检索增强生成,是大模型落地的核心技术方案,核心逻辑是通过外部知识库检索精准知识,辅助大模型生成答案,从根源解决大模型原生缺陷。
原生大模型存在三大核心问题:知识幻觉(编造答案)、知识滞后(训练数据固定无实时信息)、无法接入企业私有数据,RAG技术完美规避了以上问题。
RAG系统分为离线构建知识库和在线问答生成两大核心流程。离线流程包括文档加载、文本分块、向量嵌入、向量存储;在线流程包括用户问题向量化、语义检索、提示词拼接、大模型答案生成。
RAG的核心组件包含:异构文档加载器、递归文本分块器、语义向量模型、向量数据库、检索器、大模型生成器、提示词工程模块。
与大模型微调相比,RAG具备零微调、低成本、知识更新便捷、数据安全性高、部署速度快的优势,无需重新训练模型,仅需更新外部知识库即可迭代知识。
RAG的主流应用场景覆盖企业内部智能问答、私有文档解析、法律专业咨询、医疗知识问答、教育题库答疑、实时新闻资讯生成、金融研报分析、客服智能对话等。
工业级RAG技术栈:向量模型选用BGE、m3e、text2vec等中文开源模型;向量数据库选用FAISS(本地轻量)、Milvus(分布式生产)、Chroma;开发框架选用LangChain、LlamaIndex;大模型选用Qwen、ChatGLM、LLaMA等开源模型。
RAG工程化优化关键技术:文本分块策略优化、混合检索(语义检索+关键词BM25检索)、检索结果重排序、提示词约束、向量库索引优化、多文档融合检索。
RAG的核心特点:答案可追溯、知识可控、无需训练、支持实时数据更新、适配私有数据部署,是企业级大模型应用的首选方案。
RAG与传统检索的区别:传统检索仅返回文档片段,无自然语言答案;RAG结合大模型生成能力,将检索结果转化为流畅、精准、结构化的自然语言回答。
RAG的适用范围:适用于所有需要专业知识、私有数据、实时信息的大模型应用,尤其适合知识更新频繁、数据安全性要求高的政企、金融、医疗、法律行业。
运行结果


六、RAG 工程优化关键技巧
- 分块优化:根据文档类型调整分块大小,专业文档使用更小分块;
- 重排序(Rerank):检索后增加二次精排模型,提升相关性;
- 混合检索:结合关键词检索(BM25)+ 语义检索,提升召回率;
- 提示词优化:严格约束大模型仅使用检索知识回答;
- 向量库优化:生产环境使用 Milvus 替代 FAISS,支持分布式与高并发。
七、总结
RAG 作为大模型落地的最优轻量级方案,彻底解决了原生大模型的幻觉、知识滞后、私有数据接入难题,具备零微调、低成本、易维护、高可控的核心优势,是企业级 AI 应用的必备技术。
本文提供的实战代码可直接用于私有知识库问答、文档解析、智能客服等场景,开发者可根据业务需求替换向量模型、大模型与向量库,快速完成工业级 RAG 系统搭建。
在大模型产业化趋势下,RAG 不再是辅助技术,而是大模型从 “通用能力” 走向 “专业价值” 的核心桥梁。
参考资料
- LangChain 官方文档:https://python.langchain.com/
- FAISS 向量检索库:https://ai.meta.com/tools/faiss/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)