小白程序员快看!收藏这份 Anthropic 大模型技能学习指南(从零到实战)
本文深入解析 Anthropic 智能体生态四大核心组件(MCP、Tools、Skills、Subagents)的区别与协作,阐述它们如何构建灵活强大的智能系统。文章详细介绍官方现成 Skills(如 Office 文档处理),并手把手教你从零创建自定义 Skill,包含命名技巧、结构规范、实战案例等,助你快速掌握大模型技能开发,轻松收藏!
一、概述
上篇文章《[构建智能体的专业技能树 - 搞懂 Agent Skills(上篇)]我们阐述了 Skills 是什么、为什么需要它。这篇文章我们将围绕Skills、Tools、MCP、Subagents 四个组件有什么区别、Anthropic 官方做好了哪些现成 Skills、如何从零创建一个自定义 Skill 的完整流程 这些四个方面来进行讲解。
二、智能体生态系统概览
在 Anthropic 构建的智能体生态中,多种技术组件各司其职、协同配合,共同构成了一个灵活而强大的智能体系统:
- MCP :提供所需的上下文
- Tools:提供原子能力
- Skills:用于可重复的主线程工作流
- Subagents:用于多线程和并行处理
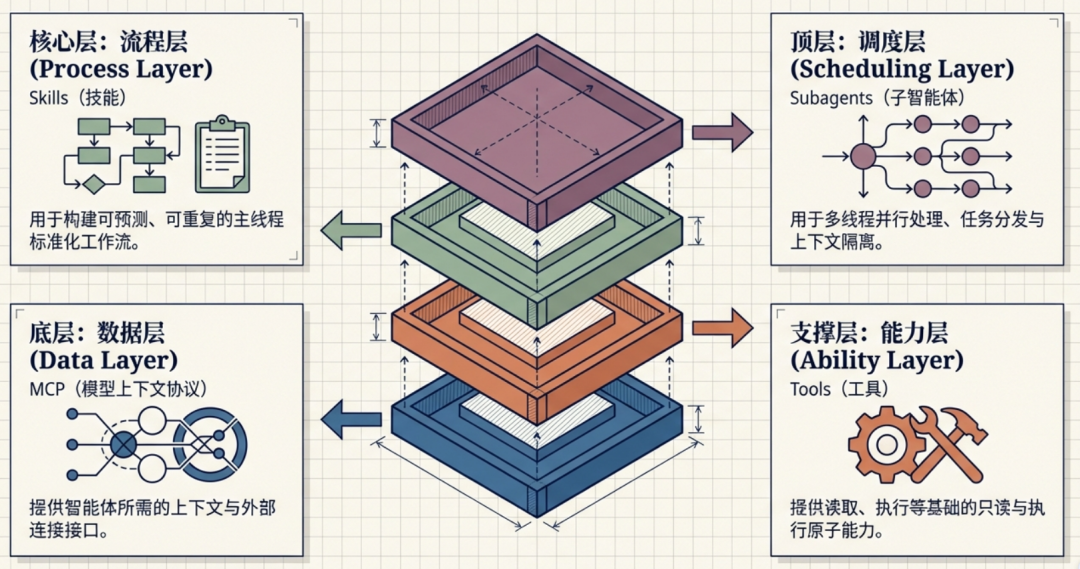
这四者的关系,本质上类似于“数据层 + 能力层 + 流程层 + 调度层”,理解这四层的分工,是构建复杂智能体系统的第一步。下面我们将逐一拆解每对组件之间的关系,来建立起清晰的认知框架。
2.1 Skills vs MCP:菜谱 vs 食材供应链
在理解这两个组件的区别之前,我们可以用一个形象的比喻来建立直觉:
MCP(Model Context Protocol,模型上下文协议) 解决的核心问题是“数据从哪来”。它像一个通用的数据接口,将智能体连接到外部的数据库、API、云存储等各种数据源。没有 MCP,智能体就像一位巧妇,虽有满腹烹饪技巧,却面临“无米之炊”的窘境。
Skills 解决的核心问题是“数据怎么处理”。它定义了拿到数据之后,应该遵循怎样的流程、使用什么方法、产出什么格式的结果。Skills 是标准化的操作手册,确保每次执行都能获得一致、可靠的结果。
| 对比维度 | MCP | Skills |
|---|---|---|
| 核心功能 | 连接智能体与外部系统和数据 | 定义可重复的工作流 |
| 数据来源 | 外部数据库等 | 利用 MCP 提供的工具和数据 |
| 使用场景 | 获取模型不知道的外部数据 | 教智能体如何处理这些数据 |
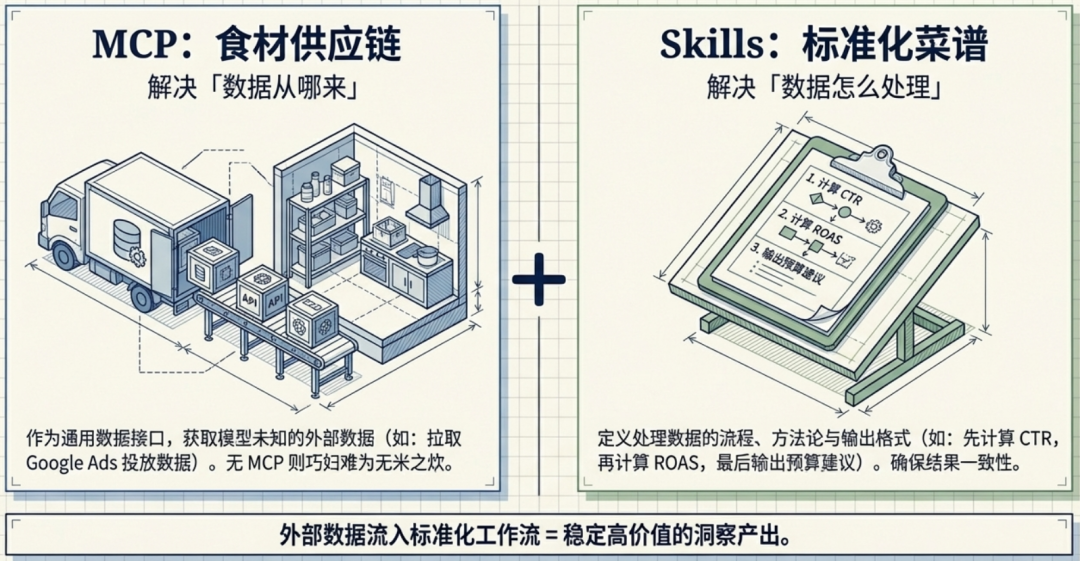
简单来说:MCP 就像带来所有底层工具和资源的连接器,Skills 则是使用这些工具构建特定工作流的可重复流程。
举个实际的例子: 你要做一份营销分析报告。
- MCP 负责:从 Google Ads、Facebook Ads、公司内部数据库里拉取投放数据
- Skills 负责:定义“拿到数据后,先计算 CTR、再计算 ROAS、然后对比各渠道效率、最后给出预算调整建议”的完整处理流程
两者缺一不可——没有 MCP,你无数据可用;没有 Skills,数据只是一堆数字,无法转化为有价值的洞察。
2.2 Skills vs Tools:锤子 vs 木工手册
打一个非常形象的比喻来区分这两个概念:
想象你有一些工具:锤子、锯子和钉子。你有一个技能:如何建造书架。
Tools(工具) 提供的是底层原子能力——读文件、写文件、执行代码、搜索网页。它们是完成任务的“原材料能力”,每个工具都是独立、可调用的基础单元。
Skills(技能) 提供的是使用这些工具的方法论——先量尺寸、再切割、然后组装、最后上漆。Skills 是对工具的有序编排,是将基础能力组合成完整工作流的“说明书”。
| Tools(工具) | Skills(技能) |
|---|---|
| 提供访问文件系统、执行代码等底层能力 | 扩展智能体的能力,提供专业知识和指令 |
| 是完成任务的原子操作单元 | 引入需要执行的额外文件和脚本 |
| 支持文件编辑、代码执行、数据查询等 | 创建可预测、可重复的工作流 |
二者关键区别在于 Token 消耗机制:
- Tools定义(名称、描述、参数)始终存在于上下文窗口中。这意味着如果你配置了 20 个工具,它们的完整定义会持续占用宝贵的上下文空间。
- Skills采用渐进式加载机制,只在需要时才会加载具体内容。如果你有 20 个 Skills,只有它们的名称和描述会常驻上下文,具体指令、脚本和资源按需加载
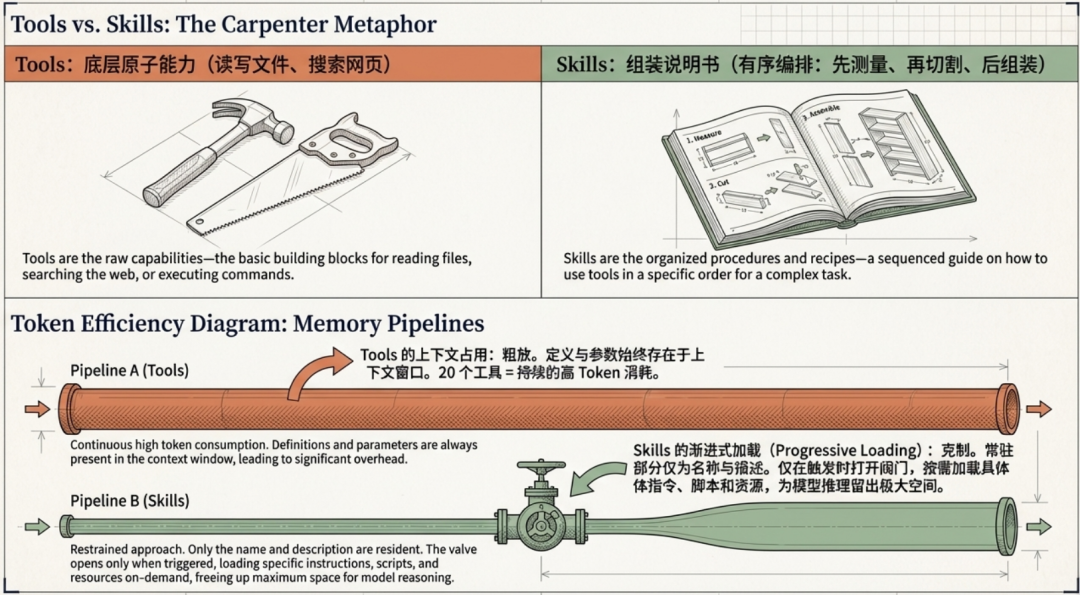
Skills的这种设计带来的Token 节省效果非常可观——尤其是在处理大量工具或复杂工作流时,技能机制能够显著降低上下文窗口的占用,为模型推理留出更多空间。
2.3 Skills vs Subagents:操作手册 vs 专项员工
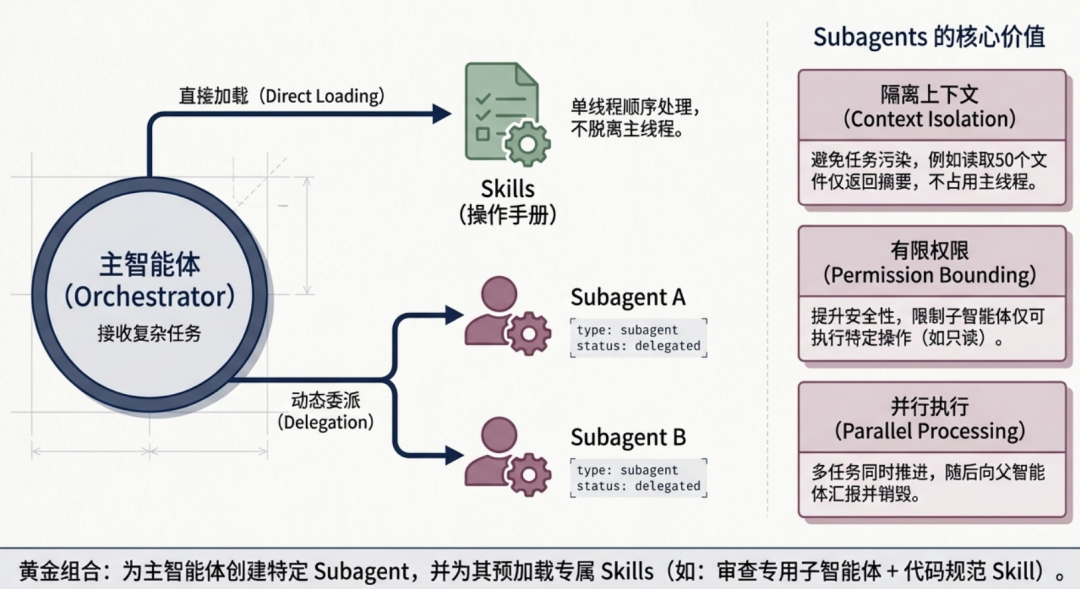
Subagent(子智能体) 是一种为执行单一、明确定义的任务而专门构建的特化 AI Agent。它并非孤立工作,而是在一个 Orchestrator(编排器)的协调下,与其他 Subagent 协同完成复杂的用户请求。
2.3.1 Subagents 的工作方式
主智能体可以根据任务需求动态创建 Subagents,这些子智能体在执行完毕后向父智能体汇报结果。子智能体可以通过多种方式创建:
- Claude Code
- Agent SDK
- 自定义实现
2.3.2 Subagents 的价值
| 特性 | 说明 | 实际收益 |
|---|---|---|
| 隔离上下文 | 为每个子任务提供独立的上下文环境 | 避免任务间的上下文污染,降低主线程的 Token 消耗 |
| 有限权限 | 限制子智能体的工具使用权限 | 提升安全性,防止权限越界操作 |
| 技能访问 | 每个子智能体可以加载特定的 Skills | 实现能力的按需分配和复用 |
2.3.3 什么时候用 Subagent 而不是 Skill
- 需要隔离上下文时:比如需要读取 50 个文件但只返回摘要,不想让这些内容占用主线程上下文
- 需要并行执行时:多个子任务互不依赖,可以同时执行,大幅提升效率
- 需要限制权限时:只允许某个子智能体执行特定操作(如只读文件、禁止写入)
2.3.4 组合使用
二者是可以组合使用的, 比如主 Agent 可以创建一个“代码审查子智能体”,并为其预加载“代码规范”和“安全审查清单”等 Skills。这个子智能体的唯一任务就是分析和审查代码库,完成后返回审查结果,然后被销毁——整个过程对主线程的上下文毫无影响
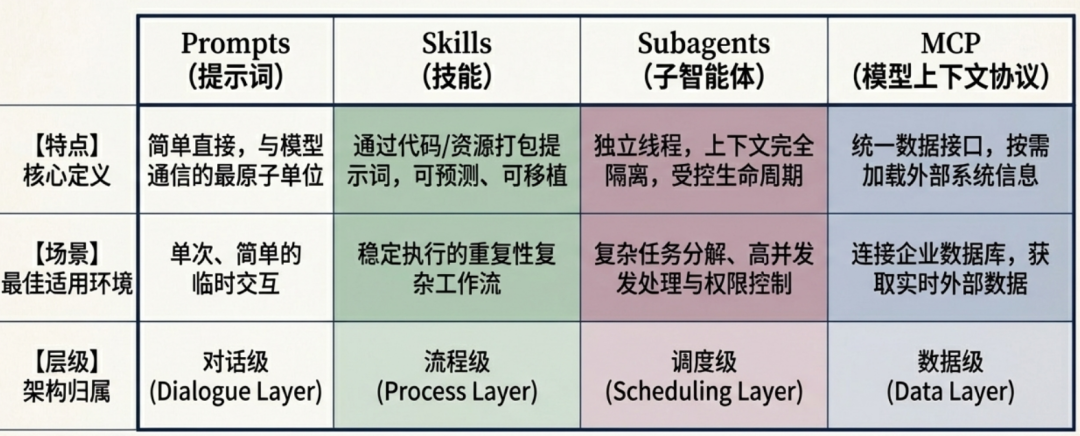
2.4 AI 生态系统组件对比
为了更清晰地理解各组件的定位,这里列出一个全景对比:
2.5 综合示例:客户洞察分析器
举一个综合案例,展示四大组件如何协同工作,构成一个功能完备的智能体系统:
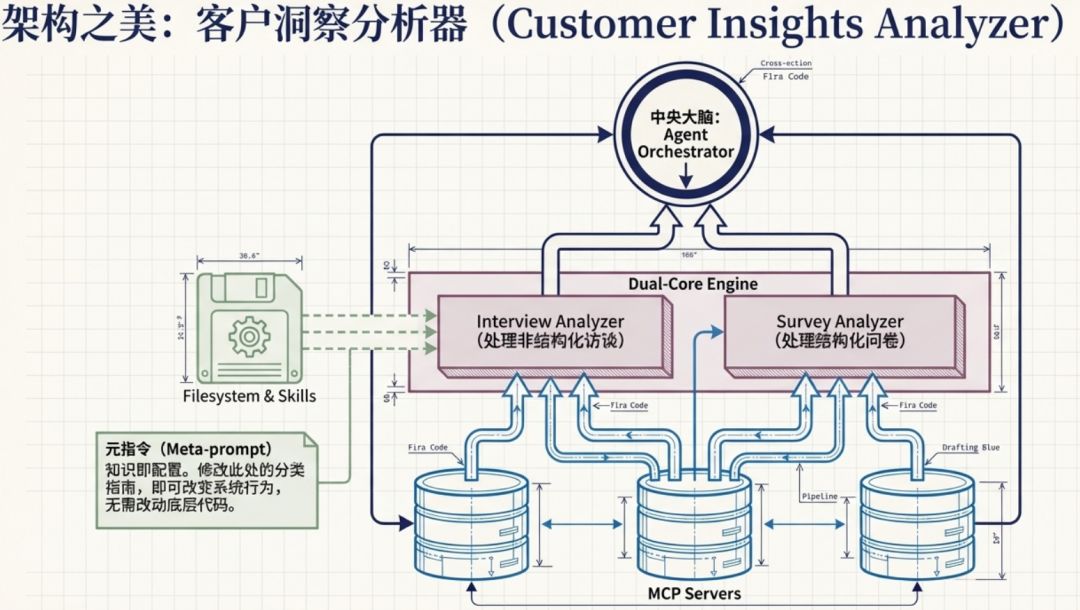
各组件角色定位:
- Agent 是整个架构的大脑与指挥中心。 LLM 作为推理引擎,能够理解复杂指令、进行多步思考和决策规划。Agent 的主要职责是接收高层任务目标,将其拆解为可执行的子任务,协调下方的 Interview Analyzer 和 Survey Analyzer 两个子分析器并行工作,最后整合各分析器的输出结果,生成统一、结构化的客户洞察报告。
- Interview Analyzer & Survey Analyzer 是 Agent 的执行手臂。 Interview Analyzer 专注于处理非结构化的客户访谈记录,运用自然语言理解技术提取关键观点、情感倾向和深层需求;Survey Analyzer 则针对结构化的问卷数据进行统计分析、模式识别和趋势归纳。这两个工具相互独立又可并行运行,各自调用 Filesystem 中的 Skills 和 LLM 能力进行深度处理。
- Filesystem 与 Skills 层构成了系统的能力基础设施。 左侧的指导文档(“A guide for how to categorize feedback and how to summarize findings”)作为元指令(Meta-prompt),定义了系统处理数据的标准方法论——包括分类维度、总结框架和质量标准。实现了"知识即配置"的理念:通过修改指导文档即可调整系统行为,无需改动底层代码。
- MCP 服务器层是系统的外部连接关键。 包含三个 MCP 服务器,Agent 能够以统一的方式调用不同服务商的 API,无需关心底层接口差异。
工作流程:
主智能体(配备工具) ↓通过 MCP 服务器获取工具 ↓分派子代理分析客户 ↓并行分析客户访谈和调查 ↓使用 Skills 进行可预测的分析
各组件作用:
| 组件 | 作用 |
|---|---|
| MCP | 从外部引入数据 |
| 子代理 | 并行化执行,在独立线程和上下文中运行 |
| Skills | 以可预测、可重复、可移植的方式消费所有信息,生成标准化输出 |
三、探索 Anthropic 官方 Skills
理解了四大组件的关系之后,让我们来看看 Anthropic 官方已经为我们准备好了哪些现成的 Skills。这些 Skills 既是开箱即用的实用工具,也是学习构建高质量 Skills 的优秀范例。
3.1 官方入口
- 总仓库:anthropics/skills —— 所有官方 Skills 的集中存放地
- 机制说明:Skills explained —— 官方博客对 Skills 机制的详细解读
3.2 Office 文档类 Skills(四件套)
Anthropic 官方提供了处理常见办公文档格式的四个核心 Skills,覆盖了日常工作中最常用的文件类型:
| Skill | 功能 | 链接 |
|---|---|---|
| xlsx | Excel 电子表格处理 | skills/xlsx |
| docx | Word 文档处理 | skills/docx |
| PDF 文档处理 | skills/pdf | |
| pptx | PowerPoint 演示文稿处理 | skills/pptx |
3.3 skill-creator:从模板到可运行产物
skills/skill-creator/scripts/ 是"把一个 skill 从模板/配置变成可运行产物"的流水线入口。如果你希望深入理解 Skill 的构建机制,建议带着以下三个问题去阅读相关代码:
- 我改了 prompt 或配置,哪些文件会变?
- 更新动作的最小输入是什么(哪些字段必填)?
- 失败时能从哪里定位(日志/报错点/中间产物)?
3.4 Claude Desktop:Skill Creator(本地迭代入口)
Claude Desktop 里的一个能力开关,用来让 Desktop 识别并加载本地 Skills,并在修改后触发更新。这是本地开发和调试 Skills 最便捷的入口。
路径:Claude Desktop > Capabilities > Skill Creator
使用方式(最小闭环操作流程):
- 从官方仓库挑选一个 skill(优先选最简单、依赖少的)
- 复制到本地 Skills 目录(保持原始结构,先不要"扁平化")
- 只改一处(例如 prompt)并记录改动点
- 通过 Skill Creator 触发 update
- 回到 Desktop 测试:输入一个最小样例,确认行为是否变化
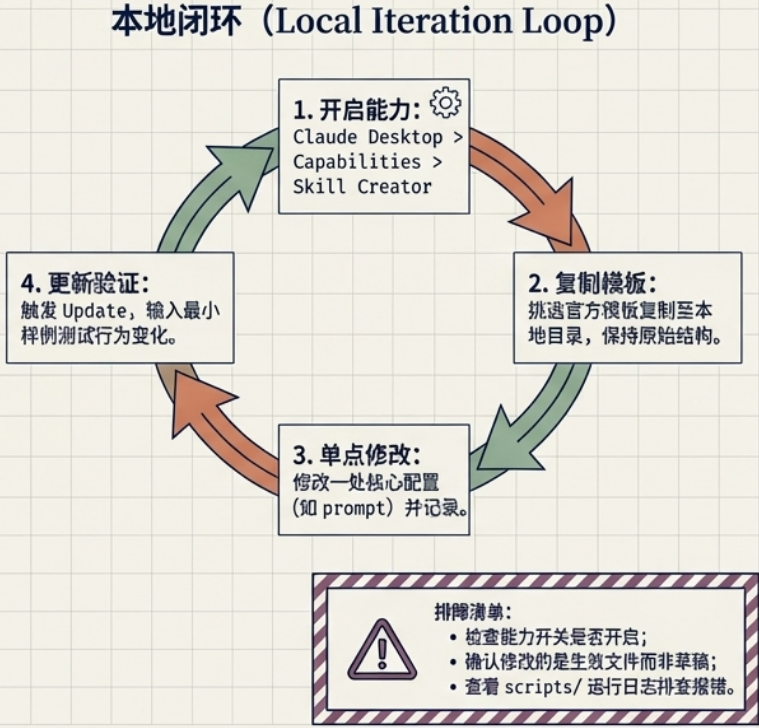
排障建议(最常见的 3 类问题):
- Desktop 看不到 skill:先检查开关是否开启,其次确认本地目录结构是否符合预期
- update 没生效:确认你修改的是 Desktop 会读取/打包的文件,而不是未被引用的草稿文件
- 运行时报错:优先找日志/控制台输出,再回到
skill-creator/scripts/看报错对应的阶段
四、从零创建自定义 Skills
理论知识和现成案例都了解之后,现在让我们真刀真枪地动手创建自己的 Skill。
4.1 Skill 的基本结构
每个 Skill 都有一个必需的 SKILL.md 文件,其中包含 YAML 格式的前置元数据(name 和 description)。在 SKILL.md 的底层,包含 Skill 的核心内容,以及对脚本、附加文本文件、必需资源的引用——这些资源只有在需要时才会被加载。

4.2 Skills 的命名技巧
Skills 的 name 不仅是标识符,更是 AI 理解和选择 Skills 的重要依据。好的 name 应该清晰、准确地传达 Skills 的核心功能。name 应该采用「动词+ing」的格式,例如 generating-practice-questions 或 analyzing-time-series。这种命名模式能够清晰地表达 Skills 的动作属性,让智能体更容易判断何时应该调用该 Skill。
一个好的 description 不仅要说明 Skills 做什么,还要明确说明何时使用以及如何使用。在撰写 description 时,应该特别关注那些能够触发 Skills 使用的关键词和短语。
description 还应该包含 Skills 的输入要求、输出格式以及任何特殊的使用条件。一个完整的 description 应该让使用者(无论是人类还是智能体)无需阅读具体实现代码,就能理解如何有效地使用该 Skill。
4.3 字段约束条件
其中 name 和 description 是必选字段,需要遵循如下约束:

| 必填字段 | 约束条件 |
|---|---|
| name | • 最多 64 个字符 • 只能包含小写字母、数字和连字符 • 不能以连字符开头或结尾 • 必须与父目录名匹配 • 建议使用动名词形式(动词±ing) |
| description | • 最多 1024 个字符 • 不能为空 • 应描述 Skills 的功能以及何时使用它 • 应包含帮助智能体识别相关任务的具体关键词 |
除必选字段外,还包括一些可选字段,为 Skills 提供更多的配置可能性:

| 可选字段 | 约束条件 |
|---|---|
| license(许可证) | 许可证名称或对许可证文件的引用 |
| compatibility(兼容性) | 最多 500 个字符,指示环境要求 |
| metadata(元数据) | 任意键值对 |
| allowed-tools(允许的工具) | 预批准工具的空格分隔列表(实验性功能) |
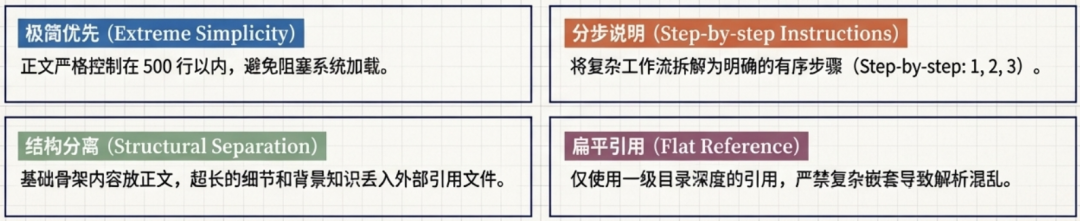
4.4 正文内容要求
正文格式上没有硬性限制,但官方总结了几条最佳实践:
- 建议采用章节分步说明(Step-by-step instructions)的组织方式
- 明确说明输入格式、输出格式,并提供输入输出示例
- 正文保持在 500 行以内,避免过于冗长
- 将详细的参考资料移至单独的文件中
- 引用文件与
SKILL.md保持一级目录深度(避免嵌套引用,便于管理)
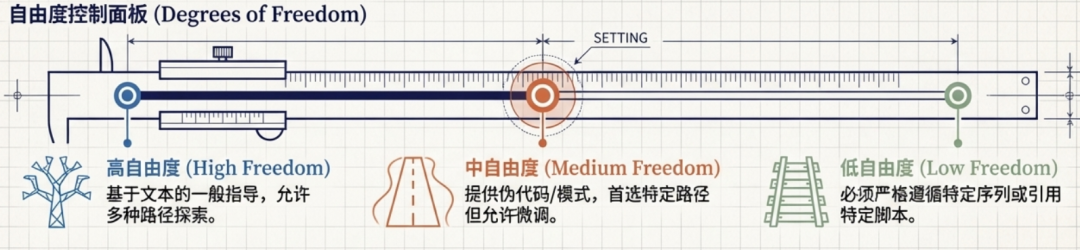
自由度选择策略:
| 自由度等级 | 特征 |
|---|---|
| 高自由度 | 基于文本的一般性指导,允许多种方法 |
| 中自由度 | 说明包含可自定义的伪代码、代码示例或模式,存在首选模式但允许一定变化 |
| 低自由度 | 说明引用特定脚本,必须遵循特定序列 |
复杂工作流处理建议:将复杂操作分解为清晰的顺序步骤;若工作流步骤过多,考虑将其拆分到单独文件。
核心要点总结:
| 要点 | 说明 |
|---|---|
| 简洁优先 | 正文控制在 500 行以内,避免冗长影响加载效率 |
| 分层组织 | 基础内容放正文,详细内容放引用文件 |
| 扁平引用 | 只使用一级文件引用,避免嵌套带来的复杂性 |
| 灵活度选择 | 根据任务复杂度选择合适的自由度等级 |
| 步骤化 | 复杂任务必须拆分为清晰的顺序步骤 |
4.5 可选目录
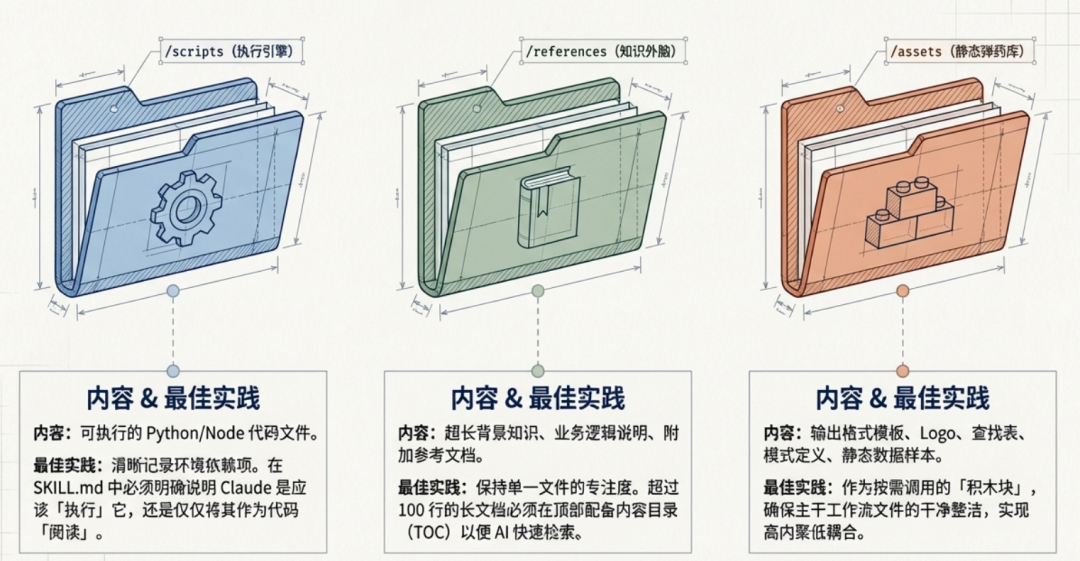
| 目录 | 内容 | 备注 |
|---|---|---|
| /scripts | 可执行的代码文件 | 清晰记录依赖项,错误处理明确且有帮助。注意在说明中明确 Claude 是应执行该脚本,还是将其作为参考阅读。 |
| /references | 附加参考文档 | 保持单个参考文件的专注性。超过 100 行的参考文件,在顶部包含内容目录。 |
| /assets | 模板、图像、数据文件 | 文档模板、配置模板、图表、logo、查找表、模式定义等。 |
4.6 实践案例一:练习题生成 Skill
第一个技能是 generating-practice-questions——根据输入的讲义笔记生成用于测试理解程度的各类教育练习题。
这个技能的设计理念是让教师或讲师能够轻松地创建全面的测试题库。用户只需要提供讲义笔记的内容,技能就能自动生成多种类型的问题,包括判断题、选择题、简答题和应用题等。
支持多种格式的讲义输入:
## Input**Supported formats**: LaTeX (.tex), PDF, Markdown (.md), plain text (.txt)- **PDF**: Use `pdfplumber` for text extraction- **LaTeX**: Read as text, strip preamble (everything before `\\begin{document}`), preserve math environments (`$...$`, `\\[...\\]`, `\\begin{equation}`, etc.)- **Markdown/Text****Content to extract**:1. **Learning objectives** - Usually at beginning: "After this lecture, you should be able to..."2. **Main topics** - Section headings, bold terms, definitions, algorithms.3. **Examples** - Use for realistic scenarios in questions.
输出结构——四类题型递进设计:
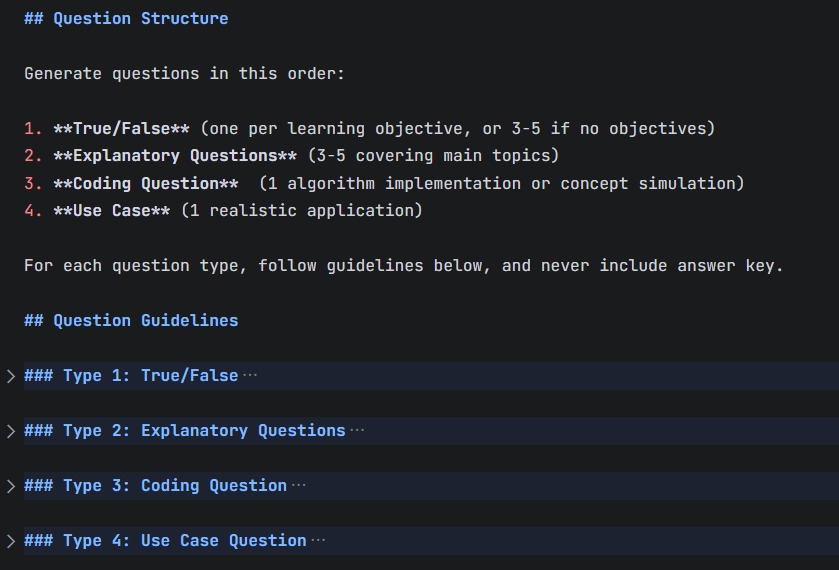
输出遵循严格的难度递进结构:
| 部分 | 题型 | 考察能力 |
|---|---|---|
| Part 1 | 判断题(True/False) | 基础概念理解 |
| Part 2 | 选择题(Explanatory) | 知识辨析能力 |
| Part 3 | 编程题(Coding) | 动手实现能力 |
| Part 4 | 应用题(Use Case) | 综合运用能力 |
模板化输出设计:
**关键实践点,**不把所有格式定义都放在 SKILL.md 主文件中,而是引用 assets 中的模板文件。这种设计思路值得借鉴:
## Output Format GuidelinesOutput format depends on user request (LaTeX, PDF, Markdown, plain text).**General structure for all formats**:1. Title with document name2. Instructions section3. Part 1: True/False Questions (numbered sequentially)4. Part 2: Explanatory Questions (numbered sequentially)5. Part 3: Coding Question (with steps, signature, examples, hints)6. Part 4: Use Case Application (with scenario, data, task, requirements, hints)**For specific formats**: 使用 assets/ 中的模板- `questions_template.tex` - Complete LaTeX document structure- `markdown_template.md` - Complete Markdown document structure
这种模板化的设计有多个优点:首先,它保持了主文件的简洁性,避免了格式定义代码膨胀;其次,它使得添加新的输出格式变得简单,只需要创建新的模板文件即可;最后,通过仅加载特定需要的模板,技能还能提高 Token 使用效率和上下文窗口的利用率。
4.7 实践案例二:时间序列分析 Skill
第二个实践案例是 analyzing-time-series——自动识别时间序列数据中的模式、趋势和异常。
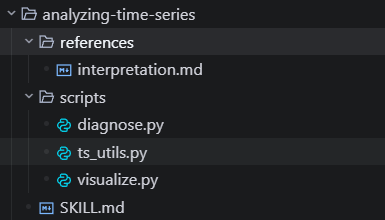
这个技能展示了如何将复杂的分析功能封装为可重用的技能单元。时间序列分析涉及金融、工业监控、医疗诊断等多个行业,通过将这一功能封装为技能,用户只需提供数据文件,技能就能自动完成特征提取、模式识别和异常检测等工作。
三步工作流设计:
它有一个非常特殊的工作流,分为三步,使用 scripts 文件夹中的 Python 脚本执行每个步骤:
Step 1: Run diagnostics(运行诊断)
python scripts/diagnose.py data.csv --output-dir results/
运行所有统计检验和分析。输出 diagnostics.json(所有指标)和 summary.txt(人类可读摘要)。列名自动检测,也可通过 --date-col 和 --value-col 指定。
Step 2: Generate plots(optional)
python scripts/visualize.py data.csv --output-dir results/
在 results/plots/ 中生成诊断图表。在 diagnose.py 之后运行,以确保 ACF/PACF 图与平稳性结果同步。
Step 3: Report to user
汇总 summary.txt 中的发现,呈现相关图表。引用 references/interpretation.md 中的解读指南回答关键问题:
- 数据是否可预测(forecastable)?
- 是否平稳(stationary)?需要几阶差分?
- 是否有季节性(seasonality)?周期是多少?
- 是否有趋势(trend)?方向如何?
- 是否需要变换(transform)?
五、在 Claude Code 中安装和使用 Skills
本节讲述如何在 Claude Code 中实际操作 Skills,从安装到使用再到评测的完整流程。
首先打开 Claude Code,输入 / 之后,输入 plugin。
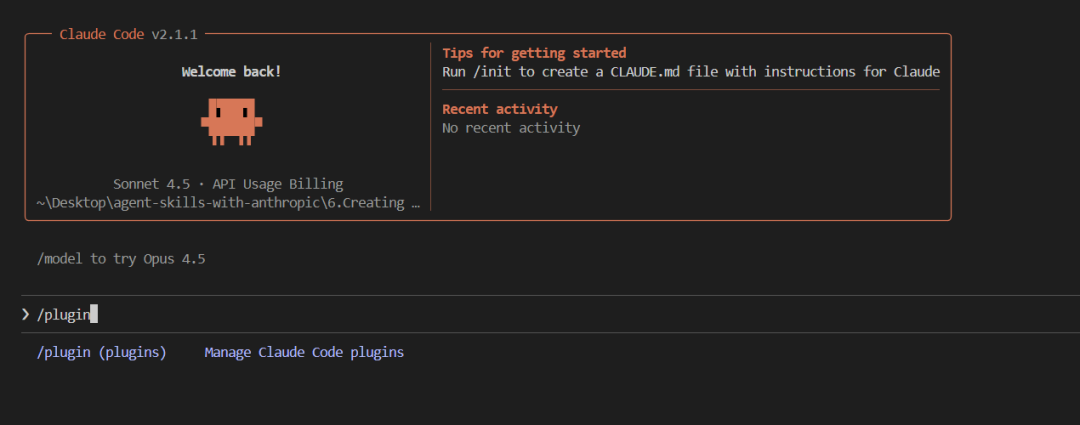
然后选择 Marketplace,选择 Add Marketplace,输入 anthropics/skills,这是我们看到的 GitHub 仓库。
下载之后,如下图所示则证明安装成功:
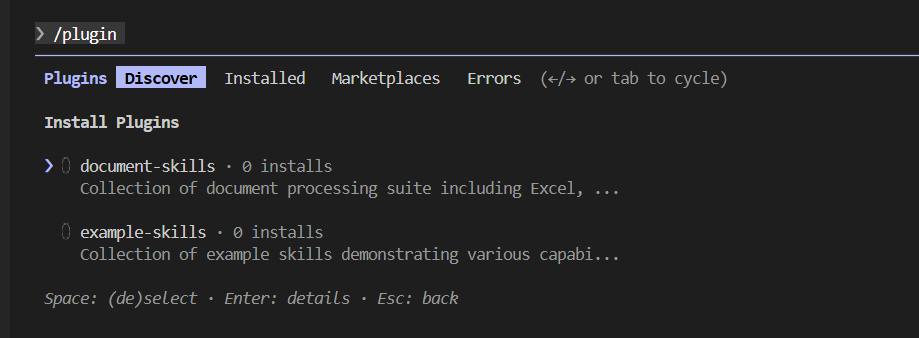
包含三个部分:diagnose.py(诊断脚本)、document-skills(处理 Excel、PowerPoint、Word、PDF 文件)、example-skills(示例技能)。
然后我们安装 example-skills 在文件目录下:

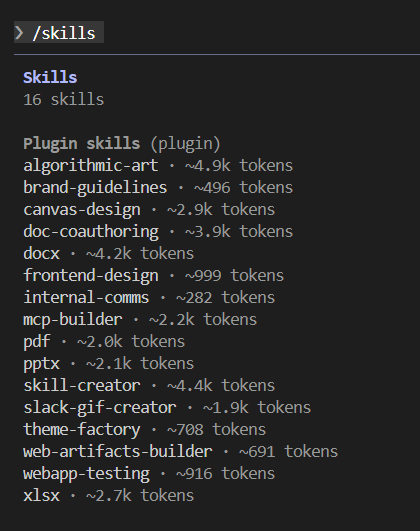
重启 Claude Code,输入 /skills,就可以看到我们安装的所有 Skills。
然后利用 skill-creator 进行 Skills 评测:
Use the skill-creator to evaluate how well my skills in ./Custom Skills/ have followed the best practices. Use two subagents in parallel, each subagent evaluates one
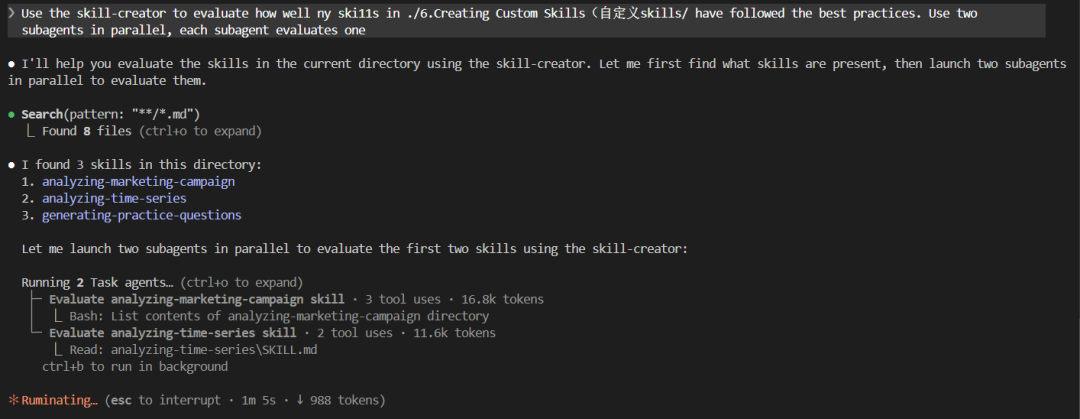
稍等大概一分钟左右,我们会得到结果:
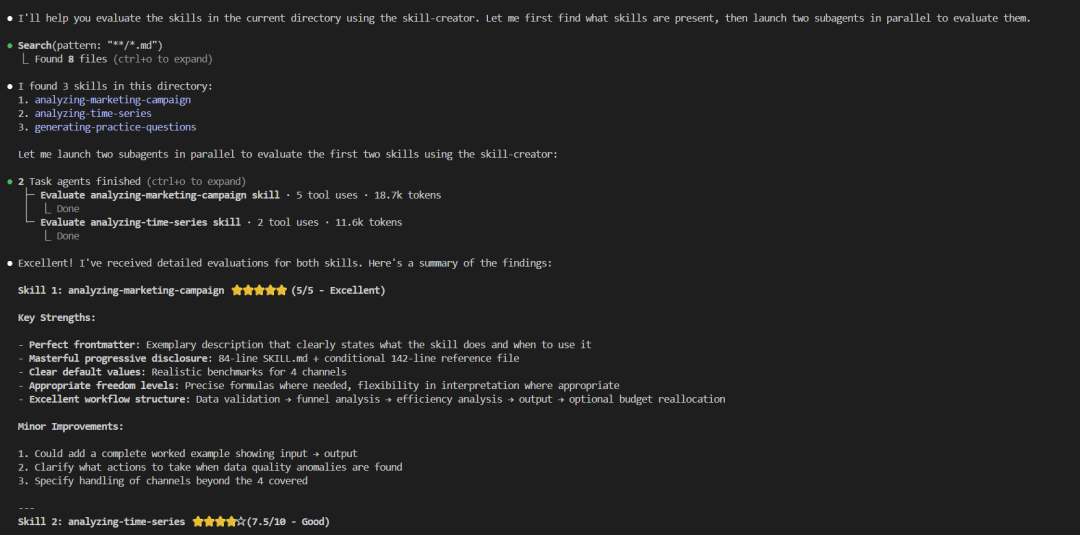
六、Skills 评测
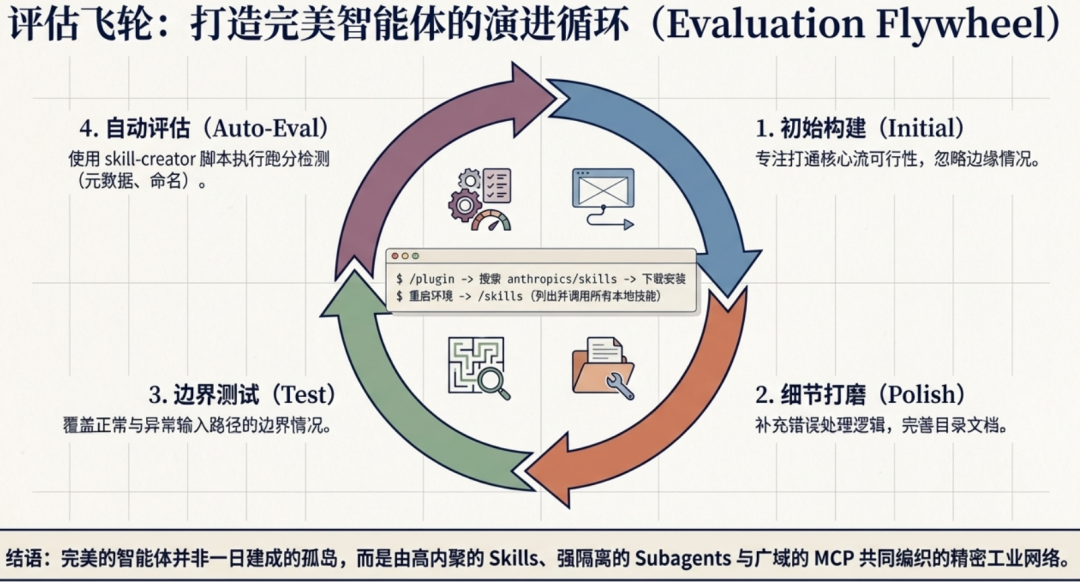
创建一个高质量的技能通常需要多次迭代和优化:
- 初始阶段:关注核心功能的实现,确保技能能够完成其基本任务,不需要过多地考虑边缘情况或优化问题,重点是验证设计思路的可行性。
- 完善阶段:关注细节的打磨,包括完善错误处理逻辑、补充文档说明、优化用户体验等,确保整体质量达到生产级标准。
- 测试阶段:覆盖正常流程和异常流程,验证技能在各种输入条件下都能产生正确的输出。边缘情况的处理尤其需要仔细测试。
- 自动评估:验证技能是否符合最佳实践可以使用自动化的评估工具。这些工具可以检查技能的元数据完整性、命名规范性、内容组织合理性等方面,提供客观的质量评估报告。
七、总结
本文系统梳理了智能体生态的三大核心:一是四大组件分工明确——MCP 管数据接入、Tools 供底层能力、Skills 定标准流程、Subagents 做并行隔离;二是官方已提供 Office 四件套等开箱即用 Skills,并支持本地快速迭代;三是自定义 Skill 需遵循“动词+ing”命名、精准描述、500行内分步说明,配合三个可选目录,两个实战案例展示了完整落地路径。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


大模型入门到实战全套学习大礼包
1、大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!

2、大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。

3、AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

4、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

5、大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献292条内容
已为社区贡献292条内容

所有评论(0)