Seqlist 顺序表 的实现c语言
本小结重点: 你将学到 函数基础 传值传地址的区别
结构体指针 简单循环控制 理解物理结构与存储结构的区别
多文件分布
简单来说就是对动态数组进行函数封装,简化了很多功能
所以很多就是对数组的利用,但更多是对结构体数组,所以学习顺序表,要对结构体熟悉,其次函数的操作,比如定义等要清晰
结构体是一种自定义的数据类型,所以可以包含各种类型的数据类型,是个集合,是包含多个数据项的数据元素,对指针的操作要清楚,不熟悉,可以去B站搜比特鹏哥,C语言部分,讲的很详细的
首先要了解一下逻辑结构和存储结构
一句话结论
逻辑结构 = 数据怎么“排”(关系)
物理结构 = 数据怎么“存”(内存)
一个管关系,一个管存放。
一、逻辑结构(你看到的样子)
逻辑结构就是:数据之间是什么关系?
只有 4 种:
1. 线性结构(一对一)
例:顺序表、链表、栈、队列
2. 树形结构(一对多)
例:二叉树、B树
3. 图形结构(多对多)
例:图
4. 集合结构(无关系)
逻辑结构 = 数据的逻辑关系
和内存怎么存 完全无关。
二、物理结构(内存里的样子)
物理结构就是:数据在内存里怎么放?
只有4种:
1. 顺序存储(连续放)
例:数组、顺序表
2. 链式存储(不连续,靠指针连)
例:链表
3. 哈希(散列)
4.索引
物理结构 = 内存布局
决定了访问速度、增删快慢。
三、最关键的关系(你必须懂)
同一个逻辑结构,可以用不同物理结构实现!
例:
栈(逻辑结构) 队列(逻辑结构)
都既可以用 数组 实现(顺序栈)
又可以用 链表 实现(链栈)
逻辑结构是“规则”或者是一种关系,物理结构是“实现方式”或者不同的路线。
特点1
顺序表是基于数组的,具有数组的特性,包括占用连续的空间
手把手教你学会顺序表
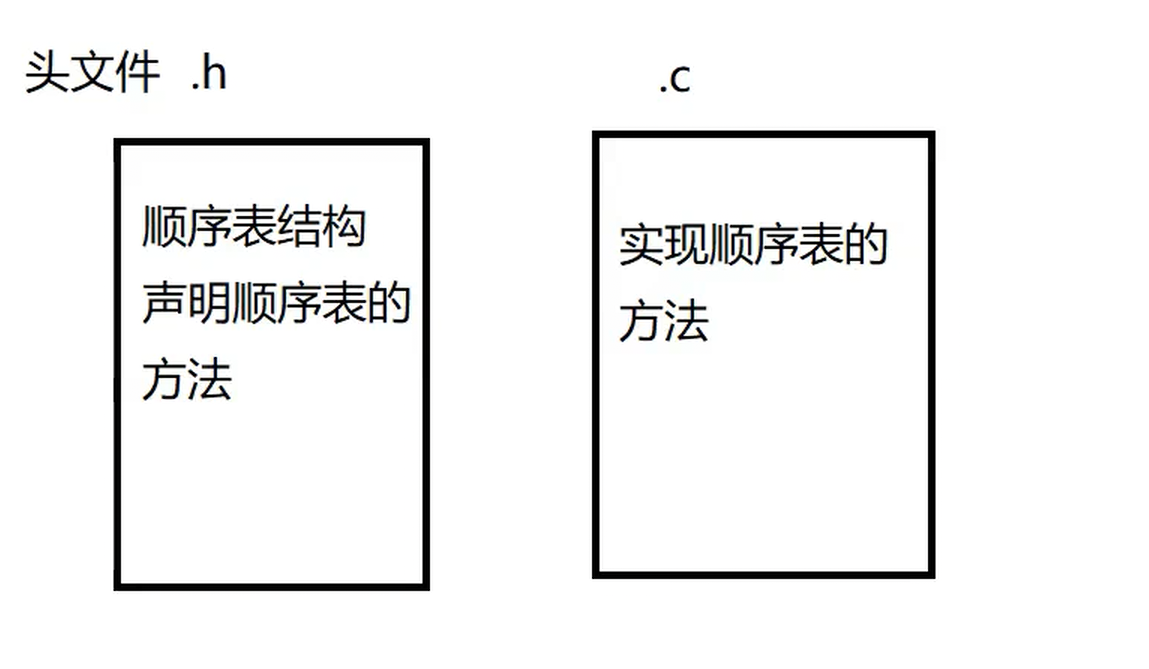
这里我们用多文件管理代码,不熟悉的可见我主页关于多文件的介绍
头文件类 比 书的目录 源文件相当于 书页的内容
在 seqlist.c文件中完成函数细节的实现,在test.c功能的测试开发
还有就是Seqlist.h中可以写好需要用到的宏后面会用
assert 断言宏 需要头文件如<assert.h>
声明各部分功能的函数还有就是统一写好需要用到的头文件
简单说明一下 主要的运算 (就是怎么用)
增 最后面插入就是尾插
SLPushBack(最常用,Push=插入,Back=尾部)
SLAddTail(Add=添加,Tail=尾)
SLAppend(Append=追加,语义贴合尾
从最前面插入 简称头插
SLPushFront(最常用,Push=插入,Front=头部)
SLAddHead(Add=添加,Head=头)
SLPrepend(Prepend=前置,语义贴合头部添加)
这些名字都特定的含义
还有就是特定位置插入
删 头删 尾删 任意位置删除 SLinsert任意
取名字 SL 顺序表+ Pop删除+位置(front / back)任意SLErase
查 查找特定的数据 如QQ号加好友
SL Check(核对,检验)不就是查找一样吗
或者 SLFind
改 修改数据 修改昵称备注ID
动态顺序表 与 静态顺序表的抉择
int arr[666];这是一个666个元素的数组
int size;这是一个整形变量,表示有效元素的个数
这里需要将这两个数据项集合为一个新的数据元素
这就最好用结构体类型,正好利用
结构体类型
struct Seqlist{
int arr[666];
int size;
}记住这只是一个类型 定义变量 是类型名 + 变量名 ;
类型重命名呀 typedef
typedef struct seqlist SL ;这里起了一个新名字叫SL类型
首先定义一个结构体变量 SL sl ;类型+ 变量名
typedef + 类型 重命名类型 例如 typedef int nb;
平时定义变量 Int a = 666; 现在是 nb a =666;
这是等价的
拆解 自定义关键字 结构体 + 标签名 + 重新命的名字
初始化结构体
struct Point {
int x; 这里都是成员列表
int y;
};
struct Point p = {.x = 10, .y = 20};这是C99规定的初始化
只有在定义的同时赋值才叫做初始化
但是大多数都是 引用赋值 变量名 + . + 成员名(数据项)
p.x = 666,p.y = 888;
静态顺序表的弊端:在一个项目软件在开发过程中,使用的用户服务端的数据量是不确定的,所以静态顺序表就很鸡肋i,那不直接就开辟很多大的空间来存储数据,但这样就会有两个问题,前期成本高,浪费太多空间,后期用户爆单不就炸了,又不可以修改原本的空间大小 so 我们最好使用动态顺序表
增加了动态扩容的属性 可以根据需求来动态开辟空间,避免资源空间浪费,健壮性更好,所以必须要会哦,就是利用realloc动态增容
typedef struct Seqlist {
int * arr; 指向数组(顺序表)起始地址的指针(数组类型和起始地址) 后面两个成员表示该数组的特点
int size;已使用的元素个数,有效元素个数总<=capacity;
int capacity;总容量 单位元素 个数
}SL;取别名 叫SL类型
或者是 另起一行重命名 直接typedef sturct Seqlist SL;
启发以及预警 上面我标出数组类型表达如果写死了就很难改,这时便可以用到 宏定义 #define SLtype int 没有分号
宏定义就是一种替换 将所有的SLtype替换为Int
同理可得 #define n 666 常见用于变长数组
typedef struct Seqlist {
SLtype * arr; 只要改变宏定义就可以改变下面这个数组的类型,就可以用于突然要用这里存储其他类型的数据
int size;
int capacity;
}SL;取别名 叫SL类型
继续修房子 ——-砖块函数方法分装 高内聚低耦合 简化理解就是功能单一化 不要又太多纠缠,比如写个加法函数 ,就不要打印那个值,仅仅只去打印
本节需要的头文件 创建 SL.h 里面主要就是这些的头文件还有就是函数的声明,还有宏定义
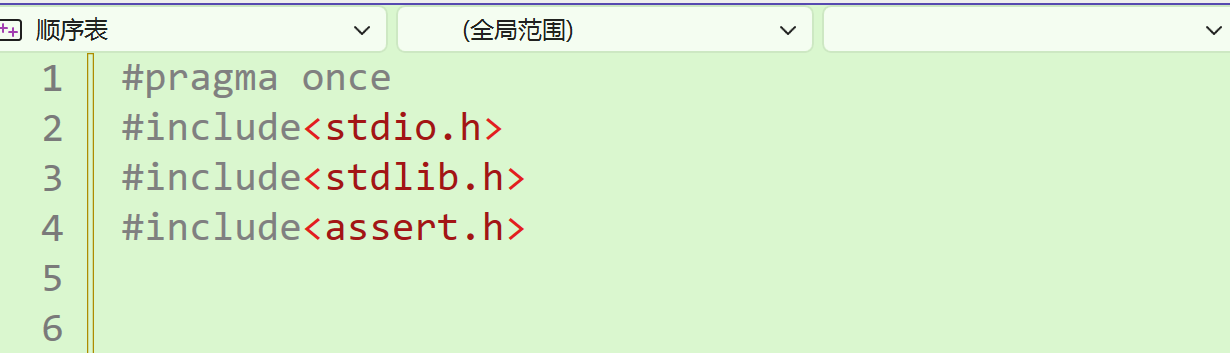
从最简单的初始化开始 这个功能我们写个函数吧!
返回值 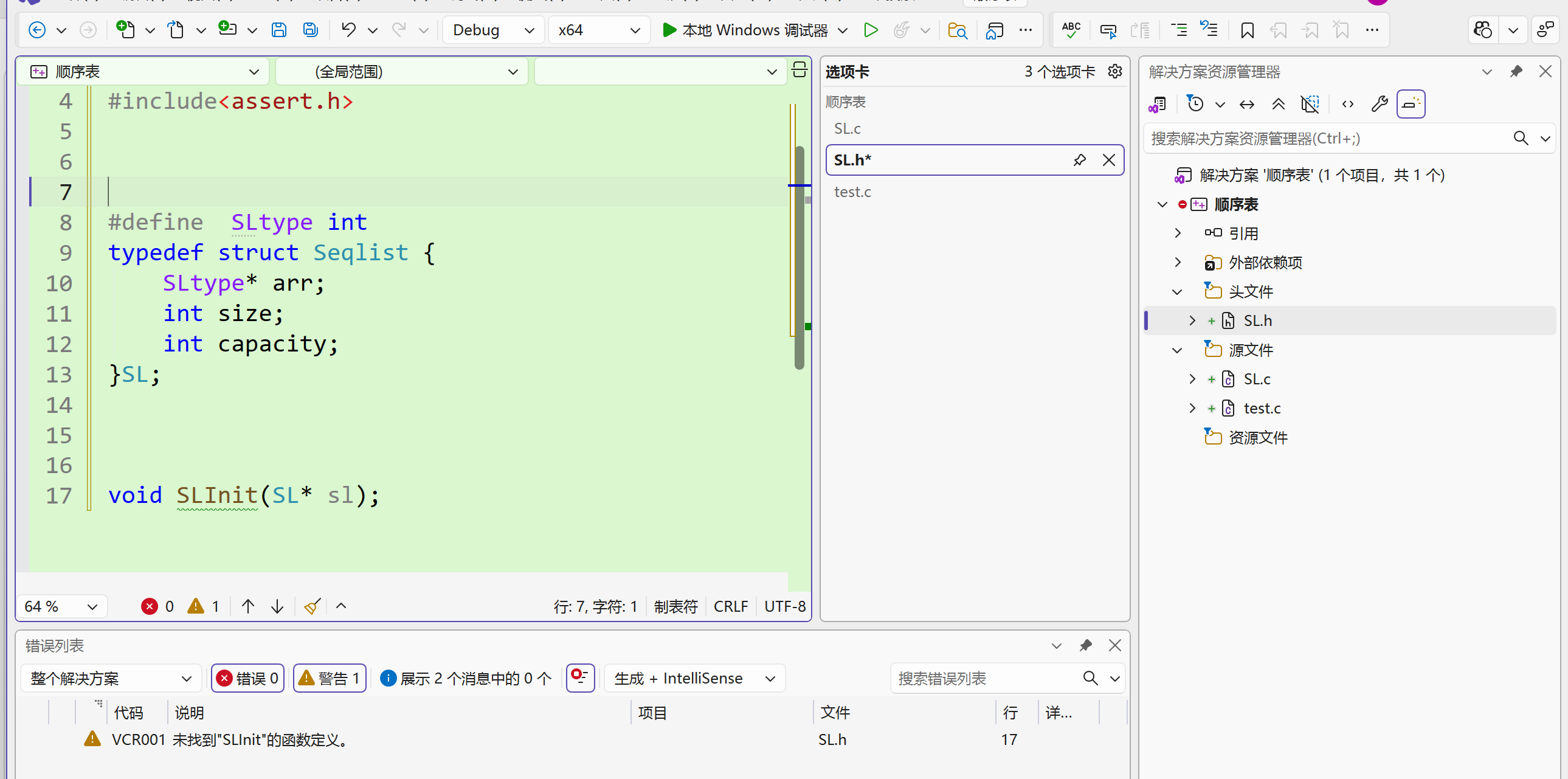
接下来就是在SL.c中完善对函数的定义,刚只是声明了
注意 :下面第二行细节要包含头文件 SL.h 这样才能使用已经定义了的结构体还有不用重复写头文件 !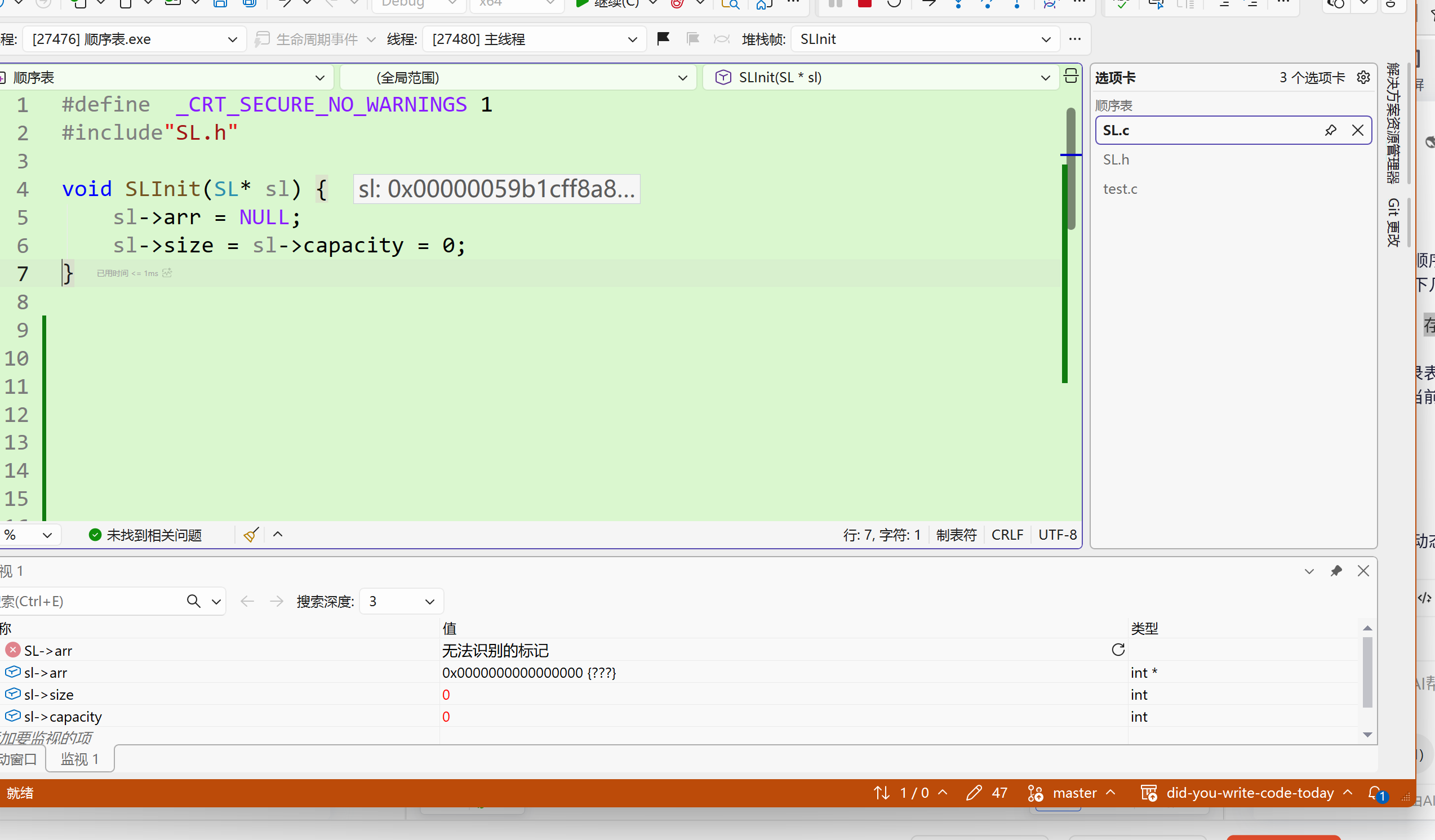
上面图片中 第一行是 为了解决在VS上的输入报错,因为安全性考虑,也为了可移植 下面的函数就是初始化的操作吗?YES
记住任何能写出函数的,都可以分开写在main函数里,只是函数最为C语言最基础的组成部分罢了
SL sl = {.arr=NULL, .size=0, .capacity=0};这一行 等价于 传递地址(指针)后赋初值改变原值都实现了初始化,但是不推荐,函数可以反复调用,不用重复写代码,不要每次初始化都写一遍,只要调用写过的函数 功能单一越好 不是不行,只是效率不高,白费人工 SO例如<stdio.h>等库函数
吗都是写好的一个个功能或者方法,可以这样理解,方便直接用,不然每次都要写输入输出的
函数 1 我们不会写 scanf printf 的函数原理,而且只要会用就好 2没必要每次花时间去写,就统一规定用统一的标准来写输入输出 3第三每个人写的函数命名呀,等等都不一样,再协同合作和工程建设时 很难合作 所以后面 写的每个那个 功能都用函数来写 比如 增删查改
比如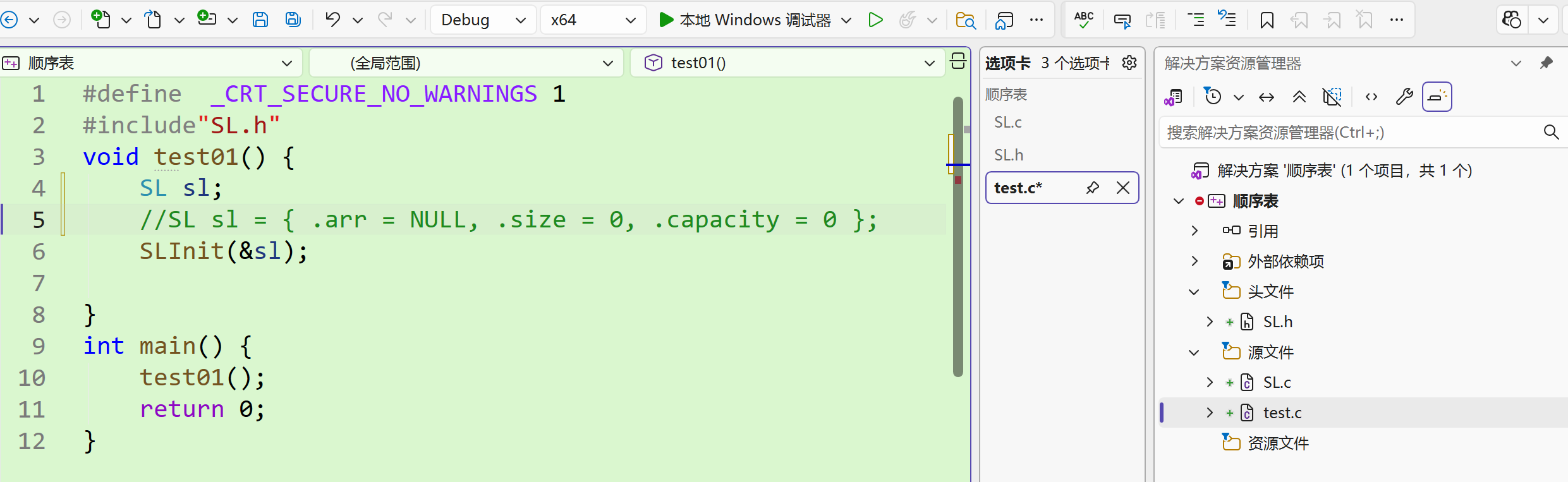
第一要理解函数参数 为什么是结构体指针变量
值做参数传递 只是对实际参数的一份临时拷贝 并不会改变原来的现状 理解为给你拍了个照片在上面乱涂乱画,实际对你来说并没有影响
地址做参数传递 传递的是地址,是指向内存空间的地址,任何变量的创建都需要开辟空间的,在相应的空间存储数据 ,传递地址就是 对实体 实参进行操作 就像你被七匹狼鞭打是一样,打的是你的本体,肯定会痛的;
第二 地址引用操作符 -> 就时 解引用 地址指针 针对结构体指针变量 在函数传递参数
.操作符也是引用操作符 适用于 结构体变量
大白话语法:结构体指针变量名 + -> 成员变量名 = 再赋值 ;
重要理解 所有的增删都需要对size进行改变
size 原来是有效的元素个数 作为下标,就是最后一个数的后一个数 不懂就画图 此时有效个数为4,作为下标的话,是从0开始的所以arr[size] 永远是数组最后一个数据的后一个,有图又真相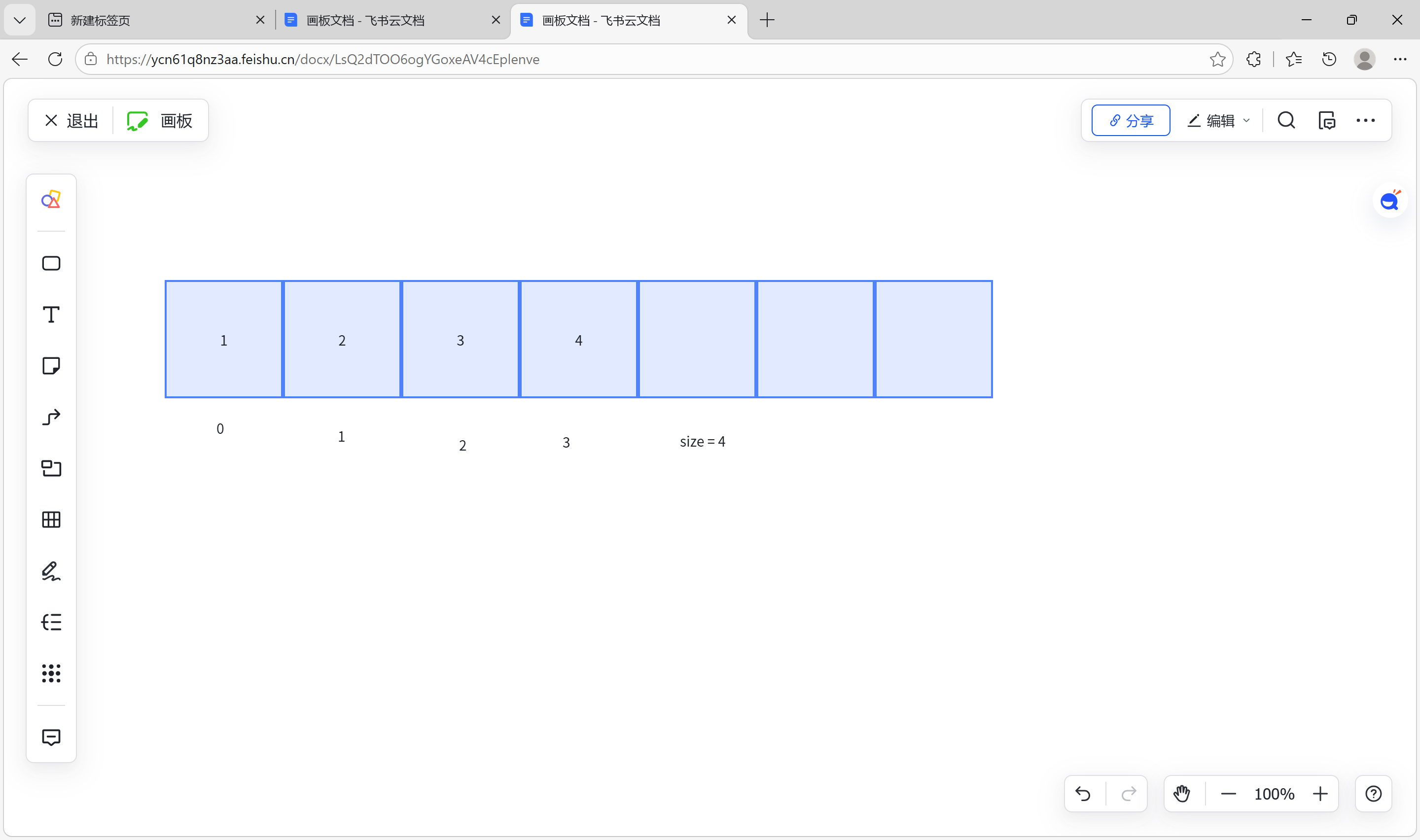
无论头插 还是尾插都需要将size++,因为都加入了一个新元素,需要腾出一个新位置呀
这里继续画图 采取古法画图手搓 这里是尾插 size由3变成4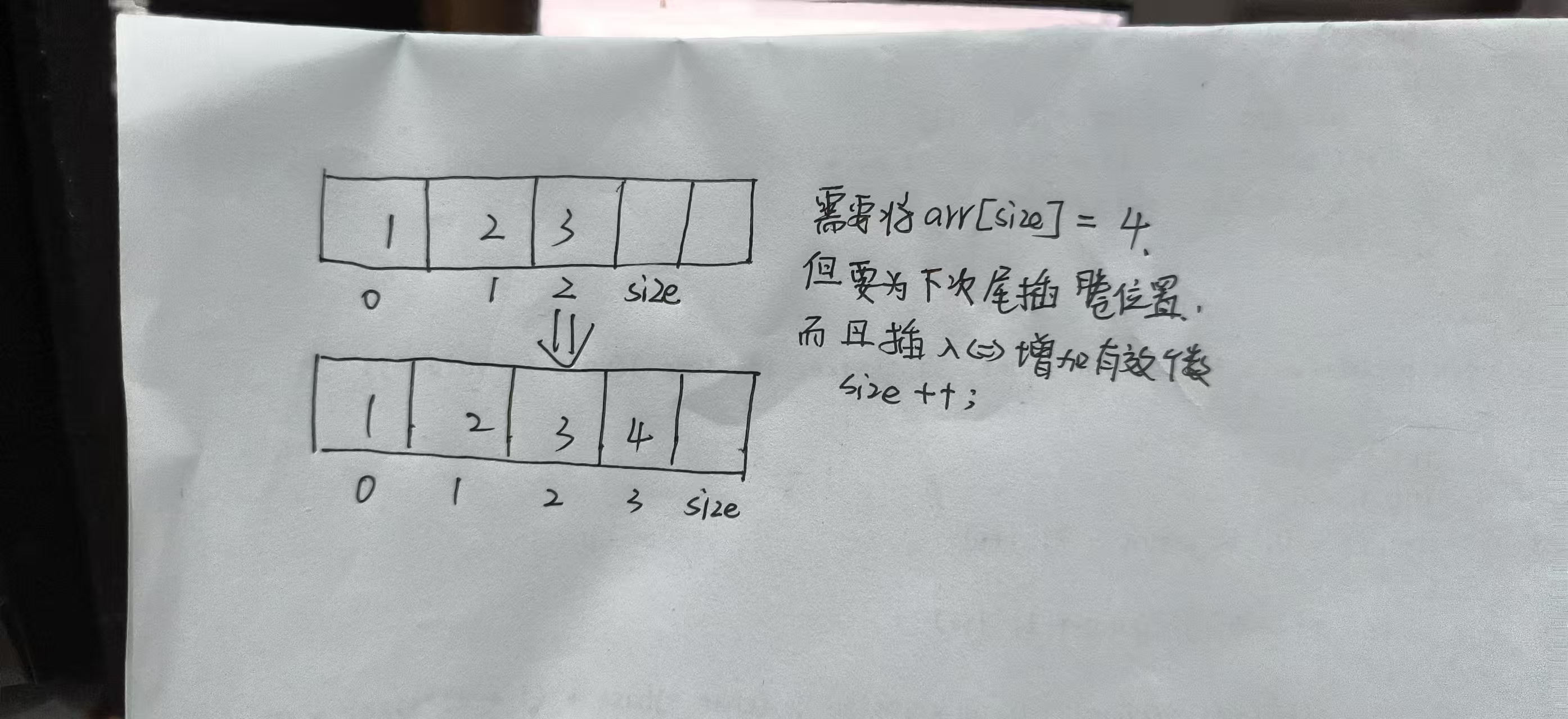
敲黑板:解释一下就是 无论在哪里插入一个数据都增加了有效个数,size要自增1,可以写size++;或者++size; 而且不要疑惑,无论是前置++或者是后置++;只要没有赋值或者参与表达式的运算,结果都是+1的效果
同理可得 各种删除操作都是需要--size 有效个数减一
---------------------------------------------------------------------------------------------------------------------------------
总结 顺序表的初始化 多文件处理 函数传值 结构体
宏定义 还有什么? 你来回忆 ,欲知后事如何,且听下回分解
增 删 查 改 的 cyu实现

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)