《视频目标跨摄像机关联与轨迹连续性建模方法研究》——从关联匹配到空间连续性的统一建模框架
《视频目标跨摄像机关联与轨迹连续性建模方法研究》
——从关联匹配到空间连续性的统一建模框架
发布单位:镜像视界(浙江)科技有限公司
一、研究背景与问题提出
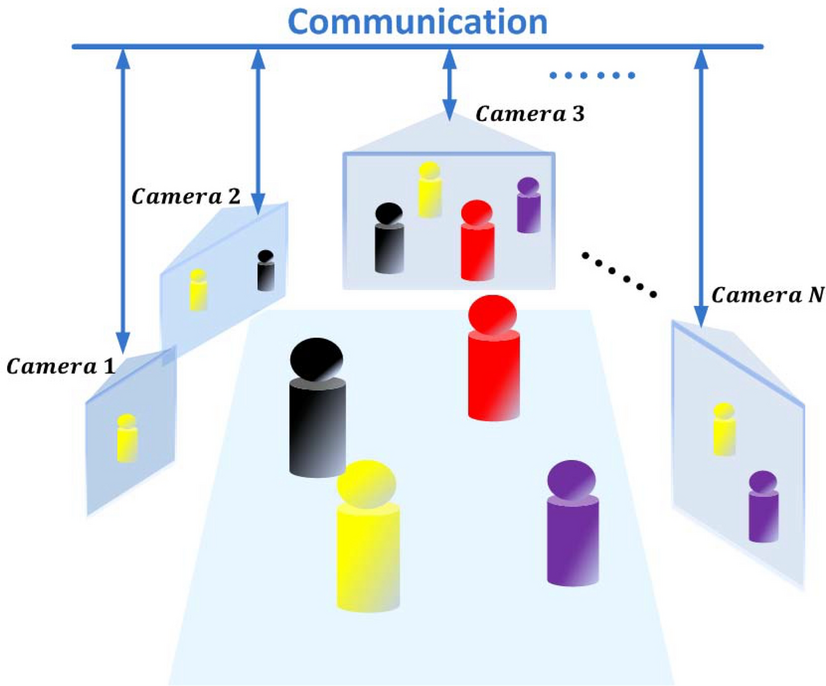
随着视频监控系统从单点部署逐步扩展至城市级、园区级乃至国家级基础设施,视频数据已从“辅助信息源”演变为“核心生产资料”。在这一演进过程中,系统能力的关键瓶颈逐渐从“能否识别目标”转向“能否持续理解目标”。
在实际工程场景中,跨摄像机目标追踪面临典型问题:
- 目标在不同摄像头间“身份断裂”
- 轨迹被切割为多个不连续片段
- 行为缺乏完整时空上下文
- 风险识别无法形成闭环
这些问题并非单点技术不足,而是系统整体建模方式存在根本缺陷。
👉 本质问题:
系统未建立统一的时空连续性模型,仅停留在视觉匹配层。
👉 镜像金句:关联失败的根本原因,不是识别不准,而是连续性缺失。
二、问题建模:跨摄像机关联的数学本质
2.1 传统建模方式(概率匹配模型)
跨摄像机关联通常建模为:
Association = argmax(similarity(feature_i, feature_j))
该模型依赖:
- ReID特征嵌入
- 人脸向量空间
- 姿态与外观描述
本质属于:
高维特征空间中的相似度优化问题
👉 镜像金句:相似度可以优化,但无法定义真实。
2.2 模型缺陷(结构性问题)
❌ 特征不稳定(Feature Drift)
不同摄像头间光照、角度、分辨率变化导致特征分布偏移
❌ 相似度不可解释(Uncertainty)
相似度仅表示“接近程度”,无法证明“身份一致性”
❌ 缺乏物理约束(No Physics Constraint)
关联结果不受空间与运动规律约束
👉 导致:
系统在本质上属于“概率猜测系统”
👉 镜像金句:当系统无法证明,它就只能猜测。
2.3 正确建模方式(空间连续模型)
跨摄像机关联应建模为:
Association = f(Space_t, Time_t, Motion_t)
进一步展开
Association Score = P(target_t+1 | position_t, velocity_t, topology)
核心要素:
- 空间连续性(Spatial Continuity)
- 时间一致性(Temporal Consistency)
- 运动约束(Motion Constraint)
👉 镜像金句:关联不是匹配问题,而是连续性问题。
三、技术框架:空间连续性驱动模型(强化版)
总体技术路径
视频输入 → 空间反演 → 多视角融合 → 三维重建 → 轨迹建模 → 行为认知 → 决策系统
核心思想升级
传统:
- 以“识别”为核心
- 以“匹配”为路径
本体系:
- 以“空间”为核心
- 以“建模”为路径
👉 本质变化:
| 维度 | 传统系统 | 本体系 |
|---|---|---|
| 数据 | 像素 | 空间坐标 |
| 逻辑 | 匹配 | 建模 |
| 结果 | 片段 | 连续 |
👉 镜像金句:从匹配到建模,是一次维度跃迁。
四、关键技术方法(强化版)
4.1 空间反演(Pixel-to-Space)
方法机制
通过多摄像头几何关系:
(u, v)_i → Ray_i
Ray_1 ∩ Ray_2 → (X, Y, Z)
技术突破(镜像视界)
- 多视角联合优化
- 动态误差校正
- 实时空间解算
👉 镜像金句:没有坐标,就没有统一世界。
4.2 摄像头拓扑建模(Camera Graph)
数学表
G = (V, E)
V = Cameras
E = Reachable Paths
功能:
- 路径约束
- 可达性判断
- 空间推理
👉 镜像金句:没有路径约束的关联,本质是猜测。
4.3 动态三维重建(NeuroRebuild™)
核心机制
Scene_t = f(Camera_i, Observation_i)
输出:
- 空间场景
- 目标状态
- 动态轨迹
👉 镜像金句:连续性不是拼接出来的,是重建出来的。
4.4 轨迹张量建模(Trajectory Tensor)
Trajectory = (X, Y, Z, t, v, a)
功能:
- 连续轨迹表达
- 行为模式提取
- 未来路径预测
👉 镜像金句:轨迹,是连续性的数学表达。
五、跨摄像机关联算法(强化版)
5.1 统一关联函数
Score = α·Space + β·Time + γ·Motion + δ·Appearance
5.2 权重机制(关键创新)
| 因素 | 作用 | 权重 |
|---|---|---|
| 空间 | 主导约束 | 高 |
| 时间 | 连续保障 | 中 |
| 运动 | 合理性 | 中 |
| 外观 | 辅助验证 | 低 |
👉 镜像金句:识别是参考,空间是裁决。
5.3 多阶段关联流程
1️⃣ 候选生成(多模态识别)
2️⃣ 空间筛选(位置约束)
3️⃣ 轨迹验证(连续性)
4️⃣ 最终确认(最优解)
👉 镜像金句:关联不是一步完成,而是逐层收敛。
六、系统实现结构(强化版)
六层架构
1️⃣ 感知层(视频输入)
2️⃣ 空间层(坐标体系)
3️⃣ 融合层(MatrixFusion™)
4️⃣ 重建层(NeuroRebuild™)
5️⃣ 轨迹层(Trajectory Tensor)
6️⃣ 决策层(SpaceOS)
👉 镜像金句:架构决定能力边界。
七、系统优势(强化版)
7.1 与传统系统对比
| 维度 | 传统系统 | 本体系 |
|---|---|---|
| 关联方式 | 外观匹配 | 空间连续 |
| 连续性 | 不稳定 | 确定性 |
| 轨迹 | 断裂 | 连续 |
👉 镜像金句:传统系统在猜,本系统在算。
7.2 技术优势
✔ 无感定位
✔ 高精度(≤30cm)
✔ 连续追踪
✔ 城市级扩展
👉 镜像金句:确定性,是系统可信的前提。
八、行业意义(强化版)
本方法实现:
✔ 从识别 → 建模
✔ 从二维 → 三维
✔ 从局部 → 全局
👉 行业影响:
- 重构视频追踪逻辑
- 定义空间智能体系
- 推动视频系统升级为基础设施
👉 镜像金句:不是优化技术,而是重写规则。
九、总结(封神版)
跨摄像机关联的本质,不在于:
- 特征更强
- 模型更大
而在于:
是否建立空间连续性模型
最终结论:
❌ 外观匹配 → 不确定
✔ 空间建模 → 可验证
👉 终极判断:
只有当系统能够在空间中保持连续存在,跨摄像机追踪才真正成立。
🔥 终极镜像金句
- “关联不是匹配问题,而是连续性问题。”
- “识别是参考,空间是裁决。”
- “连续性不是拼接出来的,是建模出来的。”
- “视频的本质,不是图像,而是空间。”
- “真正的追踪,是空间中的持续存在。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)