我用 OpenClaw 搭了一个 AI 团队,让产品经理、架构师、工程师自动协作完成需求
前言
最近一直在思考一个问题:AI 能不能真正代替一个团队来协作完成复杂任务?
不是那种"给一个 AI 一个超长 prompt 让它扮演多个角色"的单线程模式,而是真正的多个 AI agent 并行工作、各自独立思考、有主控协调、有实时进度、有最终汇总报告——像一支真实的研发团队一样运转。
带着这个想法,我花了几天时间,基于 OpenClaw(内网版)做了一个 AI Team Platform,效果超出了我的预期。
先上一个实际运行的例子:
我输入:帮我开发一个简单的 Todo 应用
然后 AI 团队自动完成了:
- 🧑💼 产品经理输出了完整的 PRD(用户故事、MVP 范围、边界情况)
- 🏗️ 架构师设计了系统架构(技术选型、数据流、扩展路径)
- 👨💻 后端工程师输出了 REST API 设计 + 数据库表结构 + 安全防护方案
- 🖥️ 前端工程师完成了组件设计 + 状态管理 + 乐观更新方案
- 🧪 测试工程师写了测试用例矩阵(P0-P3 分级 + XSS/边界/竞态场景)
- 🚀 运维工程师出了 K8s 部署方案 + CI/CD + 容灾策略
- 📋 Review 角色做了六方联合评审,发现了 5 个高风险问题并给出修正
- 🗂️ 全栈工程师根据团队方案生成了 23 个完整可运行的代码文件,直接写入磁盘
整个过程全部自动化,有实时进度条,每个角色的执行状态都可以点开查看。
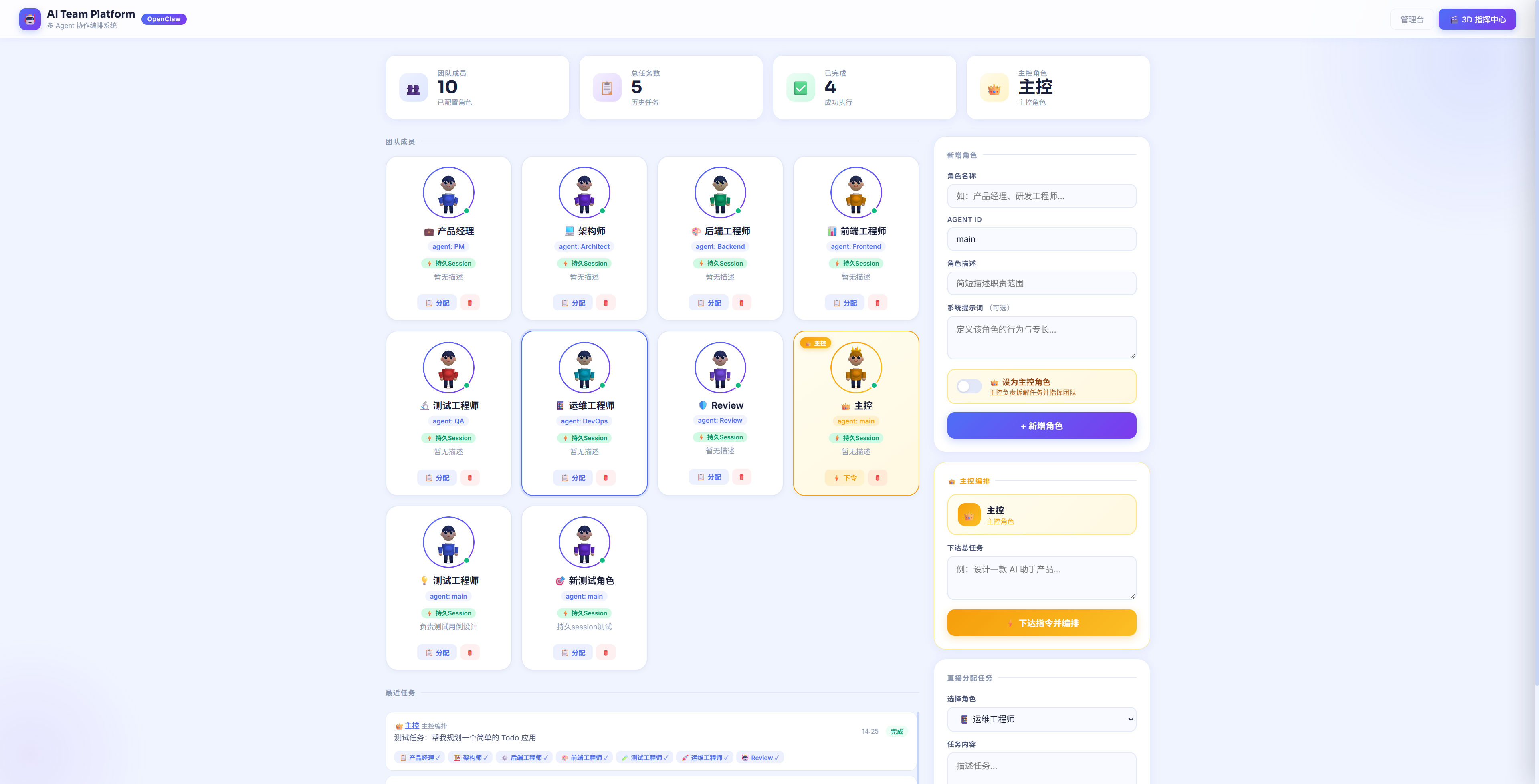
▲ AI Team Platform 主界面:团队成员列表、主控编排区域、任务执行状态一览
核心理念:让 AI 真正"分工协作"
传统的 AI 辅助开发是这样的:
用户 → 一个 AI → 一个回答
AI Team Platform 是这样的:
用户输入一句话
│
▼
主控 AI 分析任务,自动拆解成子任务
│
├── 产品经理 AI ──→ PRD
├── 架构师 AI ──→ 架构设计
├── 后端 AI ──→ API + DB 设计
├── 前端 AI ──→ 组件 + 交互方案
├── 测试 AI ──→ 测试用例
└── 运维 AI ──→ 部署方案
│
▼
Review AI 联合评审
│
▼
主控汇总输出最终方案
│
▼
全栈工程师 AI 生成完整代码
每个角色都有独立的 system prompt,有自己的专业视角,不会被其他角色的输出"污染"思维——这就避免了传统"一个 AI 扮多角色"容易出现的立场混乱问题。
技术实现:三层架构
1. 编排引擎(team_manager.py)
核心是一个异步编排引擎,主控角色完成任务拆解后,各子角色串行执行(避免并发争抢文件锁),通过 SSE 实时推送进度。
async def orchestrate_async(self, task_id, controller_id, message, target_role_ids):
# 1. 主控 AI 分析任务
plan = await self.call_openclaw_agent(
message=f"分析并拆解任务:{message}",
system_prompt=controller.system_prompt
)
# 2. 串行执行各子角色(避免 workspace-state.json 锁冲突)
for i, role_id in enumerate(target_role_ids):
self._emit("sub_task_started", {"index": i, "total": len(target_role_ids), ...})
result = await self.call_openclaw_agent(message, role.system_prompt)
self._emit("sub_task_update", {"status": "done", "elapsed": elapsed, ...})
await asyncio.sleep(3) # 间隔 3s,稳定性保障
# 3. 主控汇总
summary = await self.call_openclaw_agent(all_results_combined, controller.system_prompt)
2. Agent 调用机制(多级降级)
调用优先级如下:
| 优先级 | 方式 | 说明 |
|---|---|---|
| 1 | sessions_send | 持久化 session,保留上下文记忆 |
| 2 | sessions_spawn | 临时 subagent,session 失效时降级 |
| 3 | 本地 ollama | Gateway 不可用时 |
| 4 | 规则引擎 | 最终兜底 |
每个角色在创建时自动 spawn 一个持久 session,这样它"记得"自己是谁、之前做过什么——真正的角色连续性。
3. 实时可视化(SSE + 前端)
编排过程通过 Server-Sent Events 实时推送到前端,前端展示:
- 📊 总进度横幅:显示当前执行第几个角色,预估剩余时间
- 🃏 角色卡片:每个角色独立卡片,执行中有秒级计时器,完成后展示耗时
- 📋 操作日志:类终端风格,显示
▶ [2/6] 架构师 开始执行 - 🔍 详情抽屉:点击任意角色卡片,查看完整执行结果(含 Markdown 渲染)
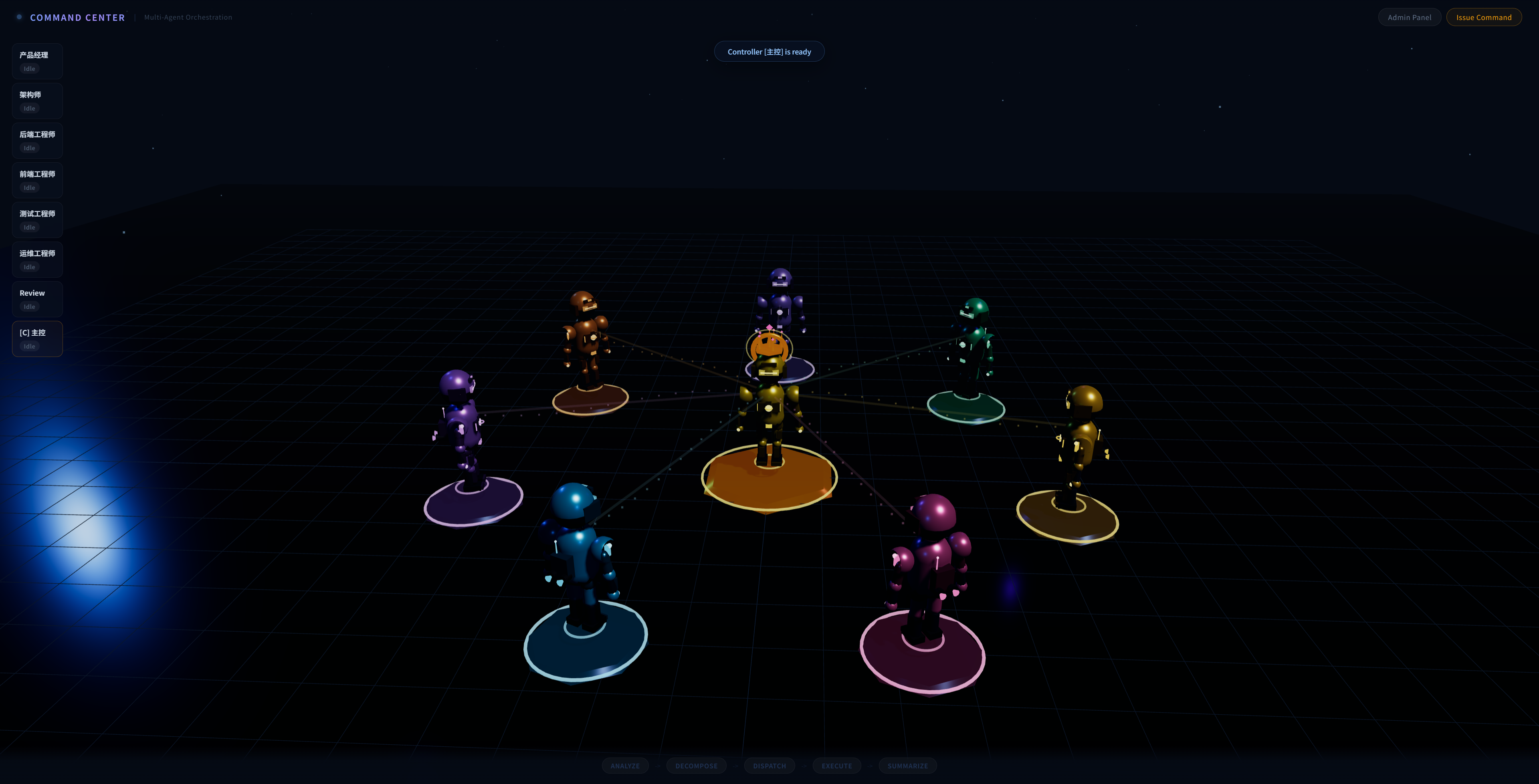
▲ 3D 指挥中心(COMMAND CENTER):多 Agent 角色可视化,连线表示协作关系,实时展示各角色状态
实际体验:一次完整的编排过程
下面是我实测的一次「开发 Todo 应用」编排,记录各角色的输出摘要:
产品经理 PRD 核心
P0 功能(MVP 必须有):
- 创建 Todo(非空校验,防重复提交)
- 查看列表(按创建时间倒序)
- 标记完成/未完成(勾选切换)
- 删除(单条,无需确认弹窗)
- 数据持久化(localStorage,刷新不丢)
明确排除:编辑、筛选、拖拽、账号、云同步
架构师方案核心
决策:纯前端 SPA + localStorage(MVP 阶段,零服务端依赖)
技术栈:React 18 + TypeScript + useReducer + Tailwind
数据流:
用户操作 → Dispatch Action → Reducer → State 更新 → UI 重渲染 → localStorage 同步
测试工程师方案核心
角色执行完成,耗时 48s,输出如下:
【测试工程师 · 测试方案】
测试范围:功能、接口、性能、安全
测试要点:
1. 核心路径正向/逆向用例
2. 边界值与异常场景
3. 并发压测(目标 QPS≥1000)
风险点:第三方接口稳定性、数据一致性
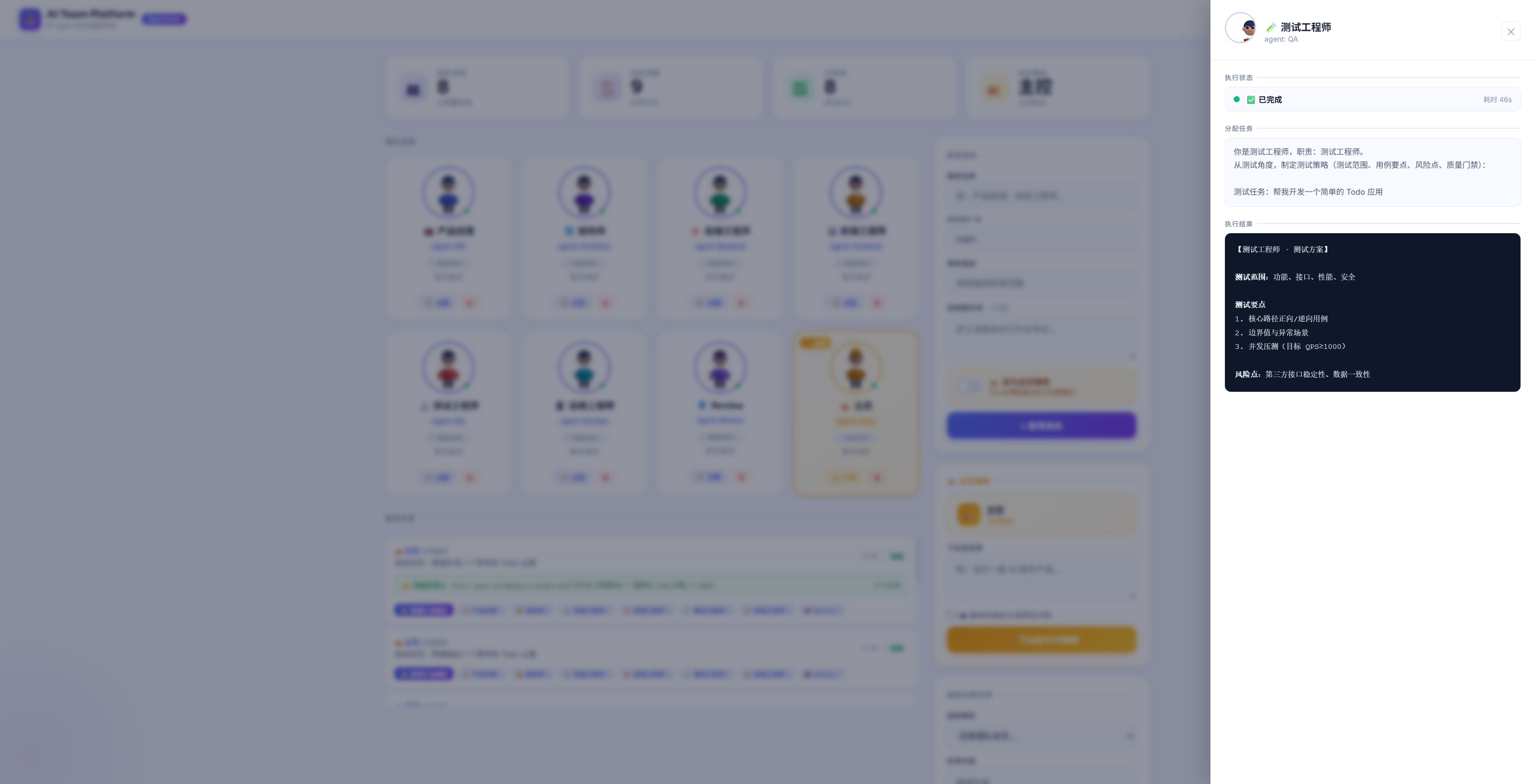
▲ 测试工程师角色执行结果抽屉:可查看完整测试方案,耗时 48s
Review 阶段:发现 5 个高风险问题
这是我认为最有价值的部分。六个角色轮流评审,每个角色必须指出至少 2 个问题:
| 角色 | 发现的问题 | 风险等级 |
|---|---|---|
| 架构师 | 持久化方案未明确(localStorage vs 远端 API) | 🔴 高 |
| 后端 | POST 接口无幂等性,网络重试会创建重复数据 | 🔴 高 |
| 前端 | 乐观更新无回滚,API 失败后 UI 状态不一致 | 🟡 中 |
| 测试 | XSS/空内容/断网/快速双击等边界场景全部缺失 | 🔴 高 |
| 运维 | 无 /health 接口、无限流、无 HTTPS | 🔴 高 |
这些问题如果没有 Review 阶段,很可能要等到上线后才暴露。
最终代码生成
Review 完成后,全栈工程师 AI 根据团队方案生成了完整可运行代码,直接写入磁盘:
/root/.openclaw/workspace/todo-app/
├── src/
│ ├── components/TodoInput/ ← 防空提交+抖动动画
│ ├── components/TodoItem/ ← 双击编辑+移动端优化
│ ├── components/TodoList/ ← 空状态三种文案
│ └── components/TodoFilter/ ← 全部/未完成/已完成+清除
├── src/hooks/useTodos.ts ← 核心业务逻辑
├── src/utils/storage.ts ← localStorage 封装(含数据校验)
└── README.md
项目技术栈
| 层次 | 技术 |
|---|---|
| 后端 | Python 3.11 + FastAPI + asyncio |
| 前端 | 原生 JS(无构建工具,直接运行) |
| AI 调用 | OpenClaw sessions_spawn / sessions_send |
| 实时推送 | Server-Sent Events(SSE) |
| 持久化 | JSON 文件(roles.json / tasks.json) |
遇到的坑(给踩过的人省时间)
坑 1:并发 subagent 争抢文件锁
最初我用 asyncio.gather 并发启动所有角色,结果频繁报 ENOENT rename 错误——多个 subagent 同时写 workspace-state.json 产生了文件锁冲突。
解决方案:改为串行执行,子任务之间间隔 3 秒。代价是速度慢了,但稳定性大幅提升。
坑 2:polling 逻辑的死等 Bug
原来的轮询逻辑要求 user_msgs <= 1 才认为 subagent 执行完毕,而实际 session 中可能有多条用户消息,导致永远不满足条件,死等 120 秒超时。
解决方案:只要 assistant 消息有内容(且稳定 2 秒内容不变)就立即返回。
# 修复前(有 Bug)
if len(user_msgs) <= 1 and assistant_content:
return assistant_content # 实际永远等不到
# 修复后
if content_str and len(content_str) > 5 and content_str != last_content:
last_content = content_str
await asyncio.sleep(2) # 等 2s 看内容是否稳定
return content_str
坑 3:SSE 连接阻塞 HTTP 请求
编排接口最初是同步的,全部执行完才返回 HTTP 响应——这意味着 HTTP 连接会超时(编排 7 个角色需要 5-7 分钟)。
解决方案:POST /orchestrate 立刻返回 task_id,后台 asyncio.create_task 执行,前端用 SSE 监听进度,pollDone() 每 3 秒兜底轮询。
快速上手
需要已安装并运行 OpenClaw(内网版)
# 1. 克隆项目
git clone https://github.com/your-repo/ai_team_platform
# 2. 安装依赖
cd ai_team_platform
pip install -r requirements.txt
# 3. 启动
python main.py
# 4. 打开浏览器
# http://localhost:8765
然后:
- 点「新增角色」,添加产品经理、架构师、后端等角色
- 设置一个角色为「主控」(点击皇冠图标)
- 在编排面板输入你的任务
- 点「下达指令」,看着 AI 团队开始工作 👀
写在最后
这个项目让我对"AI 协作"有了新的理解——单个 AI 的上限是明显的,但多个 AI 相互协作、相互检查,能产生真正的乘数效应。
Review 阶段发现的那些问题,单独问任何一个 AI 角色,它很可能不会主动提出。但当它以"审查者"而非"创作者"的身份参与时,批判性思维就被激活了。
这也许就是为什么真实团队协作能产出比个人更好的结果——不是因为人多力量大,而是因为视角不同、立场不同,能看到彼此的盲区。
AI 团队也一样。
如果你对这个项目感兴趣,欢迎 Star、提 Issue 或者直接 fork 玩起来!有任何问题或改进想法,评论区见 👇
项目地址:GitHub - AI Team Platform
相关技术: OpenClaw · Multi-Agent · FastAPI · SSE · Python
Tags:#AI #多智能体 #OpenClaw #FastAPI #Python #LLM #自动化编程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)