什么是RAG中的幻觉问题?引用溯源如何实现?
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
by @Laizhuocheng
什么是RAG中的幻觉问题?引用溯源如何实现?
一、为什么RAG也会产生幻觉?
RAG(检索增强生成)技术的初衷是让大语言模型基于事实文档回答问题,避免胡说八道。但现实很骨感——RAG系统依然会产生幻觉,而且这些幻觉往往更隐蔽、更危险。
想象这样一个场景:你问公司的知识库助手"新员工年假怎么算",它回答"工作满1年享受5天年假,满10年享受10天"。听起来很合理,但公司实际政策是"工作满1年享受7天,满5年享受10天"。模型引用了一个不存在的数据,却因为听起来"像那么回事"而误导了你。
这种幻觉之所以危险,是因为用户天然信任"有来源"的答案。传统LLM的幻觉是赤裸裸的编造,而RAG的幻觉是披着事实外衣的精巧谎言。
RAG幻觉主要源于三个层面:
- 检索层:召回的文档本身就是错的,或者与问题不匹配
- 理解层:上下文被切分得支离破碎,模型在拼接理解时产生偏差
- 生成层:LLM用预训练知识"自作聪明"地填补空白,而非诚实说"我不知道"
二、什么是RAG中的幻觉问题?
RAG幻觉指的是检索增强生成系统在回答问题时,生成的内容虽然表面上看起来合理,但要么与检索到的文档不符,要么在文档中根本找不到依据,要么混合了模型的"常识"而产生了事实性错误。
简单来说:模型没有说实话,它要么在编造来源,要么在歪曲原文,要么在画蛇添足。
举个例子:
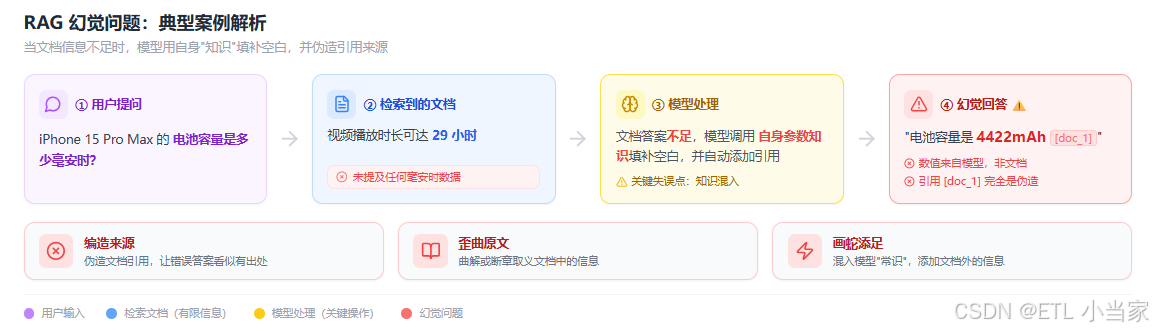
- 用户问:“iPhone 15 Pro Max的电池容量是多少毫安时?”
- 文档说:“iPhone 15 Pro Max的视频播放时长可达29小时”
- 幻觉回答:“iPhone 15 Pro Max的电池容量是4422mAh[doc_1]”
问题出在哪?文档根本没提具体毫安时数,模型用自己的知识填补了空白,还伪造了引用来源。这种幻觉在医疗、法律、金融等高风险领域尤其致命。
三、如何缓解RAG幻觉问题?
3.1 检索层的防御:提升召回精度
混合检索策略:向量+关键词双保险
稠密向量检索擅长语义理解,但对数字、日期、产品型号这类精确匹配内容不敏感。就像你问"2024年3月发布的政策",向量可能只关注"政策"而忽略了关键的时间约束。
实战方案:
用户提问 → 同时走两条路:
├─ 向量检索:召回语义相关的top-30
└─ 关键词提取:抽数字/日期/专有名词 → 关键词检索召回top-10
↓
合并去重 → 重排序 → 取top-5喂给LLM
这样既能理解"年假政策"的语义,又能精确匹配"2024年3月"这个时间点。
重排序模型:第二道防线
初筛可能召回几十篇文档,但LLM的上下文窗口有限。重排序模型用cross-encoder架构对query和每个文档做深度交互打分,比向量点积更精准。
工程实践:只对top-30做精排,平衡精度与速度。如果top-1得分超过0.9,可直接跳过重排序。
Chunk切分:魔鬼在细节
切分粒度直接影响信息完整性。切太大引入噪声,切太小破坏语义。推荐做法:
- 按段落或500 tokens固定长度切分
- 保留50 tokens重叠,避免关键信息被边界割裂
- 表格/列表保持完整,不要从中间切断
3.2 生成层的控制:Prompt工程的艺术
角色定位:激活保守模式
用"你是一个严谨的知识库助手"而非"AI助手"。前者激活模型的谨慎模式,后者让它更自由发挥。
明确边界:教会模型说"不"
不要只说"不知道就说不知道",而要明确规定:
“仅根据以下上下文回答,如果上下文中没有相关信息,必须明确回复’根据现有信息无法回答该问题’”
结构化输出:强制思考引用
要求模型输出JSON格式:
{
"answer": "你的回答",
"confidence": 0.0-1.0,
"citations": ["doc_1", "doc_2"]
}
这样强迫模型在生成时就考虑置信度和引用来源。
参数调整:降低随机性
- temperature: 0.1-0.3,让模型选择高概率token
- top-p: 0.9,限制token选择范围
四、引用溯源的实现方案
4.1 基础方案:Chunk打标签
最简单的做法是给每个文档块预埋引用标识:
public DocumentChunk prepareChunk(Document doc, String content, int index) {
DocumentChunk chunk = new DocumentChunk();
chunk.setContent(content);
Map<String, Object> metadata = new HashMap<>();
metadata.put("citation_id", String.format("[%s_%d]", doc.getId(), index));
metadata.put("source_title", doc.getTitle());
metadata.put("source_url", doc.getUrl());
chunk.setMetadata(metadata);
return chunk;
}
构造prompt时:
[doc_1] iPhone 15 Pro Max的视频播放时长可达29小时
[doc_2] 该机型支持有线充电和MagSafe无线充电
4.2 进阶方案:后处理验证
模型可能"忘记"标注引用。更可靠的做法是事后验证:
public List<Citation> verifyCitations(String answer, List<DocumentChunk> chunks) {
List<String> sentences = splitIntoSentences(answer);
for (String sentence : sentences) {
float[] sentenceEmbed = embeddingService.encode(sentence);
float maxSimilarity = 0;
DocumentChunk bestMatch = null;
for (DocumentChunk chunk : chunks) {
float[] chunkEmbed = embeddingService.encode(chunk.getContent());
float similarity = cosineSimilarity(sentenceEmbed, chunkEmbed);
if (similarity > maxSimilarity) {
maxSimilarity = similarity;
bestMatch = chunk;
}
}
// 相似度超过阈值自动补引用
if (maxSimilarity > 0.75) {
citations.add(new Citation(sentence, bestMatch));
}
}
return citations;
}
4.3 引用展示形式
| 形式 | 适用场景 | 优点 |
|---|---|---|
| Inline标注 | 维基百科风格,答案中直接嵌入[1][2] | 直观,溯源方便 |
| 脚注引用 | 学术论文风格,末尾统一列出 | 不打扰阅读节奏 |
| 高亮关联 | 点击句子→侧边栏展示原文 | 交互体验最佳,实现复杂 |
推荐:文档助手用高亮关联,客服问答用inline,知识库查询用脚注。
4.4 完整流程示例
用户提问
↓
混合检索(向量+关键词)
↓
重排序取top-5
↓
构造带引用标识的prompt
↓
LLM生成答案+引用
↓
后处理验证(相似度匹配)
↓
补充缺失的引用
↓
格式化输出(inline/脚注/高亮)
↓
展示给用户
五、实际应用与发展趋势
5.1 典型应用场景
1. 企业知识库问答
员工查询"公司报销政策中关于差旅费的标准",必须零幻觉。任何错误都可能导致财务纠纷。引用溯源让HR可以验证答案是否来自最新版政策文档。
2. 医疗咨询助手
患者问"糖尿病患者可以服用这种感冒药吗",答案必须附带药品说明书原文。Citation不是可选项,是医疗合规的必需品。
3. 法律文书分析
律师查询"劳动合同法第38条的具体解释",需要看到法条原文和关联判例。引用错误可能直接导致官司败诉。
4. 电商客服
用户问"iPhone 15 Pro Max支持多少瓦快充",需要精准召回产品参数页。如果模型用iPhone 14的数据回答,会导致退货纠纷。
5.2 当前局限性与改进方向
局限性:
- 成本问题:向量检索+重排序+LLM调用,全流程成本较高
- 速度瓶颈:后处理验证增加响应延迟
- 模型合规性:依赖模型遵循指令,小型模型效果差
- 多模态支持:图片、表格中的信息难以有效引用
改进方向:
- 缓存策略:高频问题预生成答案,80%请求避免调用LLM
- 模型分级:简单问题用小模型,复杂问题才用大模型
- 量化压缩:向量从float32压缩到int8,存储成本降至1/4
- 多模态RAG:结合视觉模型理解图表,实现图文混合引用
- Fine-tuning+RAG:用私有数据微调模型,让它学会领域知识结构,提升检索准确率
5.3 技术演进趋势
监控驱动优化:记录每次查询的召回率、置信度、用户反馈,发现某类问题幻觉率高就针对性优化chunk切分或prompt模板。
置信度评分体系:
public double calculateConfidence(String answer, List<DocumentChunk> chunks) {
double retrievalScore = chunks.stream().mapToDouble(c -> c.getRelevanceScore()).max().orElse(0.0);
double generationProb = metrics.getAverageTokenProbability();
double semanticSimilarity = calculateSemanticMatch(answer, chunks);
// 加权计算
return 0.3 * retrievalScore + 0.4 * generationProb + 0.3 * semanticSimilarity;
}
低于阈值触发人工审核或拒绝回答。
自我进化能力:把高频bad case标注后作为few-shot示例,让模型从错误中学习,形成持续优化闭环。
六、总结与思考
核心要点回顾:
- RAG幻觉源于检索质量低、上下文理解偏差、LLM填补空白三个层面
- 缓解策略需要分层防御:检索层提升精度,生成层加强约束
- Citation是生产环境RAG的必需品,不是可选项
- 实现Citation需要chunk标识+prompt约束+后处理验证三重保障
更深层的思考:
RAG技术揭示了一个根本性矛盾——我们既想利用LLM的创造性,又害怕它的创造性。幻觉本质上是一种创造性填补,在写小说时叫"想象力",在回答政策问题时叫"造谣"。
未来的方向可能不是彻底消除幻觉,而是让系统知道什么时候该保守,什么时候可创造。法律咨询场景要求零幻觉,创意写作场景需要适度幻觉。好的RAG系统应该能识别问题类型,自动调整置信度阈值和引用严格度。
此外,Citation的价值不仅在于"证明我没说谎",更在于建立人机信任。当用户能一键溯源到原文,他们更愿意采纳AI的建议。这种透明度不是成本,而是投资——投资用户对AI系统的长期信任。
最后,记住一个工程原则:不要相信LLM的诚实,要相信代码的约束。再强大的模型也需要工程化的护栏,这才是RAG系统走向生产环境的关键。
技术关键词:RAG、幻觉缓解、引用溯源、混合检索、重排序、Prompt工程、置信度评估
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
by @Laizhuocheng
什么是RAG中的幻觉问题?引用溯源如何实现?
一、为什么RAG也会产生幻觉?
RAG(检索增强生成)技术的初衷是让大语言模型基于事实文档回答问题,避免胡说八道。但现实很骨感——RAG系统依然会产生幻觉,而且这些幻觉往往更隐蔽、更危险。
想象这样一个场景:你问公司的知识库助手"新员工年假怎么算",它回答"工作满1年享受5天年假,满10年享受10天"。听起来很合理,但公司实际政策是"工作满1年享受7天,满5年享受10天"。模型引用了一个不存在的数据,却因为听起来"像那么回事"而误导了你。
这种幻觉之所以危险,是因为用户天然信任"有来源"的答案。传统LLM的幻觉是赤裸裸的编造,而RAG的幻觉是披着事实外衣的精巧谎言。
RAG幻觉主要源于三个层面:
- 检索层:召回的文档本身就是错的,或者与问题不匹配
- 理解层:上下文被切分得支离破碎,模型在拼接理解时产生偏差
- 生成层:LLM用预训练知识"自作聪明"地填补空白,而非诚实说"我不知道"
二、什么是RAG中的幻觉问题?
RAG幻觉指的是检索增强生成系统在回答问题时,生成的内容虽然表面上看起来合理,但要么与检索到的文档不符,要么在文档中根本找不到依据,要么混合了模型的"常识"而产生了事实性错误。
简单来说:模型没有说实话,它要么在编造来源,要么在歪曲原文,要么在画蛇添足。
举个例子:
- 用户问:“iPhone 15 Pro Max的电池容量是多少毫安时?”
- 文档说:“iPhone 15 Pro Max的视频播放时长可达29小时”
- 幻觉回答:“iPhone 15 Pro Max的电池容量是4422mAh[doc_1]”
问题出在哪?文档根本没提具体毫安时数,模型用自己的知识填补了空白,还伪造了引用来源。这种幻觉在医疗、法律、金融等高风险领域尤其致命。
三、如何缓解RAG幻觉问题?
3.1 检索层的防御:提升召回精度
混合检索策略:向量+关键词双保险
稠密向量检索擅长语义理解,但对数字、日期、产品型号这类精确匹配内容不敏感。就像你问"2024年3月发布的政策",向量可能只关注"政策"而忽略了关键的时间约束。
实战方案:
用户提问 → 同时走两条路:
├─ 向量检索:召回语义相关的top-30
└─ 关键词提取:抽数字/日期/专有名词 → 关键词检索召回top-10
↓
合并去重 → 重排序 → 取top-5喂给LLM
这样既能理解"年假政策"的语义,又能精确匹配"2024年3月"这个时间点。
重排序模型:第二道防线
初筛可能召回几十篇文档,但LLM的上下文窗口有限。重排序模型用cross-encoder架构对query和每个文档做深度交互打分,比向量点积更精准。
工程实践:只对top-30做精排,平衡精度与速度。如果top-1得分超过0.9,可直接跳过重排序。
Chunk切分:魔鬼在细节
切分粒度直接影响信息完整性。切太大引入噪声,切太小破坏语义。推荐做法:
- 按段落或500 tokens固定长度切分
- 保留50 tokens重叠,避免关键信息被边界割裂
- 表格/列表保持完整,不要从中间切断
3.2 生成层的控制:Prompt工程的艺术
角色定位:激活保守模式
用"你是一个严谨的知识库助手"而非"AI助手"。前者激活模型的谨慎模式,后者让它更自由发挥。
明确边界:教会模型说"不"
不要只说"不知道就说不知道",而要明确规定:
“仅根据以下上下文回答,如果上下文中没有相关信息,必须明确回复’根据现有信息无法回答该问题’”
结构化输出:强制思考引用
要求模型输出JSON格式:
{
"answer": "你的回答",
"confidence": 0.0-1.0,
"citations": ["doc_1", "doc_2"]
}
这样强迫模型在生成时就考虑置信度和引用来源。
参数调整:降低随机性
- temperature: 0.1-0.3,让模型选择高概率token
- top-p: 0.9,限制token选择范围
四、引用溯源的实现方案
4.1 基础方案:Chunk打标签
最简单的做法是给每个文档块预埋引用标识:
public DocumentChunk prepareChunk(Document doc, String content, int index) {
DocumentChunk chunk = new DocumentChunk();
chunk.setContent(content);
Map<String, Object> metadata = new HashMap<>();
metadata.put("citation_id", String.format("[%s_%d]", doc.getId(), index));
metadata.put("source_title", doc.getTitle());
metadata.put("source_url", doc.getUrl());
chunk.setMetadata(metadata);
return chunk;
}
构造prompt时:
[doc_1] iPhone 15 Pro Max的视频播放时长可达29小时
[doc_2] 该机型支持有线充电和MagSafe无线充电
4.2 进阶方案:后处理验证
模型可能"忘记"标注引用。更可靠的做法是事后验证:
public List<Citation> verifyCitations(String answer, List<DocumentChunk> chunks) {
List<String> sentences = splitIntoSentences(answer);
for (String sentence : sentences) {
float[] sentenceEmbed = embeddingService.encode(sentence);
float maxSimilarity = 0;
DocumentChunk bestMatch = null;
for (DocumentChunk chunk : chunks) {
float[] chunkEmbed = embeddingService.encode(chunk.getContent());
float similarity = cosineSimilarity(sentenceEmbed, chunkEmbed);
if (similarity > maxSimilarity) {
maxSimilarity = similarity;
bestMatch = chunk;
}
}
// 相似度超过阈值自动补引用
if (maxSimilarity > 0.75) {
citations.add(new Citation(sentence, bestMatch));
}
}
return citations;
}
4.3 引用展示形式
| 形式 | 适用场景 | 优点 |
|---|---|---|
| Inline标注 | 维基百科风格,答案中直接嵌入[1][2] | 直观,溯源方便 |
| 脚注引用 | 学术论文风格,末尾统一列出 | 不打扰阅读节奏 |
| 高亮关联 | 点击句子→侧边栏展示原文 | 交互体验最佳,实现复杂 |
推荐:文档助手用高亮关联,客服问答用inline,知识库查询用脚注。
4.4 完整流程示例
用户提问
↓
混合检索(向量+关键词)
↓
重排序取top-5
↓
构造带引用标识的prompt
↓
LLM生成答案+引用
↓
后处理验证(相似度匹配)
↓
补充缺失的引用
↓
格式化输出(inline/脚注/高亮)
↓
展示给用户
五、实际应用与发展趋势
5.1 典型应用场景
1. 企业知识库问答
员工查询"公司报销政策中关于差旅费的标准",必须零幻觉。任何错误都可能导致财务纠纷。引用溯源让HR可以验证答案是否来自最新版政策文档。
2. 医疗咨询助手
患者问"糖尿病患者可以服用这种感冒药吗",答案必须附带药品说明书原文。Citation不是可选项,是医疗合规的必需品。
3. 法律文书分析
律师查询"劳动合同法第38条的具体解释",需要看到法条原文和关联判例。引用错误可能直接导致官司败诉。
4. 电商客服
用户问"iPhone 15 Pro Max支持多少瓦快充",需要精准召回产品参数页。如果模型用iPhone 14的数据回答,会导致退货纠纷。
5.2 当前局限性与改进方向
局限性:
- 成本问题:向量检索+重排序+LLM调用,全流程成本较高
- 速度瓶颈:后处理验证增加响应延迟
- 模型合规性:依赖模型遵循指令,小型模型效果差
- 多模态支持:图片、表格中的信息难以有效引用
改进方向:
- 缓存策略:高频问题预生成答案,80%请求避免调用LLM
- 模型分级:简单问题用小模型,复杂问题才用大模型
- 量化压缩:向量从float32压缩到int8,存储成本降至1/4
- 多模态RAG:结合视觉模型理解图表,实现图文混合引用
- Fine-tuning+RAG:用私有数据微调模型,让它学会领域知识结构,提升检索准确率
5.3 技术演进趋势
监控驱动优化:记录每次查询的召回率、置信度、用户反馈,发现某类问题幻觉率高就针对性优化chunk切分或prompt模板。
置信度评分体系:
public double calculateConfidence(String answer, List<DocumentChunk> chunks) {
double retrievalScore = chunks.stream().mapToDouble(c -> c.getRelevanceScore()).max().orElse(0.0);
double generationProb = metrics.getAverageTokenProbability();
double semanticSimilarity = calculateSemanticMatch(answer, chunks);
// 加权计算
return 0.3 * retrievalScore + 0.4 * generationProb + 0.3 * semanticSimilarity;
}
低于阈值触发人工审核或拒绝回答。
自我进化能力:把高频bad case标注后作为few-shot示例,让模型从错误中学习,形成持续优化闭环。
六、总结与思考
核心要点回顾:
- RAG幻觉源于检索质量低、上下文理解偏差、LLM填补空白三个层面
- 缓解策略需要分层防御:检索层提升精度,生成层加强约束
- Citation是生产环境RAG的必需品,不是可选项
- 实现Citation需要chunk标识+prompt约束+后处理验证三重保障
更深层的思考:
RAG技术揭示了一个根本性矛盾——我们既想利用LLM的创造性,又害怕它的创造性。幻觉本质上是一种创造性填补,在写小说时叫"想象力",在回答政策问题时叫"造谣"。
未来的方向可能不是彻底消除幻觉,而是让系统知道什么时候该保守,什么时候可创造。法律咨询场景要求零幻觉,创意写作场景需要适度幻觉。好的RAG系统应该能识别问题类型,自动调整置信度阈值和引用严格度。
此外,Citation的价值不仅在于"证明我没说谎",更在于建立人机信任。当用户能一键溯源到原文,他们更愿意采纳AI的建议。这种透明度不是成本,而是投资——投资用户对AI系统的长期信任。
最后,记住一个工程原则:不要相信LLM的诚实,要相信代码的约束。再强大的模型也需要工程化的护栏,这才是RAG系统走向生产环境的关键。
技术关键词:RAG、幻觉缓解、引用溯源、混合检索、重排序、Prompt工程、置信度评估

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)