2026 AI 算力全栈拆解:不止 GPU,撑起现代 AI 的 6 大核心处理器全解析
2026 年,AI 已经完成了从实验室技术到千行百业基础设施的全面渗透:万亿参数的大模型持续迭代,端侧 AI 实现了手机离线运行 70B 级模型的突破,Agentic AI 从 Demo 走向了企业级生产落地,整个行业对算力的需求呈指数级增长。
但行业的目光,几乎始终聚焦在 NVIDIA 的 GPU 身上 ——H100、Blackwell 几乎成了 AI 算力的代名词,人人都在谈论 GPU 如何驱动 AI 革命,却几乎没人关注一个核心真相:一套完整的 AI 系统,从用户请求接入、模型训练、推理响应到数据中心全链路运维,从来都不是靠单一 GPU 跑通的。
现代 AI 的底层算力底座,是 6 种不同架构的处理器各司其职、协同工作的异构计算体系。它们分别针对 AI 全链路的不同工作负载做了极致优化,共同构成了 AI 时代的算力骨架。本文将全维度拆解这 6 大核心处理器,厘清它们的架构本质、能力边界、优劣势与适用场景,还原现代 AI 算力的完整图景。
一、为什么 AI 需要异构计算?单一芯片无法覆盖的全链路需求
AI 的全生命周期,是一套极度复杂的工作流组合:既有需要强单核性能的串行调度任务,也有需要海量并行算力的矩阵计算任务,还有需要极致低延迟的端侧推理任务,更有需要确定性响应的实时服务任务。
通用处理器的核心矛盾,在于 “通用” 就意味着无法在所有场景都做到最优。CPU 的强单核性能无法应对海量并行的矩阵乘法,GPU 的高并行算力在简单串行任务上算力过剩、功耗浪费,端侧设备无法承受 GPU 的高功耗,数据中心的基础设施开销又会挤占核心 AI 计算的资源。
而异构计算,就是为不同的工作负载匹配专门优化的处理器,让每一个环节都能实现性能、功耗、成本的最优解。这 6 种处理器,正是针对 AI 全链路不同环节的专属答案,它们没有绝对的优劣,只有场景的适配。
二、6 大核心处理器全拆解:AI 算力体系的每一环,都不可或缺
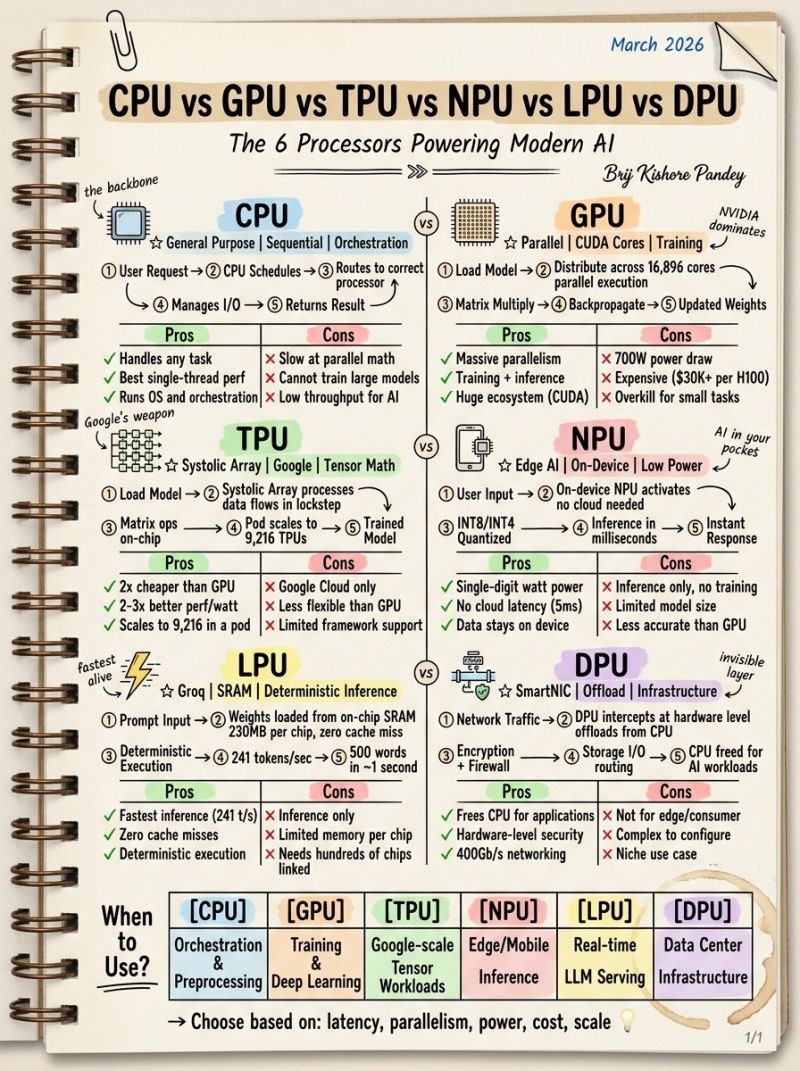
CPU:AI 栈的全能项目经理,整个系统的脊梁
核心定位:通用型处理器,整个 AI 系统的调度中枢与 backbone(脊梁),是所有 AI 任务的起点与总指挥。架构本质:以少数高性能核心为核心,擅长串行逻辑处理、分支预测、复杂指令集执行,核心设计目标是 “应对所有通用任务”,而非专项算力优化。
它的工作流贯穿了 AI 任务的全生命周期:
- 接收用户发起的 AI 请求,完成初步的任务解析与资源调度;
- 将核心计算任务路由到对应的专用处理器(GPU/TPU/LPU 等);
- 全程管理系统 I/O、内存分配、任务优先级与中断处理;
- 完成计算结果的最终整合,返回给用户。
核心优势:
- 全场景通用能力,可处理任何类型的计算任务,是操作系统与 AI 框架运行的基础;
- 行业顶尖的单线程性能,是串行调度、分支判断、数据预处理的最优解;
- 完整的生态适配性,所有 AI 开发框架、工具链都以 CPU 为基础构建,是整个 AI 栈的编排核心。
核心短板:
- 并行数学计算能力极弱,核心数量有限,完全无法胜任大模型训练所需的海量矩阵乘法;
- AI 任务的吞吐量极低,仅能做调度管控,无法承担核心的 AI 训练与推理计算;
- 面对高度并行的 AI 工作负载,能效比远低于专用处理器。
核心适用场景:系统编排与任务调度、数据预处理、AI 框架运行管控、I/O 管理,是整个 AI 系统的 “项目经理”,没有它,再强的专用算力也无法有序工作。
GPU:AI 训练的并行巨兽,行业绝对的主流算力
核心定位:并行计算核心,大模型训练与批量推理的绝对主力,NVIDIA 凭借 CUDA 生态实现了市场垄断。架构本质:将数以万计的轻量化 CUDA 核心集成在单芯片上,专为高度并行的简单计算任务优化 —— 而深度学习与大模型训练的核心,就是海量的矩阵乘法,恰好是 GPU 的绝对主场。以 H100 为例,单芯片集成了 16896 个 CUDA 核心,可同时完成数万次并行计算,将大模型训练的效率提升了数个数量级。
它的核心工作流,就是大模型训练的完整闭环:
- 将预训练模型与数据集加载到显存中;
- 将计算任务分发到数千个 CUDA 核心,实现并行执行;
- 完成前向传播的矩阵乘法计算,输出模型预测结果;
- 通过反向传播计算损失梯度;
- 完成模型权重的迭代更新,重复循环直到模型收敛。
核心优势:
- 极致的大规模并行计算能力,是目前大模型训练的最优解;
- 同时支持模型训练与推理,覆盖从科研到生产的全场景需求;
- 拥有 CUDA 这个行业无可替代的生态护城河,几乎所有 AI 框架、工具、模型都原生适配,开发者门槛极低,生态成熟度遥遥领先。
核心短板:
- 极高的功耗与成本,单张 H100 功耗可达 700W,市场售价超过 3 万美元,是中小企业私有化部署的核心门槛;
- 场景适配性有限,面对简单的小模型推理、端侧任务,算力严重过剩,能效比极低;
- 内存墙瓶颈日益凸显,大模型推理中反复的显存读写,成为了延迟优化的核心阻碍。
核心适用场景:大模型预训练与微调、深度学习任务开发、大规模批量推理,是目前 AI 行业的算力基石,绝大多数主流大模型,都诞生于 NVIDIA GPU 组成的算力集群。
TPU:谷歌的张量计算利器,超大规模训练的成本杀手
核心定位:专为张量计算设计的专用 AI 芯片,谷歌自研的 AI 算力武器,专为超大规模 AI 训练场景优化。架构本质:采用脉动阵列(Systolic Array)架构,完全抛弃了通用计算核心,所有硬件单元都围绕 AI 核心的张量运算设计。它的核心创新,是让数据在处理单元之间以锁步方式流动,无需反复读写内存,彻底解决了 GPU 矩阵计算中的内存访问瓶颈,大幅提升了张量计算的效率与能效比。
它的工作流完全为超大规模张量计算优化:
- 将目标模型加载到 TPU 的片上内存中;
- 脉动阵列以锁步方式处理数据流,无需中断与内存读写;
- 完全在片上完成矩阵乘法、激活函数等核心张量运算;
- 可无缝扩展到单 Pod 9216 个 TPU 的超大规模集群,实现线性算力提升;
- 完成超大规模模型的训练与收敛。
核心优势:
- 规模化部署下,成本仅为同级别 GPU 的 1/2,每瓦性能是 GPU 的 2-3 倍,超大规模训练的性价比远超 GPU;
- 专为张量计算优化,无通用计算的额外开销,大模型训练的算力利用率远高于 GPU;
- 极强的横向扩展能力,单 Pod 可集成 9216 个 TPU,支撑万亿参数大模型的端到端训练,谷歌 Gemini、PaLM 系列大模型,均诞生于 TPU 集群。
核心短板:
- 生态极度封闭,仅在谷歌云 GCP 中可用,无法实现私有化部署,适用范围受限;
- 灵活性远不如 GPU,仅针对张量计算优化,无法胜任通用计算任务,场景单一;
- 框架支持有限,对 TensorFlow 生态适配最佳,对 PyTorch 等其他框架的适配性不如 CUDA,开发者门槛较高。
核心适用场景:谷歌云生态下的超大规模张量计算、万亿参数大模型训练、标准化的 AI 训练任务,是超大规模 AI 企业的核心算力选择。
NPU:口袋里的端侧 AI,边缘场景的推理核心
核心定位:神经网络处理器,专为边缘 / 移动设备的低功耗端侧推理设计,是实现 “AI 在你口袋里” 的核心载体。架构本质:专为神经网络推理优化的轻量化架构,主打极致低功耗,单芯片功耗可控制在个位数瓦以内,通常集成在手机、平板、智能汽车、IoT 设备的 SoC 中,典型代表就是苹果的 Neural Engine、高通的 Hexagon NPU、联发科的 APU。
它的工作流完全围绕端侧低延迟推理设计:
- 接收用户在设备上的输入(语音、图像、文本等);
- 直接激活设备本地的 NPU,无需连接云端,无网络依赖;
- 对量化后的 INT8/INT4 模型进行本地推理计算;
- 数毫秒内完成推理计算,无云端传输延迟;
- 直接在设备上输出推理结果,实现即时响应。
核心优势:
- 极致低功耗,仅需个位数瓦的供电,即可完成 AI 推理,完美适配电池供电的移动设备;
- 无云端延迟,端侧本地计算可实现 5ms 级的响应速度,远超云端推理;
- 极致的隐私安全,所有数据都留在设备本地,无需上传云端,彻底规避了数据泄露的风险,是强隐私场景的最优解。
核心短板:
- 仅支持推理任务,无法完成模型训练,能力边界清晰;
- 算力与内存有限,仅能运行量化后的中小规模模型,无法支撑超大模型的端侧运行;
- 计算精度受限于量化位宽,推理精度不如 GPU、TPU 等云端算力。
核心适用场景:手机、智能汽车、IoT 设备的端侧 AI 推理,包括人脸识别、实时语音助手、离线翻译、影像实时处理等,是 AI 向边缘场景渗透的核心载体。
LPU:大模型推理的速度狂魔,实时响应的终极答案
核心定位:Groq 自研的语言处理单元,专为大语言模型的低延迟、高吞吐量推理设计,是目前 AI 推理领域的速度天花板。架构本质:彻底颠覆了传统 GPU 的推理架构,将大模型的所有权重全部存储在片上 SRAM 中,无需访问 DRAM 内存,实现了零缓存缺失、确定性执行,彻底解决了大模型推理中的 “内存墙” 瓶颈。传统 GPU 推理的最大延迟来源,就是反复从显存中读写权重与数据,而 LPU 让所有数据都在片上流动,无需来回调度,将推理延迟降到了极致。
它的工作流专为实时大模型推理优化:
- 接收用户输入的 Prompt,直接加载到片上处理单元;
- 模型权重直接从片上 SRAM 中调用,230W 功耗,零缓存缺失,无内存访问延迟;
- 基于张量流架构完成确定性执行,无调度开销;
- 实现 241 tokens/sec 的极致推理速度,1 秒即可生成 500 词的文本;
- 完成流式响应输出,实现无感知的实时对话。
核心优势:
- 行业顶尖的推理速度,241 tokens/sec 的吞吐量是同级别 GPU 的数倍,是实时大模型服务的最优解;
- 零缓存缺失,完全确定性的执行,延迟无波动,可精准预测响应时间,完美适配实时交互场景;
- 能效比远超 GPU,在大模型推理场景下,单位功耗的吞吐量是 GPU 的 3 倍以上。
核心短板:
- 仅支持推理任务,无法完成模型训练,场景单一;
- 单芯片的片上内存有限,运行超大模型需要数百个芯片级联,部署成本较高;
- 生态成熟度远不如 CUDA,框架适配与开发者工具链仍在完善中。
核心适用场景:实时大语言模型服务、低延迟对话 AI、实时流式生成、语音同步翻译等对响应速度有极致要求的场景,是 AI 实时交互体验的核心保障。
DPU:数据中心的隐形层,基础设施的卸载专家
核心定位:数据处理器,也叫智能网卡(SmartNIC),专为数据中心的基础设施任务卸载设计,是超大规模 AI 集群的隐形支撑。架构本质:集成了网络处理、存储 I/O、安全加密、虚拟化管控能力的专用处理器,核心目标是在硬件层面处理数据中心的基础设施开销,将 CPU 从网络、存储、防火墙等重复繁琐的任务中解放出来,让 CPU 与 GPU 能够专注于核心的 AI 计算任务。典型代表包括 NVIDIA BlueField 系列、AWS Nitro 系统、英特尔 IPU。
它的工作流完全围绕基础设施卸载设计:
- 直接在硬件层面拦截数据中心的网络流量,无需经过 CPU;
- 硬件级完成网络协议处理、加密解密、防火墙过滤等安全任务;
- 接管存储 I/O 的路由与管控,完成存储虚拟化与性能优化;
- 处理虚拟化、租户隔离、运维监控等数据中心基础设施任务;
- 彻底释放 CPU 的算力,让其专注于 AI 任务的调度与应用层计算。
核心优势:
- 彻底解放 CPU 算力,将数据中心 70% 以上的基础设施开销从 CPU 卸载,大幅提升 AI 集群的算力利用率;
- 硬件级的安全管控,实现网络与存储的隔离加密,是云数据中心与超大规模 AI 集群的安全核心;
- 极致的网络性能,支持 400Gb/s 甚至更高的网络带宽,大幅降低 AI 集群的节点间通信延迟,解决分布式训练的网络瓶颈。
核心短板:
- 专为数据中心场景设计,完全不适合消费级与普通用户,场景极度小众;
- 配置与运维门槛极高,需要专业的基础设施团队管理,中小企业难以落地;
- 仅针对基础设施任务优化,无法承担核心的 AI 计算任务,是辅助性的算力支撑。
核心适用场景:超大规模数据中心、云服务器虚拟化平台、分布式 AI 训练集群的基础设施管控,是 AI 算力集群背后的隐形支撑,没有它,超大规模 AI 集群的高效稳定运行就无从谈起。
三、AI 算力的真相:从来不是单一芯片的胜利,而是全栈协同
我们可以用一个最常见的用户场景,还原这 6 大处理器的完整协同链路,看清 AI 到底是如何跑起来的:
当你拿起手机,用语音助手发起一个大模型对话请求时:
- 你的语音输入首先被手机里的NPU接管,在本地完成语音转文字、意图识别预处理,全程离线、毫秒级响应,数据完全不用出设备;
- 预处理后的请求通过网络发送到云端数据中心,首先由DPU在硬件层面拦截网络流量,完成加密解密、防火墙过滤、路由转发,全程无需 CPU 介入;
- 服务器的CPU接收到请求后,作为总指挥完成任务解析、资源调度,将推理任务分发给对应的算力单元,同时管控全流程的内存与 I/O;
- 如果是常规的对话推理,任务会交给GPU完成;如果是需要极致低延迟的实时流式对话,任务会交给LPU处理,实现 241 tokens/sec 的秒级响应;如果是需要同步完成的大模型微调训练,任务会交给TPU集群处理;
- 推理完成后,结果经由CPU调度、DPU封装回包,发送回你的手机;
- 手机里的NPU再次接管,完成文字转语音的端侧推理,实时播放出助手的回复。
这就是现代 AI 的完整真相:它从来不是靠某一款明星芯片跑通的,而是 6 大处理器各司其职、协同工作的结果。CPU 做调度,GPU/TPU 做训练,NPU 做端侧推理,LPU 做实时服务,DPU 做基础设施支撑,缺了任何一环,都无法实现高效、稳定、低成本的 AI 服务。
四、行业终局:全栈算力布局,才是 AI 时代的核心竞争力
2026 年的 AI 行业竞争,早已从单一的模型能力内卷,延伸到了底层算力的全栈布局。每一家主流的 AI 巨头,都在这 6 大处理器的赛道上全面押注:
- 谷歌构建了从端到云的全栈算力体系,手机端的 Tensor G 系列 NPU、云端的 TPU、自研 ARM 架构 CPU、基础设施 DPU 全面覆盖,为 Gemini 系列大模型打造了专属的算力底座;
- NVIDIA 从 GPU 的绝对垄断,向全栈算力扩张,Grace CPU、BlueField DPU、Orin NPU 全面布局,打造了覆盖从训练到推理、从云端到边缘的完整 AI 算力生态;
- 微软与 OpenAI 深度绑定,同时自研 Azure Maia AI 芯片(对标 TPU)、Azure Cobalt CPU 与基础设施 DPU,为 GPT 系列大模型打造了专属的算力集群;
- Groq 专注 LPU 赛道,在实时推理领域撕开了 NVIDIA 的垄断缺口,成为了低延迟大模型服务的首选;
- 苹果、高通、联发科则深耕 NPU 赛道,持续迭代端侧 AI 算力,推动大模型向手机、汽车等边缘场景全面渗透。
对于开发者与企业而言,理解这 6 大处理器的能力边界,比盲目追逐 GPU 的参数更重要。AI 算力的选型,从来不是 “选最好的”,而是 “选最适配场景的”—— 你需要根据任务的延迟要求、并行度需求、功耗限制、成本预算、部署规模,选择对应的算力方案。
AI 时代的算力革命,从来不是单一芯片的胜利,而是异构计算的全面爆发。GPU 是聚光灯下的明星,但真正撑起现代 AI 的,是这 6 种处理器共同构建的完整算力体系。只有理解了这个完整的算力底座,才能真正把握 AI 技术的底层逻辑,在 AI 时代的竞争中占据先机。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 27
27 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)