强化学习理论3 基于策略梯度的强化学习 I 对方差和偏差的优化
基于策略梯度的算法
先混个眼熟,学完你就知道这个公式的优美之处了:

基于Q的学习存在几个问题:
很难映射到连续动作空间
有可能发散
学习Q与预期收益无关系 等
那我们能否直接学习策略Π呢?
Policy Gradient 是强化学习中从“价值驱动”转向“策略驱动”的关键转折点

整体目标:我们想直接优化策略 π(a|s)
每个策略都有一组权重参数控制,其实最简单的线性回归也是一种策略,其中的参数就是矩阵[a,b],斜率和偏移。
这里也一样,我们把这组控制策略的参数整体命名为θ,那么我们的优化目标实际上就是找到一个(一组参数)θ使得该策略能在任何状态下都能拿到最高分。
这就是这个式子:![]() =》
=》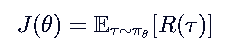
意思是:“用当前策略 π_θ 去跑很多条轨迹 τ,算平均总奖励 R(τ),我们希望这个平均值越大越好。”
怎么优化 J(θ)?→ 用梯度上升!
我们把θ当作一个变量看待,这样就可以类比二次函数找极值点的问题,只需要求出导数,不断迭代即可。在矩阵中,也有对应的导数,雅可比或黑塞(二阶导)。我们不考虑这么多,就按照普通参数来考虑。
既然要最大化 J(θ),那就求梯度 ∇_θ J(θ),然后往梯度方向更新 θ:
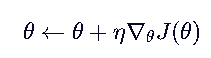
这个和梯度下降有区别,梯度下降是为了找到误差最小的点,因此是减号,我们的优化目标是使得“在多条轨迹下,这个θ主导的策略能获得最多的累计奖励”,因此优化方向是加号。
如何求导?
问题来了,
J(θ) 是个期望,没法直接求导!
于是开始了一系列“魔法操作”——其实都是为了把这个期望梯度变成可以采样的形式。
我没看懂,但希望你能看懂。


问题:上面的公式方差太大!
因为 R(τ) 是整个轨迹的总回报,它包含了很多噪声。比如某次运气好得了高分,不代表某个动作真的好。
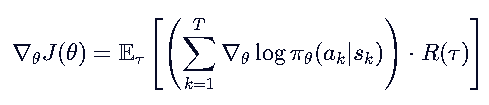
✅ 解决方案1:用 未来回报Gk 替代 全程回报Rt
定义:
![]()
→ 从时刻 k 开始的未来折现回报
于是公式变成: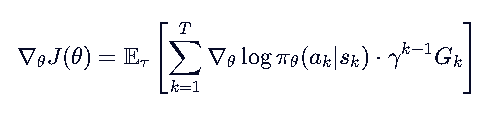
R(τ) 是整条轨迹的总回报,而 Gt 是“从时刻 t 开始”的未来回报。使用 Gt 后, t 时刻的动作只由它产生的后果(未来奖励)来评估,去除了过去无关奖励的干扰,显著降低了方差。(直观理解:你现在的决策无法改变历史,所以历史奖励对你的梯度更新没有指导意义,只会增加噪声。)
R(τ) 包含了所有时刻的奖励。如果你在 t=1 做了一个好动作,但在 t=50 因为运气不好得了低分,整个 R(τ) 都会很低。这会导致 t=1 的好动作也被“惩罚”,梯度方向变得混乱,训练极不稳定。
✅ 解决方案2:引入 Baseline(基线)[优势函数的CALLBACK]
虽然用了 Gk ,但方差仍然可能很大(比如某些状态本身就好/坏,导致所有动作的 Gk 都高/低)。
基线是什么:比如数据如下,如果以0为基线,那么计算的方差老大了,如果我们使用均值V(S)作为基线,方差一下就降下来了。
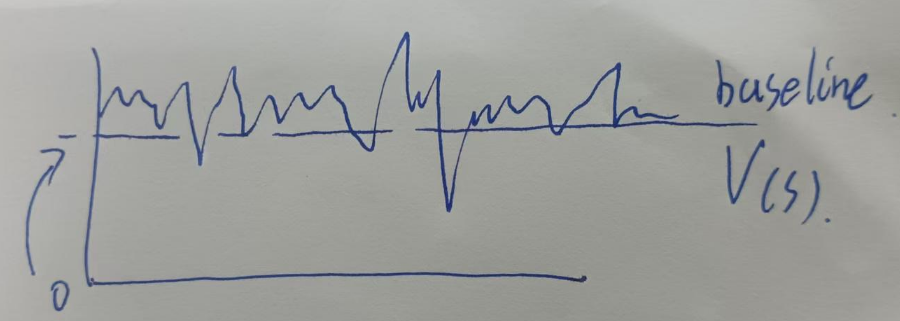
我们引入一个只依赖于状态 sk 的基线函数 b(sk) ,并减去它,只要 b(sk) 不依赖于动作 ak ,就不会改变梯度的期望!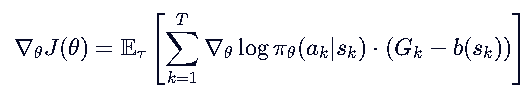
这个b(sk)选谁呢?
常用选择: b(sk)=V(sk) —— 状态价值函数‘
现在我们有: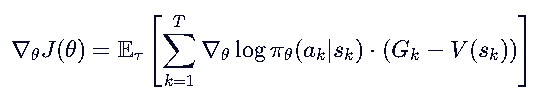
注意!!!
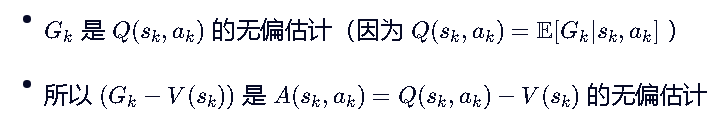
所以我们也可以写成:
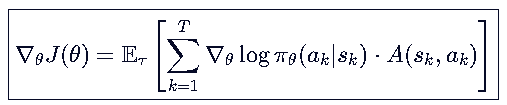
优势函数是衡量当前动作相对于平均表现的好坏的,当做的更好,A(s,a)>0,就更新θ权重矩阵,让这个动作发生得更多。
如果忘记了优势函数的定义,这里也再次给你:


但在原书的迭代过程中会涉及一个ω的更新,这个ω是来自于。
这个也很好理解,我们看到之前这张图,当Π(θ)改变后,状态价值V(s)必然改变,因此也需要更新,而ω就是控制的参数。也就是说,这是一个教学相长的过程,θ和ω交替更新!
你是不是想到了什么?这就是Actor-Critic模型的雏形。其中,Actor是PolicyModel,Critic是ValueModel(baseline就是基准)。
| 步骤 | 公式 | 特点 | 算法名称 |
|---|---|---|---|
| 1️⃣ 原始 | 高方差,包含历史噪声 | — | |
| 2️⃣ 因果优化 | 去掉历史,仍高方差 | REINFORCE | |
| 3️⃣ 引入 Baseline | 降方差,无偏 | REINFORCE with Baseline | |
| 4️⃣ 优势函数 | 最低方差(理想),相对评估 | Actor-Critic, PPO, A3C |
另一种表达形式
前面使用的是轨迹采样,有时候我们需要类似(s,a)的采样,本身轨迹就是一系列sa的序列,很好代换。
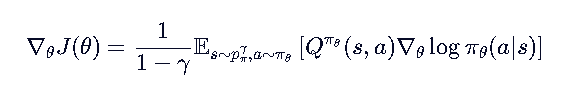
其中:
- ρ_π^γ(s):折扣状态下访问状态 s 的期望次数
- p_π^t(s₀ → s, t):从 s₀ 出发走 t 步到 s 的概率
整理捋一遍
将对Q的优化转为对策略派的优化,优化策略就是优化权重矩阵θ,目标是使得当前策略在多条轨迹下,这个θ主导的策略能获得最多的累计奖励”,方案是梯度上升,但是由于期望没有梯度,我们巧妙转换了这个公式。
但是用这个梯度公式更新,方差很大,于是我们考虑用未来回报Gt代替全程奖励Rt,防止前期奖励扩大方差。
但方差还是很大,于是我们考虑更改基线,引入基线函数,进而推导出优势函数下的梯度公式。
这个公式的直观理解也很清晰:
优势函数是衡量当前动作相对于平均表现的好坏的,当做的更好,A(s,a)>0,就更新θ权重矩阵,让这个动作发生得更多。
最后,我们补充了一个教学相长的更新模式,也就是AC模型的前身。
A2C模型
我们刚才推导的 REINFORCE with Baseline中,ω控制的V价值模型采用蒙特卡洛的更新方式,如果 ω 是通过 时序差分误差 (TD Error) 来更新的,那么它在数学结构上就已经 等价于 Actor-Critic 算法 了。
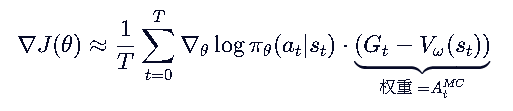
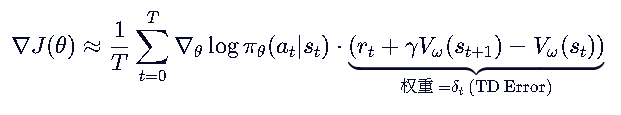


GAE的优化
但又有新问题了,
- MC 方法(如 REINFORCE):无偏但高方差
- TD 方法(如 A2C):低方差但有偏
→ 我们想要一个既不太偏、也低方差的优势估计!
GAE 的核心思想:
通过引入参数 λ ,对 任意步数的估计优势 按照合理的置信度加和,作为奖励项。
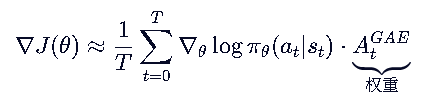

指的是 【前n步使用TD,后用MC】 的情况下的优势估计
当n=1时,就是单步的时序差分TD,可信度极高,极其稳定,但偏差极大
当n->∞时,就是蒙特卡洛MC,可信度较低,极其不稳定,但偏差极低
为了无论多少步,都能适用这个公式,我们构建一个 奖励估计和,把所有的步数的情况考虑进来
这个肯定不准,因为他把置信度低的 和 置信度高的优势估计加一起了,因此我们需要根据置信度为这个奖励估计和设计折扣因子:
展开看的清楚:
![]()
前面这个λ就是我们引入的折扣因子。
当 λ=0 ,这个奖励估计和就退化为 AC模型(单步 TD),只剩下步长为1时的奖励了。
当 λ=1 ,退化为 REINFORCE (MC),只剩下趋于无穷的蒙特卡洛奖励了。
一般地,我们选择 λ≈0.95 ,它在保持低方差的同时极大地减少了偏差,成为 PPO、TRPO、SAC 等现代 SOTA 算法的标准配置。
GAE通过λ构建了一个收敛的级数和,每一项是不同步长的优势估计(内部用γ确定折扣因子,综合了前i步为TD,后面为MC的情况)。他不依赖n,直接从1加到无穷,但是由于其是收敛的,一定可以得到一个值,作为最终的奖励权重。
大总结
所有的策略梯度算法都在更新两个模型——θ控制的策略模型,和ω控制的价值模型。
基于前文,我们知道传统的V模型有单步更新的时序差分TD模型,和走完更新的蒙特卡洛MC模型
而Π策略模型有【未来回报Gk 替代 全程回报Rt】和【基线模型】两种。
那么对于Reinforce With BaseLine而言,采用基线模型和蒙特卡洛方案
但太慢了
于是将对ω的更新改为单步的时序差分模型,这就是Actor-Critic模型
但这样偏差太大了,于是考虑综合偏差和方差的优势,
提出了GAE
GAE不管前n步是什么,直接将所有可能的步数加在一起,成为一坨奖励估计和,然后添加一个置信度因子λ,当λ趋于0,就是TD,趋于1就是MC,一般用0.95。这种情况下,求和后是一个收敛的级数,一定是个合适的奖励值。
策略梯度 (Policy Gradient)
│
├── REINFORCE (Monte Carlo Policy Gradient)
│ └── 无 baseline → 高方差
│
├── REINFORCE with Baseline
│ ├── Baseline = 常数 → 降一点方差
│ └── Baseline = V_w(s) → 显著降方差,但仍需 MC 更新 V_w
│
└── Actor-Critic Methods
├── A2C (Advantage Actor-Critic)
│ └── 用 TD error δ_t 作为优势 → 单步更新,低方差
│
└── A3C / PPO / TRPO 等
└── 使用 GAE 作为优势估计 → 平衡偏差与方差再总而言之,
所有基于策略梯度的方法(REINFORCE, Actor-Critic, PPO, TRPO, SAC...)都共享同一个数学本质:
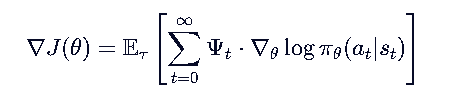

不同的算法,区别仅在于 的定义方式!
| 方法 | 特点 | 偏差/方差 | 是否需回合结束 | |
|---|---|---|---|---|
| REINFORCE (MC) | 蒙特卡洛,无偏但高方差 | 高方差,无偏 | 需要 | |
| MC with Baseline | 减去基线降低方差 | 方差↓,仍无偏 | 需要 | |
| Advantage Function | 理论最优,但 Q 难估计 | 理论上最佳 | 不一定 | |
| TD Residual (1-step AC) | 单步,低方差 | 有偏,方差极低 | 不需要 | |
| ✅ GAE (Generalized Advantage Estimation) | 多步 TD 误差加权平均,平衡偏差与方差 | 偏差-方差trade-off最优 | 不需要 |
REINFORCE (MC)
MC with Baseline
Advantage Function
TD Residual (1-step AC)
GAE
这一族统称为策略模型
你可以认为这已经非常完美了,我们已经找到一个让更新又稳又准还很快的方法,但实际上还差得远!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)