深度学习Softmax激活函数详解
深度学习Softmax激活函数详解
摘要:Softmax(归一化指数函数)是深度学习多分类任务的核心激活函数,没有之一。它的核心作用很简单:把神经网络输出的无界原始分数(logits),转化为和为1的概率分布,让我们能直观看到样本属于每个类别的概率。本文避开复杂数学推导,只讲清Softmax基本原理,重点分享实战代码、避坑技巧和选型方法,全程新手友好,看完就能套用在自己的模型中。
关键词:Softmax;激活函数;深度学习;多分类;实战代码
一、开篇直击:为什么多分类离不开Softmax?
做深度学习分类任务,大家肯定会遇到一个问题:神经网络最后一层输出的数值,可能是正数、负数,也可能是很大或很小的数,根本没法直接理解。
比如做手写数字识别(0-9共10个类别),模型输出可能是[3.2, -1.5, 2.1, 0.8, -0.3, 5.6, 1.2, 0.5, -2.1, 4.3],这些数字到底代表什么?哪个类别概率最高?
这就是Softmax的作用——它能把这组“杂乱无章”的原始分数(行业内叫logits),统一转换成(0,1)区间的概率,而且所有概率加起来等于1。上面的输出经过Softmax处理后,会变成类似[0.03, 0.002, 0.02, 0.01, 0.008, 0.75, 0.015, 0.009, 0.001, 0.15]的结果,我们能一眼看出:数字6的概率最高(75%),其次是数字9(15%),模型判断就很直观了。
总结一句话:二分类用Sigmoid,多分类用Softmax,Softmax是多分类模型输出层的“标配”,没有它,我们就无法解读模型的分类结果。
二、通俗理解:Softmax到底在做什么?
很多新手一听到“激活函数”“归一化”就头疼,其实Softmax的逻辑特别简单,就3步,用生活化的例子就能看懂,完全不用怕。
类比场景:假设我们给3个类别“打分”(对应模型输出的logits),分数分别是[2, 1, -1],Softmax的处理过程如下:
-
第一步:“转正”并放大差距。用指数运算(e^x)把所有分数变成正数,同时拉大高分和低分的差距——原来的[2, 1, -1],会变成[7.389, 2.718, 0.368]。这里的核心是:指数运算能让大分数变得更大,小分数变得更小,强化类别间的差异,让模型的判断更“坚定”。
-
第二步:归一化求概率。把所有“转正放大”后的分数加起来(7.389+2.718+0.368=10.475),然后用每个分数除以这个总和,得到每个类别的概率——[7.389/10.475≈0.705, 2.718/10.475≈0.259, 0.368/10.475≈0.036]。
-
第三步:验证结果。所有概率加起来等于1(0.705+0.259+0.036=1.0),符合概率的基本常识,这样我们就能直接解读:样本属于第一个类别的概率是70.5%,第二个是25.9%,第三个是3.6%。
再简单点说:Softmax就是“把模型的打分,变成我们能看懂的概率”,不改变分数的相对顺序,只做“标准化”处理,让结果更易理解、更符合业务需求。
三、Softmax基本数学原理
不用记复杂推导,只需要掌握核心公式和2个关键特性,足够应对实战即可。
3.1 核心公式(仅此一个,记牢够用)
假设模型输出的原始分数(logits)是一个向量z = [z₁, z₂, …, zₖ],其中k是分类的类别数,那么第i个类别的概率P(i),用Softmax计算的公式如下:
Softmax(zi)=ezi∑j=1kezj\text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^k e^{z_j}}Softmax(zi)=∑j=1kezjezi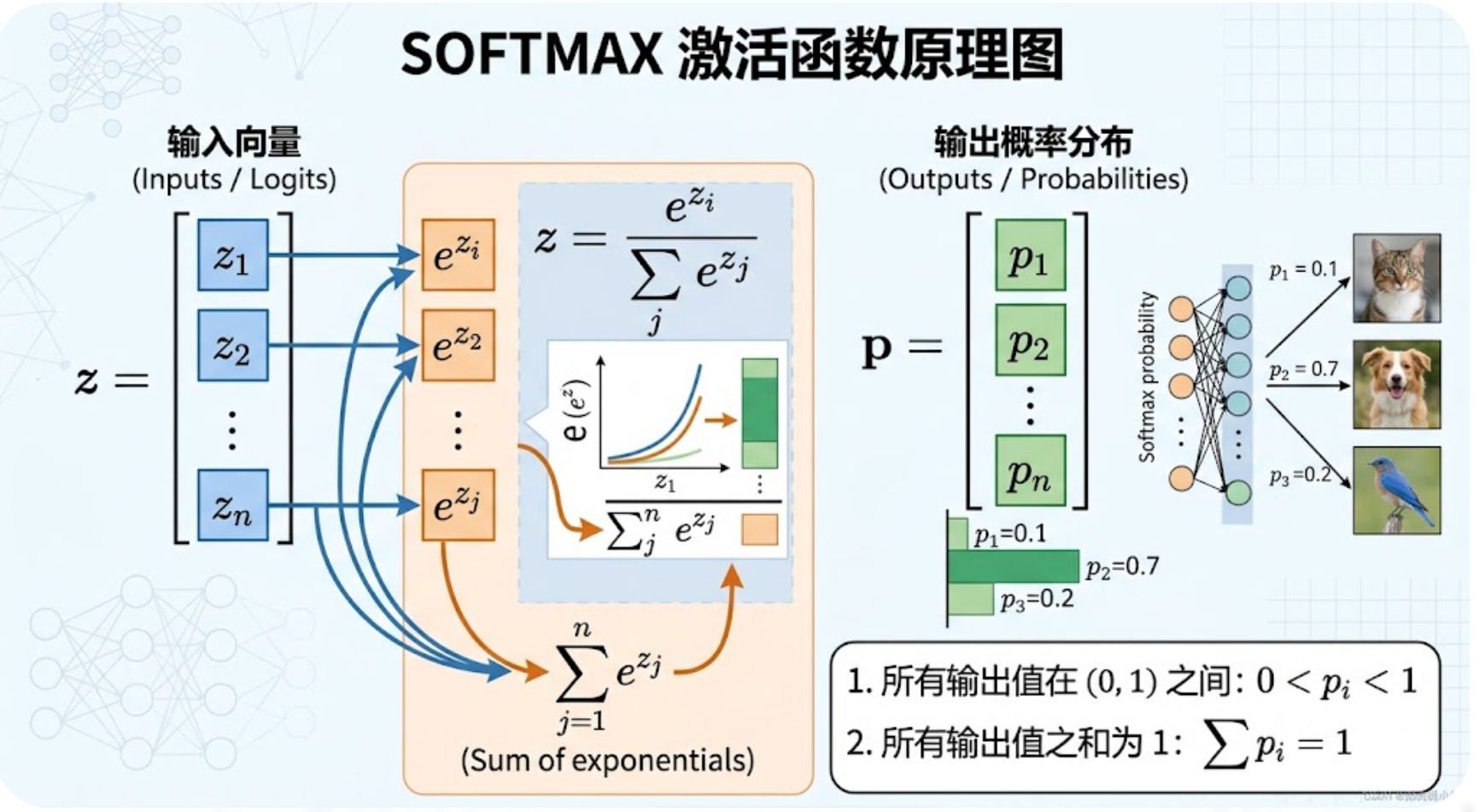
白话解释(不用懂推导):
-
分子e^zᵢ:就是我们刚才说的“指数运算”,作用是转正分数、放大差距;
-
分母∑e^zⱼ:所有类别指数分数的总和,作用是“归一化”,确保所有概率加起来等于1;
-
最终结果:每个类别对应的概率,范围在(0,1)之间,总和为1。
3.2 2个关键特性(了解即可,不用死记)
-
特性1:概率范围固定。每个类别的概率都在(0,1)之间,不会出现0或1的极端值,避免模型出现“绝对化判断”的偏见。
-
特性2:相对顺序不变。如果原始分数zᵢ > zⱼ,那么经过Softmax处理后,概率P(i) > P(j),不会改变模型对类别的判断倾向。
3.3 简单数值示例(直观验证)
已知logits向量z = [3, 1, 0, -2](4个类别),代入公式计算:
-
指数运算:e³≈20.086,e¹≈2.718,e⁰=1,e⁻²≈0.135;
-
求和归一化:总和≈20.086+2.718+1+0.135=23.939;
-
计算概率:[20.086/23.939≈0.839, 2.718/23.939≈0.114, 1/23.939≈0.042, 0.135/23.939≈0.006];
验证:所有概率之和≈1.0(微小误差源于四舍五入),完全符合预期。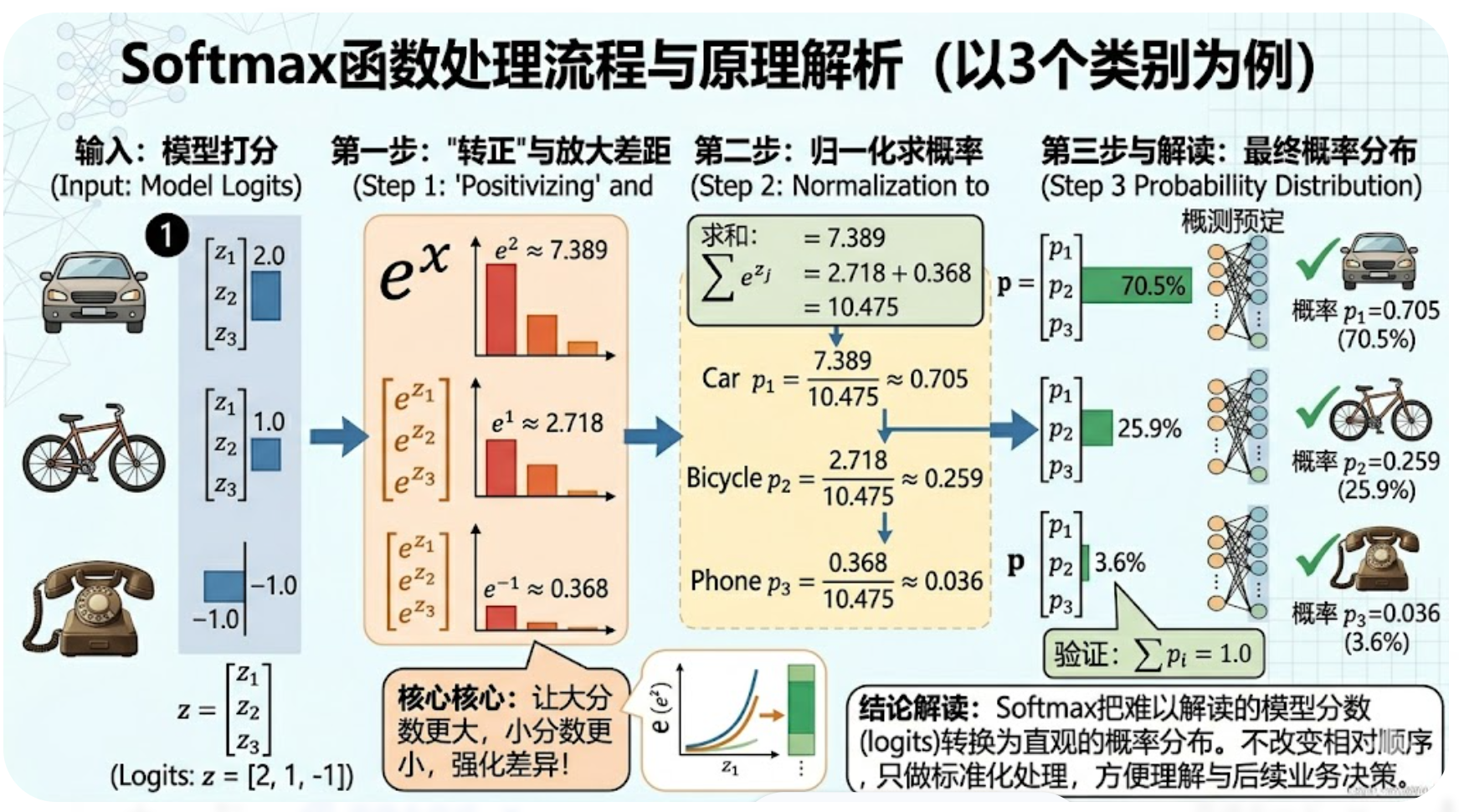
四、实战避坑:数值稳定
这是实战中最容易踩的坑!很多新手直接用上面的公式写代码,会发现模型训练时出现NaN(不是数字),导致训练失败,问题就出在“指数溢出”。
4.1 问题原因
当原始分数zᵢ很大时(比如1000),e1000会趋近于无穷大(上溢),导致分子分母都变成无穷大,计算结果为NaN;当zᵢ很小时(比如-1000),e-1000会趋近于0(下溢),同样会导致计算错误。
4.2 解决方案(直接用,不用懂原理)
最简单的优化方法:对所有原始分数z,减去z中的最大值,优化后的公式如下(已优化渲染,可直接复制):
Softmax(zi)=ezi−max(z)∑j=1kezj−max(z)\text{Softmax}(z_i) = \frac{e^{z_i - \max(z)}}{\sum_{j=1}^k e^{z_j - \max(z)}}Softmax(zi)=∑j=1kezj−max(z)ezi−max(z)
核心作用:减去最大值后,所有分数都会被映射到(-∞, 0]区间,此时e的最大值为1(e⁰=1),彻底避免指数溢出,而且不改变最终的概率结果。
补充:主流框架(PyTorch、TensorFlow)内置的Softmax函数,已经默认做了这个优化,我们直接调用即可,不用手动处理。
五、多框架实战代码
重点来了!以下代码覆盖NumPy(手动实现,理解底层)、PyTorch、TensorFlow,带详细注释,无需修改核心逻辑,复制就能运行,适合新手快速套用。
5.1 NumPy手动实现(数值稳定版)
import numpy as np
def softmax(z: np.ndarray) -> np.ndarray:
"""
数值稳定的Softmax手动实现(新手可直接复制)
:param z: 输入logits,shape=[N, K],N为样本数,K为类别数(单样本shape=[K,])
:return: 归一化后的概率分布,shape与输入一致
"""
# 核心优化:减去最大值,避免指数溢出(axis=-1表示对类别维度操作)
max_z = np.max(z, axis=-1, keepdims=True)
exp_z = np.exp(z - max_z)
# 归一化,确保所有概率和为1
sum_exp_z = np.sum(exp_z, axis=-1, keepdims=True)
prob = exp_z / sum_exp_z
return prob
# 测试代码(运行即可验证效果)
if __name__ == "__main__":
# 单样本测试(3个类别)
z_single = np.array([2, 1, -1])
prob_single = softmax(z_single)
print("单样本Softmax输出:", prob_single)
print("概率和:", np.sum(prob_single)) # 验证和为1,输出约1.0
# 多样本测试(2个样本,4个类别)
z_multi = np.array([[3, 1, 0, -2], [2, -1, 5, 1]])
prob_multi = softmax(z_multi)
print("\n多样本Softmax输出:\n", prob_multi)
print("每行概率和:", np.sum(prob_multi, axis=-1)) # 每行和均为1
5.2 PyTorch实现(实战最常用)
PyTorch内置了数值稳定优化,直接调用F.softmax即可,无需手动处理溢出,重点注意“dim=-1”(对类别维度归一化)。
import torch
import torch.nn.functional as F
# 注意:输入必须是float类型,PyTorch不支持int类型计算
logits = torch.tensor([[2., 1., -1.], [3., 0., 2.]])
# 核心:dim=-1表示对最后一维(类别维度)做归一化,固定写法
prob = F.softmax(logits, dim=-1)
print("PyTorch Softmax输出:\n", prob)
print("每行概率和:", torch.sum(prob, dim=-1)) # 验证和为1
5.3 TensorFlow/Keras实现
用法与PyTorch类似,内置稳定优化,新手可直接套用,重点注意“axis=-1”参数。
import tensorflow as tf
# 输入logits(必须是float类型)
logits = tf.constant([[2., 1., -1.], [3., 0., 2.]])
# 核心:axis=-1指定类别维度,固定写法
prob = tf.nn.softmax(logits, axis=-1)
print("TensorFlow Softmax输出:\n", prob.numpy()) # numpy()转为数组,便于查看
print("每行概率和:", tf.reduce_sum(prob, axis=-1).numpy())
5.4 实战拓展:Softmax结合简单神经网络(PyTorch,可直接运行)
新增一个“Softmax+简单神经网络”的完整样例,模拟多分类任务(3个类别),帮你快速理解Softmax在实际模型中的应用,新手可直接复制运行,直观看到Softmax的输出效果。
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 定义简单神经网络(输入层+隐藏层+输出层+Softmax)
class SimpleNet(nn.Module):
def __init__(self, input_dim, hidden_dim, num_classes):
super(SimpleNet, self).__init__()
# 隐藏层
self.fc1 = nn.Linear(input_dim, hidden_dim)
# 输出层(输出logits,后续用Softmax归一化)
self.fc2 = nn.Linear(hidden_dim, num_classes)
# 激活函数(隐藏层用ReLU,输出层后续用Softmax)
self.relu = nn.ReLU()
def forward(self, x):
# 前向传播:输入 -> 隐藏层 -> ReLU -> 输出层(logits)
out = self.fc1(x)
out = self.relu(out)
logits = self.fc2(out)
return logits
# 2. 初始化模型、损失函数、优化器
input_dim = 10 # 输入特征维度(模拟数据)
hidden_dim = 20 # 隐藏层神经元数量
num_classes = 3 # 多分类类别数(3个类别)
model = SimpleNet(input_dim, hidden_dim, num_classes)
# 损失函数:交叉熵损失(内置Softmax,无需手动添加)
criterion = nn.CrossEntropyLoss()
# 优化器:随机梯度下降
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 3. 模拟训练数据(10个样本,每个样本10维特征,标签为0/1/2)
x_train = torch.randn(10, input_dim) # 模拟输入特征
y_train = torch.tensor([0, 1, 2, 0, 1, 2, 0, 1, 2, 0]) # 模拟标签
# 4. 单轮训练(简化版,便于理解)
model.train() # 切换训练模式
optimizer.zero_grad() # 清空梯度
logits = model(x_train) # 模型输出logits
loss = criterion(logits, y_train) # 计算损失
loss.backward() # 反向传播求梯度
optimizer.step() # 更新模型参数
# 5. 用Softmax获取概率分布,查看分类结果
with torch.no_grad(): # 禁止梯度计算,节省资源
logits = model(x_train)
prob = nn.functional.softmax(logits, dim=-1) # 对logits做Softmax
# 打印前3个样本的概率和预测类别
for i in range(3):
print(f"样本{i+1}:")
print(f" Softmax概率分布: {prob[i].numpy().round(4)}")
print(f" 预测类别: {torch.argmax(prob[i]).item()}")
print(f" 真实类别: {y_train[i].item()}\n")

样例说明:该代码完整模拟了“神经网络+Softmax”的多分类流程,包含模型定义、训练、概率输出,注释详细,新手可直接运行,直观看到Softmax如何将模型输出的logits转为概率分布,以及如何通过概率判断预测类别。
六、Softmax vs Sigmoid(选型口诀,记牢不踩坑)
新手常混淆这两个激活函数,不用记复杂理论,看表格+口诀,就能快速选型,避免用错场景。
| 对比维度 | softmax | sigmoid |
|---|---|---|
| 适配任务 | 单标签多分类(样本仅属于一个类别) | 二分类、多标签分类(样本可属于多个类别) |
| 输出特点 | 所有概率和为1,类别间相互竞争 | 每个输出独立,概率和不一定为1 |
| 典型场景 | 手写数字识别、新闻分类、图像分类 | 垃圾邮件识别、多标签标注(如图片同时含猫和狗) |
| 选型口诀(记牢够用):单标签多分类用Softmax,二分类/多标签用Sigmoid。 |
七、Softmax常见应用场景(实战必知)
除了多分类输出层,Softmax还有两个高频应用场景,新手了解即可,后续实战中会经常遇到:
-
多分类模型输出层:这是最核心的应用,CNN、Transformer、MLP等模型做多分类时,输出层必用Softmax,配合交叉熵损失函数训练模型。
-
注意力机制:在Transformer、BERT等模型中,会用Softmax对注意力分数做归一化,得到和为1的权重分布,实现“关注重要信息、忽略无关信息”的效果。
-
置信度输出:业务场景中(如金融风险分类、疾病诊断),用Softmax输出的概率作为“置信度”,辅助业务决策(比如概率>0.8判定为高风险)。
-
生成模型采样:在生成式深度学习模型(如VAE、GAN、大语言模型)中,Softmax用于对模型输出的logits进行归一化,得到候选结果的概率分布,再基于该分布采样生成目标结果(如生成文本、图像特征),确保采样结果符合概率逻辑,提升生成内容的合理性。
八、Softmax优缺点
8.1 优点
-
概率可解释性强:输出直接是类别概率,不用额外处理,业务友好,便于理解和决策。
-
适配多分类:完美满足“概率和为1”的需求,是多分类输出层的标配,无可替代。
-
实战友好:主流框架内置实现,无需手动推导公式,直接调用即可,新手也能快速上手。
8.2 缺点(避坑重点)
-
存在溢出风险:必须做数值稳定优化(减去最大值),否则会导致模型训练崩溃。
-
不适配多标签:类别间相互竞争,无法处理样本属于多个类别的场景(比如一张图片同时有猫和狗)。
-
计算开销略高:相比ReLU等激活函数,多了指数运算和归一化,计算速度稍慢,但不影响常规实战。
九、总结
Softmax其实很简单,不用被“激活函数”“归一化”这些术语吓住,核心总结3点,记牢就能应对实战:
-
核心作用:把模型输出的无界logits,转化为和为1的概率分布,方便解读多分类结果。
-
核心公式:记住一个即可,实战中直接用框架内置函数,无需手动实现。
-
关键避坑:必须做数值稳定优化,新手直接调用PyTorch、TensorFlow的内置函数,就能避开溢出问题。
对于深度学习新手来说,掌握Softmax的基本原理和实战代码,就能轻松应对多分类任务,后续随着实战经验增加,再逐步深入理解其底层逻辑即可。
参考资料
-
PyTorch官方文档:torch.nn.functional.softmax 详细说明
-
TensorFlow官方文档:tf.nn.softmax 实现细节
-
深度学习实战:多分类模型中Softmax的应用技巧
如果本文对你有帮助,欢迎点赞、收藏、关注!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)