流模型和扩散模型
1.1 Generative Modeling As Sampling
前置知识:
计算机表示 图像、视频、蛋白质结构:
- 图像:宽 × 高 × 3彩色通道
- 视频: 图像 × 时间维度
- 蛋白质:N 个原子 × 原子的(x ,y , z)坐标
总结:生成的物体从数学上来看,各种数据都可以看成一组向量
并且这些数据都是连续的,流和扩散模型也主要用于生成连续数据,而不是文本这样离散数据。

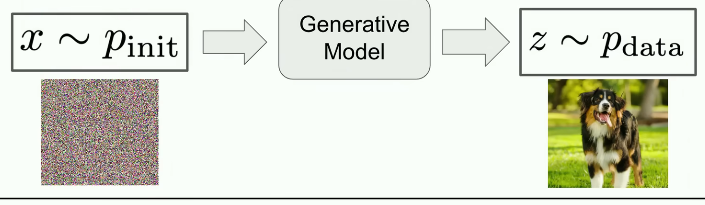
这节课的学习目的:如何把一堆毫无意义的“噪声点”,一步步变为一张清晰的狗的图片
生成模型的本质:完成一次概率分布的转换;从一个极其简单的“初始分布”出发,最终转换为包含真实数据的“数据分布”(比如网上能找到的狗的图片)
最终的“数据分布”(Pdata)是全局固定不变的,它在数学上代表了世界上”所有狗的照片“的整体集合,模型不是每次都完成从”初始分布“到”数据分布“这个过程,而是早就构造好了一条从“纯噪声世界”通往“狗的世界”的固定桥梁。
为什么每次生成的狗的图像不同?
答:1. 因为每次采样的”初始分布“不同,每次生成图像。系统都会从初始分布(Pinit)中抽取全新的提点,顺着”向量场“一步步移动时,你最终采样的点落在数据分布的不同位置
2.路径的”随机性“:扩散模型特有的"随机轨迹",如果使用扩散模型(基于随机微分方程 SDE),那么不仅起点是随机的,连你在中间走的每一步都包含随机。路径中不断包含“布朗运动“的随机噪声,这使得生成过程变成随机过程
模型学习的是这个转换规则,也就是”向量场“,然后就不再改变了
每次生成图片,只是在这团"初始分布"噪声点中随机采样粒子
判断一张图像生成的质量好坏,以它在数据分布下 Pdata 的可能性作为评判标准。
以概率论的方式评判
一张好的生成图片,相当于从目标数据分布中抽取出高概率的样本
在机器学习中,生成数据可以看作是从数据分布 Pdata 中采样,例如要生成狗的图片,数据分布中那些看起来像狗的图片就有更高的概率密度。而我们的训练数据集就是这个分布的有限个样本组成
通常情况下我们进行无条件生成,一个模型固定提示词,如dog,这意味着总是从这个模型获取狗的图像,外观可能有略微区别
另外有时候我们会希望在给定条件y下进行生成,这时候数据分布就是一个条件分布Pdata(⋅∣y) 。
给定条件y“dog”、“cat”,“snack”
普通数据分布(无条件的)数据分布 Pdata包含的是”各种杂七杂八的图片“
有条件数据分布 Pdata(⋅∣y) 相当于给集合加了一个过滤器。当条件设置为"dog"时,这个分布就精确缩减到了狗的整体集合
那么如何从数据分布中采样呢?我们的做法是先从一个简单的初始分布 (先验分布)
![]()
,例如标准正态分布
![]()
,中采样,然后将其转换为数据分布中的样本。而实现这一转换的方法就是模拟合适的微分方程,例如流模型 (Flow Models) 是模拟常微分方程 (ODEs, Ordinary Differential Equations),扩散模型 (Diffusion Models) 是模拟随机微分方程 (SDEs, Stochastic Differential Equations).
生成模型的本质就是将初始高斯分布,转换为数据分布
流匹配:为了解决扩散模型“慢且复杂”的痛点而提出的新一代数学框架与训练目标。
- 核心机制:流匹配选择直接学习一个向量场。它告诉空间中的每一个噪声粒子:“此时此刻,你应该以什么速度、朝哪个方向直线移动,能最快到达真实数据点”。
- 它与扩散模型的关系
-
- 流匹配是扩散模型的泛化与升级。
- 扩散模型的去噪路径充满随机性;而流匹配允许我们构建“直线路径”。从噪声点到数据点,两点之间直线最短。这使得流匹配的训练更简单,生成速度快的多
扩散模型:它强制规定一个“前向加噪”过程,把数据一点点变成噪声。然后训练神经网络去逆转这个过程,一步步“去噪”。它是实现“从噪声到数据”的一种具体框架
- 特点和痛点:它的优化路径高度随机,迭代步数多,才能保证不偏离轨道。这导致扩散模型虽然生成质量极高,但采样(生成)速度非常慢。
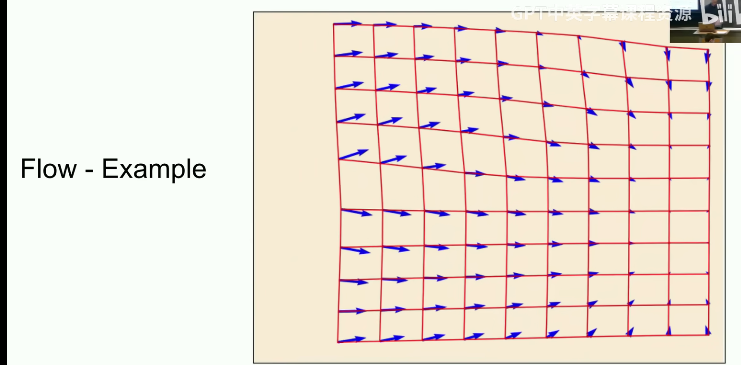
- 常微分方程(ODE):规定规则的“风场”
在生成模型的语境下,ODE本质上就是一个“速度指示牌”或“风场地图”。
想象一个二维平面,平面上的每一个点、在每一个时刻,都有一个特定的风速和风向。

ODE 的解,指的是粒子从 t = 0 开始,严格按照指示牌一步步走,最终在 t = 1时到达目标地的那一条完整路径(流 Flow)
1.2 Flow Models
流匹配是模拟常微分方程。先定义常微分方程:首先,定义轨迹
![]()
,它是时间到空间的映射,
![]()
表示时间t时映射对应的点
![]()
,然后定义向量场(Vector Field)
![]()
,
它的输入空间位置和时间,得到一个向量,
![]()
表示位置x在时间t时的“速度方向”。然后我们定义ODE:
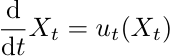
,它是描述轨迹Xt 如何随时间变化的微分方程,意思是轨迹在点Xt处的导数(速度)等于在该点上的向量场ut(Xt),可以发现,向量场确定了ODE,我们还需要设置一个初始条件
![]()
,表示t=0时的位置。
接下来我们可以定义流(Flow)
![]()
,它输入初始点x0和时间t,输出在时刻t的位置,
![]()
表示从位置 x0 出发,经过时间t后,在向量场u中走过的位置。显然
![]()
,并且
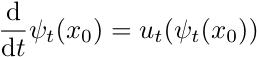
. 可以发现流本质上是遵循ODE的一系列轨迹的集合,而轨迹是ODE在某一初始条件下的一个解。换句话说,流是ODE的全体解,轨迹是ODE在某个初始条件下的特解。并且在u连续可微且导数有界 (这在机器学习中几乎总是成立) 时,ODE的解
![]()
存在且唯一。
我们通常无法直接计算得到ODE的解,因此我们需要模拟ODE,最简单的方法就是欧拉方法,由
![]()
更新x,具体算法如下:

有了以上定义和方法,我们考虑如何用机器学习实现。我们的目标是找到一个ODE使
![]()
转换为
![]()
,而ODE由向量场确定,因此我们就把向量场设为一个神经网络,将其参数化,则有
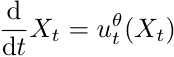
,初始条件 X0 从
![]()
中采样得到,这就是流模型 (Flow Model). 具体算法如下:

1.3 Diffusion Models
扩散模型是模拟随机微分方程,而SDE相比于ODE就是多了一个随机噪声使轨迹变为了随机过程,即
![]()
,这个随机噪声的 Wt 由布朗运动构造,并由超参数噪声系数 σt 进行缩放。可以发现当 σt 为0时这就是ODE. 和ODE一样,在u连续可微且导数有界时,SDE的解 (随机过程) 存在且唯一。
这里介绍一下布朗运动
![]()
。布朗运动是一个随机过程,并有
![]()
,他的轨迹 Wt 满足以下两个条件:1)正态增长,即,0 ≤ s < t ; 2)独立增长,即对于任意0 ≤ t0 < t1 < · · · < tn,有
![]()
是相互独立的随机变量。因此对于增量为h的布朗运动有
![]()
.
由于SDE中有随机项,因此我们希望公式中没有导数。我们可以使用这个公式来等价表示SDE:
![]()
,其中 Rt(h) 是当 h->0 时的无穷小项。
和ODE一样,我们也需要模拟SDE,可以使用欧拉-丸山法 (Euler-Maruyama Method),由
![]()
, 更新X,具体算法如下:

最后,有了以上定义和方法,我们可以用机器学习来实现。和ODE一样也是把向量场设为一个神经网络,初始条件 X0 从
![]()
中采样得到,随机噪声从标准正态分布中采样再乘以标准差和噪声系数得到,这就是扩散模型。具体算法如下:

1.4 Insight
流模型和扩散模型都要有一个向量场,再根据这个向量场逐步更新 X 以模拟ODE / SDE,最后将从初始分布
![]()
中采样得到数据转换为数据分布中的数据。不同的是,扩散模型在每一步都添加一项随机噪声,这使得它的随机性更强,且如果某一步生成的像素点不太对劲,后续的噪声注入和纠错机制能把它“拉”回正确的数据分布上,因此生成数据的多样性和质量更高,而流模型对于每个x0其最终结果都是固定的,效率更高。由于流匹配训练更稳定,流模型推理速度更快,因此现在先进的快速推理模型如Stable Diffusion 3采用的是ODE流匹配。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)