【Token】大局已定!告别 Token:140 万亿“词元”狂飙,AI 下半场的风暴才刚刚开始!
导语: 如果你以为最近 AI 圈只有“名字”的变化,还在一口一个 “拓肯”、 “令牌” 甚至 “代币” 地称呼那个神秘单位,那你可能要赶紧更新一下你的知识库了。
在刚刚结束的 中国发展高层论坛2026年年会上,国家数据局局长 刘烈宏的一场重磅演讲,不仅正式把 Token 命名为——“词元”,更直接揭开了中国智能经济的一张宏伟蓝图。这不只是一个名字的改变,更是 AI 时代“度量衡”的确立。从 “算电协同” 到底座重构,从破 10 万亿的产业规模到智能体的全面爆发……信息量巨大!建议先收藏,再细品。
👋 大家好,我是蜂蜜。
我是那个白天在比特世界里写着 Java 接口、跑着 Python 数据脚本、死磕 SQL 优化的底层“牛马”蜂蜜。世界变化太快,我正在努力跟上。
最近,AI 圈子里发生了一件大事。看起来只是一个名词的确定,但懂得人都懂,这标志着中国 AI 产业正在走向规范化和规模化。2026年3月23日,国家数据局官方盖戳,随后《人民日报》、央视新闻等官方媒体迅速跟进,广泛使用这一译名进行科普和报道。
这意味着,在中文语境下,Token 的争论结束了,“词元”正式上岗。
今天,我们拆解掉那些枯燥的术语,深度聊聊:这个看似简单的“词元”到底是什么?140 万亿的恐怖调用量背后,藏着怎样的大时代?中国 AI 下半场的底座、逻辑和新物种,到底长什么样?
🧐 一、“词元”(Token)到底是个啥?AI 时代的乐高积木
对于大多数不直接手撸大模型 API 的朋友来说,Token 一直是个“熟悉的陌生人”。你可能在 OpenAI 的计费页面见过它,但它到底长啥样?
为了让你秒懂,我们可以做一个形象的类比:它就像是 AI 的“乐高积木”。
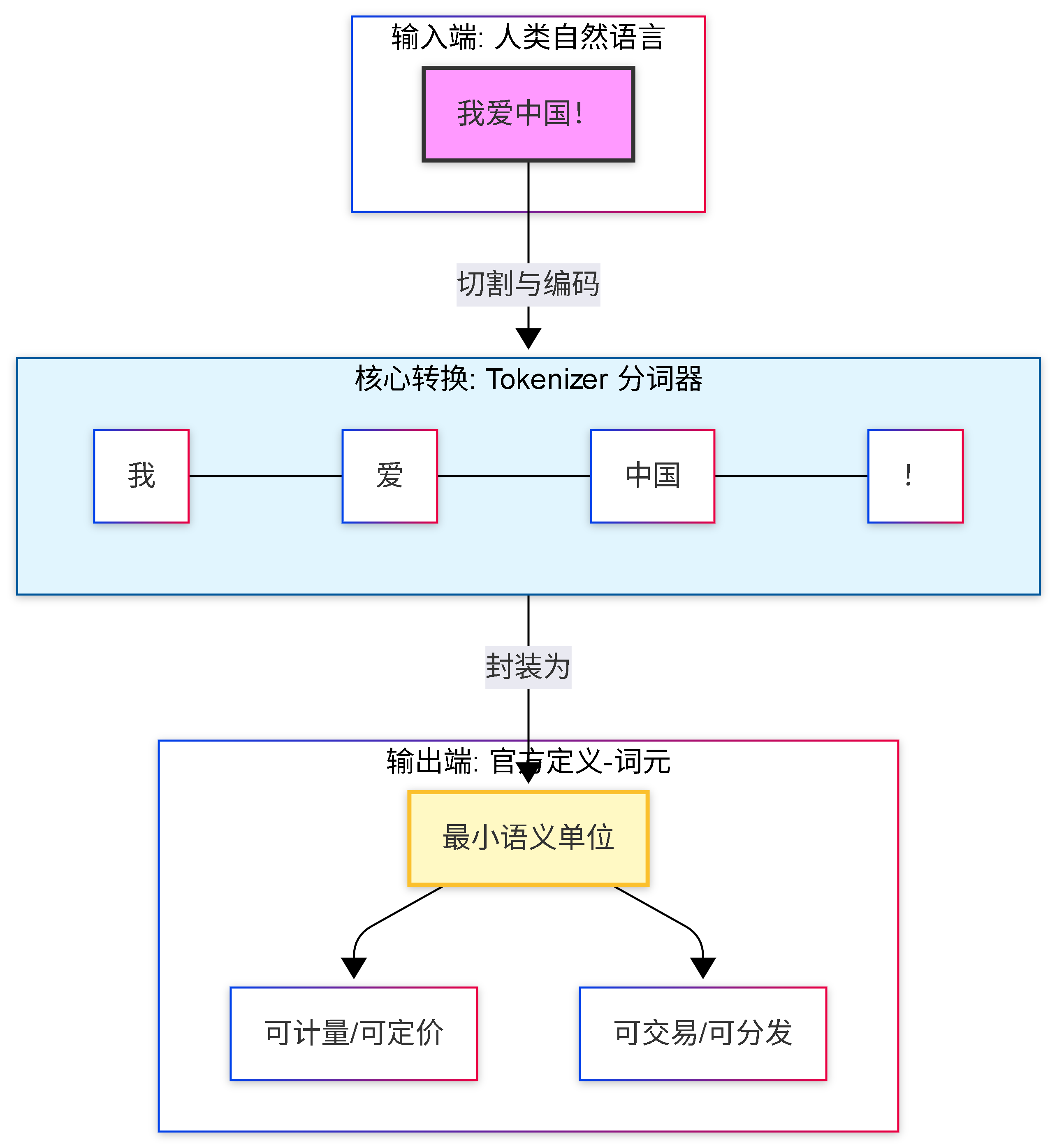
我们人类读一句话,是按字、按词、按句子来理解的。比如“我爱中国!”这句话,在我们的思维里是三个部分:“我”、“爱”、“中国”,加上一个标点。但对大模型(LLM)来说,它不直接“读”文字。它需要先把我们输入的文本,“切”成一个个它 能处理的、最小的、标准化的信息单位。这些被“切”出来的小块,就是词元(Token)。
在 LLM(大语言模型)的底层架构中,Token 是连接人类自然语言与机器向量空间的 ‘协议门票’。它不等于单纯的字数,而是经过 分词器(Tokenizer) 切割后的语义碎片
🧩 不是“字”,也不是严格的“词”
以前,有人把 Token 翻成“字”或者“词”,但这其实都不准确。
- 在英文里: 一个短单词(如
apple)可能是一个词元;但一个长单词(如unbelievable)可能会被拆分成多个词元(如un,believ,able)。 - 在中文里: 情况更复杂。由于中文没有空格,模型的分词器会根据算法,把句子切分成单字、双字词甚至多字短语。
还是上面那个例子:“我爱中国!” 大模型的分词器可能会把它切分成:我、爱、中国、! 这 4 个小块,就是 4 个词元。
小思考 🤔: 你写的一篇 1000 字的公众号文章,到了大模型那里,可能会变成 1500 到 2000 个“词元”。所以,如果你按“字数”来预估 AI 的消耗,那肯定是不准的。
🚫 “武林争霸”的结束:为什么叫“词元”?
过去两年,关于 Token 的中文翻译,除了早期的音译“拓肯”和带有误导性的“令牌/代币”,专家们还提议过“模元”(强调模型处理单位)和“智元”(强调通用智能单位)。
这些名字听起来都挺高级,但官方最终选择了 “词元”。这背后有深谋远虑:
- 直击本质: Tokenizer 在技术上本就是“分词器”,Token 是分词的结果。叫“词元”(词的元单位),最贴合技术本质,不花哨,够准确。
- 降低门槛: 苹果官网、OpenAI 中文文档等此前已经有类似用法,认知门槛最低,利于向公众科普。
📏 二、商业逻辑突变:为什么“词元”是智能时代的价值锚点?
互联网时代,我们衡量信息消耗用的是“流量”(MB/GB)。AI 时代,我们衡量大模型算力消耗、进行商业计费,基础单位就是“词元”! 就像你不能去菜市场买“一团”肉,你需要说“一斤”肉一样,你得按“词元”来给 AI 厂商付费。
刘局长在演讲中给出一组震撼全场的数据,直观地展示了我国 AI 应用的爆发速度:
2024 年初,中国日均词元调用量大约是 1000 亿; 到 2026 年 3 月,这个数字已经突破了 140 万亿!
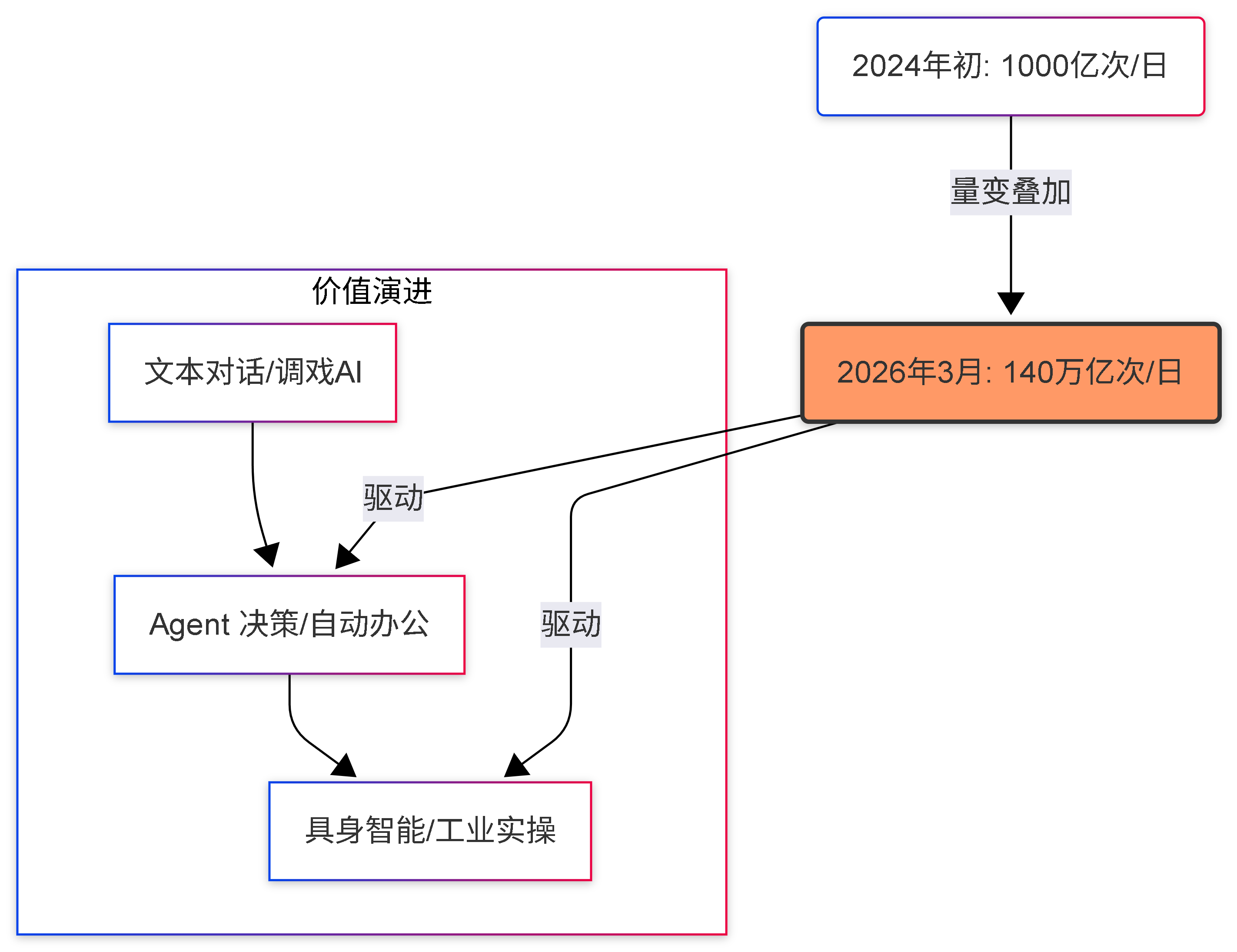
两年,增长了超过 1000 倍!🚀
这不仅仅是流量的激增,更是一套新型商业逻辑的诞生。
- 它是计费基础: 演讲中提到,有的模型企业创下了 20 天收入超越 2025 全年 的奇迹。靠的是什么?就是这 140 万亿次词元调用的分发与结算。
- 数据价值具象化: “词元”是可计量、可定价、可交易的。以前数据是“沉睡的金矿”,现在通过 AI 解析,庞大的非结构化数据变成了清晰的“数字商品”,变成了流动的“词元”。
⚡️ 三、算力底座:不只是“东数西算”,还要“算电协同”
140万亿个词元在每天被计算、被生成。我们每点一次 “提交”,每用一次智能助手,背后都是 GPU 的轰鸣和电力的消耗。现在的国家战略,直接把 “基建狂魔” 的属性加到了 AI 上。
1. 智算规模的“恐怖”增长
截至 2025 年底,中国智算总规模已经达到了 159 万 PFlops。更牛的是,国家布局的“八大枢纽”和“十大集群”承载了其中 80% 以上的算力。我们的算力不再是散兵游勇,而是正规军“集团化”作战。
2. 算力也要“绿”起来 🍀
演讲中提到了一个极具前瞻性的新词:“算电协同”。 简单说,就是把数字化技术与电力系统深度融合。以后,新建的枢纽节点算力设施,绿电应用占比要达到 80% 以上。这意味着,你在东部跑的一个复杂数据处理任务,调用的每一个“词元”,可能都是由西部大漠的风电或光伏驱动的。这不仅是技术的进步,更是“双碳”目标的硬核落地。
🦞 四、新物种的崛起:从“调戏对话”到“养龙虾”的进化
今年 AI 圈最火的是什么?演讲中点名了最近掀起热潮的开源框架 OpenClaw。这标志着 AI 正在经历范式跃迁。
1. 智能体(Agent)正式接管比赛
刘局长指出,大模型应用正从单纯的“对话”演进到了“决策执行”。 以 OpenClaw 为代表的智能体,不再是只会打嘴炮的聊天机器人。通过构建强大的 Agent Engine,配合灵活的 Gateway 和持续的 Memory,它们成了能自主规划任务、调用外部工具的“行动派”。
重点来了!官方定义的“好智能体”标准非常清醒:
它不应仅仅是炫技式的 “全能执行者”,更应是坦诚的风险告知者。在展示 “能做什么” 的同时,清晰界定 “有哪些风险” 并提供安全闭环。
在智能体爆发的当下,“最小权限、主动防御、持续审计”才是企业级落地的核心护城河。
2. RAG:打通数据与智能的核心王者
在千行百业的落地中,行业高质量数据集正在取代通用语料。这就不得不提 RAG(检索增强生成) 技术。它是让大模型真正拥有企业私域知识的“核心王者”。没有高质量的 RAG,再好的模型也只是个没有业务经验的实习生。
3. 具身智能:AI 也要“长身体”
AI 正在从数字模拟走向物理交互。刘局长提到,国家将推动高价值真机数据的采集,夯实具身智能的数据基础。以后,工业制造、仓储物流里的机器人,将拥有基于海量词元训练出来的“大脑”,真正实现感知、决策、执行的闭环。
💵 五、钱景与结语:拥抱 2.3 万亿的数据大产业
如果你觉得 AI 离钱很远,看这组预测:
- 2025 年,中国数据产业产值规模预计将超过 2.3 万亿元。
- 到“十五五”末,人工智能相关产业规模将突破 10 万亿元!
这已经不是小打小闹,而是一个完整的生态系统。在这个系统里,如果你能提供高质量、高知识密度、高鲜活度的数据集,那你就是 AI 时代的“顶级供应商”。
刘烈宏局长在演讲最后提到,2026 年的工作重点是:“数据价值释放年”。这意味着,我们要建立的是 “高质量数据集 + 算力网 + 安全治理方案” 的全栈体系,让技术真正扎进产业土壤。
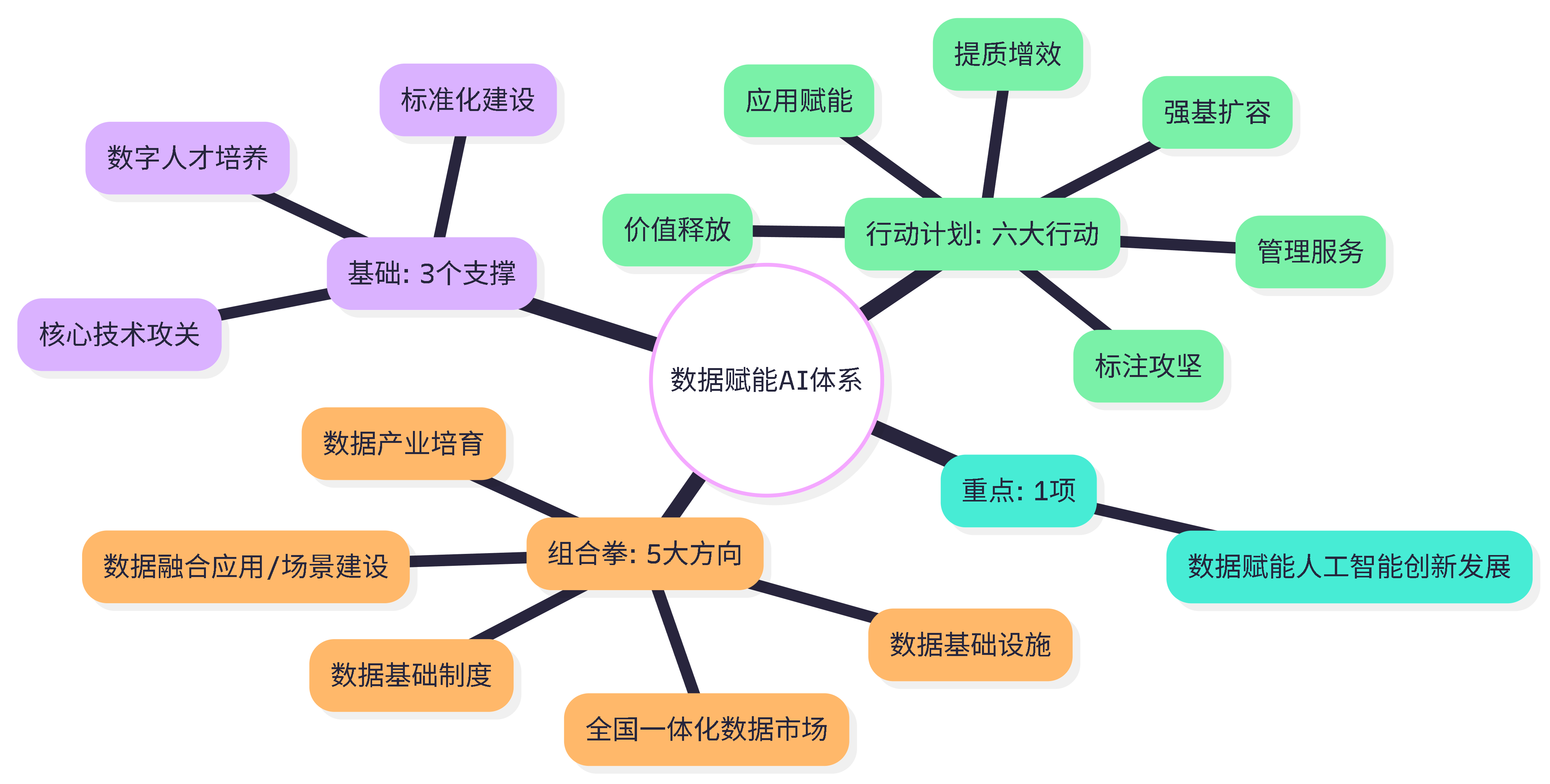
为了实现这一蓝图,官方其实已经划好了“施工图”,即 “5+3+1”工作体系:
这张图梳理了 国家数据局对 AI 赋能的全局规划,建议收藏备用
作为在这个“比特风暴”中努力敲代码的牛马,我们最重要的一件事就是:理解词元,拥抱智能。
当我们还在谈论“人工智能将如何改变未来”时,官方的种种举措已经宣告:未来已来,且已规范化。
下一次,当你看到 AI 生成了一段完美的文案,或者处理了一份复杂的表格,你可以优雅地在心里念一句:“嗯,这又消耗了好多词元。” 🐝
参考资料:
- 《深化数据赋能人工智能发展,加快培育智能经济新形态》——刘烈宏(2026.03.23)
- 《人民日报》相关科普报道
- 国家数据局官方发布
(END)
💬 互动一下: 看完这 140 万亿的震撼增长,你觉得下一个爆发的 AI 场景会在哪里?是帮你自动办公跑 SQL 的 Agent,还是工厂里干重活的具身机器人?欢迎在评论区留下你的思考!👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)