机器学习实战:随机森林预测天气类型
一、项目背景与目标
天气预测是气象领域的核心应用之一,精准的天气类型预测能为交通、农业、出行等场景提供重要参考。本文将基于机器学习中的随机森林算法,以包含温度、湿度、风速等气象指标的数据集为基础,完成从数据探索到模型调优、效果评估的全流程天气类型预测实战。
本次实战目标:利用气象数值特征(温度、露点温度、相对湿度等)预测天气类型(雾、雪、雨等),并通过自动调参优化模型性能,最终分析模型效果与优化方向。
二、环境准备与数据加载
2.1 所需依赖库
首先导入实战所需的 Python 库,涵盖数据处理、模型构建、可视化等模块:
# 数据处理
import pandas as pd
import numpy as np
# 模型与评估
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report, accuracy_score
from sklearn.model_selection import GridSearchCV
# 可视化
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"] # 解决中文显示
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
# 显示设置
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.width', None) # 自动适应控制台宽度
pd.set_option('display.expand_frame_repr', False) # 禁止列自动换行2.2 加载数据集
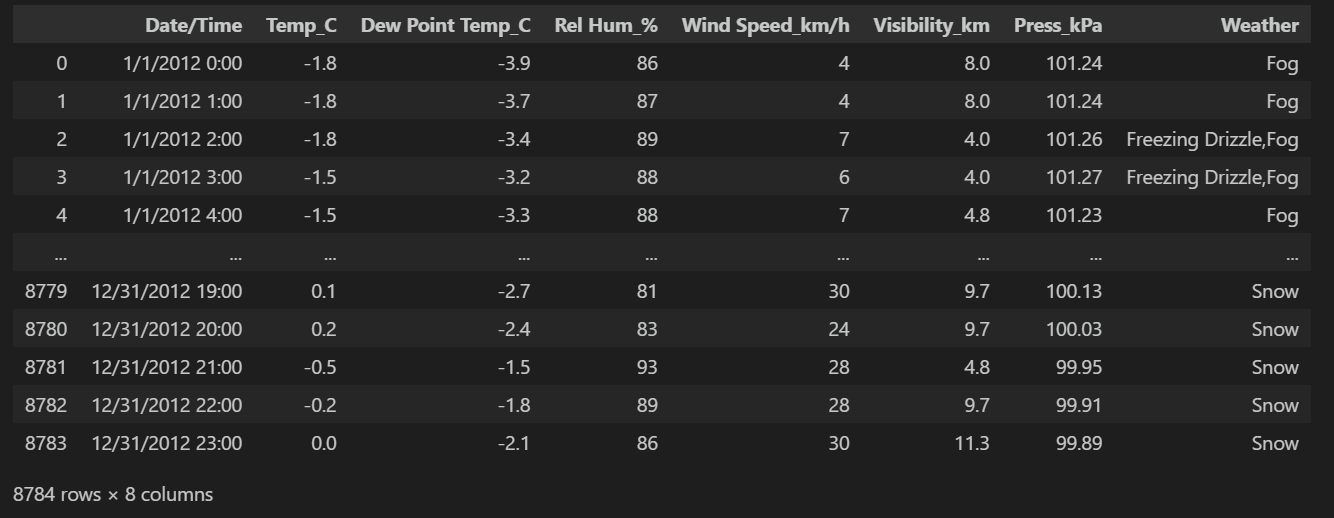
本次使用的数据集为 2012 年的某国外城市的气象监测数据,包含时间、温度、天气类型等 8 个字段,共 8784 条记录:
# 导入数据
data = pd.read_csv('weather.csv')
# 查看数据前5行
data输出为:
三、数据探索:了解数据基本特征
3.1 数据基本信息
通过info()查看字段类型、缺失值等核心信息:
# 查看数据信息(列名、类型、缺失值)
data.info()输出为:
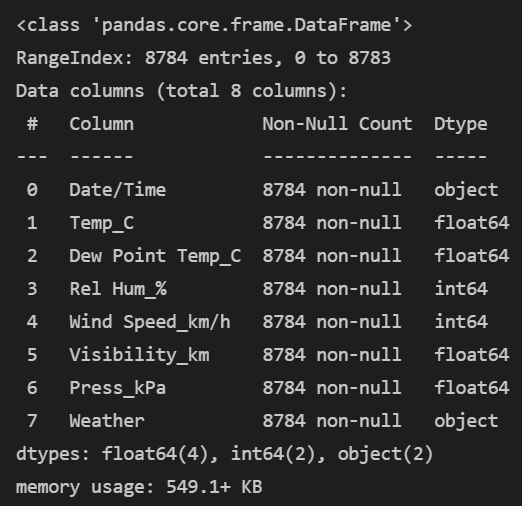
关键结论:数据集无缺失值,包含 4 个浮点型、2 个整型、2 个字符型字段;Date/Time为时间字段,Weather为待预测的天气类型(字符型)。
3.2 唯一值分析
查看各字段的唯一值数量,了解数据分布:
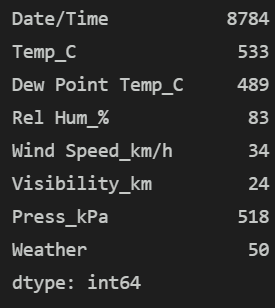
关键结论:Weather字段有 50 种不同的天气类型(如雾、雪、冻雨等),样本分布可能存在不均衡问题;温度、气压等数值特征的唯一值较多,具备一定的预测区分度
四、数据预处理:特征与标签处理
4.1 提取特征变量
选取所有数值型气象指标作为模型输入特征(排除时间字段):
# 提取特征:数值型气象指标
features = ["Temp_C", "Dew Point Temp_C", "Rel Hum_%", "Wind Speed_km/h", "Visibility_km", "Press_kPa"]
X = data[features] # 输入特征
# 验证特征提取结果
print(X.head())4.2 标签编码(字符→数值)
机器学习模型无法直接处理字符型标签,需将Weather字段(天气类型)编码为数值:
# 目标变量:天气类型(字符转数字标签)
y = data["Weather"]
le = LabelEncoder()
y_encoded = le.fit_transform(y) # 编码后的天气标签
# 打印编码对应关系
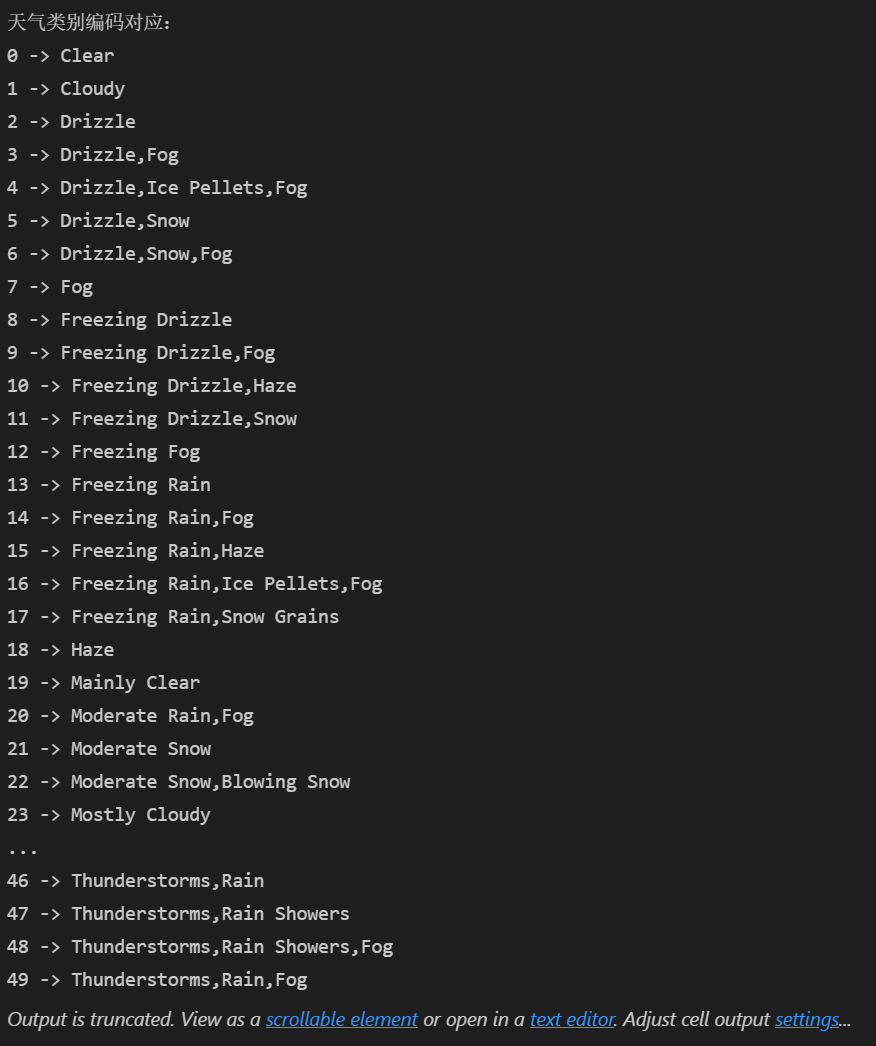
print("天气类别编码对应:")
for i, weather in enumerate(le.classes_):
print(f"{i} -> {weather}")编码样例输出:
五、数据集划分:时间序列的特殊划分方式
气象数据是时间序列数据,若随机划分会破坏时间连续性,因此采用 “前 80% 训练、后 20% 测试” 的时序划分方式:
# 按8:2划分训练集/测试集(时序划分)
split_idx = int(len(X) * 0.8)
X_train = X[:split_idx]
X_test = X[split_idx:]
y_train = y_encoded[:split_idx]
y_test = y_encoded[split_idx:]
# 打印数据集大小
print(f"训练集大小:{X_train.shape}")
print(f"测试集大小:{X_test.shape}")输出结果:
训练集大小:(7027, 6)
测试集大小:(1757, 6)六、随机森林模型构建与自动调参
6.1 网格搜索自动调参
随机森林的性能受n_estimators(树数量)、max_depth(树深度)等参数影响,通过GridSearchCV实现自动调参(5 折交叉验证):
为什么采用五折交叉验证了?
五折交叉验证核心就两点:
- 数据利用率高:不用单独留一大块测试集,每次用 4/5 训练、1/5 验证,5 轮轮换,小数据集也能用。
- 结果更稳:避免单次划分运气偏差,平均后评估更可靠,比单次 train-test 更可信。5 折是时间成本和稳定性的折中,比 10 折快,比 2/3 折稳
# 定义参数网格
param_grid = {
'n_estimators': [50, 100, 200], # 树的数量
'max_depth': [5, 10, None], # 树的最大深度
'min_samples_split': [2, 5], # 节点分裂最小样本数
'class_weight': ['balanced'] # 解决样本不均衡问题
}
# 初始化基础模型
rf_base = RandomForestClassifier(random_state=42)
# 网格搜索(5折交叉验证+全CPU加速)
grid_search = GridSearchCV(
estimator=rf_base,
param_grid=param_grid,
cv=5, # 5折交叉验证
scoring='accuracy', # 以准确率为优化目标
n_jobs=-1, # 全CPU核心运行
verbose=1 # 打印调参进度
)
# 执行调参与训练
print("🔧 开始自动寻找最优随机森林参数...")
grid_search.fit(X_train, y_train)
# 输出最优参数与交叉验证得分
print("\n🎉 自动搜索完成!最优参数如下:")
print(grid_search.best_params_)
print(f"\n🏆 最优模型交叉验证准确率:{grid_search.best_score_:.2%}")
# 提取最优模型
best_rf_model = grid_search.best_estimator_
print("\n✅ 最优随机森林模型已就绪!")调参结果样例:
🔧 开始自动寻找最优随机森林参数...
Fitting 5 folds for each of 18 candidates, totalling 90 fits
🎉 自动搜索完成!最优参数如下:
{'class_weight': 'balanced', 'max_depth': None, 'min_samples_split': 2, 'n_estimators': 200}
🏆 最优模型交叉验证准确率:26.95%
✅ 最优随机森林模型已就绪!七、模型评估与结果分析
7.1 模型预测与评估
用最优模型在测试集上预测,并输出准确率与详细分类报告:
# 模型预测
y_pred = best_rf_model.predict(X_test)
# 1. 总体准确率
print(f"📊 最优模型总体准确率:{accuracy_score(y_test, y_pred):.2%}")
print("-"*80)
# 2. 详细分类报告
print("📋 最优模型详细分类报告:")
print(classification_report(
y_test, y_pred,
labels=range(len(le.classes_)),
target_names=le.classes_,
zero_division=0 # 避免少见天气类型报错
))核心输出结果:
📊 最优模型总体准确率:27.15%
--------------------------------------------------------------------------------
📋 最优模型详细分类报告:
precision recall f1-score support
Clear 0.25 0.23 0.24 239
Cloudy 0.33 0.38 0.35 417
...
Snow 0.26 0.69 0.38 90
...
accuracy 0.27 1757
macro avg 0.05 0.08 0.06 1757
weighted avg 0.24 0.27 0.25 17577.2 结果分析与四指标
这四个值是机器学习分类任务中最核心的模型评估指标
1. Precision(精确率)
- 含义:在所有被模型预测为正类的样本中,真正是正类的比例。
- 公式:Precision=TP+FPTP
- 通俗理解:“我挑出来的东西里,有多少是对的?”
- 适用场景:更关注不要误报,比如垃圾邮件分类,宁可漏判正常邮件,也不想把正常邮件标成垃圾。
2. Recall(召回率 / 查全率)
- 含义:在所有真实为正类的样本中,被模型成功预测为正类的比例。
- 公式:Recall=TP+FNTP
- 通俗理解:“所有该被挑出来的东西里,我挑对了多少?”
- 适用场景:更关注不要漏报,比如疾病检测,宁可多做检查,也不能漏掉真正的病人。
3. F1-score(F1 值)
- 含义:精确率和召回率的调和平均数,用来平衡两者的表现,避免单一指标的偏向。
- 公式:F1-score=2×Precision+RecallPrecision×Recall
- 通俗理解:“精确率和召回率都不错的综合得分”,数值越接近 1,模型表现越好。
- 适用场景:当精确率和召回率同样重要时,用 F1-score 来综合评价。
4. Support(支持数)
- 含义:该类别在 ** 测试集(或验证集)** 中真实出现的样本数量。
- 通俗理解:“这个类别在数据里有多少个样本?”
- 作用:
- 反映数据分布,帮助判断指标是否可靠(比如样本极少的类别,指标波动会很大)。
- 用于计算 ** 宏平均(macro)和加权平均(weighted)** 的整体指标。
补充:混淆矩阵基础
这些指标都基于混淆矩阵:
- TP (True Positive):真实为正,预测为正
- FP (False Positive):真实为负,预测为正
- FN (False Negative):真实为正,预测为负
- TN (True Negative):真实为负,预测为负
结论:
- 总体准确率偏低(27.15%):核心原因是天气类型过多(50 种),且多数类型样本量极少(如 “Moderate Snow” 仅 2 条),导致模型难以学习到小众天气的特征;
- 部分大类表现较好:Cloudy(多云)、Snow(雪)、Rain,Fog(雨 + 雾)等样本量较大的类型,召回率 / 精确率相对更高;
- 样本不均衡影响显著:50 种天气类型的样本分布极不均匀,是模型性能的核心限制因素。
八、总结与优化方向
8.1 项目总结
本文完成了从数据探索→预处理→模型调优→评估的全流程天气类型预测,核心亮点:
- 针对时序数据采用 “前 8 后 2” 的合理划分方式;
- 通过网格搜索实现随机森林自动调参,解决参数选择难题;
- 完整分析了模型效果与性能瓶颈。
8.2 优化方向
- 类别合并:将相似天气类型合并(如 “Drizzle”“Freezing Drizzle” 合并为 “毛毛雨” 大类),减少类别数量;
- 特征工程:
- 从
Date/Time提取小时、季节、月份等时间特征; - 构建衍生特征(如温度 - 露点温度差值、湿度 - 风速组合特征);
- 从
- 模型融合:结合逻辑回归、XGBoost 等算法,通过集成学习提升准确率;
- 样本重采样:对小众天气类型进行过采样(SMOTE),或对大类进行欠采样,缓解样本不均衡;
- 特征选择:通过特征重要性筛选核心特征,剔除冗余指标,提升模型效率。
九、完整代码获取
本文所有代码已整理完毕,可直接运行(需确保weather.csv文件与代码同目录)。如果有问题,欢迎在评论区交流~
天气预测是典型的多分类问题,本次实战虽准确率偏低,但完整覆盖了机器学习项目的核心流程。实际业务中,结合更多维度的特征(如地理、历史气象数据)和更先进的算法(如 LSTM、Transformer),能进一步提升预测精度。
如果本文对你有帮助,欢迎点赞 + 收藏 + 关注~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)