Qwen3.5-Omni这波更新有点意思:215个SOTA + 自己学会写代码?
没专门训,它自己就学会了Vibe Coding
通义实验室刚刚放出了 Qwen3.5-Omni。
老实说,Omni这个系列之前我关注得不算多,但这次看完技术卡和demo,有几个点确实让我愣了一下。
先说结论
这是一个真正的全模态模型——文本、图像、音频、视频,任意组合输入,它都能处理。
而且它不是那种“为了全模态牺牲单项能力”的妥协方案。
215项SOTA,在音频、音视频理解、推理、翻译这些任务上,直接压过了Gemini 3.1 Pro。同时文本和视觉能力没掉,和同尺寸的Qwen3.5单模态模型持平。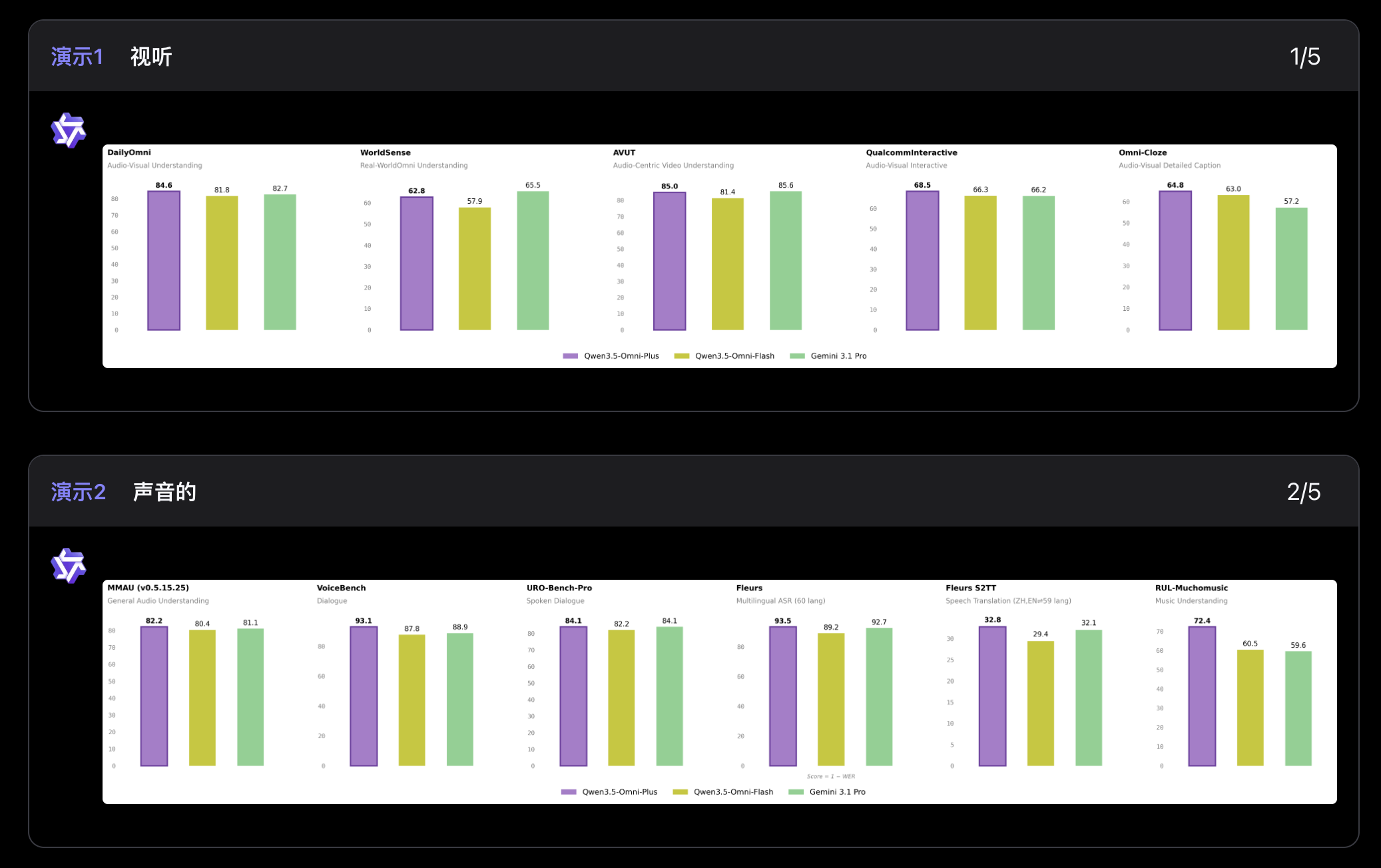
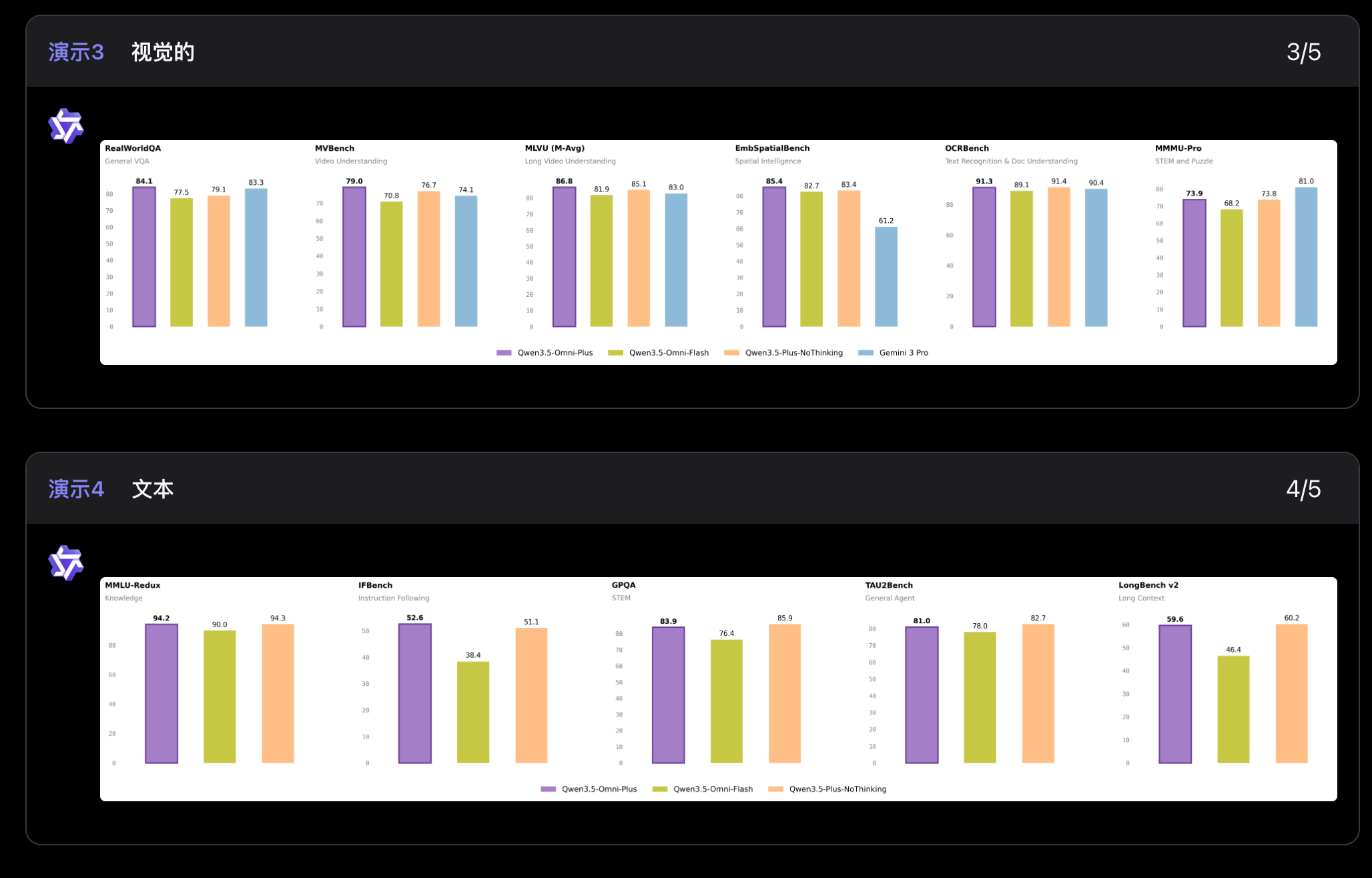
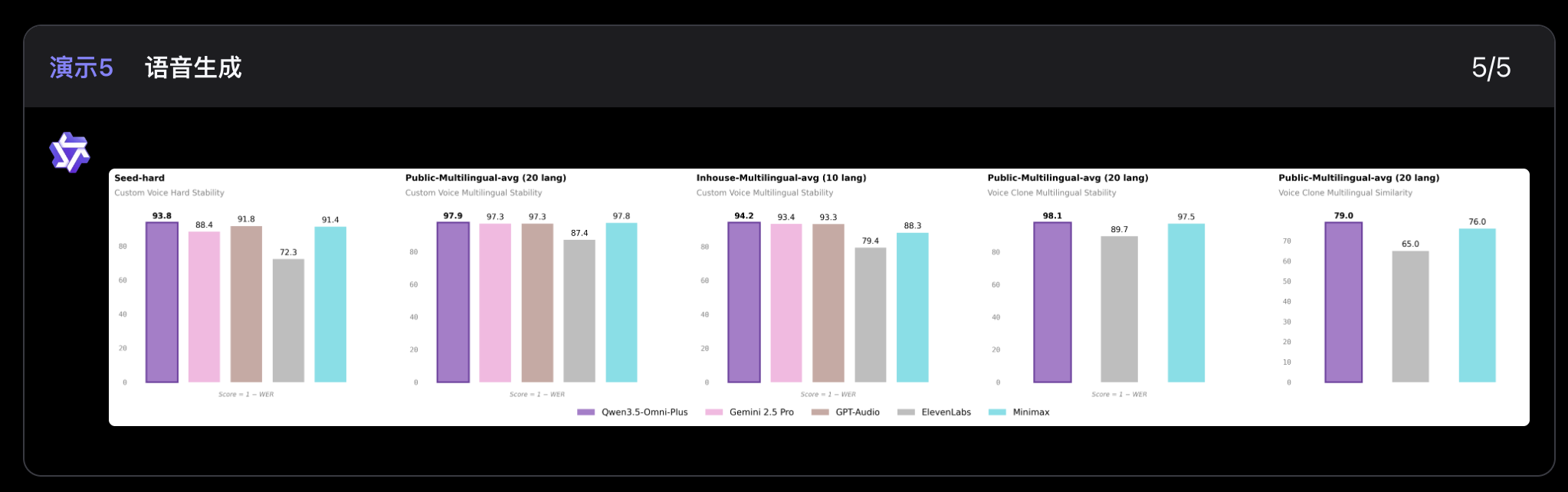
MoE专家混合架构在这里起的作用很明显:听音频的专家、看视频的专家、理解文本的专家各干各的,不互相干扰。
核心亮点
- 真正的“全模态”原生,无缝理解文本、图片、音频及音视频输入,支持细粒度、带时间戳的音视频 Caption 生成;
- 215 项 SOTA霸榜,在音频及音视频分析、推理、对话、翻译等任务超过Gemini3.1-Pro;
- 自然涌现的 Audio-Visual Vibe Coding 能力;
- 支持语义打断、音色克隆及语音控制,让对话体验更自然;
- 支持 256K 超长上下文与 113 种语言识别,可处理 10小时音频或 1 小时视频。
- 原生支持 WebSearch 和复杂 Function Call,不仅能聊天,更能帮你做事。
最让我意外的一个能力:Vibe Coding
这个是真没预料到。
官方说法是:未进行专门训练,模型自然涌现出了Audio-Visual Vibe Coding能力。
翻译成人话就是——你给它一个画面逻辑,它能直接生成可运行的Python代码或前端原型。
我没法确认这到底是“涌现”还是某种迁移学习的副产品,但从demo来看,它能根据视频内容生成对应的代码实现,这个能力在Omni模型里确实少见。
意味着什么?
从“看懂”到“做出”,中间那层工程翻译工作,模型帮你省了。
模型架构
Qwen3.5-Omni 延续采用 Thinker-Talker 架构,Thinker 通过 Vision Encoder 和 AuT 接受视觉和音频信号输入,音视频信号通过 interleave 交织并搭配 TMRoPE 编码位置信息。
Thinker 负责处理全模态信号并输出文本,Talker 负责接收来自 Thinker 的多模态输入以及文本输出,进行 contextual 语音生成,语音表征通过 Qwen3-Omni 提出的 RVQ 编码来替代繁重的 DiT 运算。
由于 chunk-wise 的流式输入设计和流式 Talker 设计,整个模型可以进行 realtime interaction。
不同于上一代 Qwen3-Omni 的双轨 Talker 输入,Talker 在输入的组织方式上采用了 ARIA(自适应速率交错对齐,Adaptive Rate Interleave Alignment)来动态对齐文本与语音单元,然后进行交错排布,以避免由于文本与语音 Token 编码效率差异导致的语音不稳定性,如漏读、误读或数字发音模糊等问题。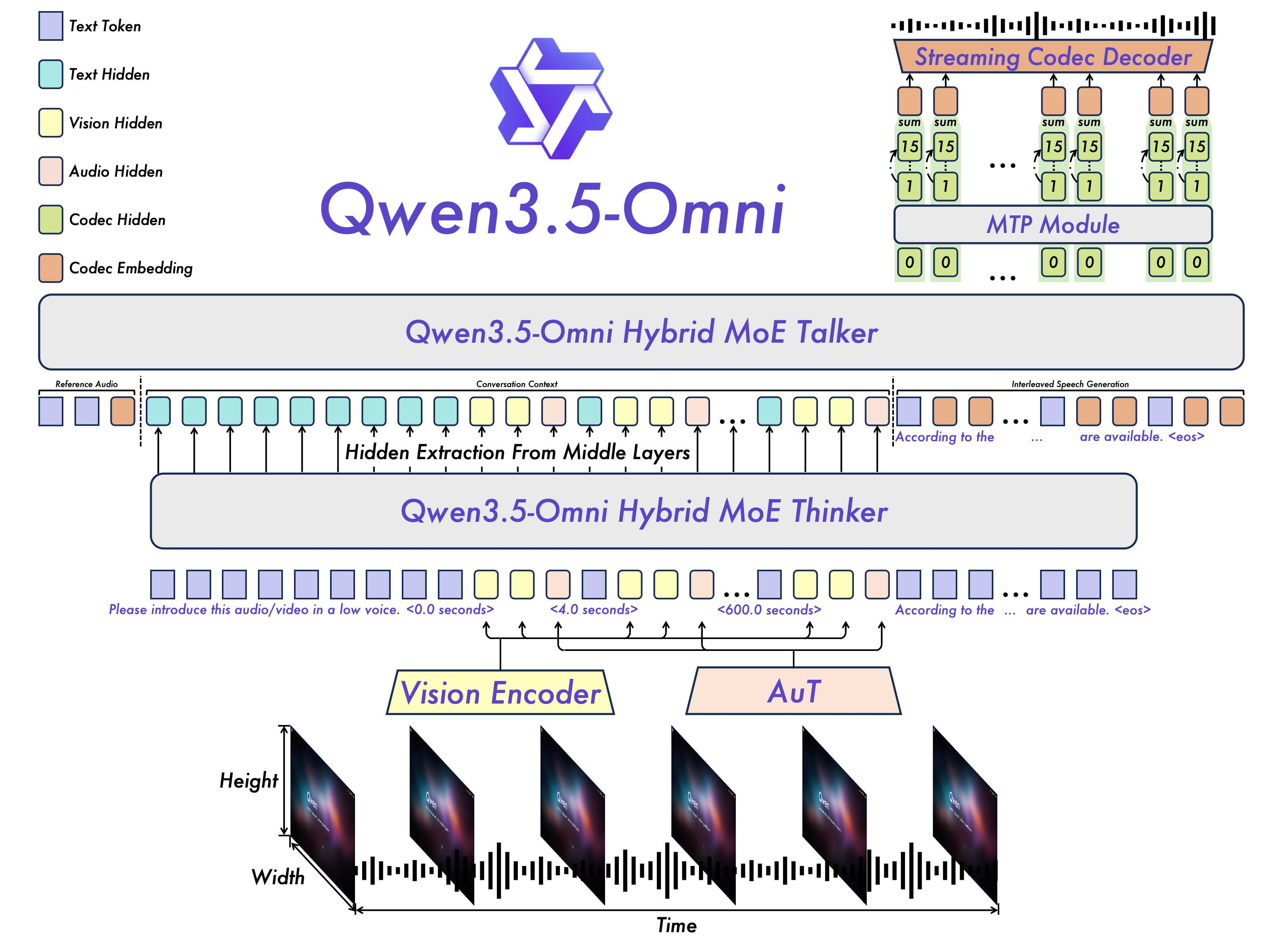
实时交互的细节,这次终于像人了
之前很多号称“实时”的多模态模型,交互体验其实挺反人类的——你咳嗽一下它就打断,你插句话它反应不过来。
Qwen3.5-Omni在这一点上处理得比较细致:
- 语义打断:区分环境噪音和真正的插话,该停的时候停,不该停的时候不理你
- 语音控制:直接说“小声点”、“用开心的语气”,它当场就调
- 音色克隆:上传一段录音,定制自己的AI助手声音,自然度还不错
再加上ARIA技术做了文本和语音单元的动态对齐,之前那种漏字、数字念不清的问题改善了不少。
长上下文,10小时音频
256K上下文,具体来说能处理:
- 约10小时音频
- 1小时视频
而且支持带时间戳的细粒度Caption——画面里是谁、说了什么、背景音乐什么时候变的、镜头怎么切的,都能输出结构化的描述。
这个能力对视频剪辑、内容审核、长视频转结构化笔记这些场景,落地价值比较直接。
能干活,不只是聊天
原生支持WebSearch和Function Call。
问它“明天北京天气如何,推荐一家酒店”,它能自主判断要联网查天气,然后调用工具完成任务,最后给出整合后的建议。
这个能力本身不算新鲜,但放在一个全模态模型里,意味着它可以处理更复杂的多模态输入→执行任务的链条。
版本和怎么用
三个尺寸:
- Plus:完整能力
- Flash:轻量,低延迟
- Light:更小,适合终端部署
阿里云百炼可以直接调API,魔搭有离线和实时Demo可以玩。
API文档:https://help.aliyun.com/zh/model-studio/realtime
魔搭实时Demo:https://modelscope.cn/studios/Qwen/Qwen3.5-Omni-Online-Demo
最后
多模态模型这两年卷得厉害,但大多数还是在做“理解”这一层。
Qwen3.5-Omni让我觉得有点不同的是:它在往“执行”的方向走。
Vibe Coding也好,语义打断也好,音色克隆也好,本质都是在让模型从“你说我听”变成“我看到、听到、然后帮你做”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)