AI Coding Agent-基于claude code与云原生技术搭建的企业端到端代码交付平台
从需求到上线:我们是如何用 AI Agent 打通端到端代码交付流水线的
前言
软件交付是一件既繁琐又高度依赖经验的事情。一个需求从产品文档变成线上功能,中间要经历需求理解、代码分析、方案拆解、代码修改、提交推送、环境部署、回归验证……每一步都需要开发者的持续介入。
我们团队在过去一年里做了一件事:把这条链路里大量的"机械性思考"交给 AI Agent 来完成,让开发者只需要在关键节点做决策,其余的交给系统自动推进。
本文记录的是这套系统的设计思路、核心实现和踩过的坑。
ps: claude code 牛逼
这里贴一下效果图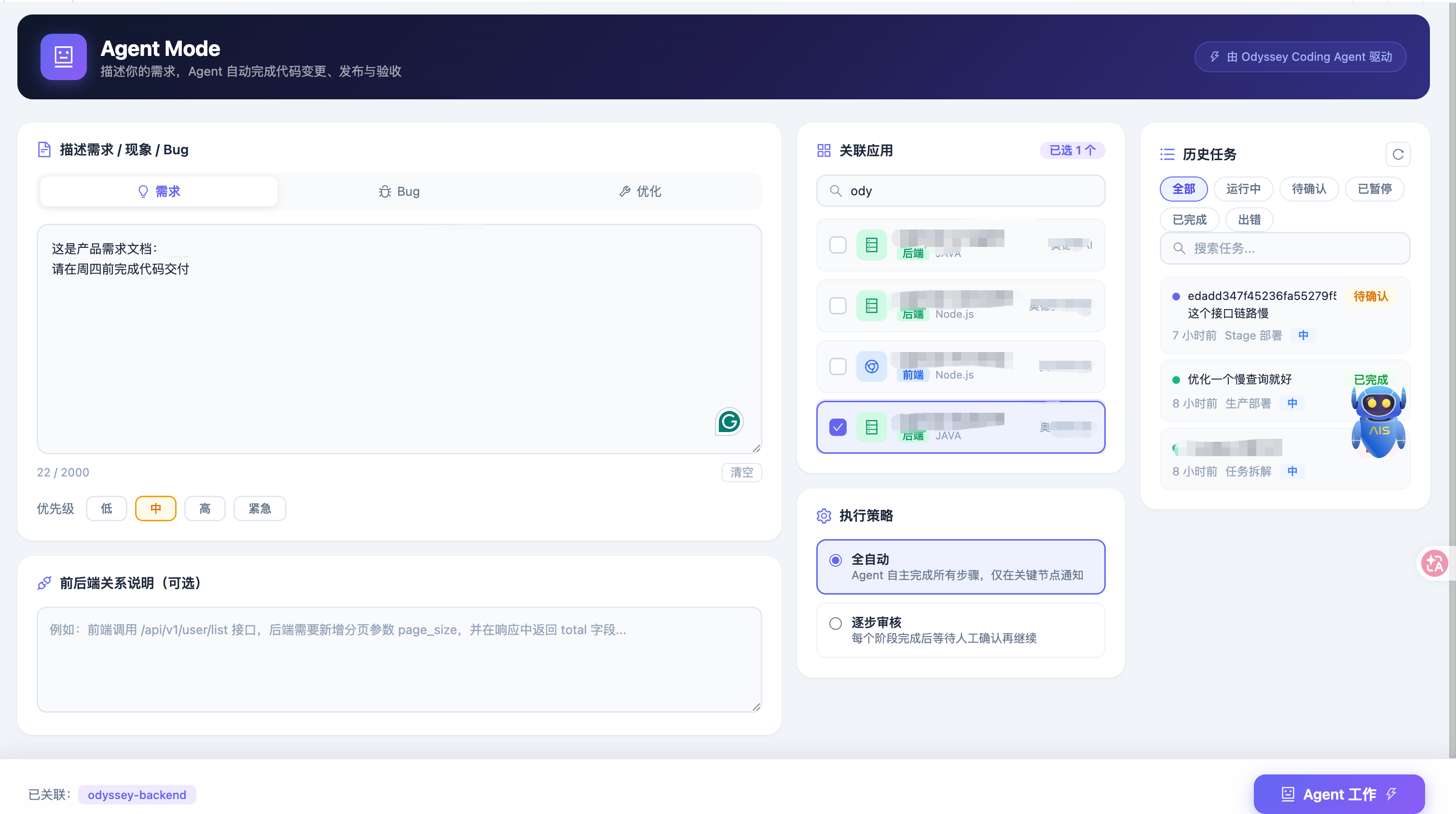

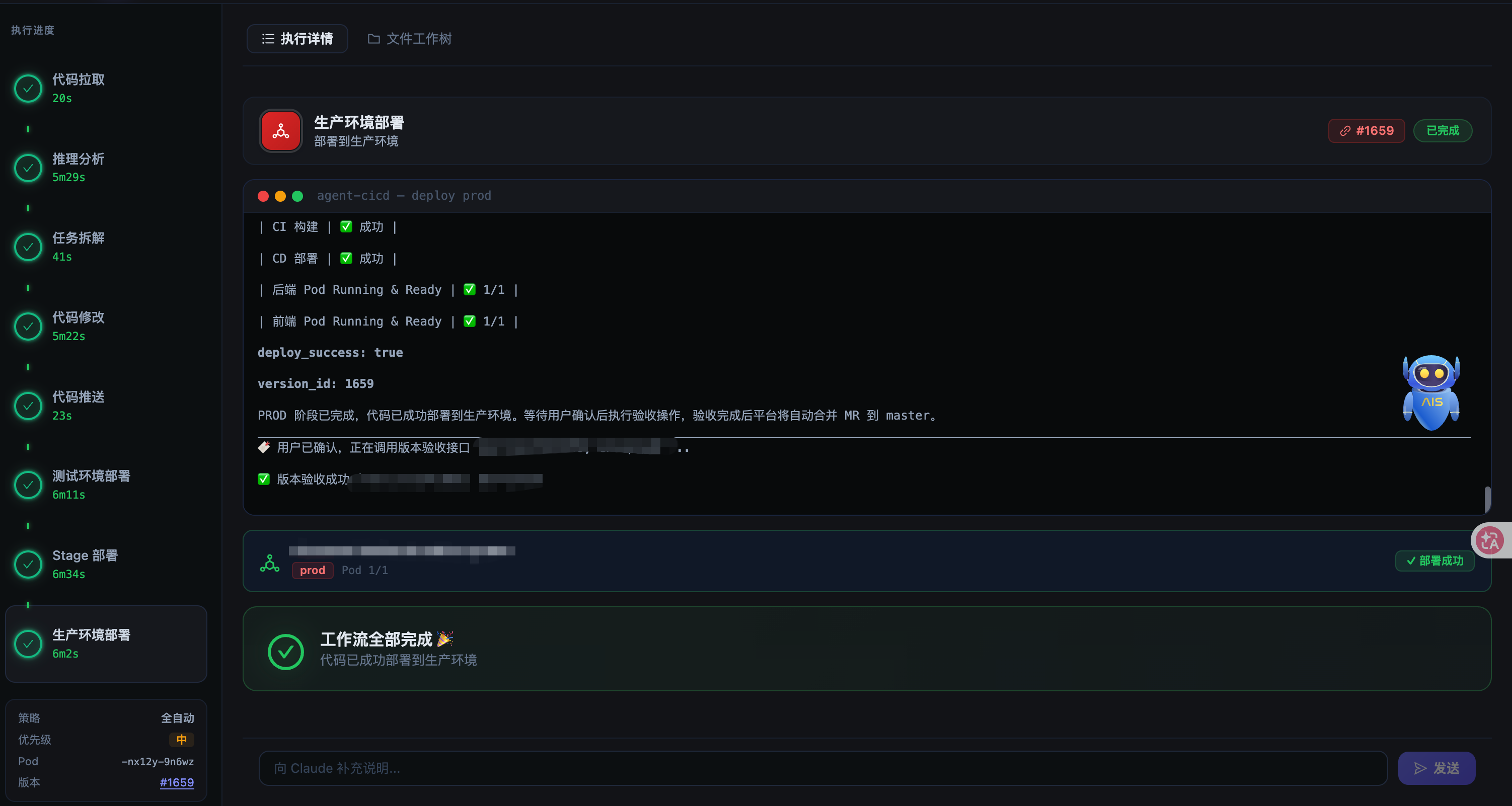
一、为什么要做这件事
先说背景。我们的业务迭代速度很快,每周都有多个需求并行开发。在这种节奏下,有几个痛点反复出现:
痛点一:重复性工作占用大量精力。 每次发布,开发者都要手动创建 MR、等待 CICD、查看构建日志、确认 Pod 状态、调用验收接口。这些操作本身没有技术含量,但每次都要花 20-40 分钟。
痛点二:上下文切换成本高。 开发者在写代码时被打断去处理发布,回来后需要重新拾起思路。一天里这样的打断发生三四次,实际的深度工作时间所剩无几。
痛点三:人工操作容易出错。 发布到 stage 忘记验收、prod 部署后没有确认 Pod 状态、MR 合并到了错误的分支……这类低级错误在高频发布中时有发生。
我们最初的想法很简单:能不能让 AI 来做这些事?
二、整体架构设计
经过几轮讨论,我们把系统分成三层:
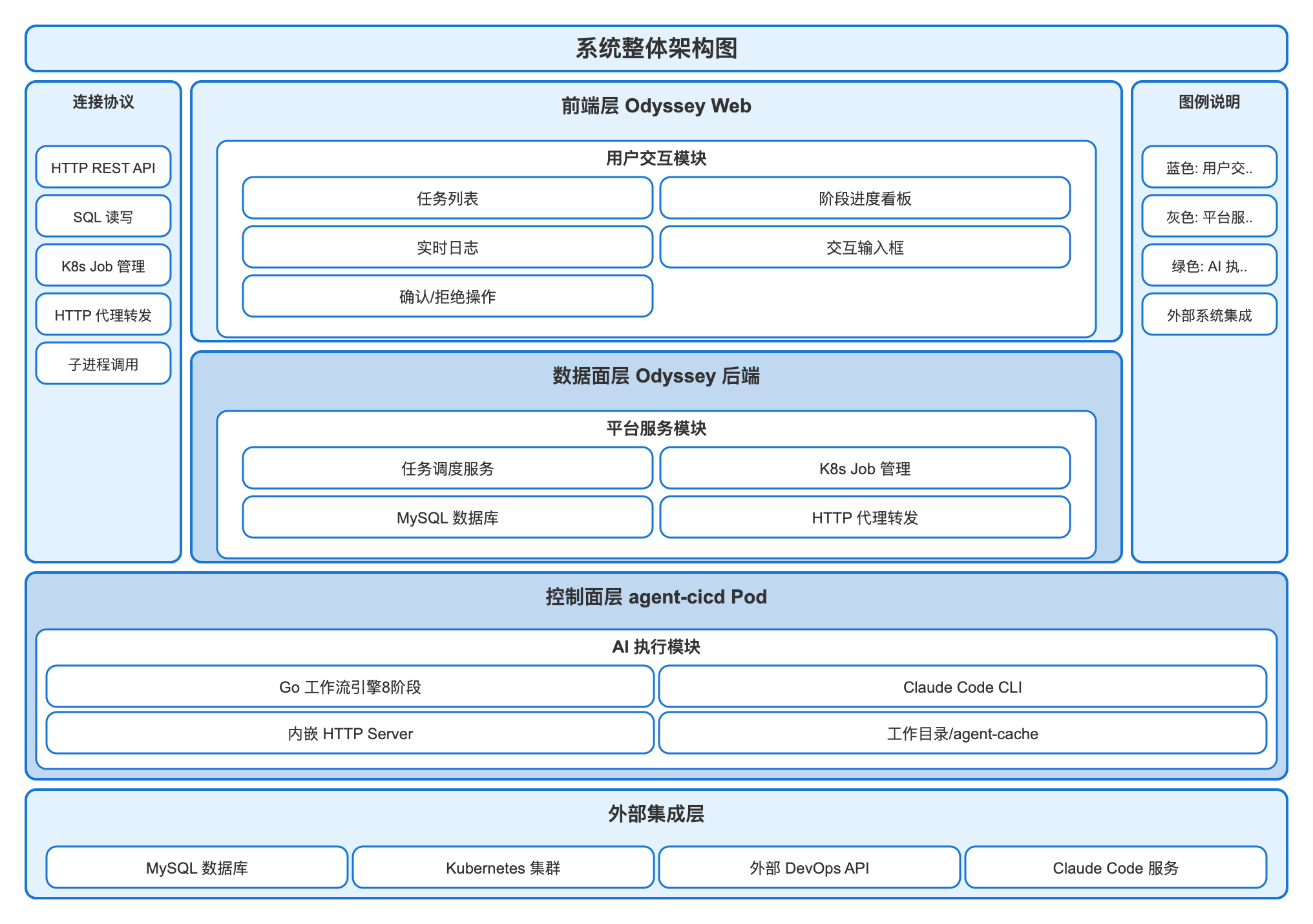
前端负责展示和交互,用户在这里提交需求、查看进度、做确认决策。
数据面是 devops 平台的后端服务,负责任务的持久化、K8s Job 的调度、以及作为前端和 agent Pod 之间的代理层。
控制面是本文的主角,一个运行在 K8s Job 里的 Go 程序,负责驱动整条 AI 流水线。
这种分层设计有一个重要好处:控制面是无状态的(状态全在 MySQL 里),可以随时被 K8s 重新调度,也可以在任意阶段被暂停和恢复。
2.1 任务创建与调度时序
下图描述了从用户提交需求到 agent Pod 开始执行的完整流程: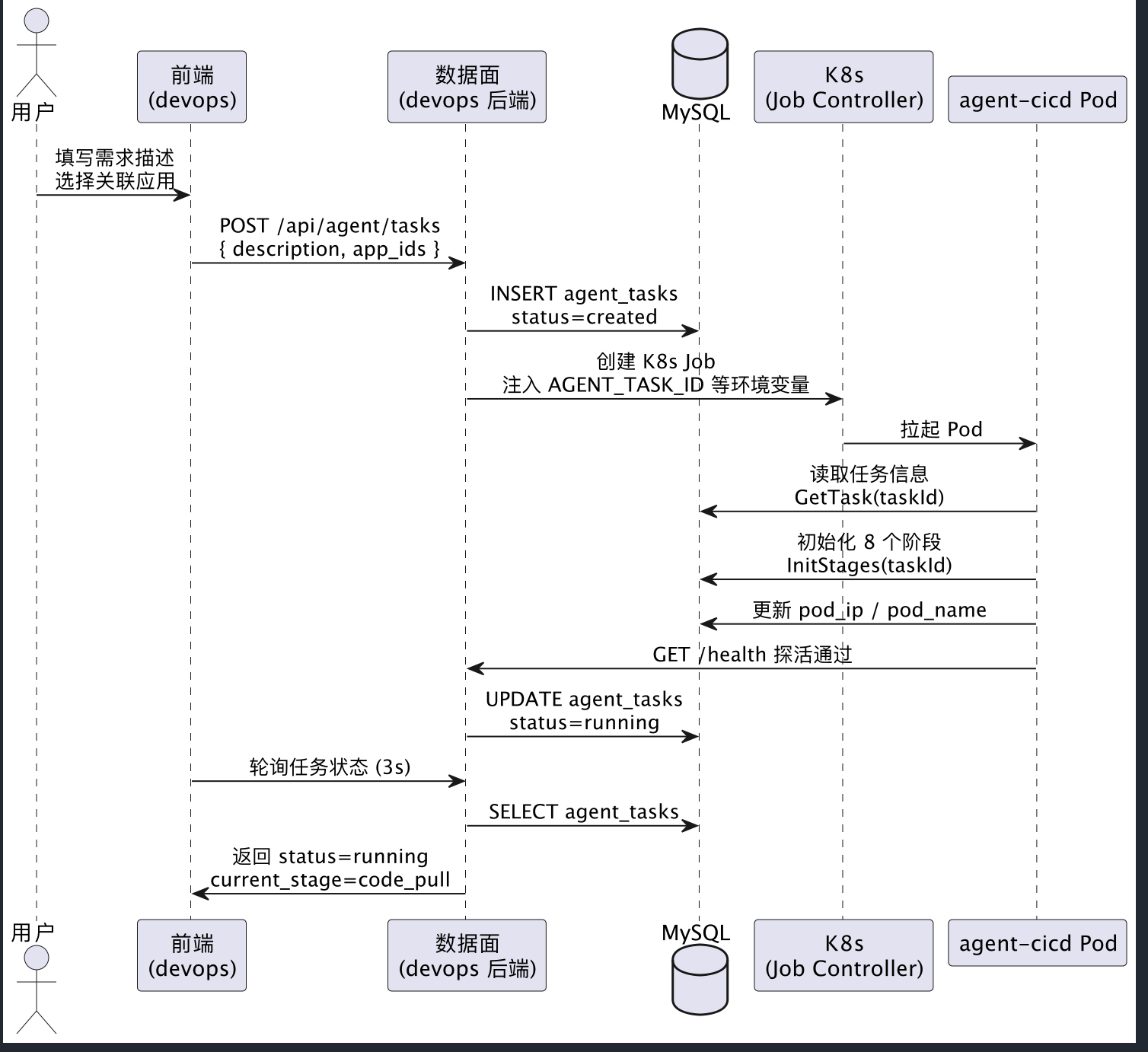
2.2 组件交互全景
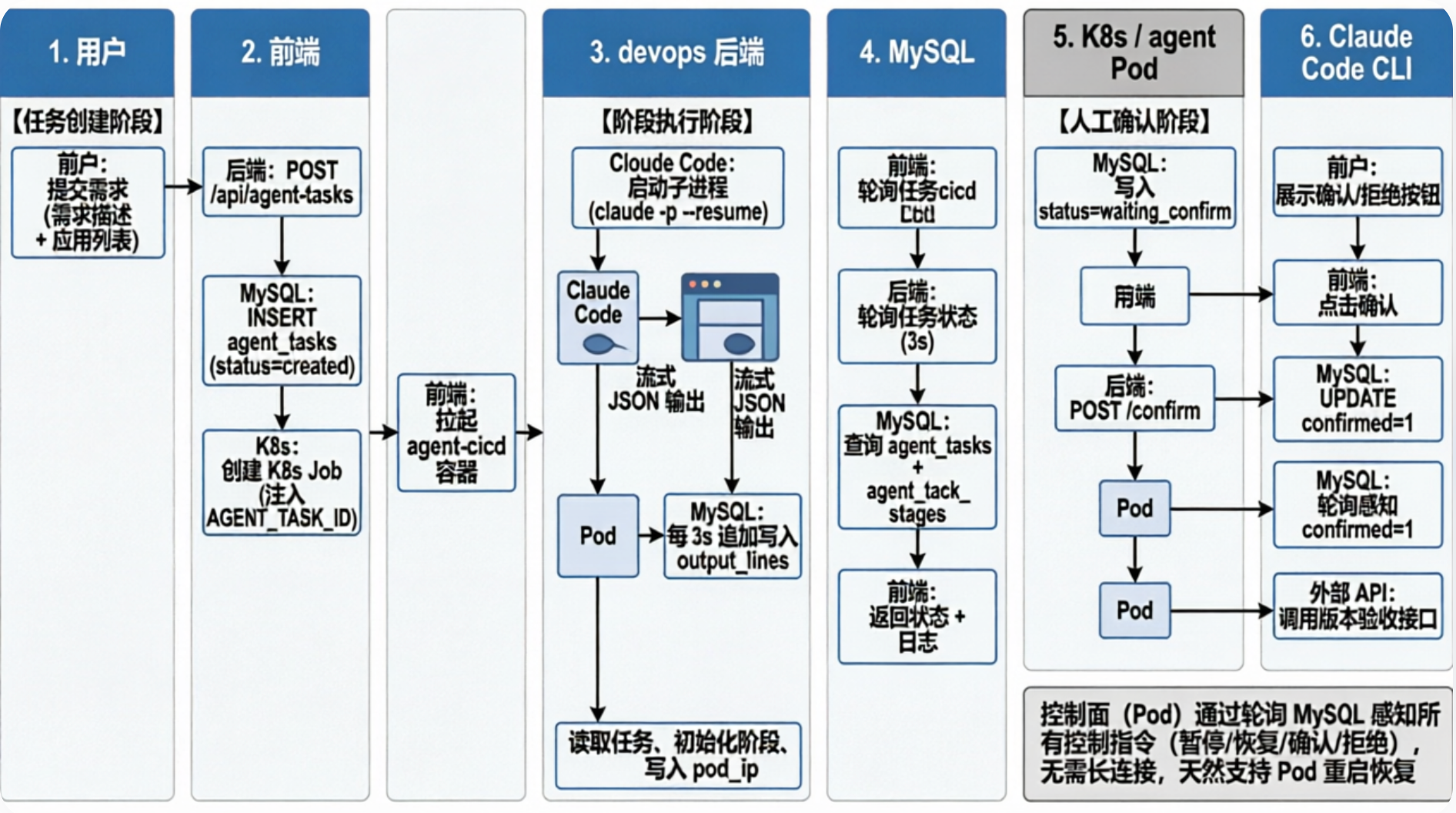
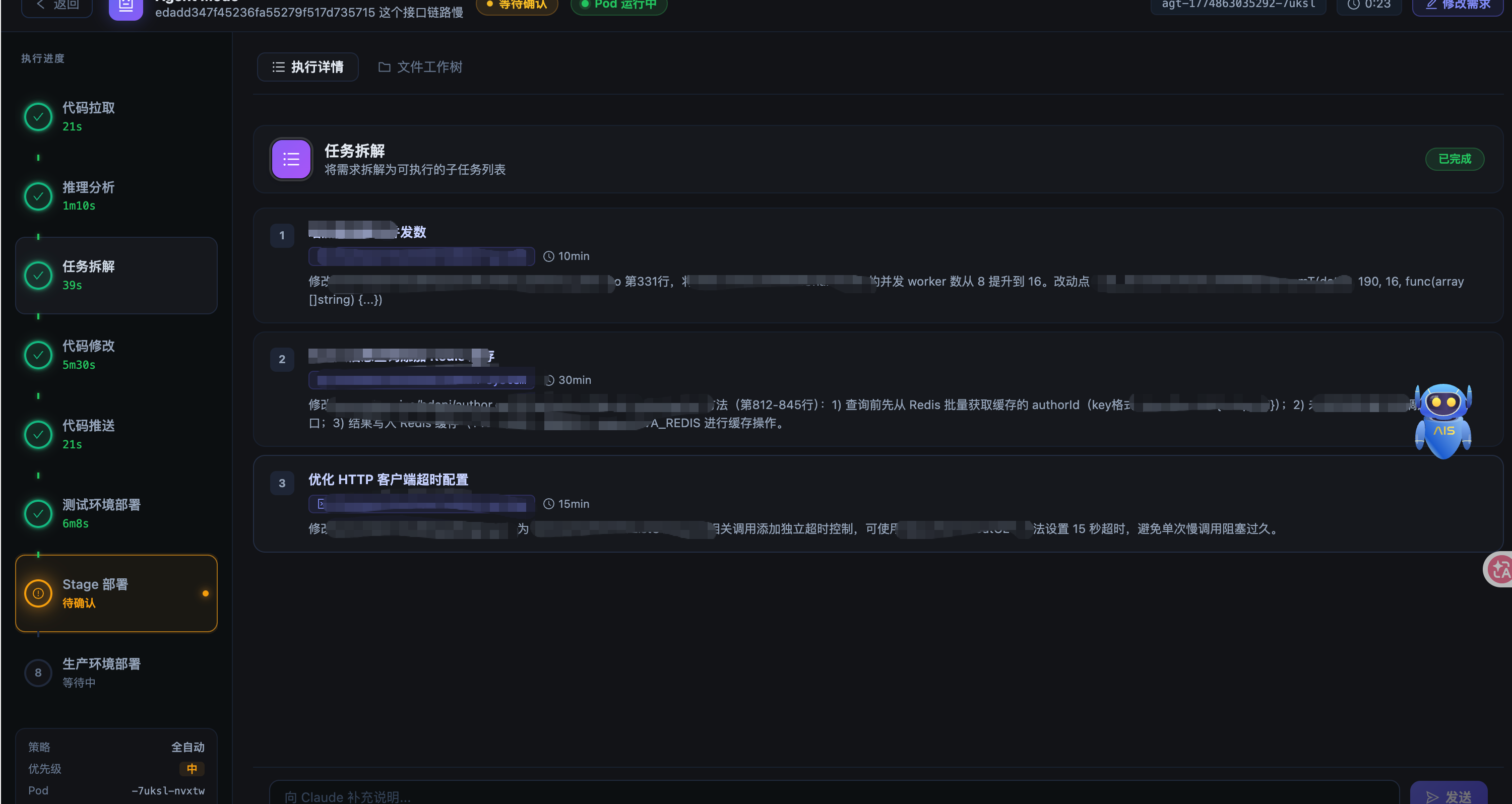
三、八阶段流水线
整条流水线分为八个阶段,按顺序执行:
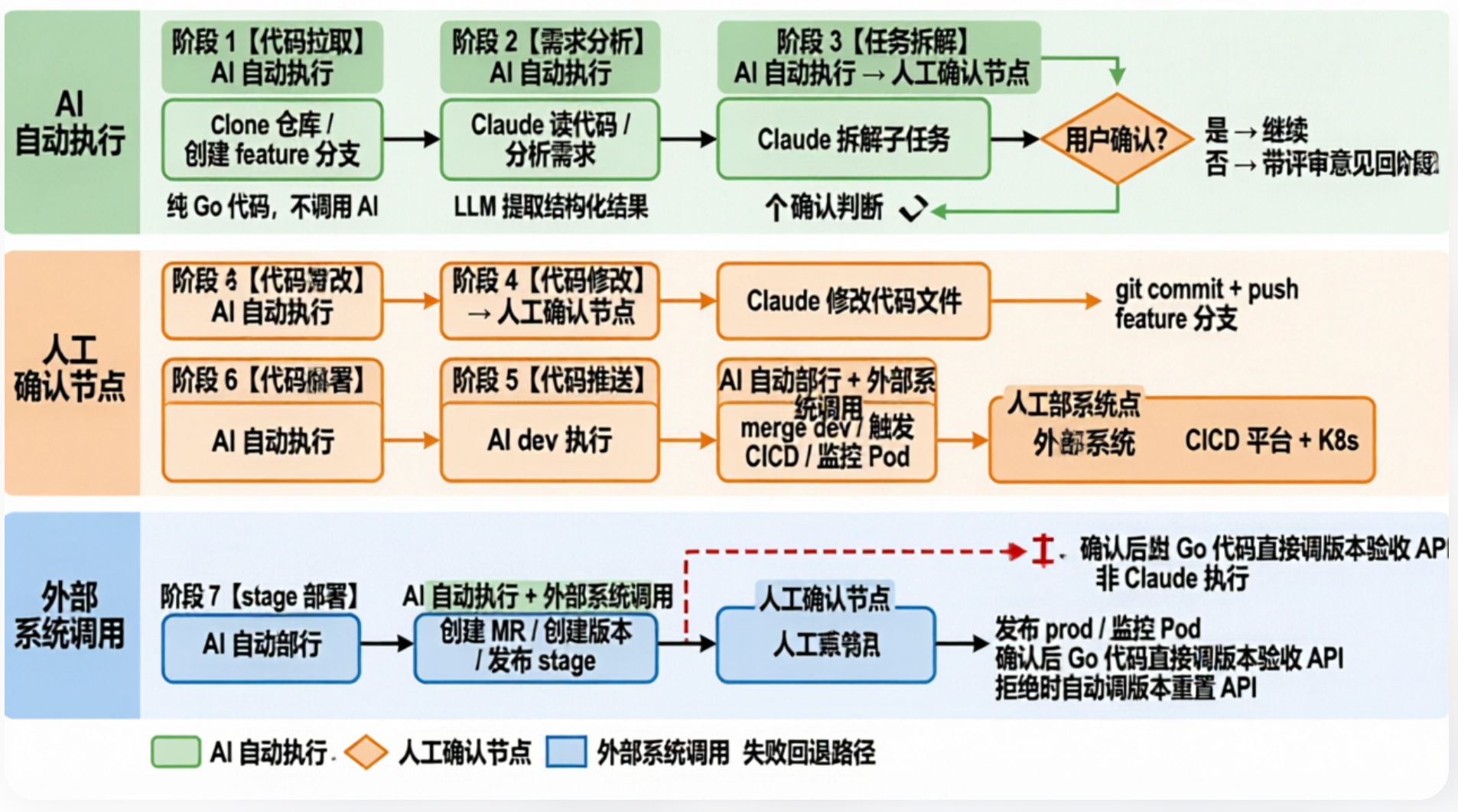
每个阶段的状态存在 MySQL 的 agent_task_stages 表里,字段包括 status(pending/active/done/error)、need_confirm、confirmed、output_lines(实时日志)、result(结构化结果)等。
下面逐个介绍每个阶段的设计。
3.1 代码拉取(code_pull)
这是唯一一个不调用 AI 的阶段,完全由 Go 代码硬编码实现。
逻辑很简单:根据任务关联的应用列表,逐个 clone 或 fetch 代码仓库,检出主干分支,然后创建并切换到 feature/agent-{taskId} 分支。
为什么不用 AI?因为这个操作是完全确定性的,没有任何需要"理解"的地方。用 AI 反而会引入不确定性。这个原则贯穿整个系统设计:能用确定性代码解决的,绝不交给 AI。
// 为每个仓库创建 feature 分支
featureBranch := fmt.Sprintf("feature/agent-%s", eng.TaskID)
if err := runGit(ctx, localPath, "checkout", "-b", featureBranch); err != nil {
// 分支已存在时直接切换
runGit(ctx, localPath, "checkout", featureBranch)
}
3.2 需求分析(analysis)
这是第一个调用 Claude Code 的阶段。
我们给 Claude 提供了两份上下文:
- 需求描述:用户在前端填写的文字
- 代码仓库信息:上一阶段拉取的仓库路径和分支
Claude 会读取相关代码文件,理解需求,输出分析结论。
阶段结束后,我们用一个轻量级 LLM 调用从 Claude 的输出日志里提取结构化数据:
{
"risk_level": "medium",
"estimated_duration": "2-3小时",
"estimated_files": 5,
"confidence": 0.85
}
这份数据会存到 result 字段,供后续阶段和前端展示使用。
3.3 任务拆解(task_breakdown)
Claude 基于分析结果,把需求拆解成具体的子任务列表。每个子任务包含:应用名称、改动描述、预估时间。
这个阶段需要人工确认。用户在前端看到拆解结果后,可以确认通过(继续执行)或拒绝(带评审意见回退到分析阶段重做)。
这是系统里第一个"人在环路"的节点。我们刻意保留了这些节点,因为 AI 对业务语义的理解不可能百分之百准确,关键决策点需要人来把关。
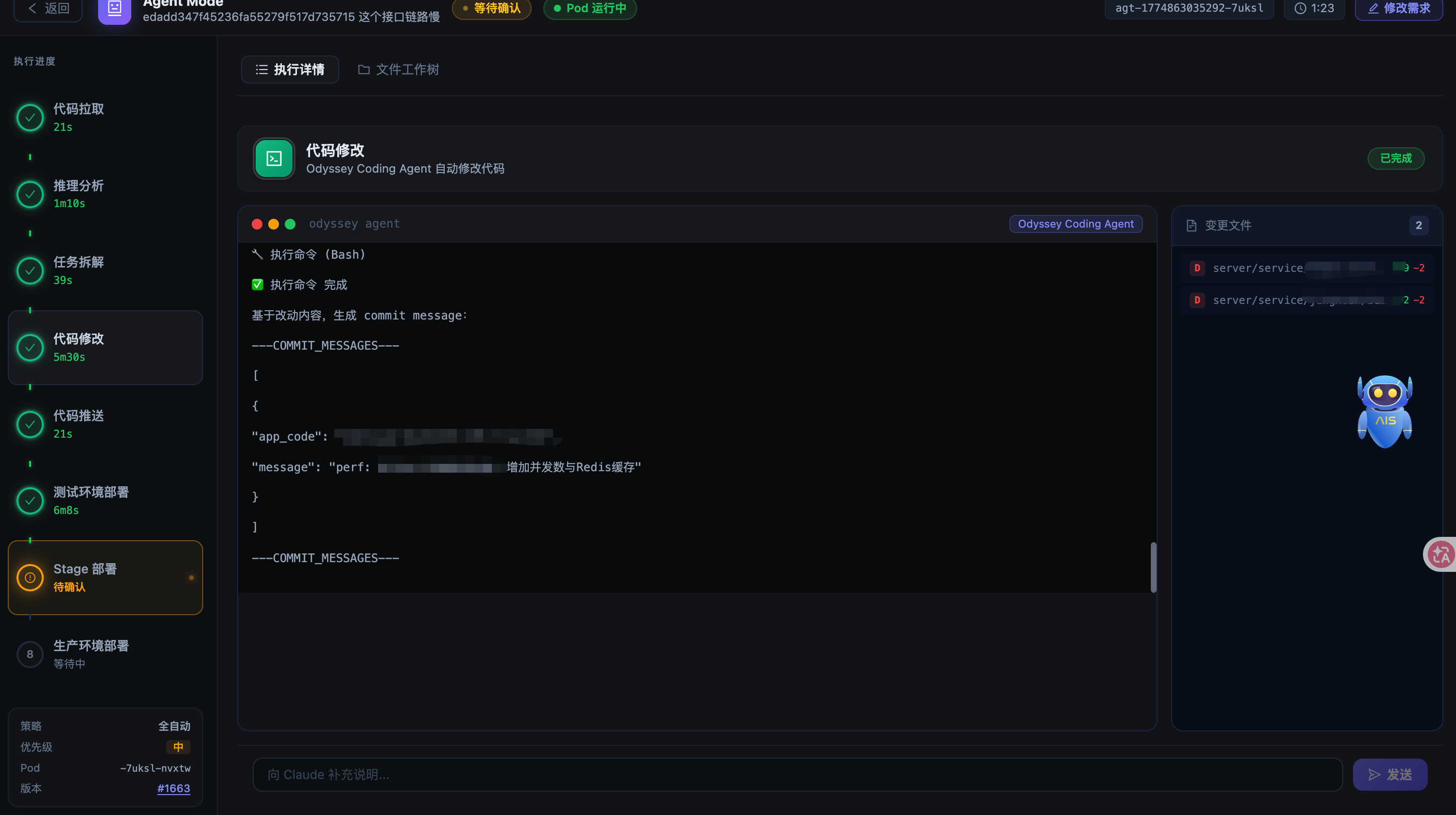
3.4 代码修改(code_modify)
这是整条流水线里最核心、也最复杂的阶段。
Claude 拿到子任务列表后,开始逐个修改代码。为了安全起见,这个阶段的工具权限是受限的,只允许使用文件读写、编辑、Bash 命令等基础工具,不允许调用网络请求或其他高权限操作。
opts := claude.RunOptions{
AllowedTools: []string{
"Bash", "Read", "Edit", "Write", "MultiEdit",
"Grep", "Glob", "LS", "TodoWrite", "TodoRead",
},
}
阶段结束后,我们通过 git diff 汇总变更文件列表,同时让 LLM 从日志里提取 SyncAction——那些需要人工同步执行的操作,比如数据库 DDL、配置变更、环境变量更新等。
这个阶段同样需要人工确认。用户可以在前端查看 Claude 改了哪些文件,决定是否继续。
3.5 代码推送(code_push)
Claude 为每个仓库生成 commit message,然后执行 git add/commit/push,将 feature 分支推送到远端。
这里有一个早期踩过的坑:新创建的分支在 push 时需要 --set-upstream,否则会失败。而且失败后 Pod 会直接退出,没有任何错误信息。后来我们在 runGit 函数里加了完整的错误输出,并在 push 命令里固定加上 --set-upstream:
if err := runGit(ctx, repo.LocalPath, "push", "--set-upstream", "origin", repo.FeatureBranch); err != nil {
db.AppendOutputLines(eng.TaskID, s.Name(), fmt.Sprintf("推送 %s 失败: %v\n", repo.AppCode, err))
return fmt.Errorf("git push %s: %w", repo.AppCode, err)
}
3.6 dev 部署(deploy_dev)
dev 部署的策略和 stage/prod 不同。我们选择了直接 git merge + push 的方式,而不是走 MR 流程。
原因是:dev 环境是开发环境,需要快速验证,MR 流程会引入不必要的等待。而且如果有代码冲突,Claude 可以直接在本地解决,效率更高。
具体流程:
- 暂存当前 feature 分支的改动(
git stash) - 切换到 dev 分支,拉取最新代码
- 将 feature 分支 merge 到 dev
- 如果有冲突,Claude 直接读取冲突文件,结合需求描述判断如何合并
- push dev 分支到远端,触发 CICD 构建
- 轮询构建状态,监控 Pod 就绪情况
这个阶段启用了 VerboseTools,会把 Bash 命令的执行内容和结果都输出到日志,方便排查问题。
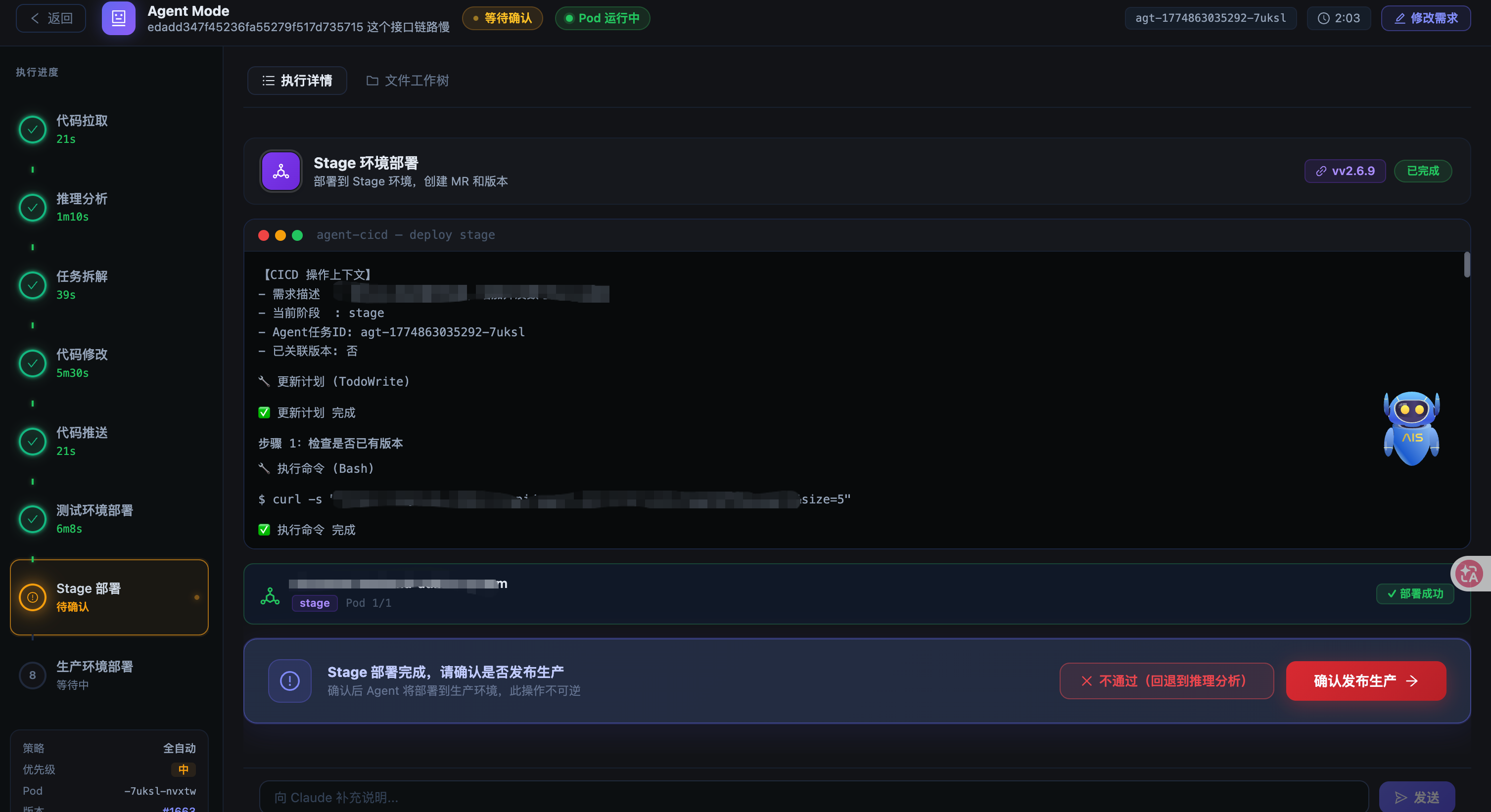
3.7 stage 部署(deploy_stage)
stage 部署走正式的版本管理流程:创建 MR、创建版本、发布到 stage 环境、监控 CICD 节点状态、确认 Pod 就绪。
这个阶段有一个关键设计:版本 ID 的自动提取和回写。
Claude 在创建版本时会输出版本 ID,我们用 LLM 从日志里提取这个 ID,写入 agent_tasks.version_id 字段。后续的 prod 部署和版本验收都依赖这个字段。
// 如果 Claude 创建了版本且任务还没有关联版本,自动回写 version_id
if deployResult.VersionID > 0 && versionID == 0 {
db.UpdateTaskVersionID(eng.TaskID, deployResult.VersionID)
}
部署成功后,这个阶段需要人工确认。用户确认后,系统会直接调用 devops 的版本验收 HTTP 接口,不再经过 Claude。
这是一个重要的设计决策,后面会详细说。
3.8 prod 部署(deploy_prod)
prod 部署流程与 stage 类似,但有几个额外的约束:
- 必须有 version_id:如果 stage 阶段没有成功提取到版本 ID,prod 部署会直接报错
- 禁止重新建版本:prod 阶段只能使用已有版本,不能新建
- 拒绝时自动重置版本:如果用户拒绝了 prod 部署(比如发现线上问题),系统会自动调用版本重置接口,将版本状态回退
四、调度引擎设计
八个阶段的调度由 Engine 结构体驱动,核心是一个 Run() 方法里的循环:
func (e *Engine) Run(ctx context.Context) error {
curIdx := 0
for curIdx < len(e.Stages) {
// 从 DB 读取当前阶段状态
stageMap, _ := e.loadStageMap()
stage := e.Stages[curIdx]
info := stageMap[stage.Name()]
// 已完成的阶段直接跳过
if info.Status == "done" {
curIdx++
continue
}
// 暂停检测
e.waitIfPaused(ctx)
// 执行阶段
if err := stage.Execute(ctx, e); err != nil {
// 分类处理各种错误...
}
curIdx++
}
}
每次循环开始都从 DB 读取阶段状态,这样做的好处是:即使 Pod 重启,也能从上次中断的地方继续,不会重复执行已完成的阶段。
4.1 错误分类处理
阶段执行可能返回多种错误,引擎对每种错误有不同的处理策略:
| 错误类型 | 触发条件 | 处理方式 |
|---|---|---|
ErrInterrupted |
用户发送交互消息 | 重置当前阶段,带入用户消息重新执行 |
ErrKilled |
调用 Reset 接口 | 重新扫描第一个 pending 阶段 |
ErrDeployFailed |
部署失败 | 自动回退到 analysis 阶段 |
ErrRollback |
用户拒绝确认 | 回退到指定阶段,带入评审意见 |
| 普通 error | 其他错误 | 任务状态置为 error,停止执行 |
4.2 Claude Code 的调用方式
我们通过 Go 的 os/exec 包调用 Claude Code CLI,以非交互模式运行:
claude -p --output-format stream-json --verbose --include-partial-messages \
--system-prompt "..." \
--resume <sessionId>
关键参数说明:
-p:非交互模式,从 stdin 读取 prompt--output-format stream-json:流式 JSON 输出,便于实时解析--resume <sessionId>:续接上一次会话,保持上下文连续性--system-prompt:注入系统级规则(包括 Superpowers 插件的约束)
Claude 的输出是一系列 JSON 事件,我们解析这些事件,提取文本输出、工具调用记录、会话 ID 等信息,实时写入数据库的 output_lines 字段。
// 解析流式 JSON 事件
scanner := bufio.NewScanner(stdout)
for scanner.Scan() {
var event claudeEvent
json.Unmarshal(scanner.Bytes(), &event)
// 根据 event.Type 分类处理...
}
4.3 会话连续性
Claude Code 支持通过 --resume <sessionId> 续接会话。我们在引擎里维护一个 ClaudeSessionID 字段,每次 Claude 运行结束后保存返回的 session ID,下次运行时传入。
这样做的好处是:Claude 在整个任务执行过程中能保持上下文连续性,后续阶段可以"记住"前面阶段做了什么。
五、人机交互设计
这是整个系统里最有意思的部分,也是我们迭代最多的地方。
5.0 人机交互全流程时序
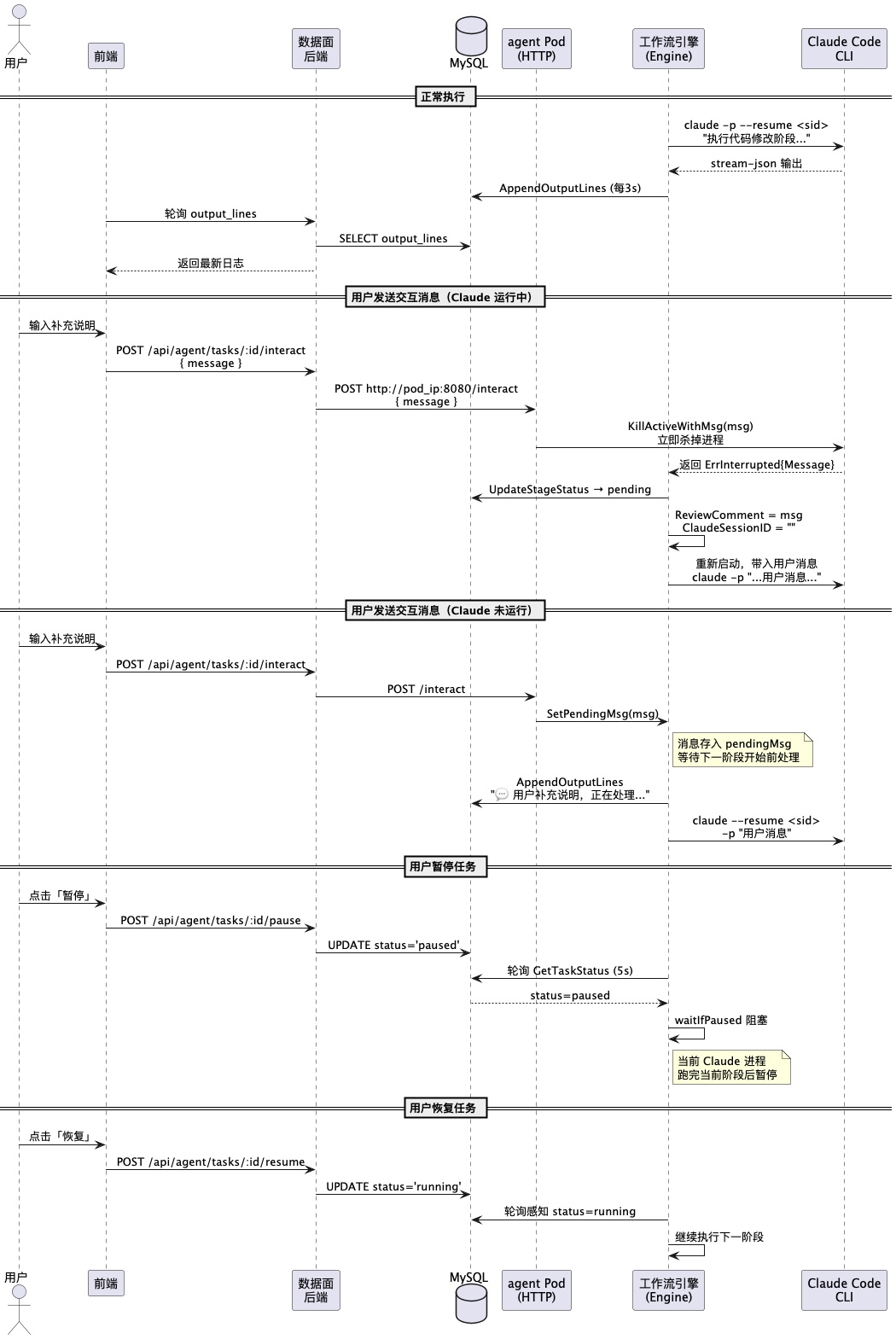
5.1 暂停与恢复
用户可以随时暂停任务。暂停的实现很简单:后端把 agent_tasks.status 改为 paused,引擎在阶段间隙轮询这个字段,发现 paused 就阻塞等待。
func (e *Engine) waitIfPaused(ctx context.Context) error {
for {
status, _ := db.GetTaskStatus(e.TaskID)
if status != "paused" {
return nil
}
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(5 * time.Second):
}
}
}
注意:暂停不会打断正在运行的 Claude 进程,而是在当前阶段完成后才生效。这是有意为之的设计——强行杀掉 Claude 进程可能导致代码处于中间状态。
5.2 实时交互消息
用户可以在任务运行过程中发送补充说明,这是我们花时间最多的功能。
最初的实现是把消息放进队列,等当前阶段结束后再处理。但这意味着用户发的消息对当前阶段完全无效,体验很差。
第二版实现是在阶段结束后用 --resume 追加处理。这比第一版好一些,但用户消息仍然不能影响当前阶段的执行结果。
最终实现分两种情况:
情况一:Claude 正在运行
收到消息后立即调用 KillActiveWithMsg(msg) 杀掉当前 Claude 进程,进程退出时返回 ErrInterrupted{Message: msg},引擎捕获后:
- 把当前阶段状态重置为
pending - 把用户消息写入
ReviewComment - 清空
ClaudeSessionID(会话重建) - 重新执行当前阶段,用户消息作为补充上下文带入 prompt
var ei *claude.ErrInterrupted
if errors.As(err, &ei) {
db.UpdateStageStatus(e.TaskID, name, "pending")
e.ReviewComment = ei.Message
e.ClaudeSessionID = ""
continue // 重新执行同一阶段
}
情况二:Claude 未在运行(阶段间隙或已完成)
消息存入 Engine.pendingMsg,下一个阶段的 RunClaude() 开始前,用 --resume 先处理这条消息,输出追加到上一个阶段的日志里。
// RunClaude 开始前检查 pendingMsg
if msg := e.takePendingMsg(); msg != "" && e.ClaudeSessionID != "" {
db.AppendOutputLines(e.TaskID, e.lastStage, "💬 用户补充说明,正在处理...\n")
e.runWithFlush(ctx, e.lastStage, claude.RunOptions{
Prompt: msg,
SessionID: e.ClaudeSessionID,
})
}
这样,无论用户在什么时机发送消息,都能得到响应。
5.3 重置与重新执行
用户可以在任意时刻重置任务,从头开始。重置流程:
- 调用
KillActive()杀掉当前 Claude 进程 - 清空工作目录(删除所有 clone 的代码)
- 清空
ClaudeSessionID - 数据库里所有阶段重置为
pending - 引擎重新定位到第一个 pending 阶段,继续执行
关键设计:Pod 不退出。重置后引擎继续在同一个 Pod 里运行,不需要 K8s 重新调度。这大大减少了重置的等待时间。
func (e *Engine) Reset() error {
claude.KillActive()
time.Sleep(500 * time.Millisecond) // 等待进程退出
os.RemoveAll(e.WorkDir)
os.MkdirAll(e.WorkDir, 0755)
e.ClaudeSessionID = ""
db.ResetAllStages(e.TaskID)
db.UpdateTaskStatus(e.TaskID, "running", "")
return nil
}
用户还可以修改需求描述后从指定阶段重新执行,比如"从任务拆解阶段重新开始"。这通过 devops 后端的 update-description 接口实现,后端更新需求描述后调用 Pod 的 /reset 接口触发重置。
六、版本验收的一个重要教训
这是我们踩过的最深的坑之一,值得单独说。
6.0 stage/prod 确认与验收时序
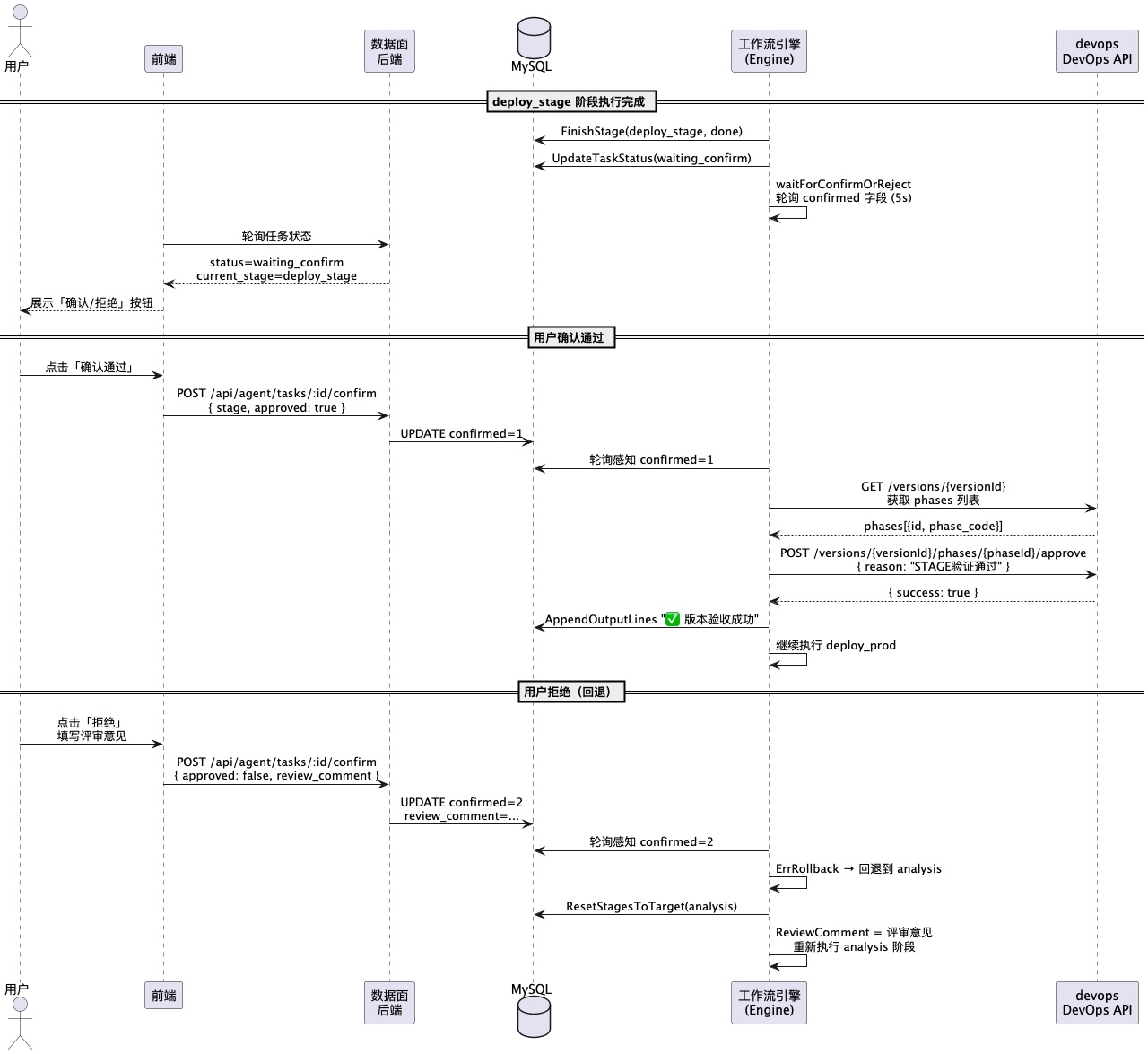
问题描述:stage 环境部署成功,用户在前端确认通过,但版本始终没有被验收。查日志发现 Claude 执行了验收操作,但接口调用失败了,而且失败原因各种各样——有时是找不到 phaseId,有时是接口参数格式不对,有时是 Claude 在验收前做了多余的状态检查导致超时。
根本原因:我们最初让 Claude 来执行版本验收操作,给它一段 prompt 说"请调用验收接口"。但验收是一个确定性操作:已知 versionId,查 phases 列表,找到对应 phaseCode 的 phaseId,调 approve 接口。这个过程没有任何需要"理解"的地方,但 Claude 每次执行都会有细微的差异,导致偶发性失败。
解决方案:用 Go 代码直接调 HTTP 接口,完全绕开 Claude。
func (e *Engine) callVersionApprove(envName string) error {
versionID, _ := db.GetTaskVersionID(e.TaskID)
phaseCode := map[string]int{"stage": 1, "prod": 2}[envName]
return devops.ApproveVersion(versionID, phaseCode, "验证通过")
}
// devops/client.go
func ApproveVersion(versionID int64, phaseCode int, reason string) error {
// 1. GET /versions/{versionId} 获取 phases 列表
detail, _ := GetVersionDetail(versionID)
// 2. 找到对应 phaseCode 的 phaseId
var phaseID int64
for _, p := range detail.Phases {
if p.PhaseCode == phaseCode {
phaseID = p.ID
break
}
}
// 3. POST /versions/{versionId}/phases/{phaseId}/approve
return doJSON("POST", fmt.Sprintf("/versions/%d/phases/%d/approve", versionID, phaseID),
map[string]string{"reason": reason}, &result)
}
这个改动上线后,版本验收的成功率从 ~85% 提升到 ~100%。
这个教训可以总结为一个原则:AI 适合处理模糊性和创造性的任务,不适合处理确定性的操作。凡是能用代码精确描述的逻辑,就用代码实现,不要交给 AI。
七、Skill 系统:给 AI 的操作手册
Claude Code 本身是一个通用的代码助手,它不知道我们的 DevOps 平台有哪些接口、每个接口的参数格式是什么、有哪些操作限制。
我们通过 Skill 文件来解决这个问题。每个阶段对应一个 SKILL.md 文件,里面写清楚了这个阶段应该做什么、怎么做、有哪些禁止操作。
以 agent-cicd 技能为例,它定义了所有 DevOps 操作的规范:
## 强制规则
1. 命令执行后必须检查输出,有报错立即停止,不得重试
2. 不得跨阶段操作,每个阶段只做本阶段的事
3. 非 dev 阶段已有 version_id 时,禁止重新建版本
4. 发布失败时只分析原因,不自动重试发布
5. stage/prod 阶段严禁调用合并 MR 接口
这些规则通过 --system-prompt 注入到每次 Claude 调用中,确保 AI 的行为在预期范围内。
Skill 系统的设计理念是:把业务知识和操作规范从代码里剥离出来,以文档的形式维护。这样做的好处是:
- 规则更新不需要改代码,只需要修改 Skill 文件
- 规则对人类可读,便于 review 和讨论
- 可以针对不同环境、不同团队定制不同的规则
八、Pod 内嵌 HTTP 服务
agent-cicd Pod 内嵌了一个轻量级 HTTP 服务,提供以下接口:
| 接口 | 说明 |
|---|---|
GET /health |
探活,返回当前任务状态和阶段 |
GET /files?path= |
浏览工作目录文件 |
GET /files/tree?depth= |
获取文件树 |
POST /interact |
发送交互消息 |
POST /reset |
重置任务 |
这个设计让 devops 后端可以通过 Pod IP 直接访问 Pod 的内部状态,不需要通过 K8s 的 exec 或日志接口,响应更快,也更安全(路径穿越防护、大文件截断等)。
// 防止路径穿越攻击
rel = filepath.Clean("/" + rel)
absPath := filepath.Join(workDir, rel)
if !strings.HasPrefix(absPath, workDir) {
http.Error(w, "forbidden", http.StatusForbidden)
return
}
健康检查接口的状态由后台 goroutine 每 5 秒从 DB 同步一次,这样即使 DB 查询偶发超时,也不会影响探活的响应速度。
九、数据库设计
整个系统的状态持久化依赖两张核心表:
十、踩过的其他坑
10.1 Claude 进程的会话管理
早期我们没有正确处理 --resume 的时机,导致每个阶段都是一个全新的会话,Claude 不知道前面发生了什么,经常做出重复或矛盾的操作。
后来我们在引擎里维护 ClaudeSessionID,在同一个任务的所有阶段里复用同一个会话。但有一个例外:当阶段被打断重置时,必须清空 session ID,因为被打断的会话上下文可能包含错误的中间状态。
10.2 LLM 结果提取的稳定性
我们用一个轻量级 LLM 从 Claude 的输出日志里提取结构化数据(比如版本 ID、部署结果等)。早期这个提取经常失败,因为 Claude 的输出格式不固定。
后来我们做了两个改进:
- 在 prompt 里明确要求 Claude 在输出关键信息时使用特定格式,比如
versionId=12345 - 提取失败时使用兜底值,不让整个阶段失败
10.3 并发安全
Engine 结构体的字段会被主流程 goroutine 和 HTTP handler goroutine 并发访问。早期我们没有加锁,偶发性地出现数据竞争。
后来对所有需要并发访问的字段加了互斥锁:
type Engine struct {
// ...
pendingMsgMu sync.Mutex
pendingMsg string
}
func (e *Engine) SetPendingMsg(msg string) {
e.pendingMsgMu.Lock()
defer e.pendingMsgMu.Unlock()
e.pendingMsg = msg
}
10.4 Superpowers 插件的注入方式
Claude Code 有一个 Superpowers 插件,提供了一套元技能框架,可以强制 Claude 在执行前先检查相关技能文档。
最初我们想通过在工作目录放 CLAUDE.md 文件来注入这些规则,但 Claude Code 在非交互模式下工作目录是动态的(每个仓库一个目录),CLAUDE.md 不可靠。
后来改为通过 --system-prompt 参数直接注入,这样无论工作目录是什么,规则都会生效。
十一、效果与展望
系统上线三个月后,我们统计了一些数据:
- 一个中等复杂度的需求(3-5 个文件改动),从提交到 dev 环境验证,平均耗时从 45 分钟降低到 12 分钟
- 开发者在发布流程上的主动操作次数从平均 23 次降低到 4-6 次(主要是几个确认节点)
- 因操作失误导致的发布问题,从每周 2-3 次降低到近乎为零
当然,系统也有明显的局限性:
- 对需求描述的质量要求较高:如果需求描述模糊,AI 的分析和拆解质量会显著下降
- 复杂的业务逻辑修改仍需人工介入:对于涉及多个服务、复杂事务逻辑的改动,AI 的代码修改质量还不够稳定
- 调试成本较高:当 AI 做出错误操作时,排查原因需要阅读大量日志
接下来我们计划做的事情:
- 引入代码 review 环节:在代码推送前,让另一个 AI 实例对改动做 review,减少低质量代码进入仓库的概率
- 支持多任务并行:目前一个应用同时只能有一个 agent 任务在运行,后续考虑支持并行
- 改进失败恢复:当某个阶段失败时,提供更智能的恢复建议,而不是简单地回退到分析阶段
结语
这套系统的核心思想可以用一句话概括:让 AI 处理模糊性,让代码处理确定性,让人类处理决策性。
AI 擅长理解自然语言、分析代码语义、生成符合上下文的代码改动,这些是"模糊性"任务。版本验收、git 操作、接口调用,这些有明确规范的操作应该用代码直接实现。而"这个改动是否符合业务预期"、“这个版本是否可以上线”,这些涉及业务判断的决策,应该由人来做。
把这三类任务分配给正确的执行者,是构建可靠 AI 交付系统的关键。
本文涉及的代码已做脱敏处理,隐藏了企业内部域名、认证信息等敏感内容。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)