第4节.分类任务
一、机器学习回顾和展望
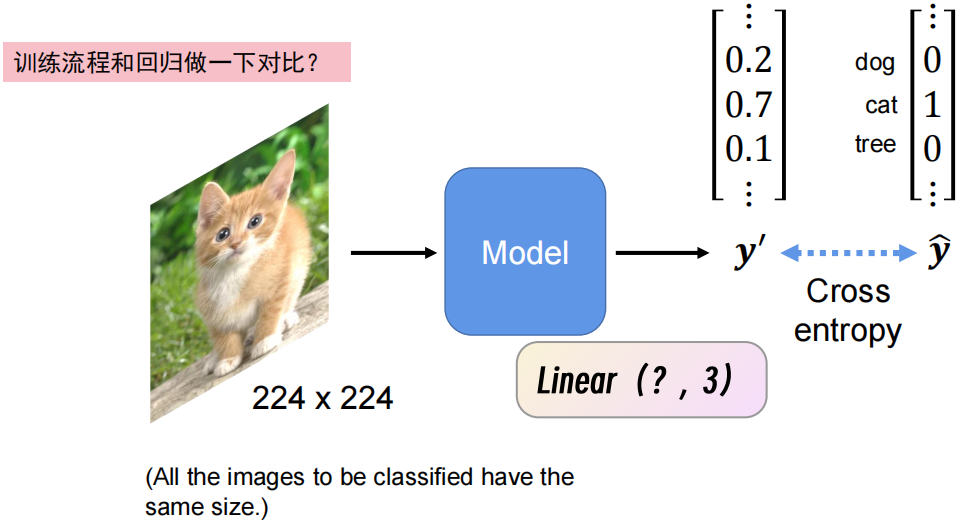
1、nn.Linear
把向量/矩阵从A维度转为B维度
2、卷积
见下文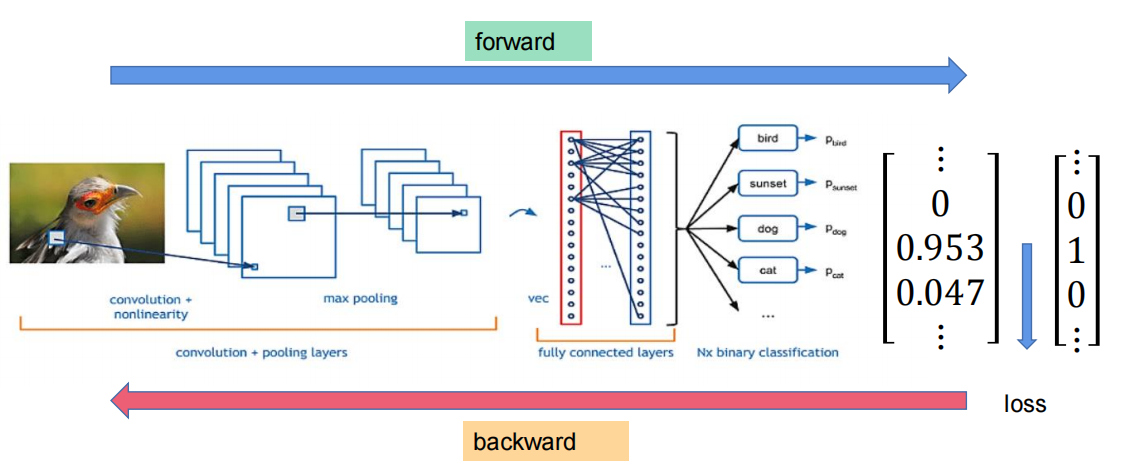
二、分类
现实中很多问题并不是预测问题,是分类问题,如:判断一封邮件是否是垃圾邮件,根据两个人的样貌判断是否为直系亲属,判断图片里是人、狗、还是猫,下围棋等
回归是要预测一个值、模拟已有的数据分布、根据新的x得到新的y,分类是要找到一个分界线、把2个类别分割开来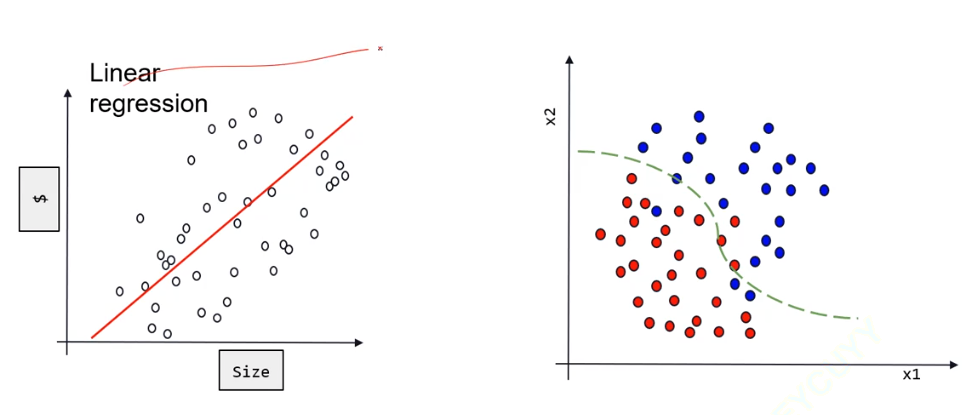
1、分类的输出
与回归不同,分类的输出为了让不同类别等价,不能采用回归到一个值的方式来进行输出
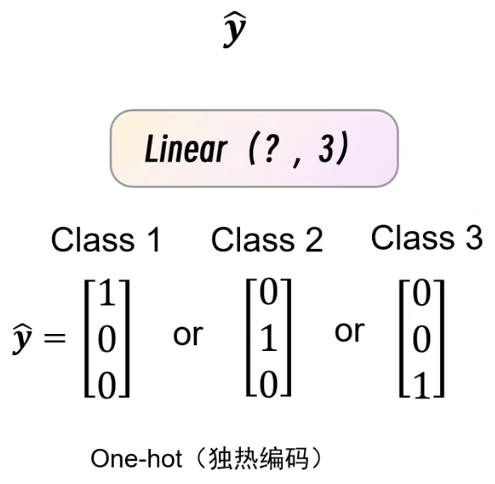
一般采用的是,独热编码。y^表示标签、真实值,y’表示预测值,用元素1所在的位置表示
最大值所在的下标为预测类,输出其角标即可知道是哪一类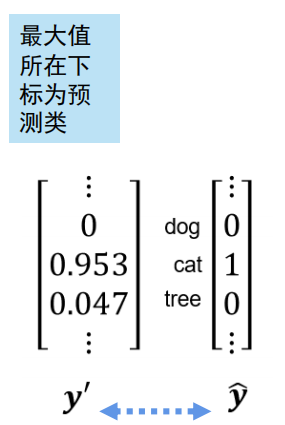
2、分类的输入
用一个图像分类任务做例子
以下例子:输入一张图片,判断是猫还是狗
按照概率分布来理解这个,是狗的概率是0.2,是猫的概率为0.7,是树的概率是0.1
求2个概率分布之间的Loss不能用之前的mae,要用交叉项损失
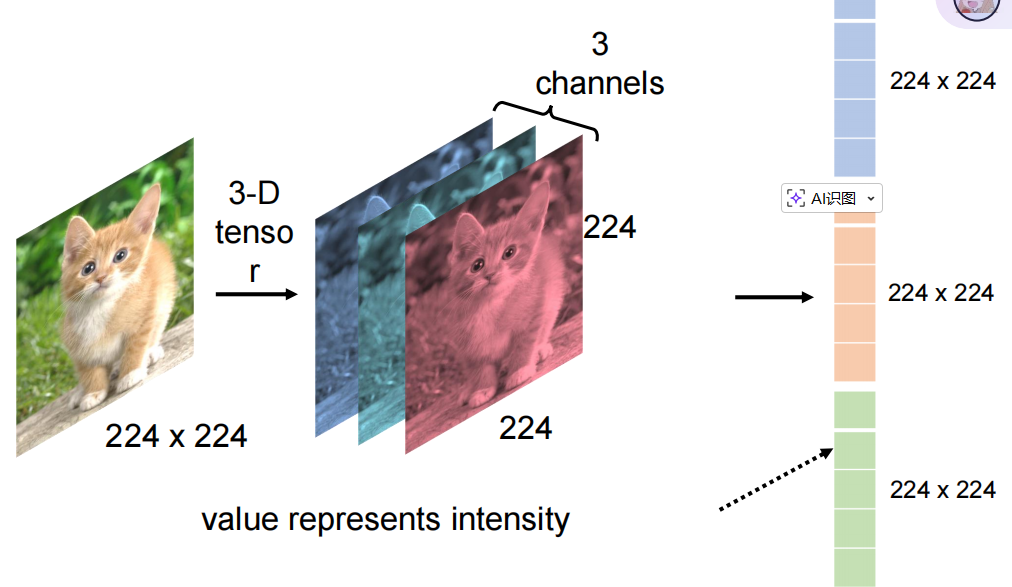
将三通道的拉直,3个拼接在一起,成为一个向量,作为输入
3、卷积神经网络
不需要对比整张图,只需要关注到小的特征图。越像,值越大。用和卷积核相同的大小去一个个算原始图片中的每一部分,直到全部“卷”完
(1)每次卷积都减小了特征图尺寸,如何保持尺寸不变
zero padding是补0,padding1表示补1圈0,padding2表示补2圈0

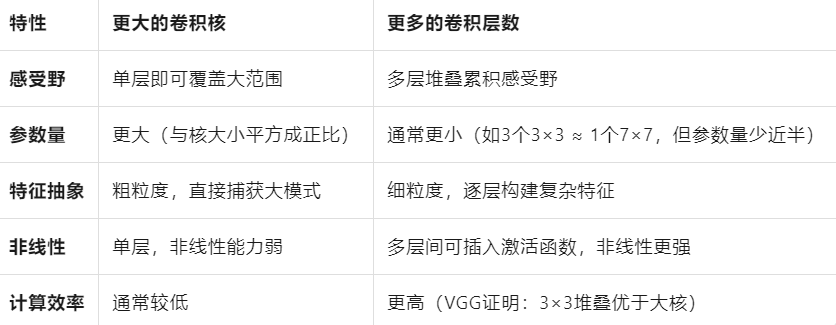
(2)更大的卷积核和更多的卷积层数可以带来什么
(3)原始特征图和新特征图,与卷积核的深度有什么关系
原始特征图和卷积核的深度/厚度要保持一致,
新特征图的厚度与卷积核数量是保持一致的。而新特征图的大小受原特征图大小、padding层数、卷积核大小3个条件的影响。
(4)一个卷积层是什么,卷积核的参数量怎么计算
以下为例题,卷积核大小为2表示2*2,3就表示3*3
公式:输入特征图大小=输入特征图大小-卷积核大小+1,
参数量=卷积核大小的维度次方

答案:
①3*3,4(用2*2计算)
②2*2
③4*4(padding加了一圈0变成6*6)
④98*98(3个一卷,3个一卷,1-98都可以卷,到99就不能卷了)
⑤100*100(padding1以后变成了102*102,减二后同上)
⑥2*2(8-7+1),49
⑦94*94(100-7+1)

①3
②224*224(228-5+1)
③3*3*3,27(3是指通道长,padding1后是3*6*6;卷出来的特征图和之前特征图相同4*4,所以卷积核大小是3*3,厚度上和输入特征图保持一致是3,因此卷积核是3*3*3,参数量3^3=27)
④7*4*4(padding后特征图3*6*6,卷积核3*3,卷出来特征图大小应该是4*4。每一个卷积核都可以卷出来一张特征图,一个特征图对应一个卷积核,卷出来是7*4*4特征图)
⑤64*224*224(padding后特征图3*226*226,226-3+1=224,卷出来特征图64*224*224)
⑥128*224*224,73728(padding后特征图64*226*226,226-3+1=224,卷了以后特征图大小是224*224,厚度与卷积核数量保持一致,所以卷了以后特征图是128*224*224。这套卷积核参数量=卷积核数量*每个卷积核的参数量=128*64*3*3=73728)
(5)特征图大小一直不变,不论怎么卷参数展平后都需要大量参数,怎样让特征图变小
依次卷积每次减少2可行吗,不太可行。卷积神经网络常用的方法是subsampling降采量,比如隔一个像素点取一个,200*100→100*50。有以下2种方法:
a.扩大步长
b.依靠pooling:池化
a.卷积步长
有时候卷积不是一个格子一个格子来的,会有一个步长记录跳过的部分

b.pooling:池化
直接减少。有2种方法:
最大池化与平均池化
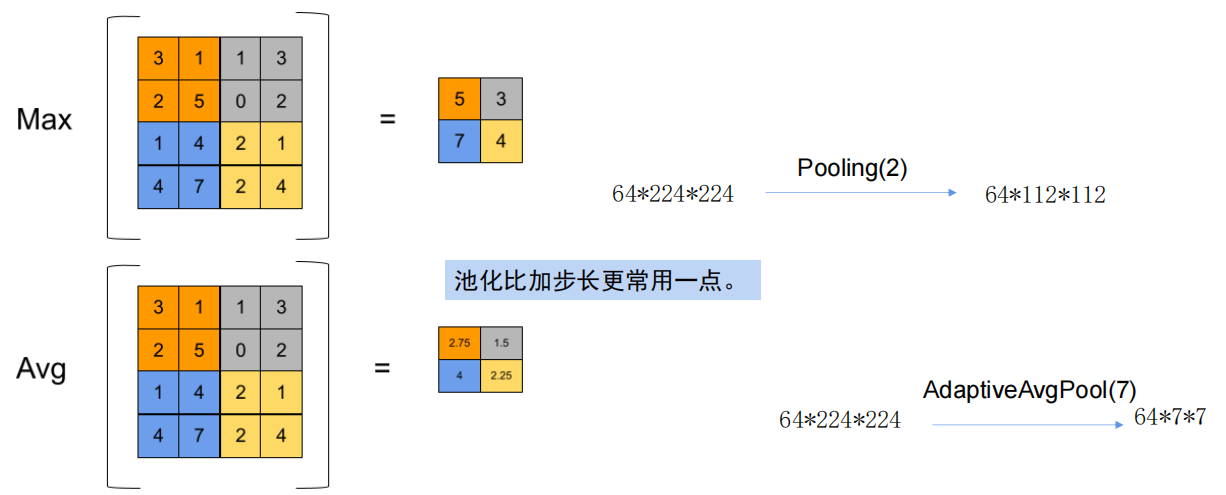
应用的时候我们很少用平均池化,最大池化用的多一点,一般会选择最显著的那一个点,不用做计算。人眼也只会看到最显著的那个点


一般一次卷积搭配一次pooling池化来进行
(6)最初的目的--怎么通过卷积卷出来一个类别呢
卷到一定程度拉直,经过一个全连接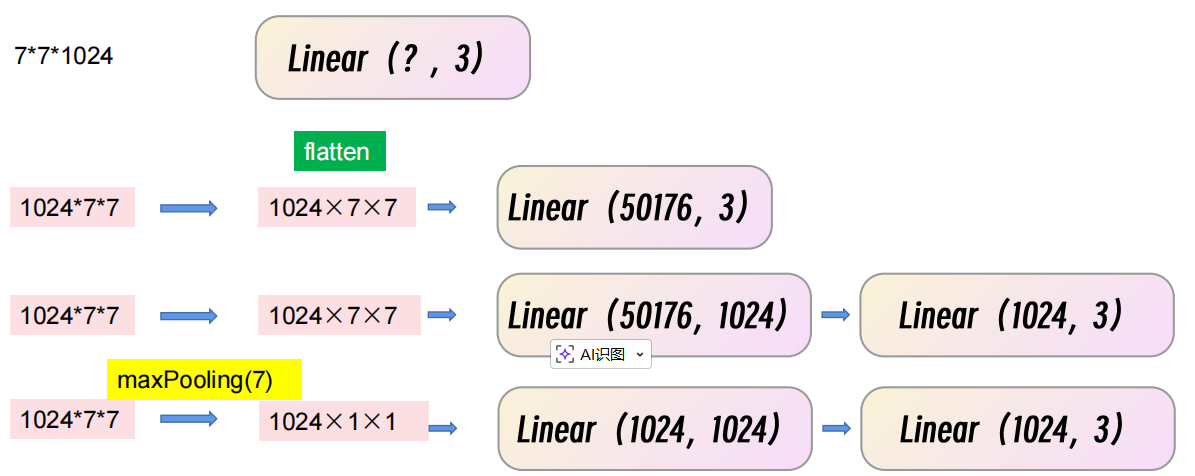
4、分类的LOSS
让输出也变成概率分布
通过softmax函数,将其转化为整齐的概率分布

2个分布之间的LOSS,可以根据交叉熵损失(以下博客中有关于交叉熵损失的详细介绍)


5、需要大量的、带标签的图片作为数据集
大佬们整理的经典数据集:
其中手写数字被很多人说已经被考研复试老师看烂了……是一个很基础的数据集;
coco数据集除了有标签,还有对图片的描述

三、模型的历史和发展
复试老师经常会问你对于一个领域的了解,包括它的发展历史
the state of the art,最先进模型
1998-2012,由于显卡的发明,显著准确率提升,推动了神经网络的发展
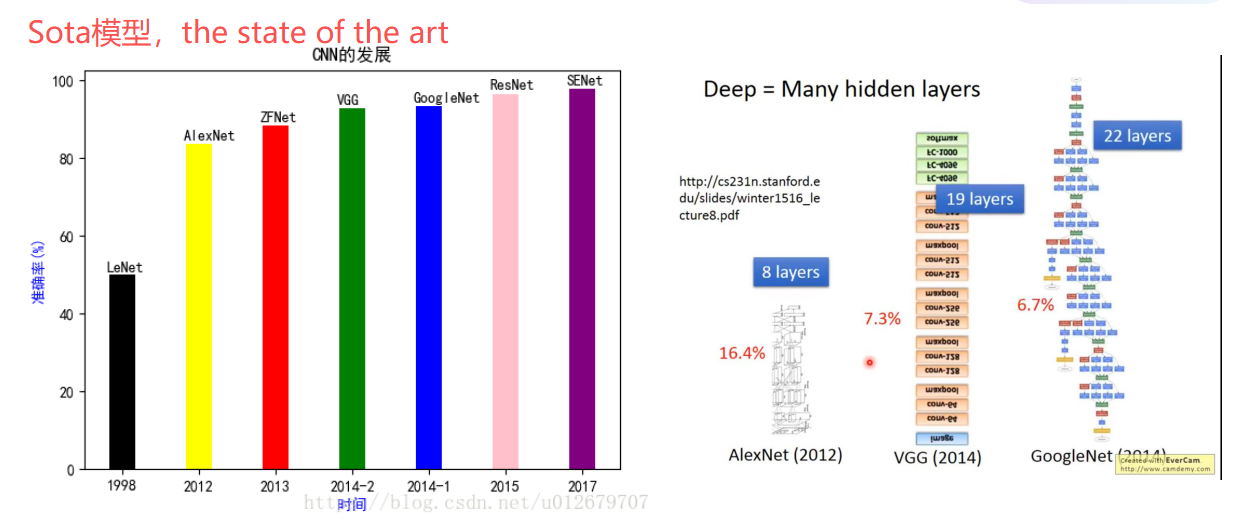
TOP5准确率是指,给5个类别,只要有1个对就对。相当于神经网络的骗局
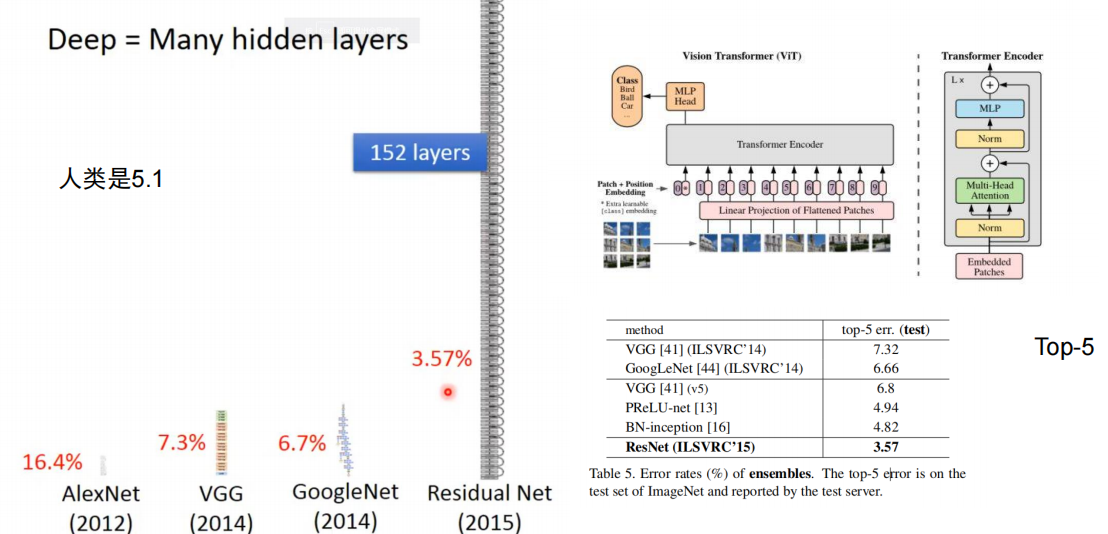
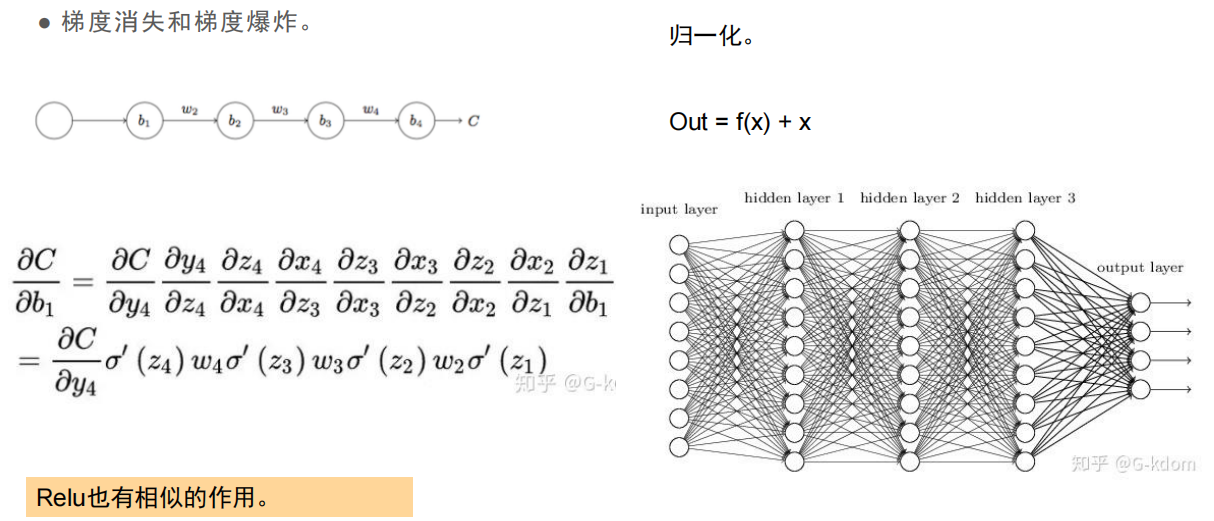
梯度太长了很多个数相乘,会产生梯度趋于0(消失)或非常大(爆炸)的现象
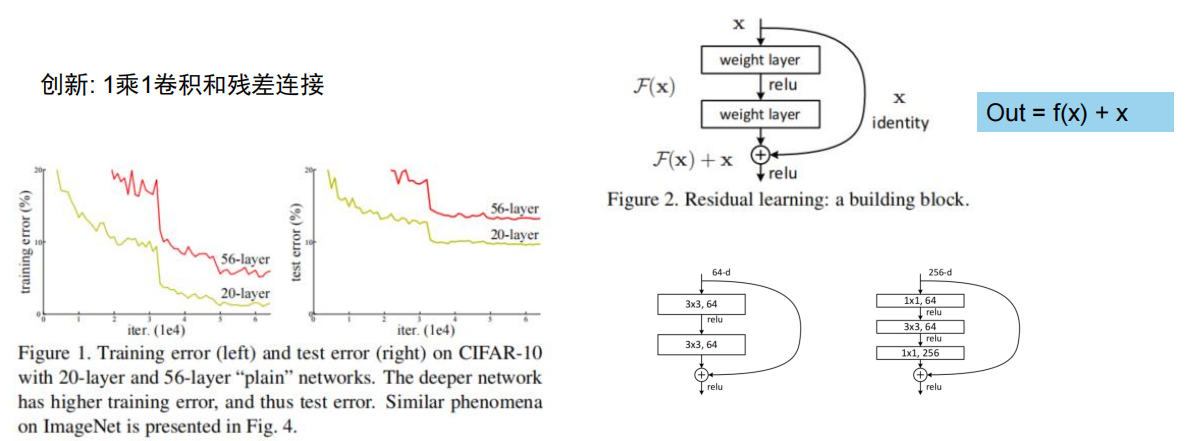
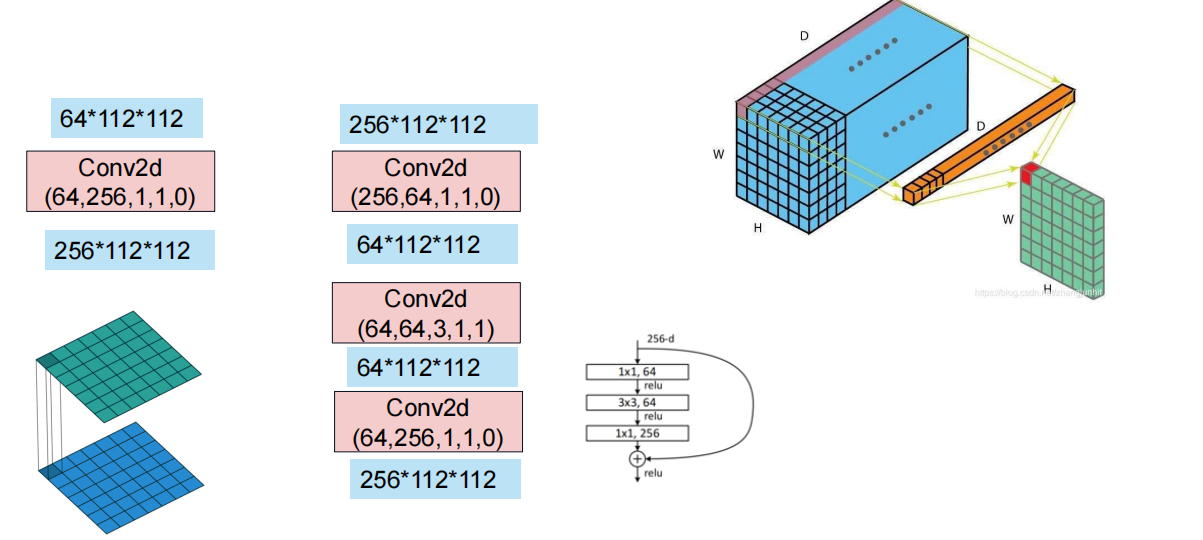
1×1卷积可以实现降维

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)