Transformer的算法原理和计算流程
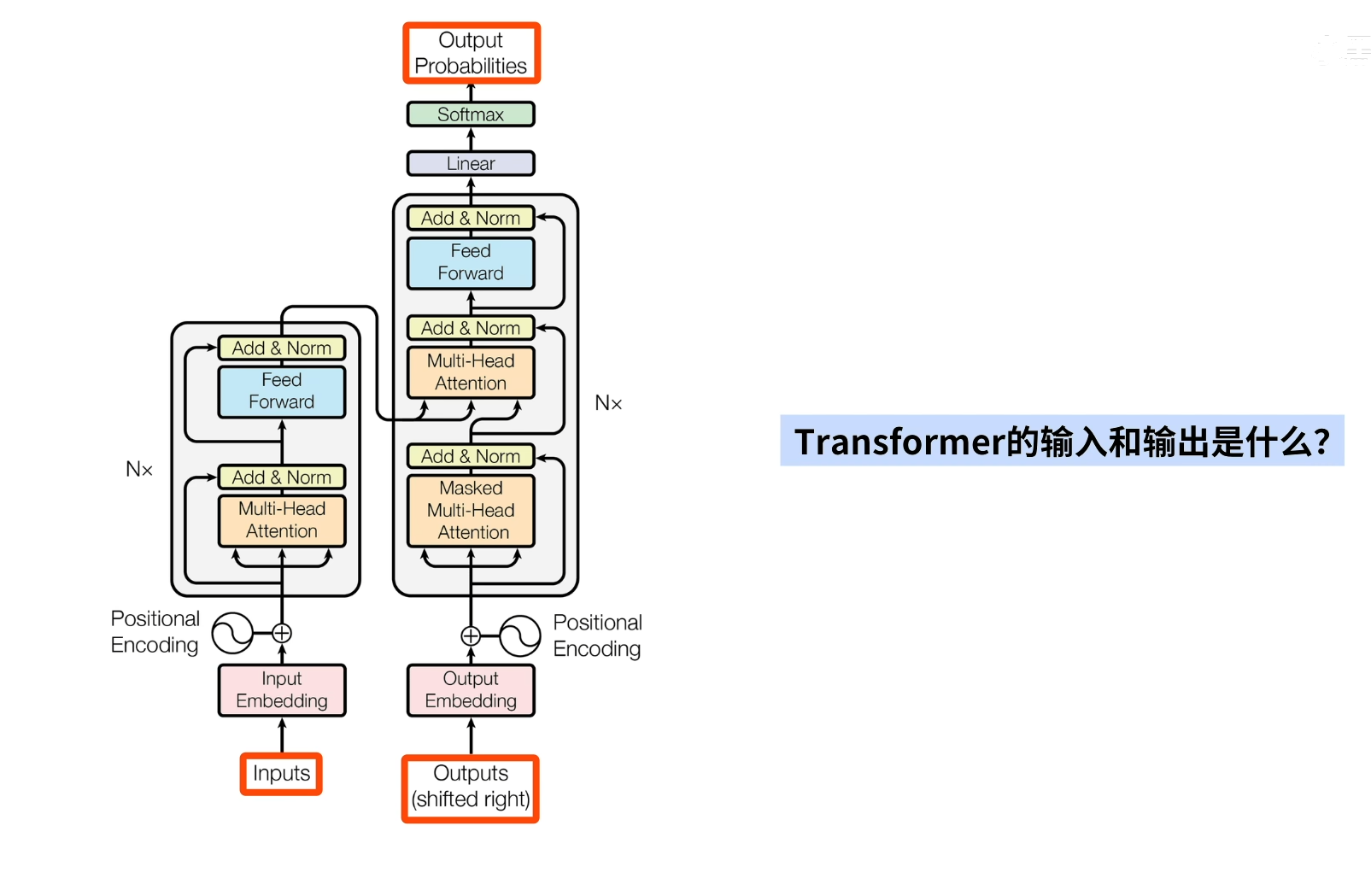
输入:inputs、outputs(shifted right)
输出:output probabilities
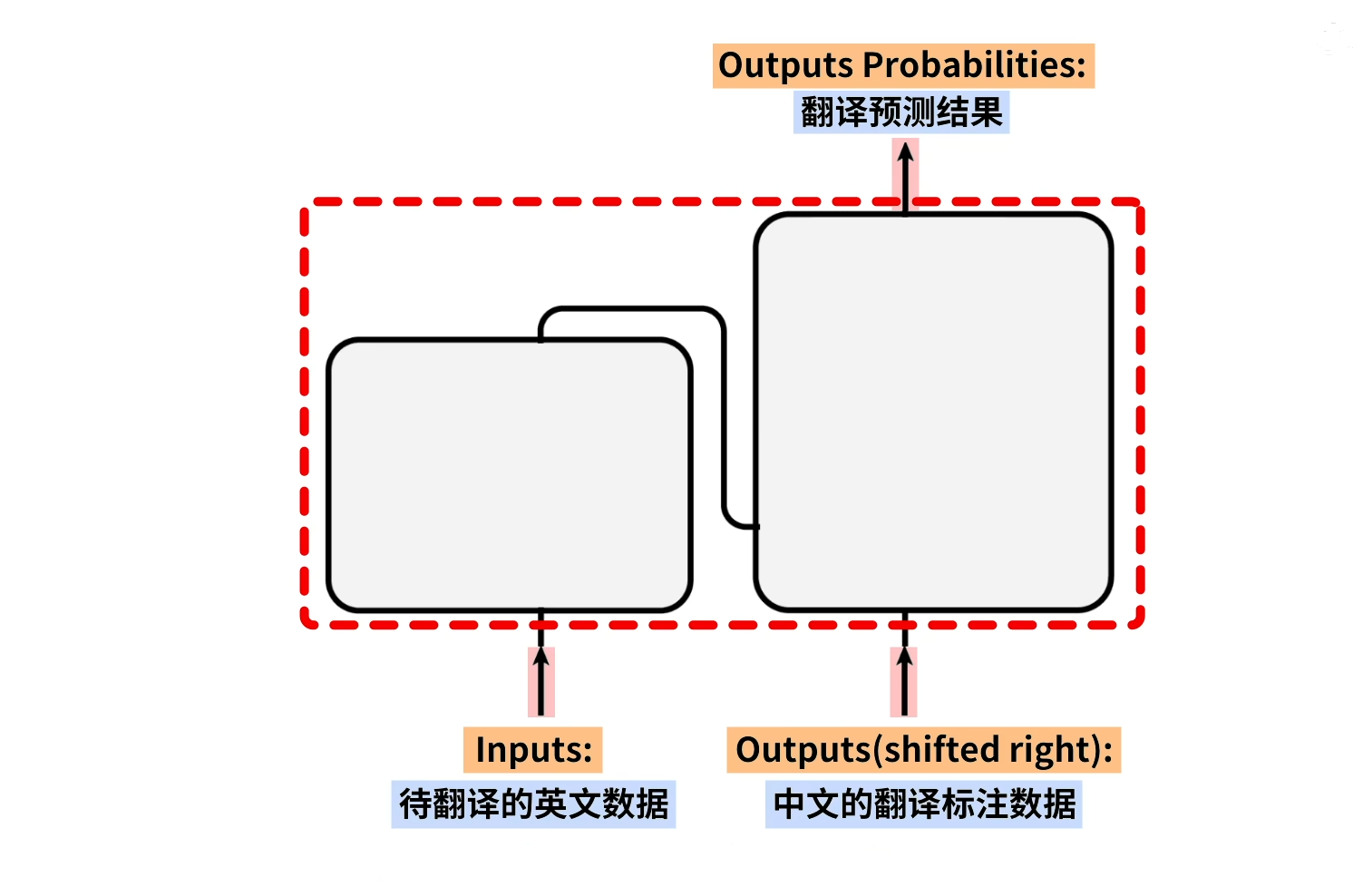
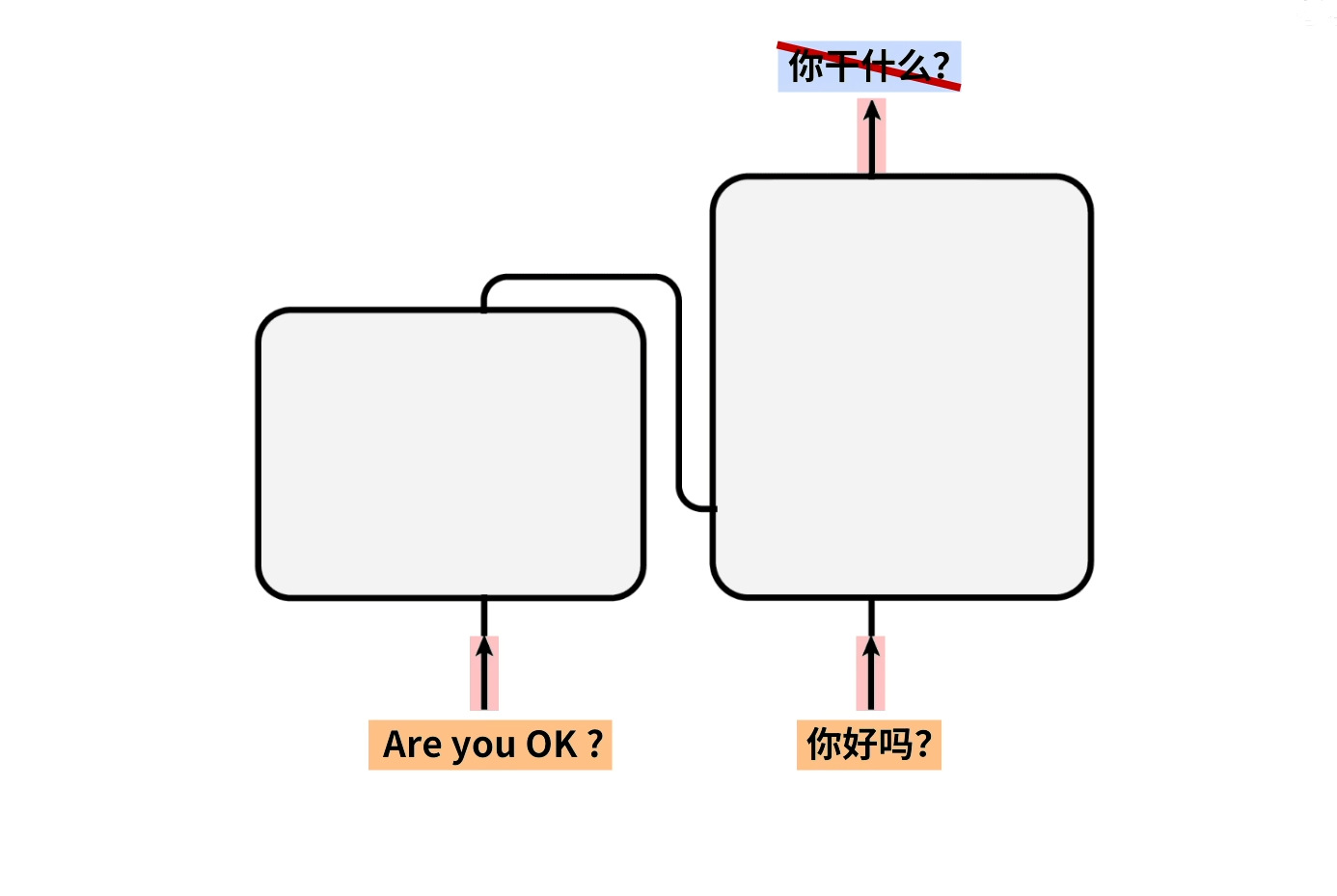
假设要翻译一个句子,这里inputs输入的就是待翻译的英文数据,outputs(shifted right)输入的就是中文翻译标注数据。然后outputs probabilities输出的便是翻译预测的结果(注意:这里的outputs probabilities是错误的代表模型实际的输出可能会和中文翻译标注数据有出入)。
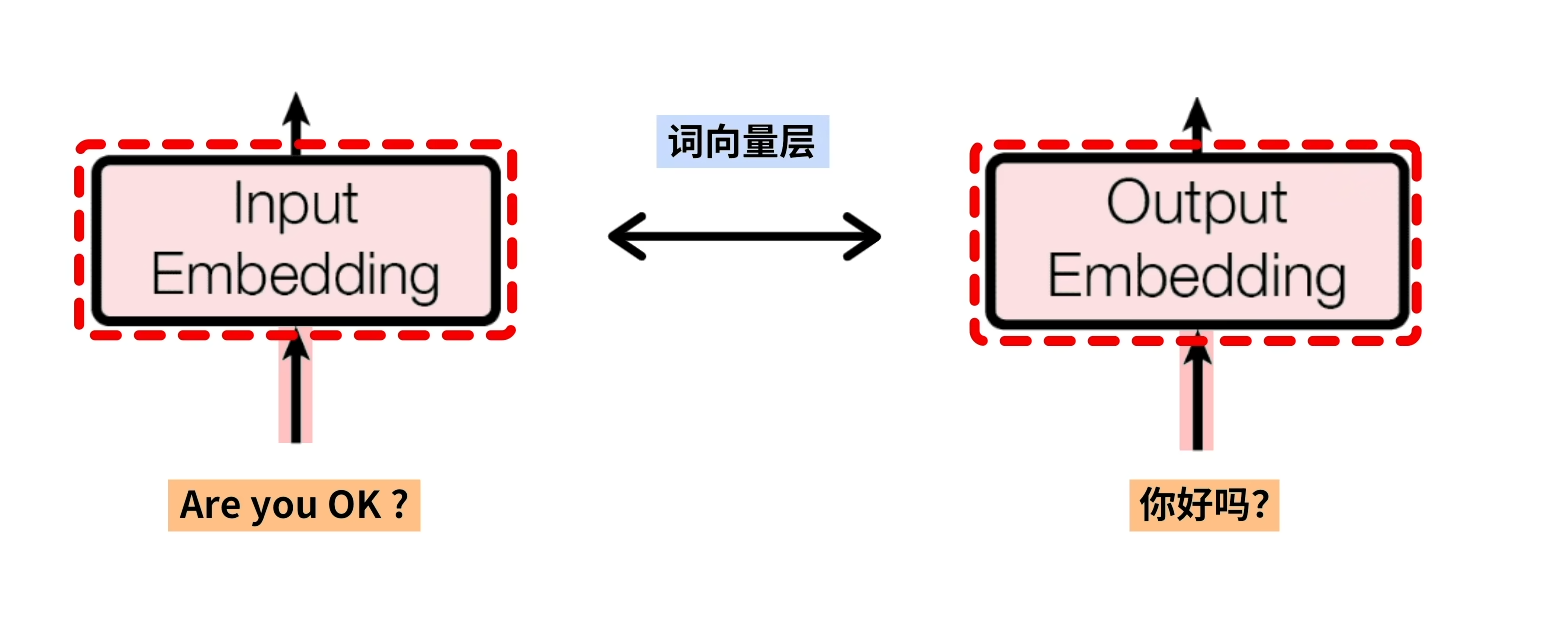
inputs和outputs(shifted right)输入的数据会被词向量层处理
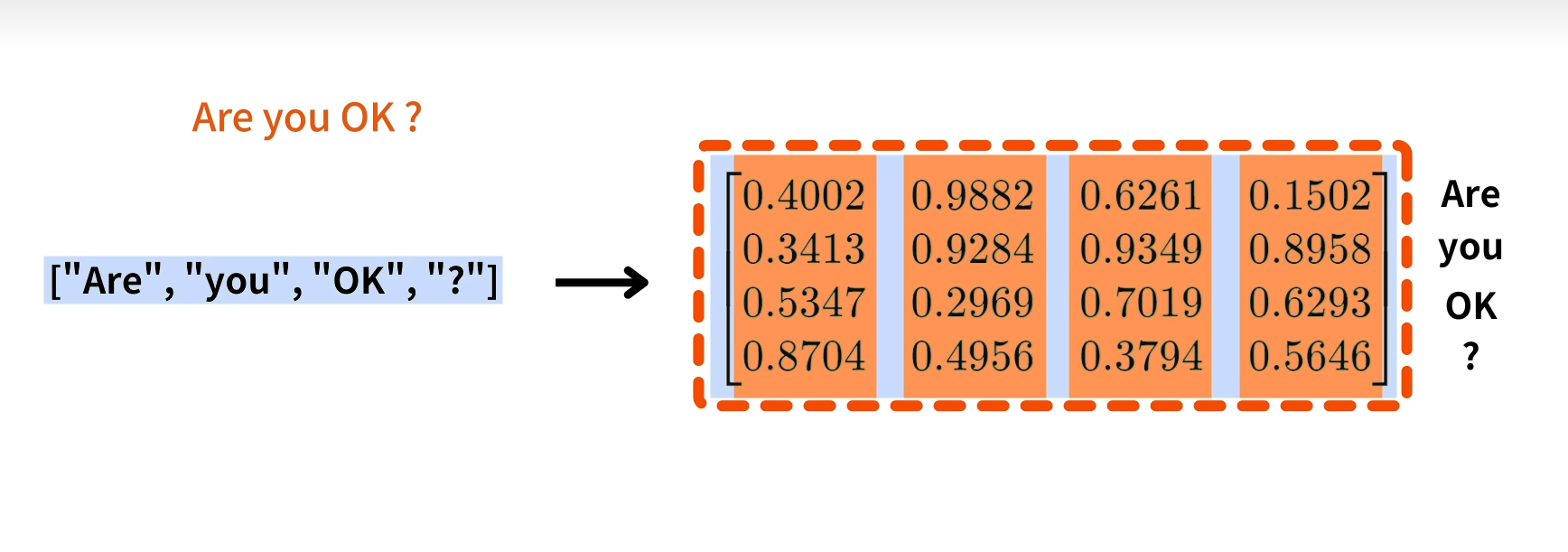
这里inputs的”Are you OK?“被转化成为一个4x4的矩阵,每一行代表一个单词。
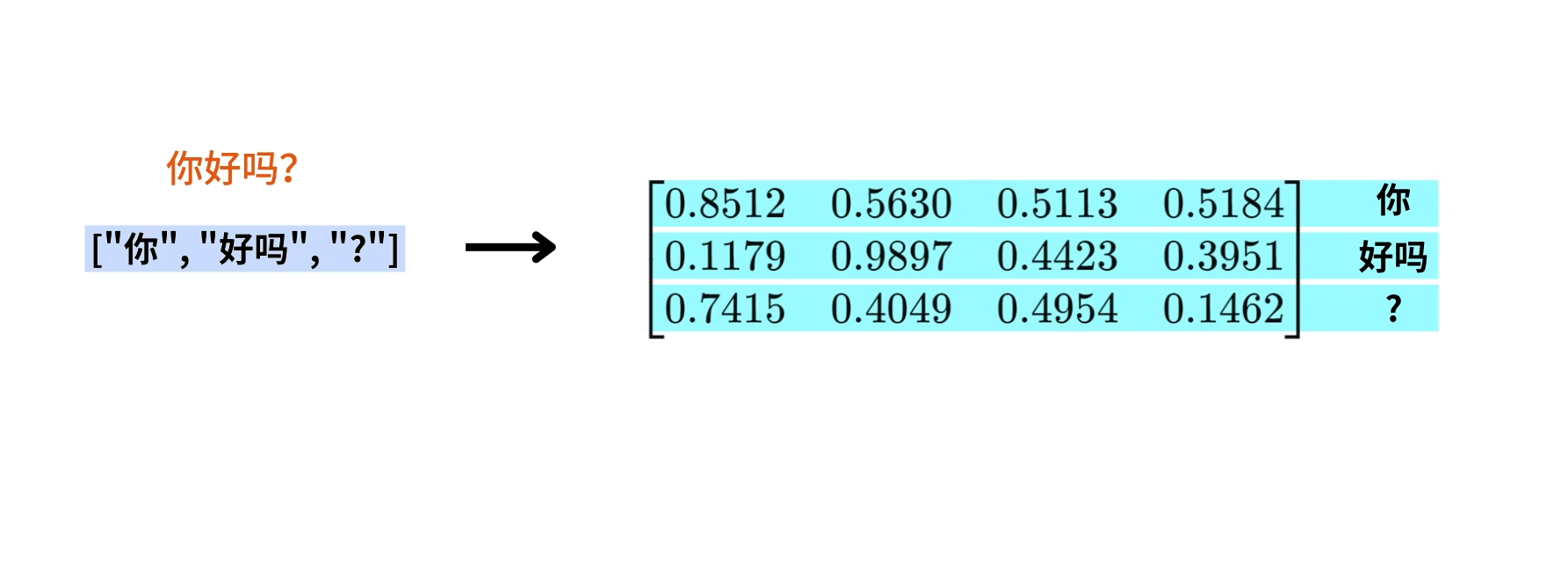
相同的,outputs(shifted right)的”你好吗?“也会被转化为向量。
positional encoding
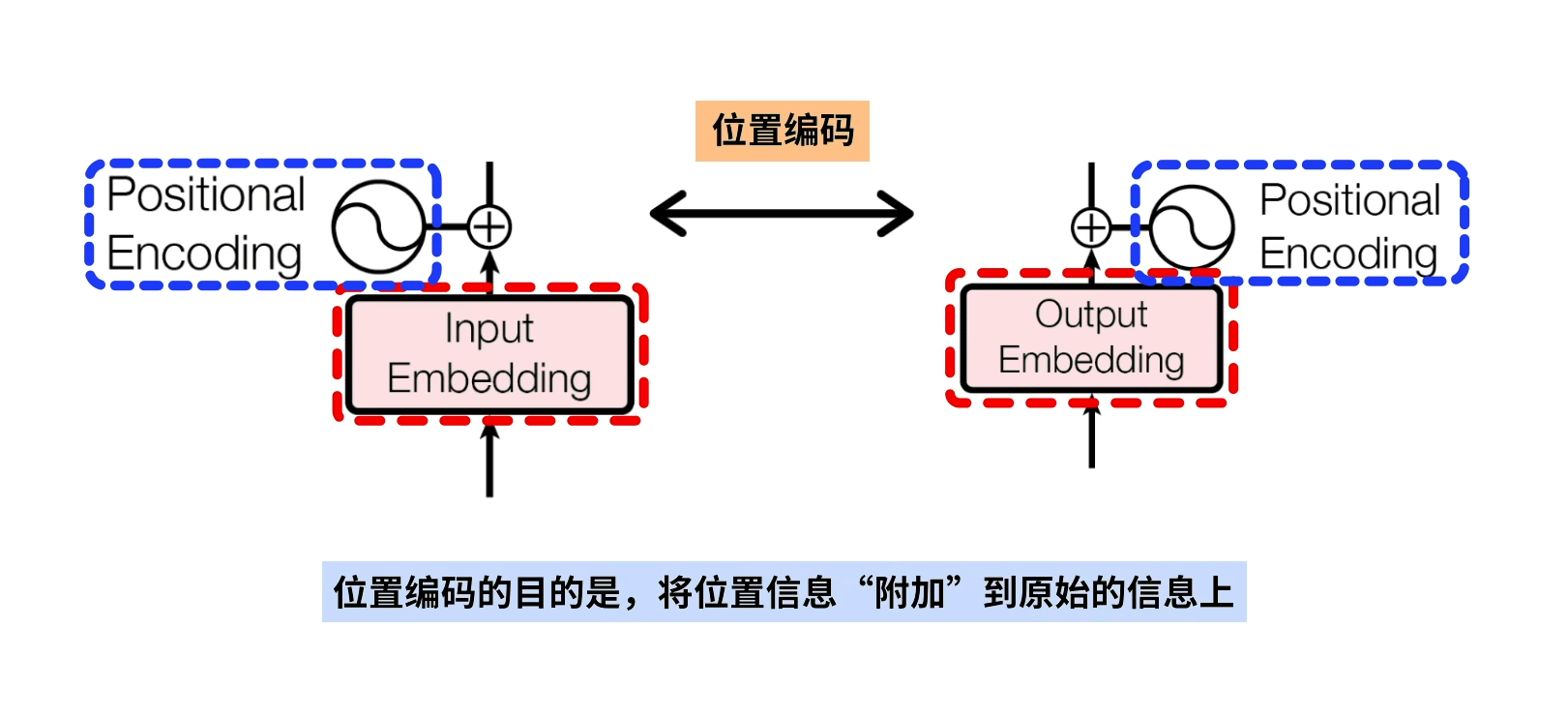
如图所示,这就是positional encoding干的事情,embedding之后每个词会转化为他所对应的哪些向量,然后各个词(向量)的位置信息靠positional encoding完成。
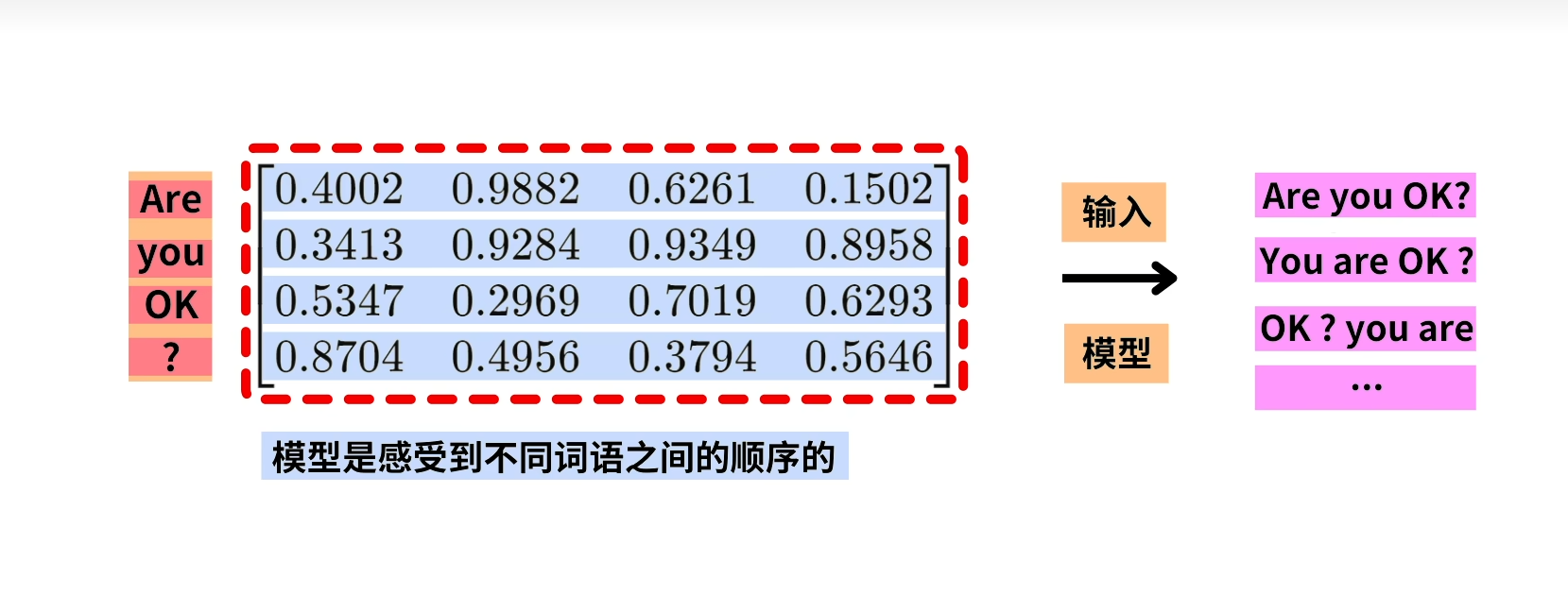
模型感受不到不同词语之间的顺序的,所以可能会被理解成 ok?you are等。所以positional encoding 才显得有他的重要之处。
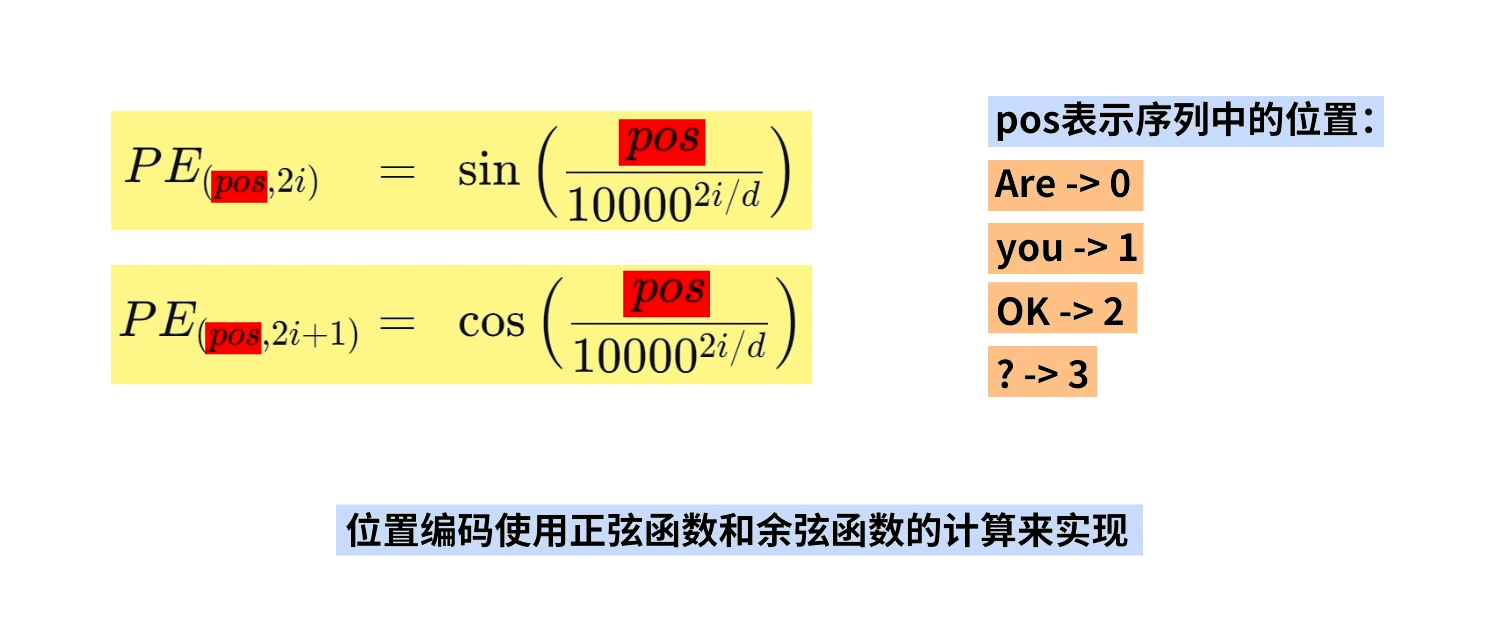
在Transformer模型中,位置编码(Positional Encoding)用于为模型提供序列中各元素的位置信息。由于Transformer缺乏处理序列顺序的内在机制,位置编码显得尤为重要。
使用正弦和余弦函数来计算位置编码具有以下优势:
- 唯一性和区分性:正弦和余弦函数的不同频率确保了每个位置的编码在各维度上都是唯一的,从而使模型能够区分不同位置的元素。 (blog.csdn.net)
- 平滑性和连续性:正弦和余弦函数的平滑变化使得相邻位置的编码在数值上变化平缓,有助于模型捕捉相邻元素之间的关系。 (blog.csdn.net)
- 周期性:正弦和余弦函数的周期性特性使得位置编码在不同长度的序列中具有一致性,避免了随着序列长度增加而导致的编码值过大或过小的问题。 (cnblogs.com)
综上所述,正弦和余弦函数的这些特性使其成为计算位置编码的理想选择,帮助Transformer模型有效地理解和处理序列数据中的位置信息。
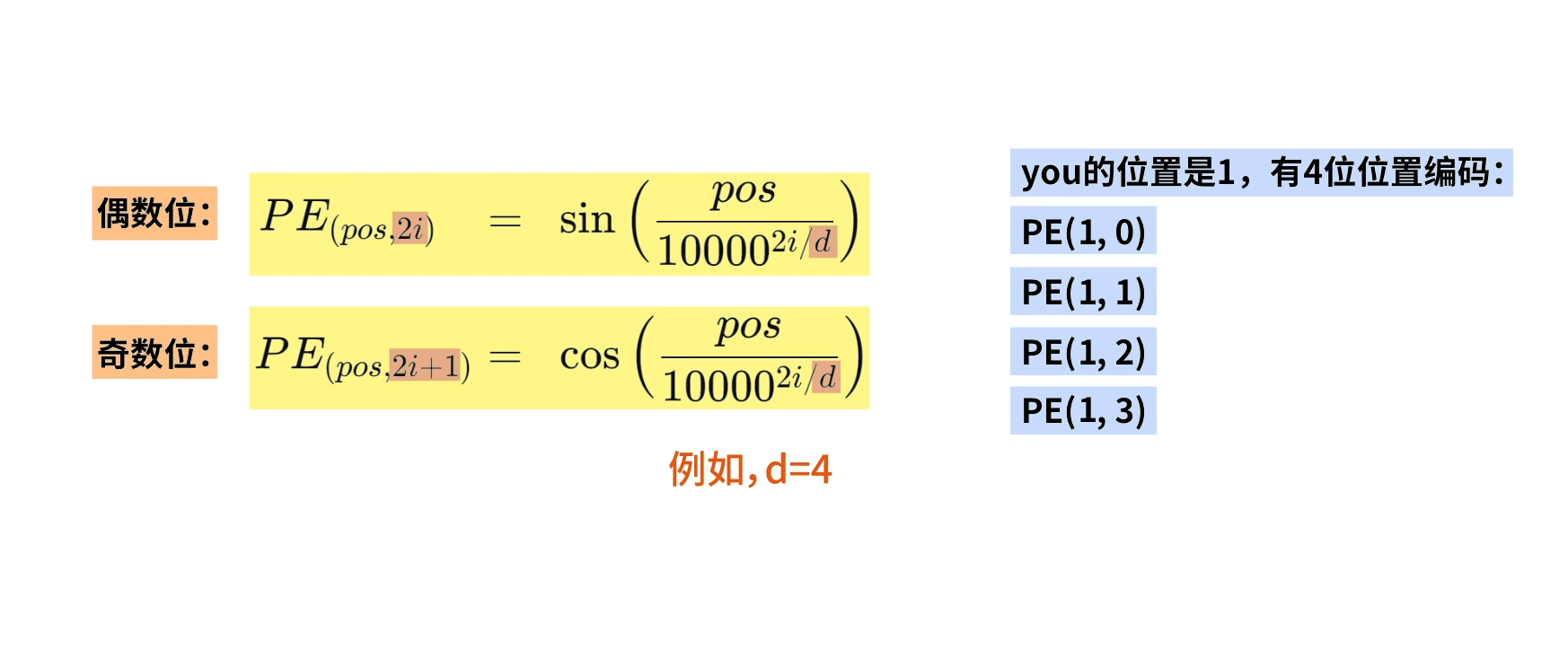
2i代表偶数维度,2i+1代表奇数维度。d代表总维度。
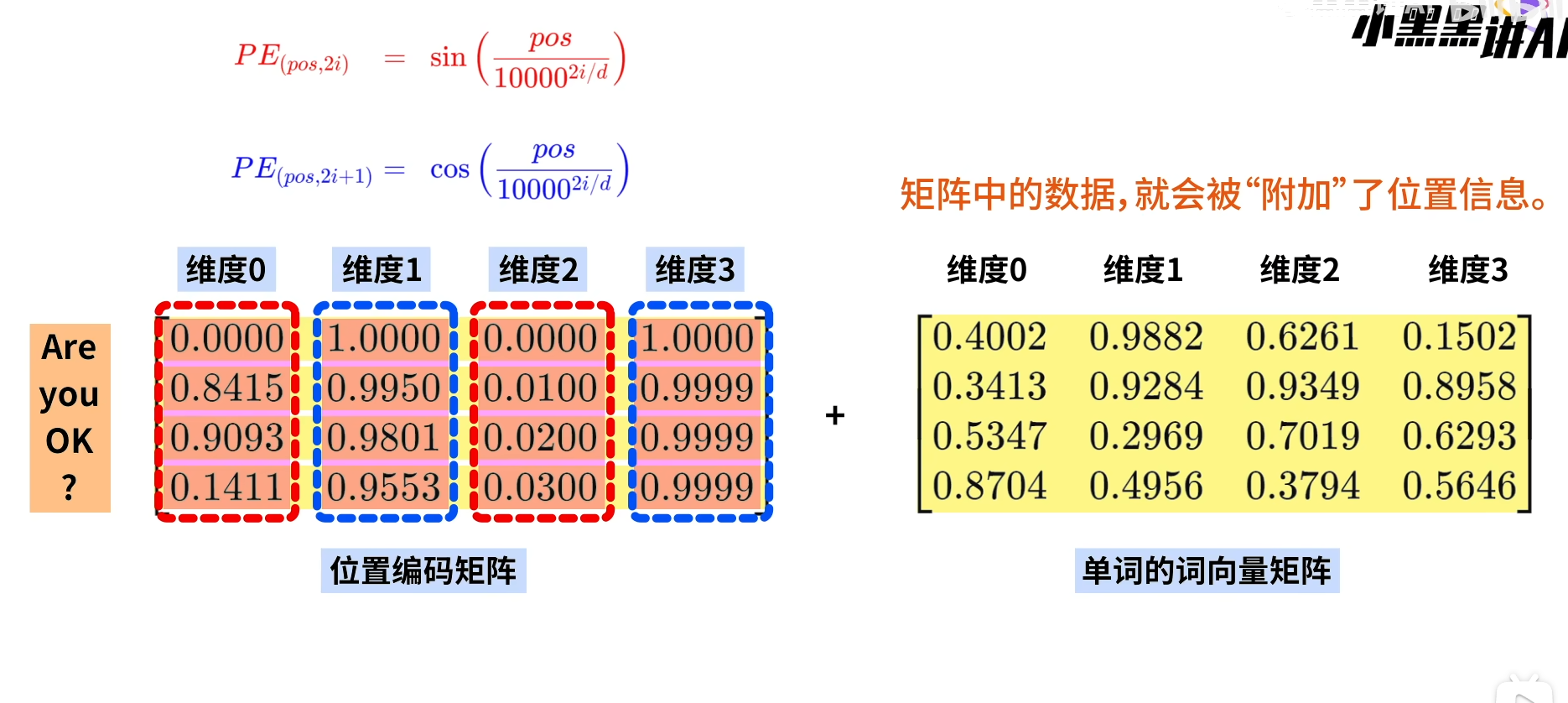
可见生成的位置编码矩阵加上单词的词向量矩阵,就会让原来单词的词向量矩阵附加上位置信息。
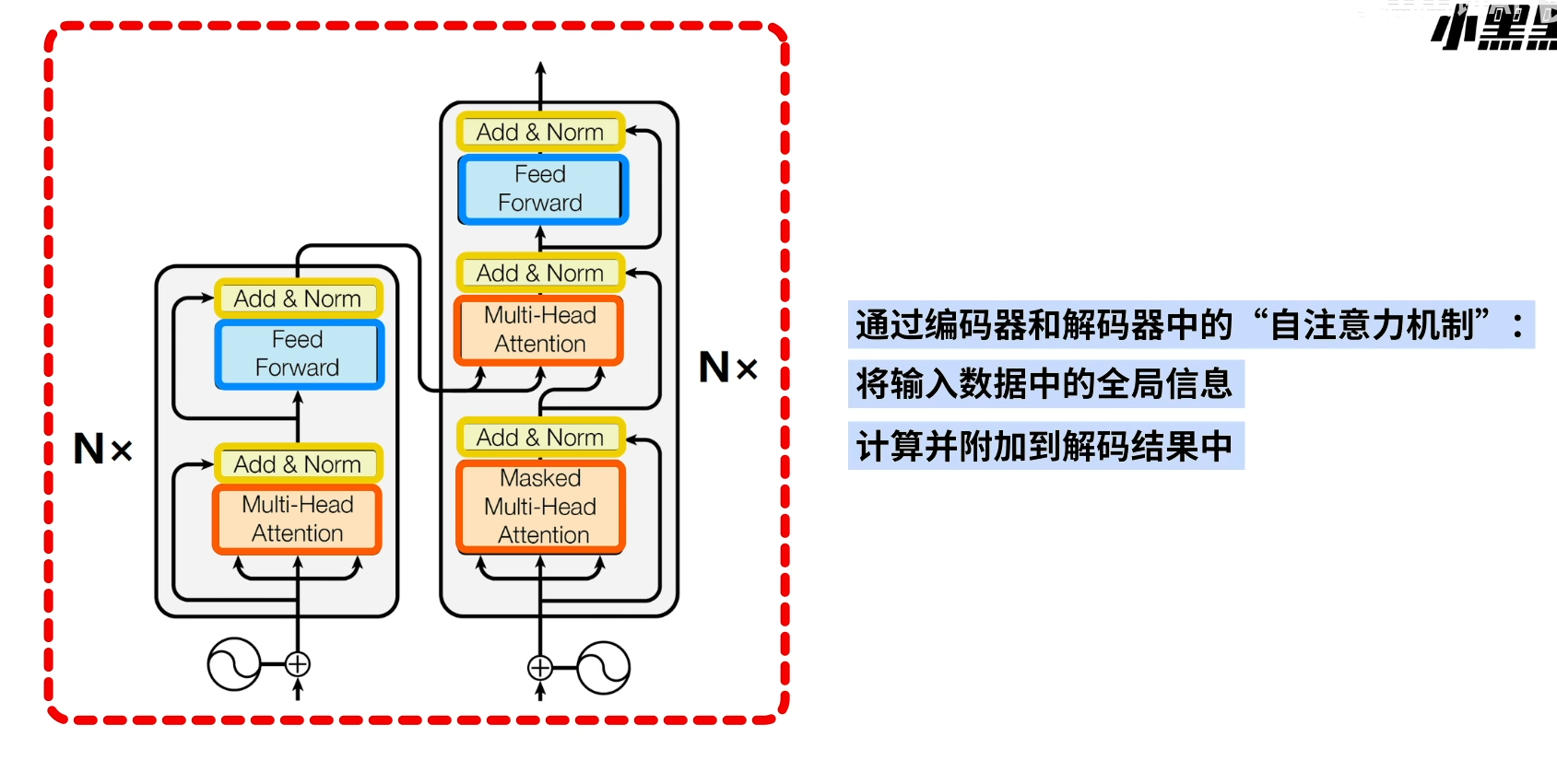
编码器与解码器
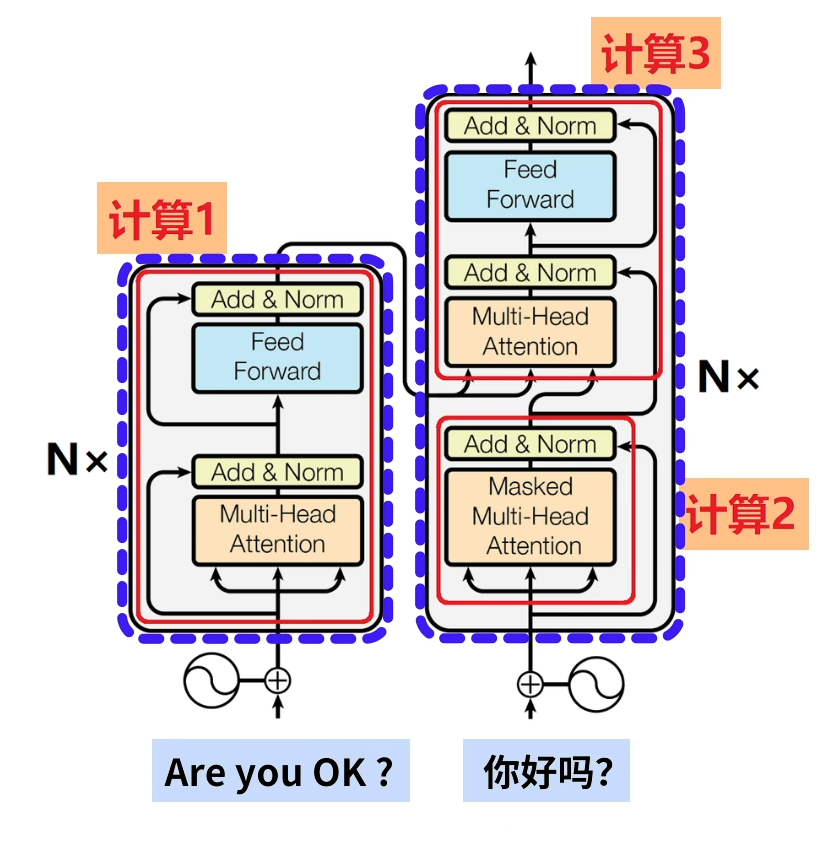
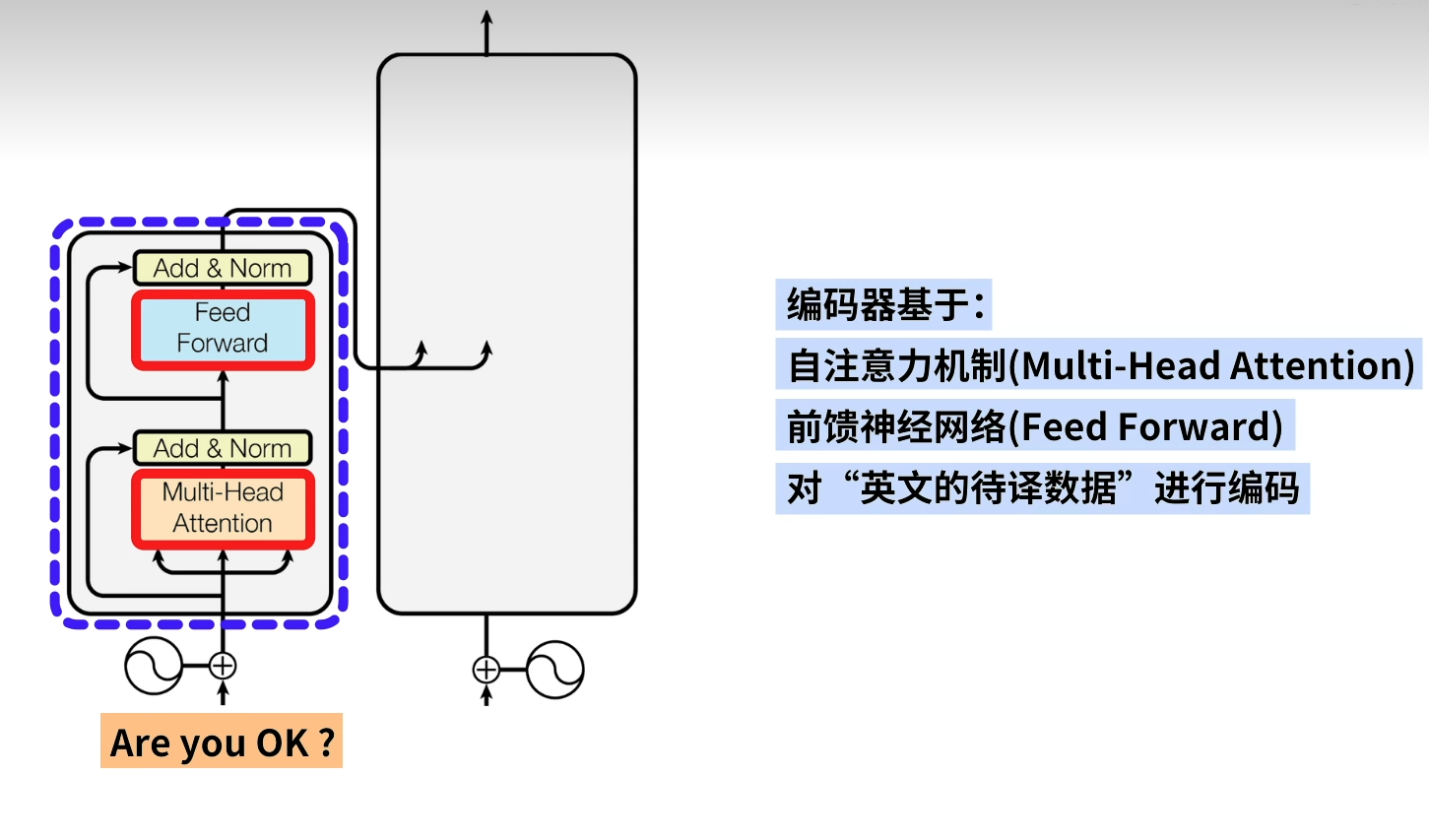
计算1主要的作用如上图所示
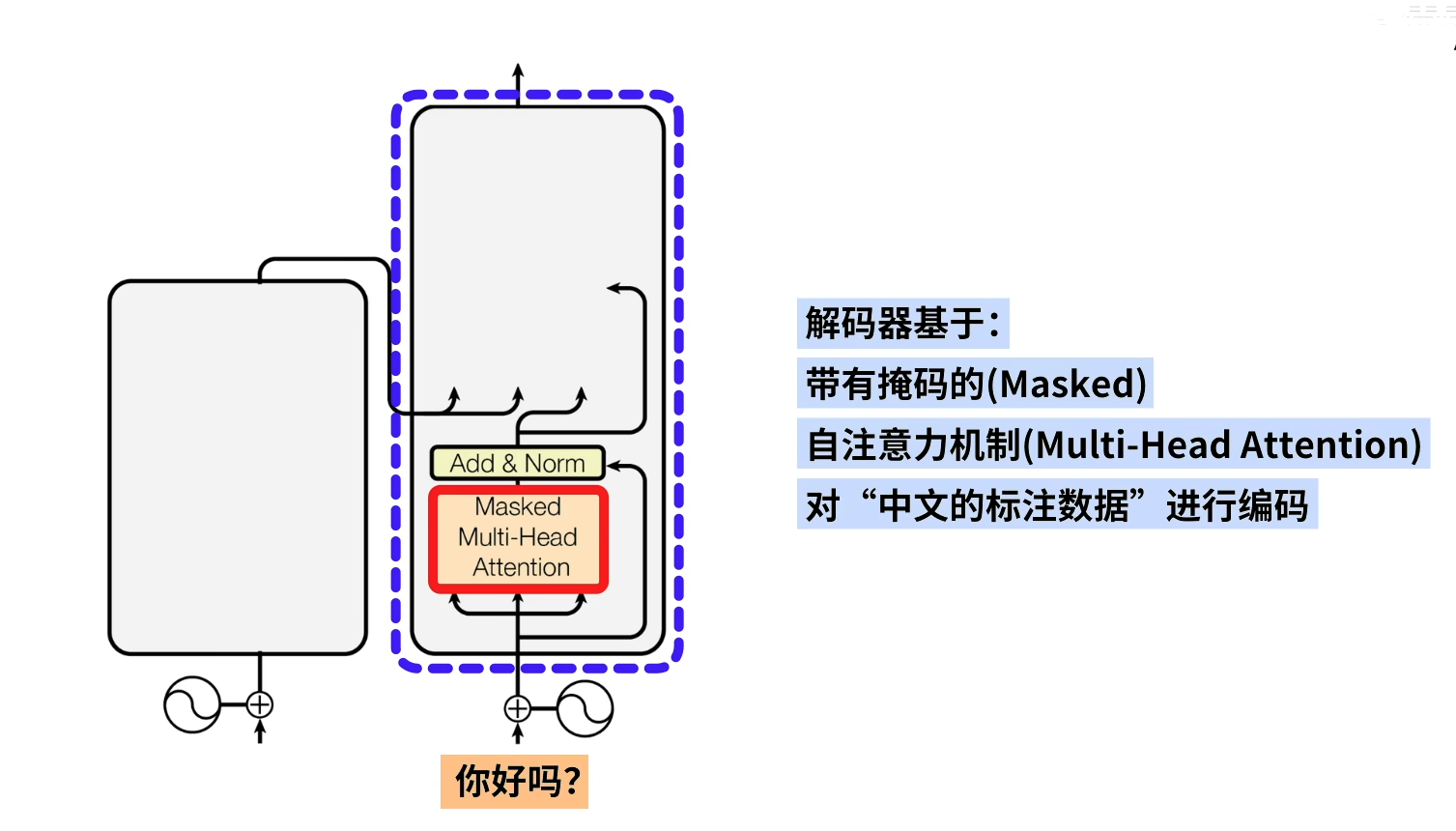
计算2主要的作用如上图所示
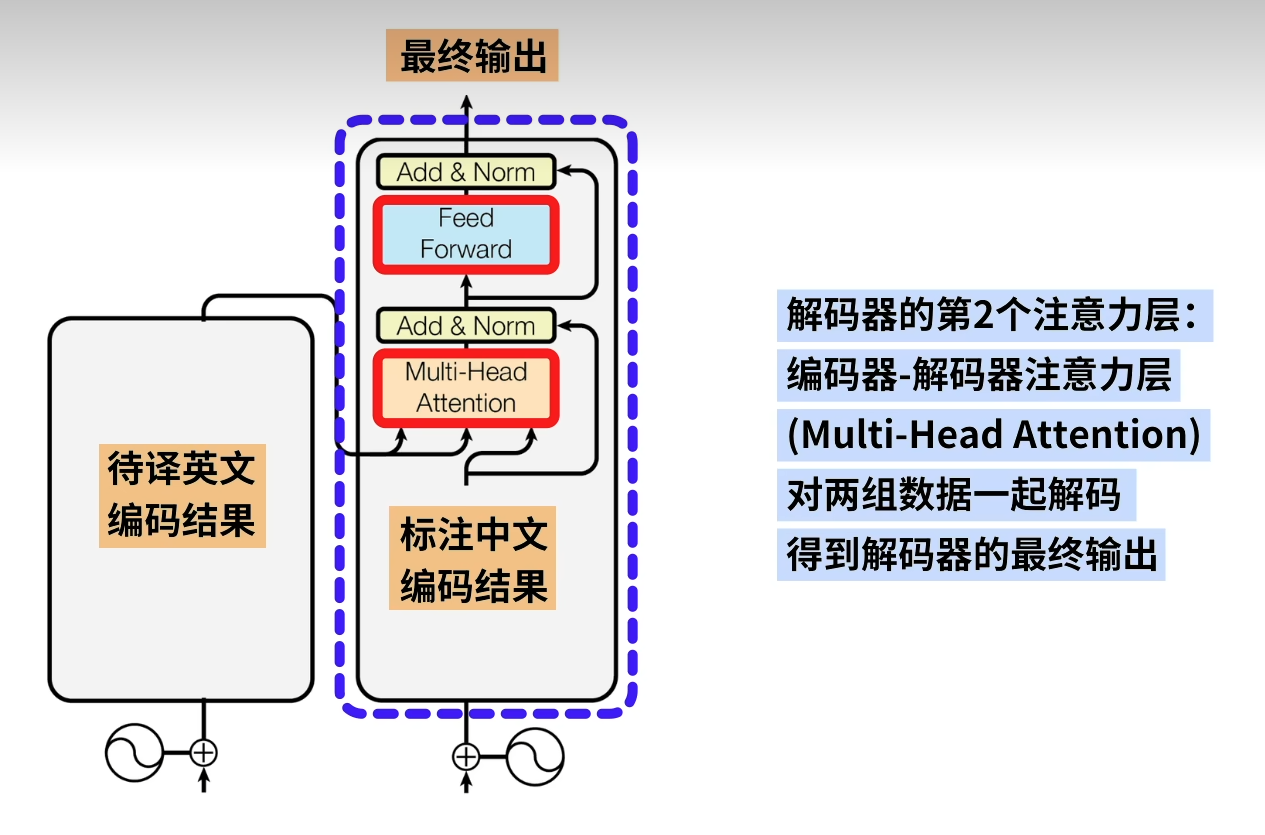
计算3主要的作用如上图所示
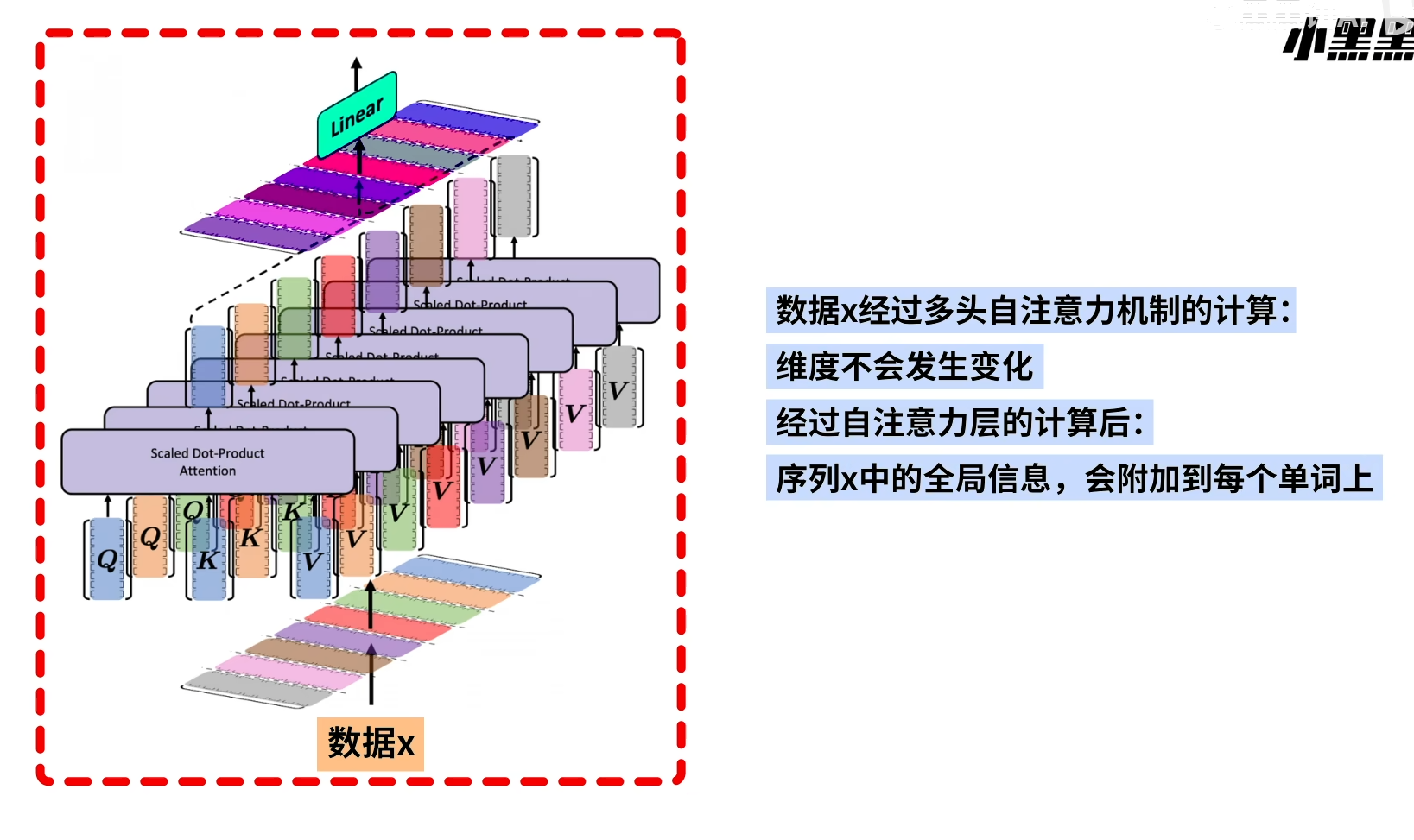
多头注意力机制(muti head self attention)
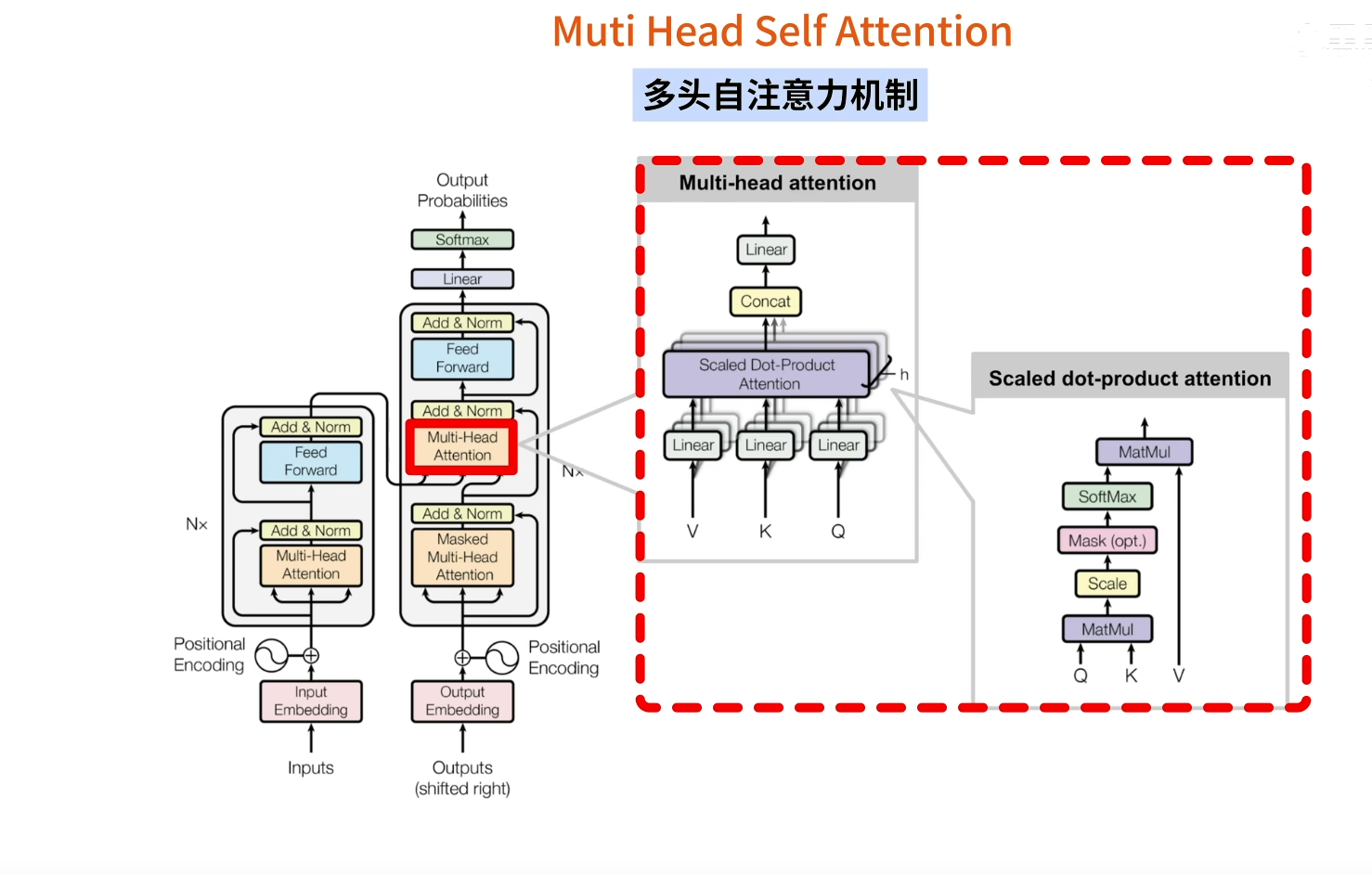
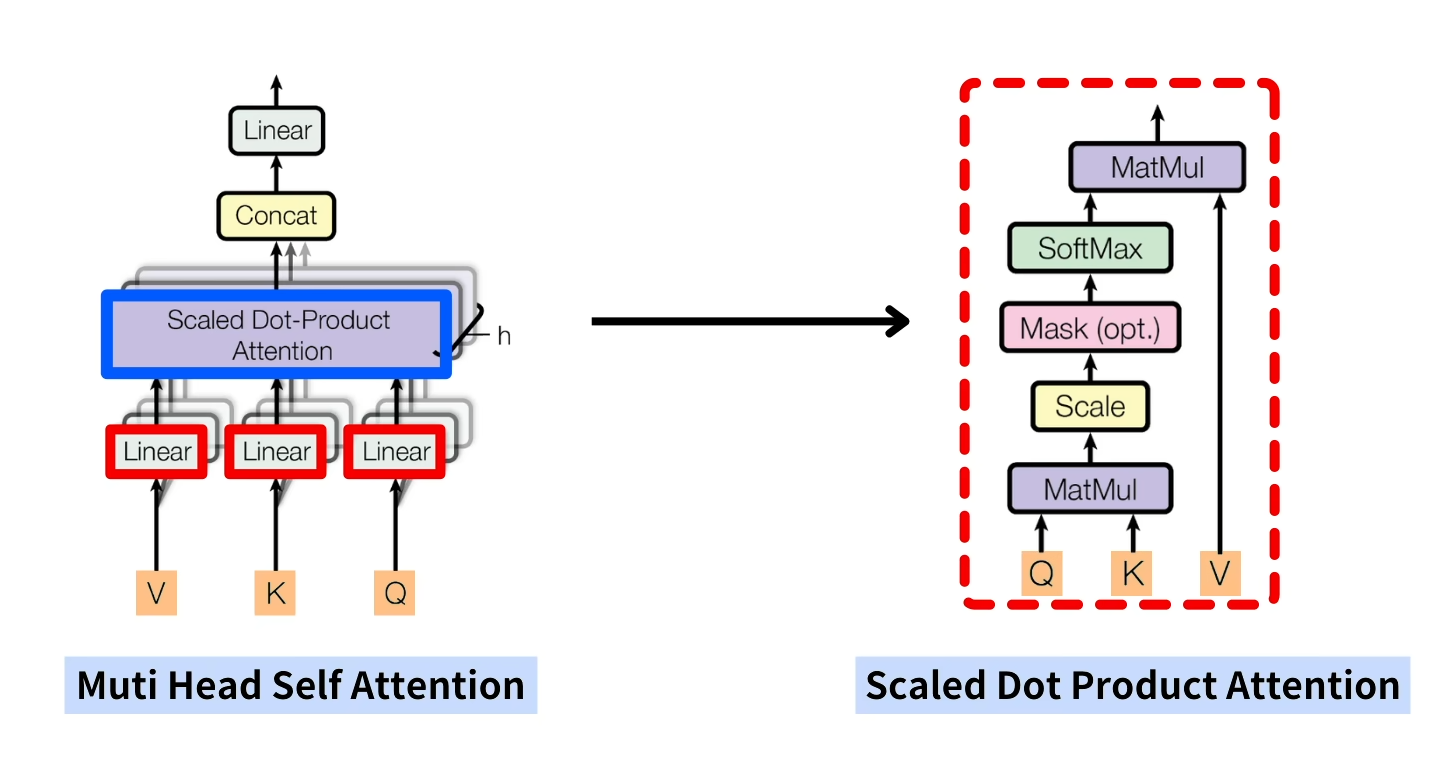
对Q K V进行特征变化,然后用Scaled Dot Product Attention 对特征变换之后的Q K V进行组合
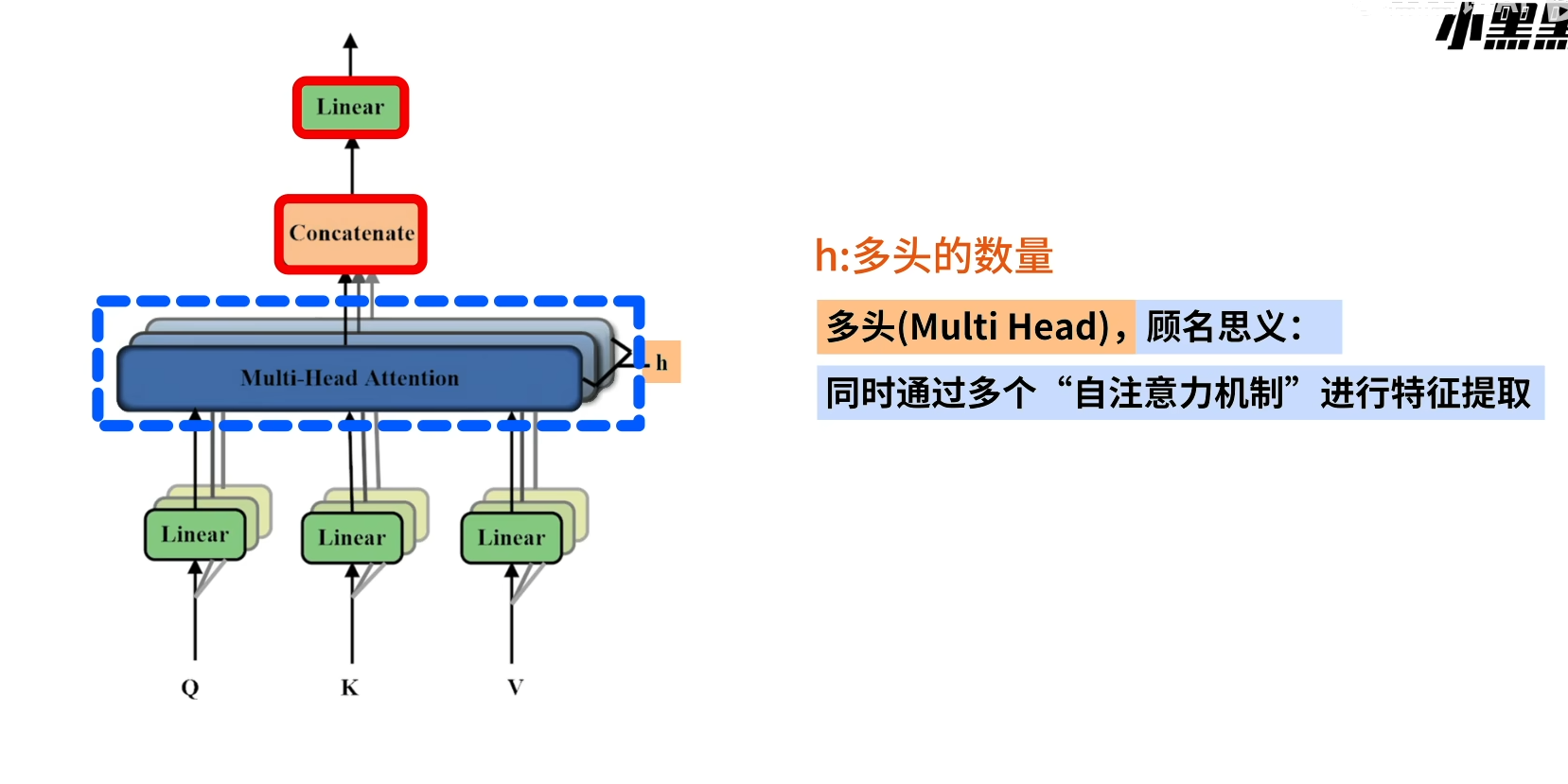
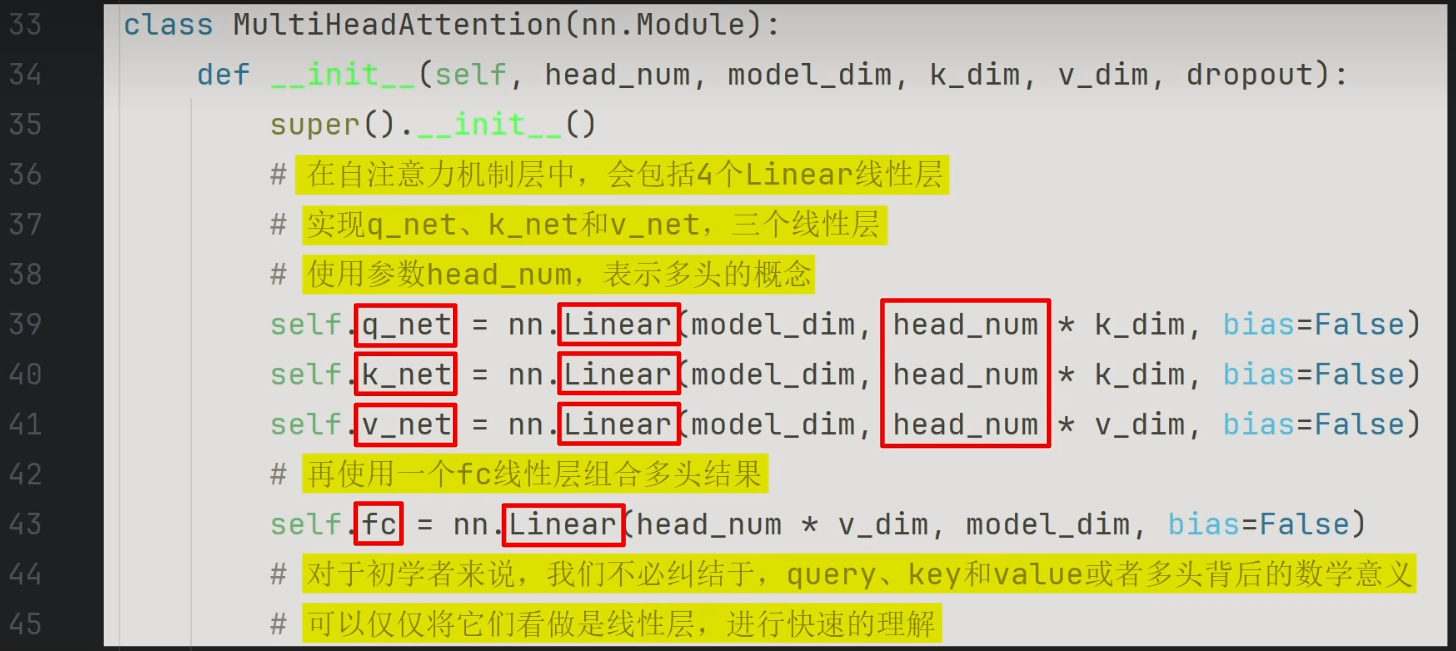
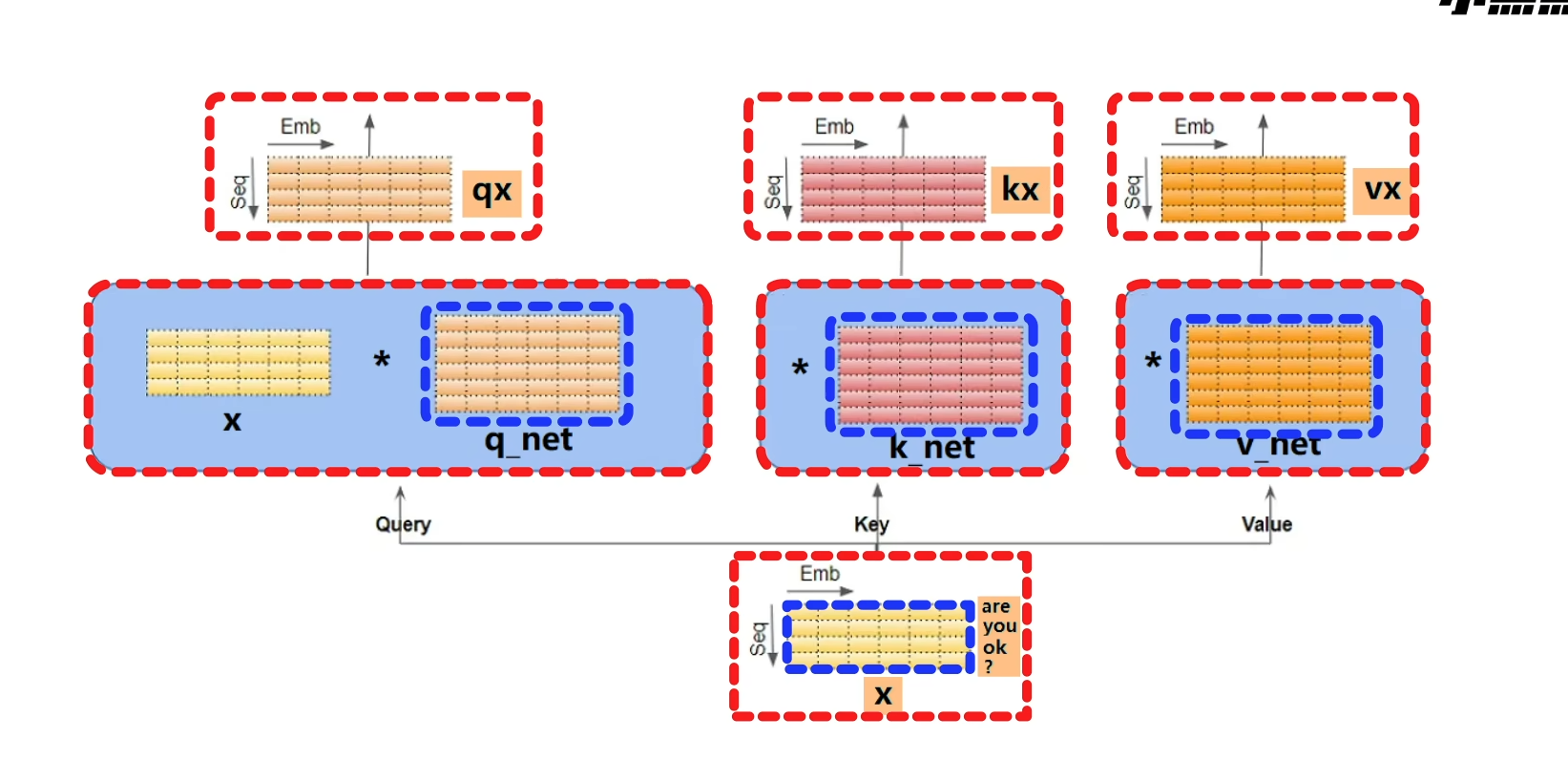
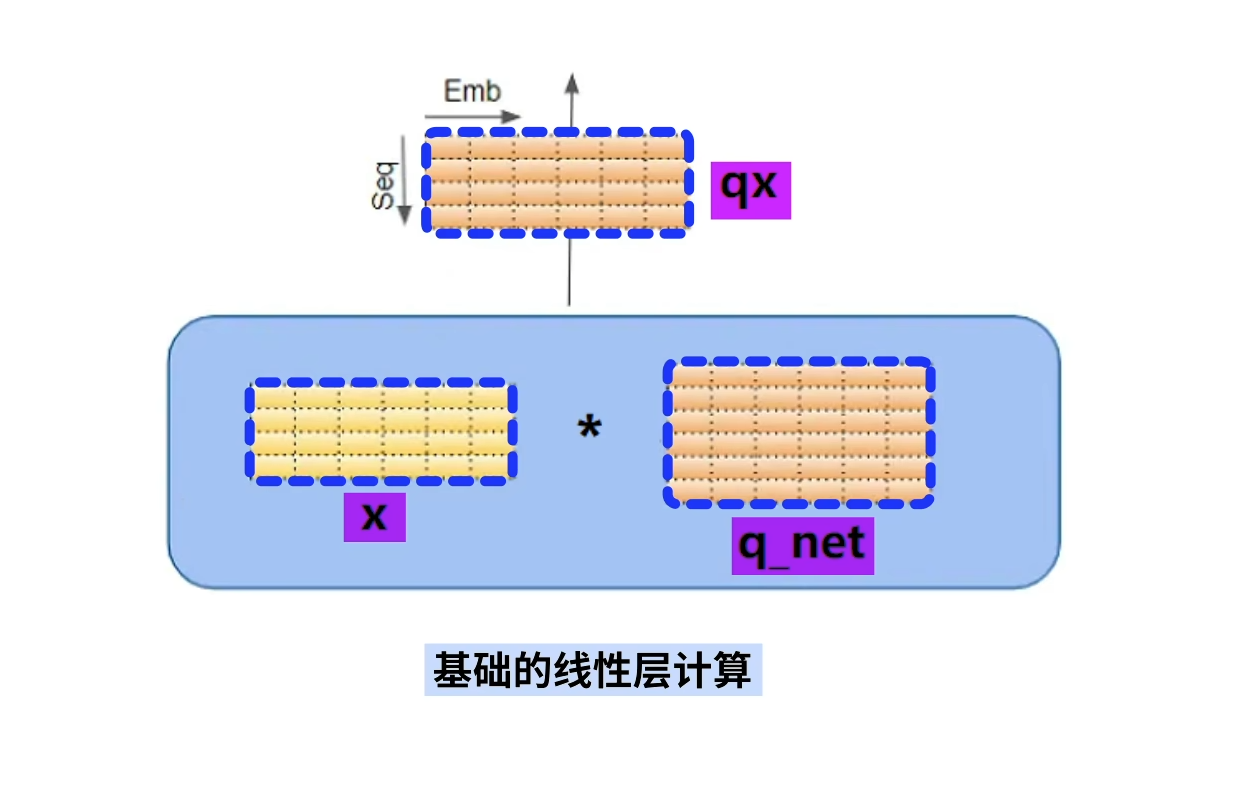
x与三个线性层进行线性计算得到三组结果

带入这个公式中得到一个最终的注意力结果,这就是softmax的作用。
最后通过linear层将注意力结果进行合并输出。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)