Google 把时间序列预测玩成了大模型——TimesFM 深度解析
Google 把时间序列预测玩成了大模型——TimesFM 深度解析
时间序列预测这个领域,终于也迎来了属于自己的"GPT 时刻"。
先说结论:这玩意儿能直接用,不用训练
传统的深度学习预测模型,上手之前得先经历一套折磨流程:收集数据、清洗、调参、训练、验证……光是跑通一个新数据集就能让人头大半天。
Google Research 这次发布的 TimesFM,直接把这套流程砍掉了——扔进去数据,开箱出预测结果,零训练,就这么简单。
这篇论文《A decoder-only foundation model for time-series forecasting》已被 ICML 2024 接收,模型也已同步上线 HuggingFace 和 GitHub,最新版本已经更新到 TimesFM 2.5。
架构设计:从 LLM 里抄的作业,但抄得很聪明
TimesFM 的核心思路,是把 LLM 的 decoder-only 架构直接搬到时间序列预测上来。
LLM 的做法大家都熟悉:把文本拆成 token,喂进堆叠的因果 Transformer 层,每个 token 的输出用来预测下一个 token。问"法国的首都是哪里",模型一个词一个词往外蹦,最后拼出"法国的首都是巴黎"。
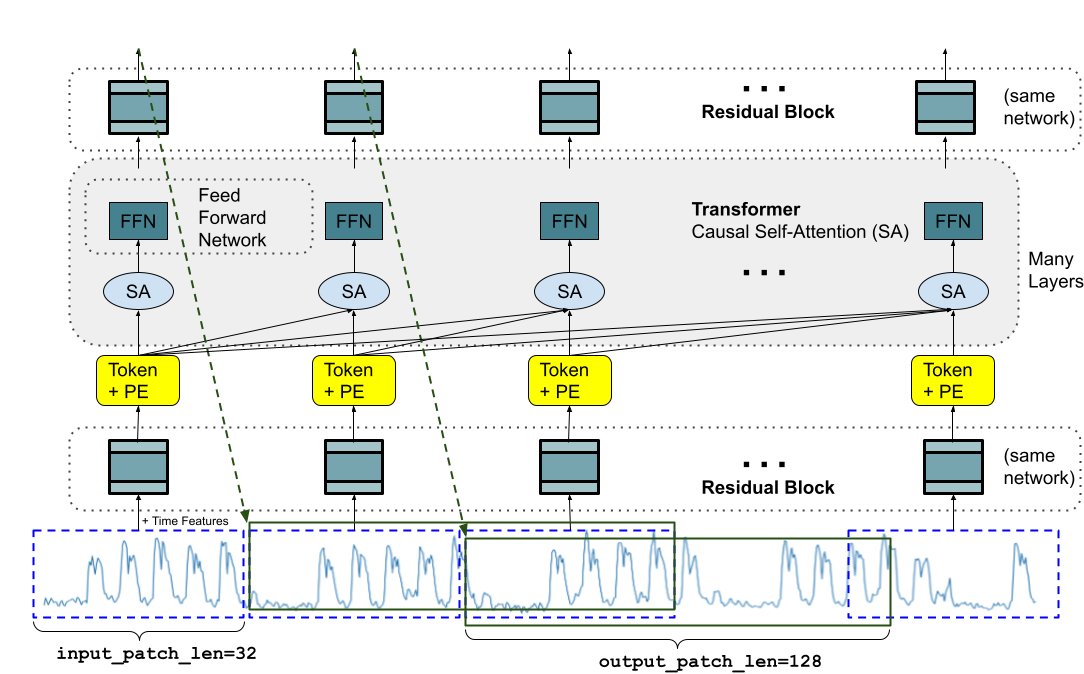
TimesFM 做了一个类似的事:把一段连续时间点打包成一个 patch(块),作为模型的输入单元。然后用前面若干个 patch 的信息,预测下一段时间窗口的走势。
但跟语言模型比,还是有几处关键差异值得关注:
输入端:原始时间序列数值没法直接扔进 Transformer,需要先过一个带残差连接的 MLP,把 patch 转换成 token 向量,再加上位置编码。
输出端:这里有个设计亮点——输出 patch 的长度可以大于输入 patch 的长度。比如输入是 32 个时间点,输出可以直接预测未来 128 个时间点。这样每次生成步骤覆盖的范围更大,累积误差更少,长期预测效果也更好。举个具体例子:给模型 256 个时间点,让它预测未来 256 步,如果输出 patch 是 128,只需要 2 步就能生成完整预测;如果输出 patch 跟输入一样是 32,就得跑 8 步,误差滚雪球的风险大多了。
预训练数据:1000 亿个真实时间点怎么来的
模型能泛化,数据是根本。TimesFM 的预训练语料下了很大功夫。
合成数据打底:用统计模型和物理仿真生成一批合成时间序列,让模型先学会时序数据的基本规律——周期性、趋势、噪声这些"语法"。
真实数据上量:从公开数据集里精挑细选,最终拼出了 1000 亿个真实世界时间点。其中 Google Trends 搜索热度数据和 Wikipedia 页面访问量数据占了大头——这两类数据天然包含了人类行为在时间维度上的各种模式,和零售、金融、交通等领域的时序规律有很强的共鸣,泛化能力因此大幅提升。
测评结果:零样本打赢有监督模型
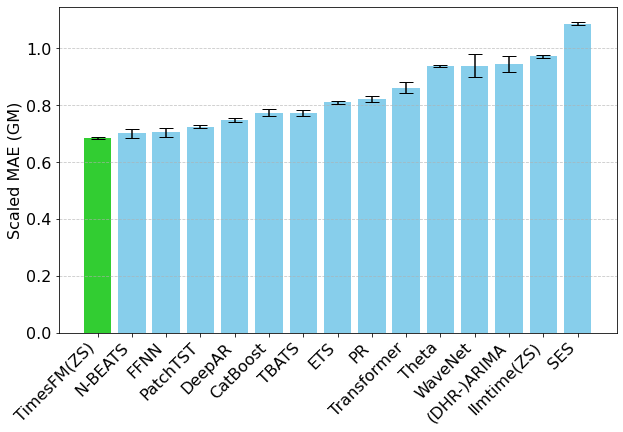
评估用的是 Monash Forecasting Archive,里面涵盖了交通、天气、需求预测等多个领域,频率从几分钟到年度数据都有,规模很全面。
结果挺出乎意料:TimesFM 零样本(ZS)下的表现,直接超过了 ARIMA、ETS 这些经典统计方法,还能跟 DeepAR、PatchTST 这类在目标数据集上专门训练过的深度学习模型掰手腕。更有意思的是,拿它跟 GPT-3.5 用 llmtime 提示词做预测的结果比,TimesFM 赢了,而且参数量小了几个数量级。
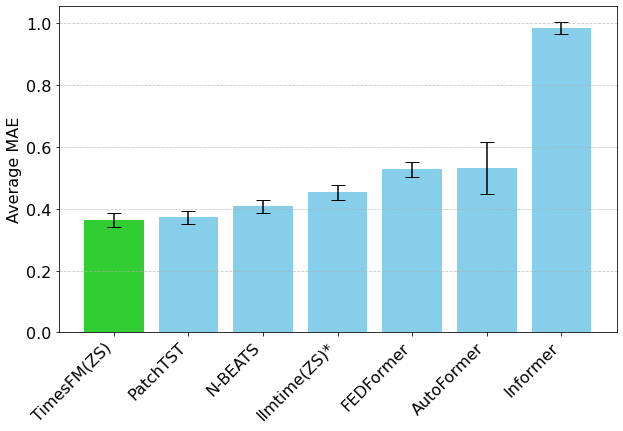
长期预测的表现同样不虚。在 ETT 数据集上预测未来 96 和 192 步的任务里,TimesFM 不只是把 llmtime(ZS) 甩在身后,预测精度还能跟专门在这些数据集上训练的 PatchTST 打平。
TimesFM 2.5:最新版本升级了什么
论文发布之后,Google 持续在迭代。2025 年 9 月推出的 TimesFM 2.5 相比 2.0 做了几个值得关注的改动:
参数量从 500M 缩回了 200M,但上下文长度从 2048 扩展到了 16k,长序列建模能力大幅增强。还新增了一个可选的 30M 分位数预测头,支持输出连续分位数预测结果(覆盖最长 1k 步的预测区间),对于需要不确定性估计的业务场景来说很实用。频率指示器也被移除,模型接口更加简洁。
代码层面,调用方式也变得很直接:
import timesfm
model = timesfm.TimesFM_2p5_200M_torch.from_pretrained("google/timesfm-2.5-200m-pytorch")
point_forecast, quantile_forecast = model.forecast(
horizon=12,
inputs=[np.linspace(0, 1, 100), np.sin(np.linspace(0, 20, 67))],
)
加载预训练权重,配置预测参数,forecast() 直接出结果,点预测和分位数预测一起给,干净利落。
为什么这件事值得关注
在 NLP 领域,大家早就习惯了"预训练+零样本"这套范式——一个大模型,包打天下。但时间序列预测这个方向,长期以来还停留在"一个任务一套模型"的阶段,每次换数据集都要重新来过。
TimesFM 证明了这套范式在时序预测上同样能跑通。即便只有 200M 参数,即便没见过目标数据集,它的预测表现已经足够接近那些在目标集上精调过的专用模型。
对于需要快速验证预测效果的工程师、数据科学家来说,这类开箱即用的基础模型,意义不只是省了训练时间——它改变的是整个工作流的起点。
项目地址:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)