AI Coding 实战:2周重构54万行代码,真的吗?
有人说这是吹水,有人说这是给老板递刀子,也有人很认真地追问:你们到底是怎么做到的?
说实话,有些质疑我都能理解。
因为如果换作是我,看到10年系统、54万行代码、2周重构完成这几个词摆在一起,第一反应大概率也不是“牛”,而是:
这怕不是又一个 AI 神话(笑话)
但问题在于,这件事确实发生了,他不是 PPT,也不是 Demo,而是已经灰度、已经上线的系统…
所以这篇文章,我不想再重复讲AI 有多强,也不想把它写成一篇爽文。而是认真的回答四个问题:
- 这件事到底是怎么做到的?
- 它真正成立的前提是什么?
- 它的边界在哪里?
- 普通团队能不能复制,老板又该怎么理解?
要注意的是,我这边尽量在不透露过多课件特有的知识的情况下,真诚的回答。也希望大家在以后的工作中不要对 AI Coding 有太多的误解。
无论是神话 AI Coding,觉得他无所不能;还是妖魔化他,觉得在给老板画大饼,都是不对的,还是建议拥抱他,切不可故步自封…

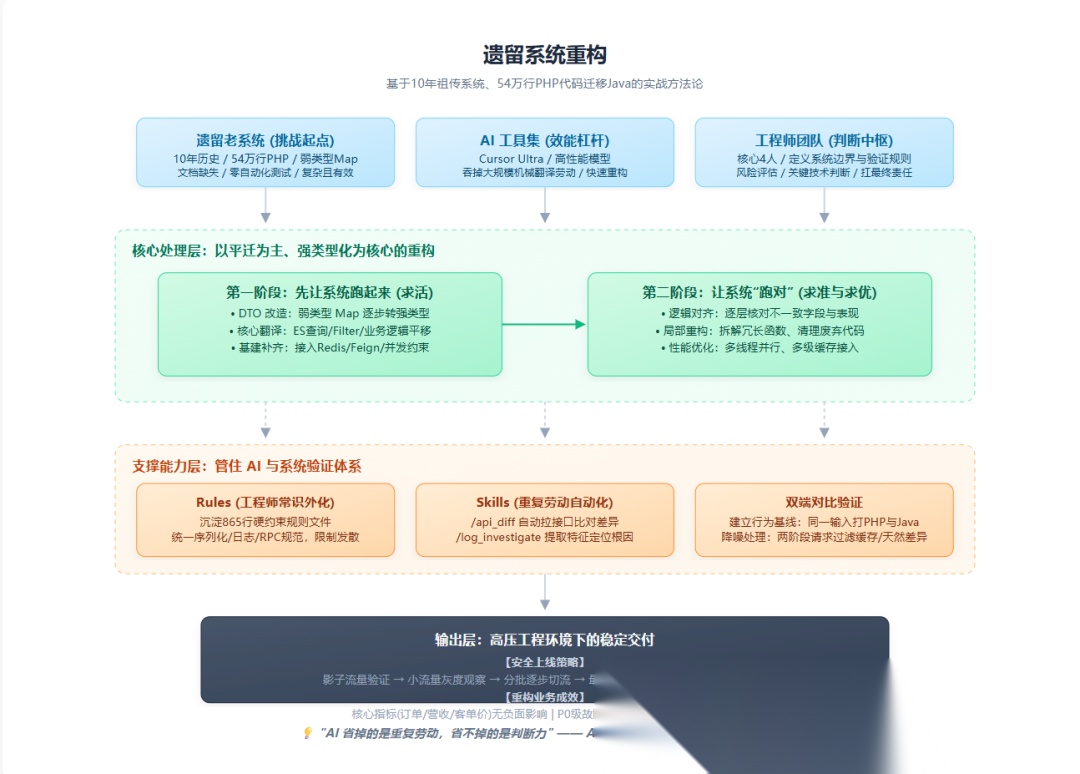
2周重构完成?
首先,先把最容易引战的问题说清楚:这到底是不是“2周重构完成的”?
这是评论区里最集中的质疑。
因为在很多工程师的理解里,重构完成这四个字,默认包含的东西很多:
- 业务梳理
- 技术方案
- 核心开发
- 回归测试
- 灰度观察
- 线上稳定
- 长尾问题收口
- …
如果按这个口径理解,“2周搞定 10 年老系统”,确实很像天方夜谭。
所以这里我先把口径说清楚:
两周,指的是核心迁移开发 + 关键行为对齐 + 基础验证的时间。
后续灰度切流、线上观察、零星修复,又持续了一周多
也就是说,这里的“两周重构完成”,更准确地说,是:代码层面的主体迁移,在两周内交付完成。
而不是说两周之内,所有上线后问题、所有隐性分支、所有历史兼容细节,都被彻底清空了。
只不过虽然这两个说法差别很大。好像前者是一个高压但真实的工程案例;后者就很容易变成营销叙事。
但是 2周 跟 4周,这个事情差异很大吗?
重构还是翻译
整个评论里面,我认为最专业的就是这个问题了,他是值得讨论的。
因为很多人一看到“重构”这个词,脑子里想到的是另一种画面:
- 重新梳理领域模型
- 重新划分边界
- 重写架构
- 借机修掉历史债务
- 顺便把不合理的业务也整理一遍
- …
如果按这个标准,这次项目当然不能算那种理想意义上的大重构。
因为我们这次项目最核心的目标,从来不是重做一个更先进的系统,而是:
在不改变外部行为的前提下,把一套跑了 10 年的 PHP 老系统,迁到 Java,并把后续维护成本降下来
所以更准确一点说,这次项目本质上是:
- 平迁
- 行为对齐
- 强类型改造
- 工程能力补齐
- 带有局部优化的重构
- …
所以,如果你说它是翻译 + 小部分优化,这个说法不算错。但如果只说它是翻译,又低估了它的工程含量。
因为真正纯翻译,不会做这些事:
- 把 PHP 的弱类型 Map 全链路替换成 Java DTO
- 把一堆历史逻辑拆成可维护的模块
- 补齐缓存、RPC、序列化、并发的工程约束
- 做双端验证、日志闭环、差异追踪、PHP 同步监控
- 在上线阶段设计灰度和回滚策略
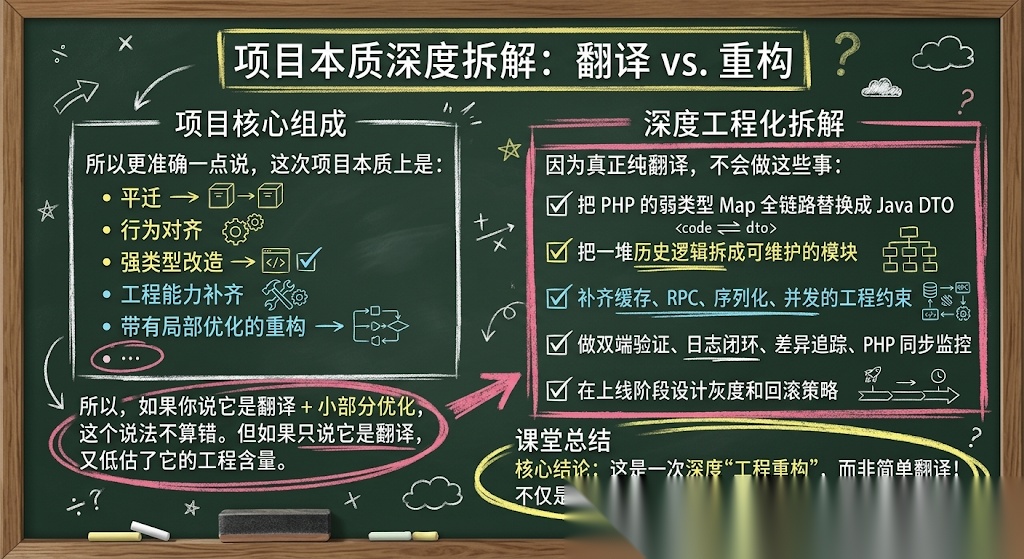
所以如果非要找一个更准确的表述,我会这样定义这次项目:
这是一次以平迁为主、以行为一致为约束、以强类型化和工程补齐为核心的重构
它不是纯翻译,也不是理想化的大重构,它更像是一场开着车换轮胎的工程迁移。
他可信吗?
到这里我们才来讨论:为什么很多人会觉得这事不可信?
因为按传统路径,这件事根本推不动。
你想一下,一个运行了 10 年的老系统,54 万行 PHP,文档缺失,自动化测试几乎为零,很多逻辑混着业务补丁、历史兼容和临时修复。
面对这种系统,传统做法一般是:
- 先花很长时间理解全貌
- 梳理业务和技术债
- 补测试
- 再逐步开始重构
- …
听起来很合理,但现实里经常会死在第一步。
因为这类系统最麻烦的地方不是“代码多”,而是:
你根本不知道你眼前看到的这段烂代码,到底是在解决一个真实问题,还是只是在堆历史屎山
很多老系统最危险的不是复杂,而是**“复杂且有效”**。
这些老系统的很多部分,它可能很丑、很绕、很反直觉,但它已经在线上跑了很多年。你今天看不懂,不代表它没用;你今天觉得可以简化,不代表简化后不会炸。
所以这种系统迁移,最容易犯的错误就是:还没搞清楚它现在实际上怎么工作,就急着把它改成你觉得更合理的样子。
而这恰恰是 AI 最爱干的事。AI 很容易在局部看起来很聪明,动不动就
- 帮你优化一下
- 顺便简化一下
- 这里可以更优雅
但对遗留系统来说,很多时候:优雅,反而是危险的。
所以这次项目能推进,不是因为我们先理解了整个系统,而是因为我们换了一个问题定义方式。
改变战局/改变思路
这次项目最关键的转折点,我认为不是不是先理解代码,而是先还原真实行为。
我们没有先追求理解这个系统为什么这么设计,而是先追求:这个系统现在实际上是怎么工作的。
换句话说,我们把问题从理解意图改成了还原事实。
因为对迁移来说,最重要的不是你能不能讲清楚当年作者脑子里在想什么,而是:
- 这个接口输入什么
- 输出什么
- 会经过哪些链路
- 哪些字段必须一致
- 哪些差异其实不重要
- 哪些逻辑是历史兼容,不能乱动
一旦把问题改写成这个样子,事情就从“无底洞式理解系统”,变成了“可拆解、可验证、可收敛的工程任务”。
这一步非常重要。因为它决定了我们不是在做理解全系统后再编码的项目,而是在做:
一边建立行为基线,一边推进迁移,一边持续收敛差异
这也是为什么两周能够推进。不是因为系统突然变简单了,而是因为任务被重新组织了。
两周,没日没夜
很多人其实很好奇:那两周你们到底做了什么?
答案很简单:**我们在没日没夜的加班啊!**我说的两周,跟你说的两周,你们以为真的是一回事?
哦,这件事,就这么轻轻松松就完成了,我 TM 每天工作15个小时,还不能吹个牛了…
第一周:先让系统跑起来
第一周的目标非常明确:不是优雅,不是完美,而是让系统先跑起来。
这一周我们大概提交了 300 多次,日均 45 次左右,代码量大概 10 万行
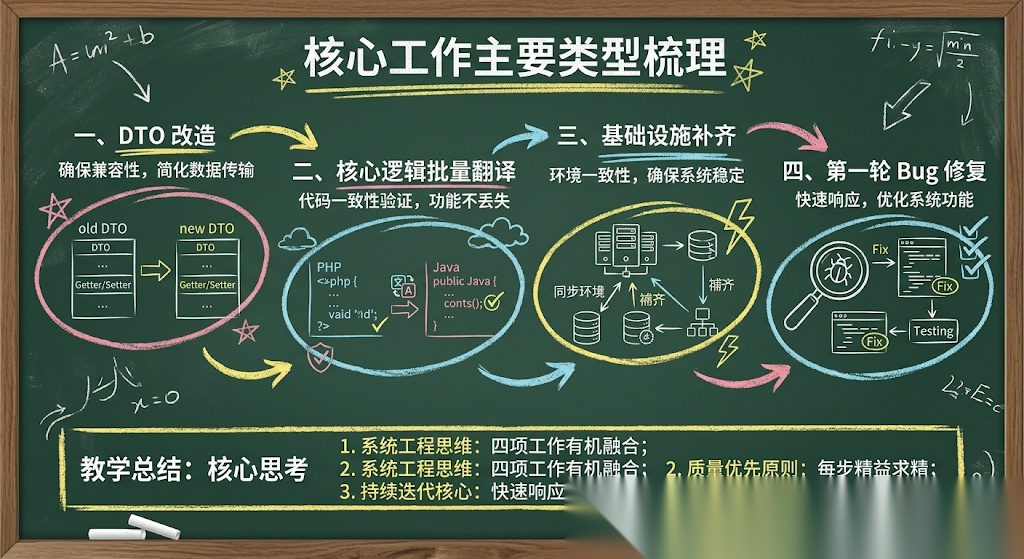
核心工作主要有几类:
一、DTO 改造
PHP 老系统大量使用弱类型 Map 传参。
迁到 Java 后,如果继续保留这种写法,代码虽然能“翻”过来,但根本不具备长期维护价值。
所以第一周我们做了大量 Map → DTO 的转换,把原本散乱的参数传递,逐步拉回强类型体系。
// PHP:弱类型 map 传参$params = [ "goodsId" => $goodsId, "countryCode" => $countryCode, "lang" => $lang, "currency" => $currency,];$result = $this->goodsService->queryGoodsDetail($params);
二、核心逻辑批量翻译
这一步包括:
- ES 查询层
- Filter 逻辑
- 缓存层
- Sticker / 价格 / 颜色等业务处理逻辑
这里 AI 起到的作用非常直接:吞掉大规模机械翻译劳动。
如果没有 AI,这一部分会非常耗体力,而且极其容易把工程师拉进低质量重复劳动里。
三、基础设施补齐
除了业务代码,基础设施也要一起补:
- ES 模型建立
- Redis 缓存接入
- Feign 客户端封装
这一步其实很关键,因为它决定了你不是在“翻源码”,而是在把系统真正迁到另一个可运行的工程环境里。
四、第一轮 Bug 修复
BUG 当然会很多啦,比如:
- 序列化问题
- Final Sale 判断逻辑
- 类型转换错误
这一周结束的时候,系统的状态大概是:它已经可以启动了,接口开始有响应了。
虽然里面还有很多不够优雅的地方,虽然很多地方还是 Map 味很重,但至少我们完成了最关键的一步:把巨大未知系统变成了可以继续验证和推进的工程对象。
紧接着就进入第二周了:
第二周:让系统“跑对”
如果说第一周解决的是能不能跑,那第二周解决的就是跑得对不对。

这一周的提交次数暴增,大概 500 多次,日均 70 次以上,代码量也到了 20 万行以上
重点工作主要有:
1 继续做强类型改造
第一周为了抢进度,很多地方先保留了中间形态。
第二周开始集中清理这些技术债,把遗留的 Map 逐步替换成更稳定的 DTO 和强类型结构。
2 开始做真正的逻辑对齐
这里不是说第一周不对齐,而是第一周更像“先让接口跑起来”,第二周开始针对那些不一致的地方做逐层核对:
- 为什么这个字段类型不一样?
- 为什么 PHP 返回了,Java 没有?
- 为什么顺着查是一样的,结果却还是不同?
3 清理和重构局部结构
包括:
- 拆解冗长函数
- 清理废弃代码
- 加 PHP 源码映射注释
- 把一些“能工作但很脆”的实现改成更稳定的结构
4 补性能优化
例如:
- 多线程并行
- 多级缓存
- 一些高频请求链路的极致性能优化
所以两周下来,我们做的并不是“读完系统再重写”,而是:
先把它跑起来,再把它跑对,再把它逐步拉回可维护状态
这是一个很典型的工程推进思路:先求活,再求准,最后再求优。
最难的地方:对错
整体下来,我们感受最难的不是写代码,而是:没有测试,你怎么知道它“对”?
这是评论区里最合理、也最尖锐的质疑之一。
因为原系统几乎没有自动化测试:
- 零单元测试
- 零集成测试
- 零回归测试
如果按传统思路,这种项目应该先补测试,再动代码。
但问题是,54 万行代码,真按这个路径来,项目大概率会死在“理解”和补测试阶段。
所以我们换了个思路:
不用“先理解代码,再写测试”这条传统路径
改成先建立行为基线,再做双端验证
一、双端对比:同一输入,打 PHP 和 Java 两边
核心逻辑很简单:同一组请求参数,同时发给 PHP 老系统和 Java 新系统,然后逐字段比对返回值。
这个方法的价值在于,你不需要先完全理解代码内部每一层是怎么写的,你先回答一个更硬的问题:
对同一个输入,这两个系统给出的输出是不是一致?
只要行为一致,迁移就有了基础可信度。
二、为什么直接对比不够?因为缓存会骗人
一开始我们直接对比,很快就发现一个问题:PHP 和 Java 的缓存数据不同步,你直接一比,满屏都是差异…
这时候如果没有方法论,很容易被噪音淹死。所以后来我们把验证拆成两轮:
***第一轮:带缓存请求。***模拟真实用户流量,先把所有差异都找出来。
***第二轮:跳过缓存请求。***只有在第一轮有差异时才触发,用来判断差异到底是不是缓存导致的。
交叉分析规则是这样的:
- 第一轮有差异、第二轮消失 → 缓存差异,不是 Bug
- 两轮都有差异 → 业务逻辑差异,必须修
- 第一轮没有、第二轮新增 → 缓存掩盖了底层问题
这套方法最大的价值,就是把差异变成了可解释的差异。
差异对比 → 降噪
一开始做双端对比时,报告里动不动就是几百条差异,但后来发现,绝大多数都不是真 Bug。比如:
- “1” vs 1
- “59.00” vs 59.00
- requestId、traceId
- _id 的不同生成策略
这些差异放在报告里看起来很吓人,但其实都不影响业务。真正的痛苦是:这些噪音会把真正该修的问题淹没掉。
所以我们后来不断补忽略规则,把这些PHP 弱类型天然差异、请求级动态字段差异从报告里剔除掉。
最后把整个差异对比的信噪比,大概从 10% 提升到了 80%+。
这个数字不是为了显得厉害,而是想说明:工程验证的关键,不只是能不能发现问题,而是能不能把问题筛成值得处理的问题。
AI 会不会犯错?
当然会,而且会犯得很离谱…

如果你真正用 AI 做过复杂工程,你一定知道:
AI 最大的问题,从来不是不会写,而是太敢写
它很容易写出那种:
- 局部看起来没问题
- 整体却埋了坑
- 还一副很自信的样子
我们这次踩过的坑,举几个最典型的。
坑一:message 变成了 msg
Java 默认返回体用 message 字段,PHP 用 msg。
AI 在翻译时识别到了这个差异,但修复方向搞反了,结果前端拿不到错误提示。
这个 Bug 发现得不算晚,灰度 5% 时就暴露出来了,修起来也不难,10 分钟就搞定。
但它给人的警示非常大:
AI 能看见差异,不代表它就知道该怎么处理差异
坑二:ES 查询明明对了,商品数却还是少
有一次接口返回的商品数量比 PHP 少。AI 看完 ES 查询逻辑后,判断“没问题”;人看第一眼也觉得查询条件对得上。
结果最后一路 debug 才发现,问题根本不在查询,而在返回值格式化阶段:Java 在组装响应时把一部分商品丢掉了。
这个坑直接逼出了后面的核心规则:不能只看入口逻辑,必须递归追踪到最终赋值的那一行。
坑三:AI 未经确认,直接执行破坏性操作
调试某个接口时,AI 直接跑了 mvn compile,把现场全清了。
这一类问题特别像一个“有热情但没边界感”的实习生:它不是故意搞你,它是真觉得自己在帮忙。
所以后来我们把这类行为也写进了规则里:
- 任何可能影响编译或运行环境的操作,必须先确认
- 不允许未经确认执行破坏性操作
- 不允许顺手优化
- 不允许扩大改动范围
好,看到这里的一定是真爱粉,所以我们给出一点干货:
方法论:管住 AI
到这里问题就来了:那我们是怎么把 AI 管住的?
答案可不是一句多写提示词,能说清楚的,真正有效的,是两件事:
规则(Rules) + 技能(Skills)
Rules:把工程师脑子里的常识,写成 AI 必须遵守的约束
最开始最痛苦的一件事就是,每开一个新对话,AI 都会重复犯同样的错。比如:
- 用反射去处理弱类型
- 自作主张简化逻辑
- 不按项目规范做序列化
- 不走统一 RPC 封装
- catch 里默认打 warn
- 到处保留 toMap / fromMap
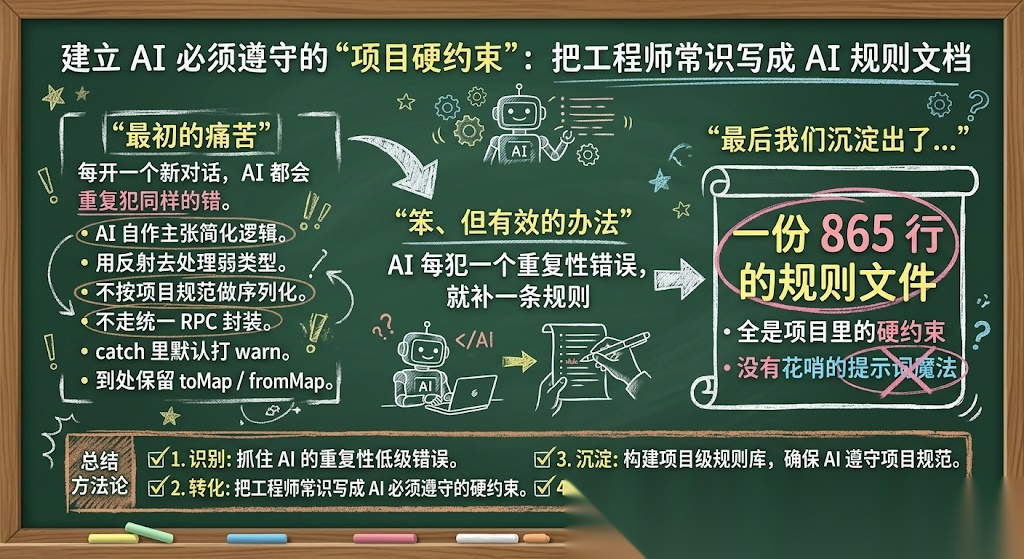
后来我们采取了一个非常笨、但非常有效的办法:
AI 每犯一个重复性错误,就补一条规则
最后我们沉淀出了一份 865 行 的规则文件,里面没有什么花哨的提示词魔法,全是项目里的硬约束。比如:
===== 翻译行为约束 =====- 翻译 PHP 代码时不要应用反射- 全部按照原代码实现,不要简化实现- 确保每次实现都完整,不允许“剩余逻辑类似,省略”- PHP 中是 API 访问的,统一封装到 Feign===== 序列化规范 =====- 序列化 / 反序列化统一用 JsonUtil- Redis 写入前先 toJson- 读取后必须按约定方式反序列化===== 性能约束 =====- 强类型优化,全链路不需要 toMap/fromMap- Redis 多 key 场景按项目封装约束实现===== 工程规范 =====- catch 中日志统一 error 级别- import 规范统一,不允许内联全路径
翻译行为约束
- 翻译 PHP 代码时不要应用反射
- 全部按照原代码实现,不要简化实现
- 确保每次实现都完整,不允许“剩余逻辑类似,省略”
- PHP 中是 API 访问的,统一封装到 Feign
序列化规范
- 序列化 / 反序列化统一用 JsonUtil
- Redis 写入前先 toJson
- 读取后必须按约定方式反序列化
性能约束
- 强类型优化,全链路不需要 toMap/fromMap
- Redis 多 key 场景按项目封装约束实现
工程规范
- catch 中日志统一 error 级别
- import 规范统一,不允许内联全路径
这些规则看起来都不高级,很多工程师甚至会觉得这不就是常识吗。但关键就在这里:
人脑里的常识,如果不写出来,AI 是不会自动继承的
所以加完这套规则之后,AI 代码的一次性可用率,确实从 50%\60% 提升到了 90%+。
不是 AI 变聪明了,而是它终于被工程纪律管住了。
**Skills:**把高重复劳动封装成一条命令
除了规则,我们还把一系列重复性工作做成了 Skills。

因为有些事情,如果一个人做超过 3 次还在手工操作,那大概率就值得自动化了,比如:
/api_diff
输入一条命令,自动完成:
- 构造 PHP / Java 双端请求
- 拉接口响应
- 逐字段对比
- 分类差异
- 输出报告
这个 Skill 本质上解决的问题是:把手工比 JSON这种低效劳动,变成稳定可复用的验证流程。
/api_diff "US站列表页价格差异"/api_diff re-diff "US站列表页价格差异"对比规则: - 按 goodsId 做主键匹配,逐商品对比关键字段 - 关键字段:goodsId、title、url、color、price、originalPrice、shipsNow、stickers... - 差异类型:value_mismatch / missing_field / type_mismatch忽略规则: - costTime、requestId、traceId - _id - string ↔ number 类型差异交叉分析: - 第一轮有、第二轮消失 → 缓存差异 - 两轮都存在 → 业务逻辑差异(需修复) - 第一轮无、第二轮新增 → 缓存掩盖的差异
PS:篇幅问题,后面我就不插入 Skills 示例了
/log_investigate
输入一行日志或一个关键词,自动:
- 提取 traceId / 时间 / 类名 / Pod
- 查日志频率
- 定位代码
- 分析根因
- 生成排查记录
这个东西的价值也很大:每排查完一个问题,就多一篇可复用的知识文档。
php_sync_check
每天自动拉 PHP 最新代码,对比 Java 实现,发现逻辑分叉。
这个 Skill 的出现,是因为重构期间老系统还在继续迭代。 如果没有这类同步机制,两边很容易越跑越偏。
所以回头看,这套 Rules + Skills 干的其实是同一件事:
把原本只存在于工程师经验里的东西,外化成 AI 可执行的工程系统
AI 编程的可验证性
很多人看这类案例,最容易只盯着一件事:代码是怎么那么快写出来的?
但如果你真的做过线上系统迁移,你就会知道:写出来只是第一步,并且不是很重要的一部,真正决定你能不能活着上线的,是后面这三件事:验证、灰度、回滚!
验证:不是我觉得差不多,而是我知道哪里还不一样
双端对比、两阶段缓存分析、递归追踪、日志定位,这些东西的目的都不是为了显得方法论高级,而是为了回答一个最现实的问题:
上线前,你到底知不知道自己还有哪些风险没压下去?
**灰度:**这是修正机会
上线前我们设计了完整的灰度方案:
影子验证 → 小流量灰度 → 分批切流 → 全量替换
不是一下子全推,而是带着数据一步步往上走。这里最核心的不是勇气,而是节奏。
复杂系统上线最怕的,不是慢,而是:你没有观察窗口。
**回滚:**这是命…
回滚方案也是提前准备好的,而且是按分钟级恢复来设计。
很多人会觉得:都这么有信心了,为什么还强调回滚?
因为工程不是赌徒游戏,并且我们心里其实慌得不行…
所以,必须有兜底策略,我们要确定:
就算出问题,也能把损失控制住
来了,最终效果
还不信的同学们,到这里,就真的可以坐下了
上线效果,这个问题也不能靠感觉良好来回答,只能靠数据说话。
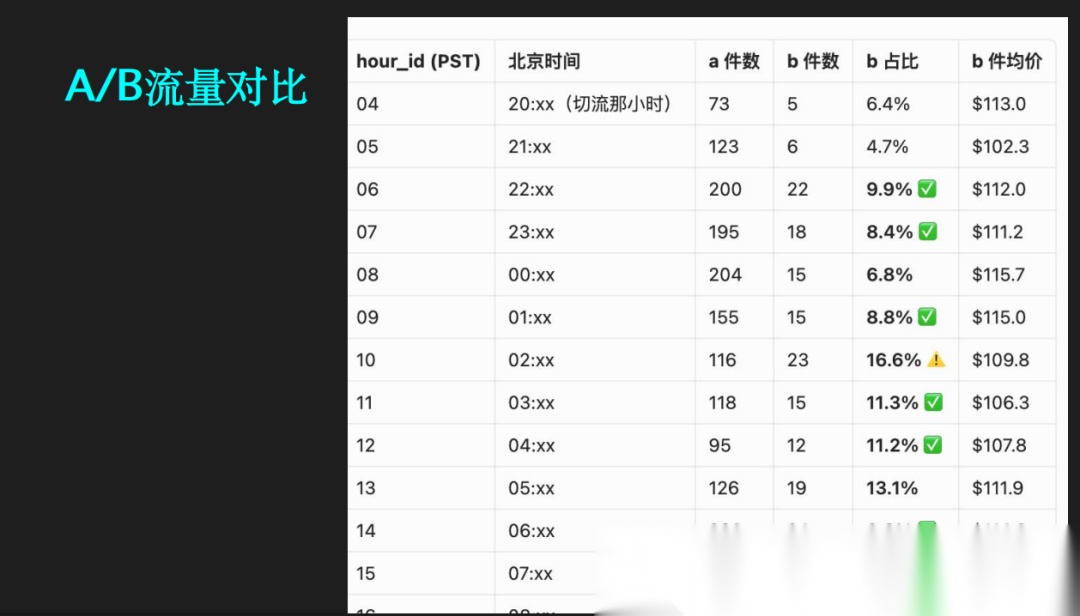
AB 测试结果(脱敏数据)
| 指标 | Java(实验组) | PHP(对照组) | 差异 |
|---|---|---|---|
| 订单量 | 7,418 | 7,475 | -0.8% |
| 营收差异 | — | — | -0.6% |
| 客单价 | 157 美元 | 149 美元 | 无显著差异 |
结论:迁移未对业务指标产生负面影响。
灰度状态
| 站点 | 比例 | 状态 |
|---|---|---|
| US 站 | 100% | 全量上线 |
| CA 站 | 80% | 灰度中 |
当前系统运行状况
| 项目 | 状态 |
|---|---|
| 回滚情况 | 无回滚 |
| P0 故障 | 无 |
| 日常修复 | 零星对齐修复进行中,PHP 仍在改动,Java 需同步 |
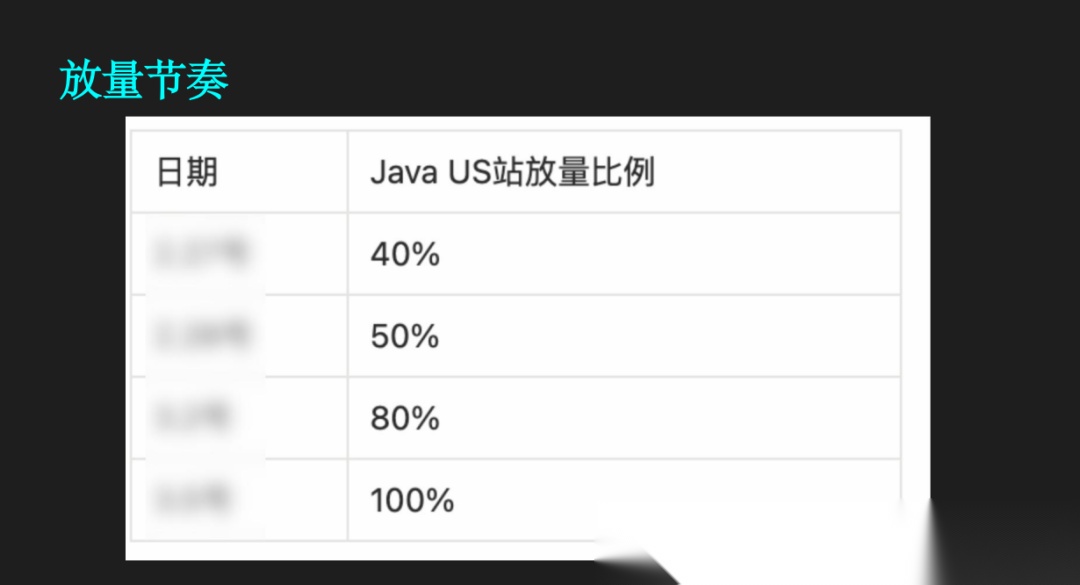
这里再补一句:全量上线至今,没有回滚,没有出现 P0 级故障,仍然有零星的对齐修复在持续进行。
对吧,可能大家也看到想要的结果了,他确实是有 BUG 的,对的:
这不是一次完美翻译,而是一次风险可控的迁移
复杂系统迁移,尤其是还在演进中的老系统,不可能用一篇文章就画上句号。后续持续监控、持续同步、持续收口,本来就是常态。
可复制性如何?
之前就有粉丝加微信质疑过这件事,我统一给的回答就是:假的,忽悠人的!
原因很简单,没必要去强行改变别人的认知,你愿意信,自然就会去尝试,你不信,哪我又何必,白费口舌呢?
但我也有一些担忧的店,因为如果有人看完这篇文章,只记住了:“别人 2 周都能搞定 54 万行,你们为什么不行?”
那这个案例就真的变成给团队递刀子了。所以我必须把前提条件讲得非常明确。
1)团队不是纯靠 AI
核心 4 个人,都是有多年经验、熟悉 Java 生态、做过复杂系统改造的人。
AI 是提效工具,不是替代判断的人。
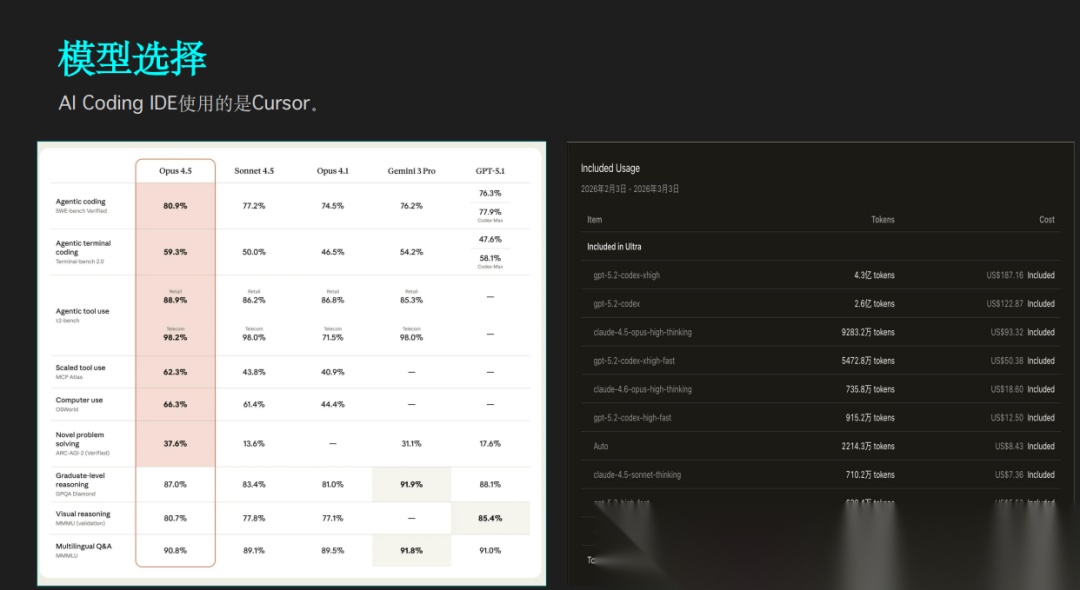
2)这是有成本投入的
两周大概消耗了 1800 美元,9 个 Cursor Ultra 账号,主要用的是高性能模型。
这不是“免费版随便聊聊”能干出来的活。
3)系统本身有可收敛性
我们迁的是一套相对模块化、电商接口边界比较清晰的系统。
如果换成那种盘根错节的单体系统、状态高度隐式传播、上下游依赖一团乱麻的系统,难度会高很多。
4)业务和流程能配合
重构期间,业务需求没有停。但我们有专门的 PHP 同步检查机制,能持续对齐两边逻辑。
这件事不是“程序员开干就行”,背后其实也需要组织和流程支撑。
给老板们的话
所以,老板们可以从这个案例里获得些什么?
我最希望老板们学到的,不是***“两周”***这两个字。而是下面这句话:
AI 不是把复杂工程变成了无需经验的体力活,恰恰相反,它把工程能力的重要性进一步放大了
因为 AI 确实能吞掉大量脏活累活:
- 批量翻译
- 差异比对
- 日志分析
- 调用链追踪
- 知识沉淀
- 流程自动化
但它吞不掉的东西,依然非常关键:
- 边界判断
- 风险评估
- 规则制定
- 验证设计
- 灰度策略
- 回滚预案
- 对结果负责
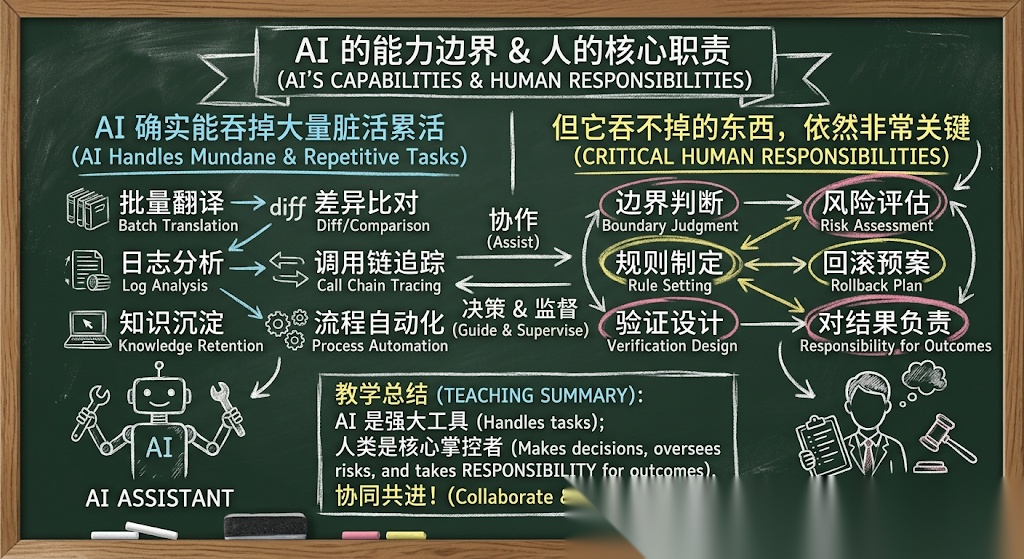
所以如果老板只看到了效率提升,没看到工程纪律和风险控制,那大概率会误用这个案例。
而一旦误用,这个案例带来的就不是效率红利,而是组织灾难。
我话是说清楚了的,你们老板还要乱搞,可就不怪我了…
结语
如果让我用一句话总结这次项目,我会这么说:
AI 省掉的是重复劳动,省不掉的是判断力
并且有一点特别关键:使用 AI Coding 后,我乃至我身边的同学,都更加的累了,AI 并不让我们变得轻松,这让我挺气馁的…
AI可以在很短时间里,把 57 万行 PHP 翻成 22 万行 Java。但它不能告诉你:翻得对不对。
但这挺重要的。因为他背后是人真正的价值:
- 人定义边界
- 人制定规则
- 人做关键判断
- 人设计验证体系
- 人扛最终责任
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献204条内容
已为社区贡献204条内容

所有评论(0)