大模型LLM(electron)
2026.3.24
学习慕课网上electron桌面聊天应用开发项目
什么是大模型
大模型(Large Language Model)是一种特殊的人工智能技术:它们被称为 “大型” 是因为拥有数十亿甚至上百亿个参数,这些参数就像是模型的 “大脑”,帮助它们理解和处理各种复杂的信息。
大模型的工作原理
一个大型语言模型(LLM)有两个文件:
- 一个包含数十亿个参数的大型文件,用于神经网络模型
- 一个只有几百行代码的小文件,用于运行该模型
可以将 LLM 想象成一个 “下一个词预测器” 或者一个高级的自动补全功能。
大模型的训练过程
第一阶段:预训练
预训练将互联网内容压缩到一个神经网络中:
- 从互联网上获取 10 TB 的文本。
- 使用 GPU 和数百万美元将这些文本压缩到一个神经网络中。
- 获得基础模型。
-
什么是神经网络
神经网络就像一个神经元网络,它们做出决策并相互传递信息。随着处理更多数据,神经元可以随着时间改善他们的决策能力。
第二阶段:微调
微调是为了针对特定用例优化基础模型:
- 使用由人类撰写的 10 万个以上的对话来训练模型。或者,根据一系列问题,让人类审查并选择模型的最佳答案。
- 获得微调后的模型。
- 运行评估来进一步完善模型,找出糟糕的模型响应,并让人类进行修正。
知名的模型列表
https://github.com/wgwang/awesome-LLMs-In-Chinahttps://artificialanalysis.ai/leaderboards/providers
- 文心一言 百度
- 通义千问 阿里云
- GPT(GPT-3.5,GPT-3.5 Turbo,GPT-4 等等) OpenAI
- Gemini Google
- Llama Facebook
- Claude Anthropic
提供商和模型的关系
提供商是为用户提供访问和利用 LLM 的平台或服务的实体。这些提供商可能是科技公司、人工智能研究机构或云计算服务提供商,他们通过向用户提供 API、SDK 或其他工具,使用户能够轻松地接入和使用 LLM,所以一个模型可以被多个提供商所使用。
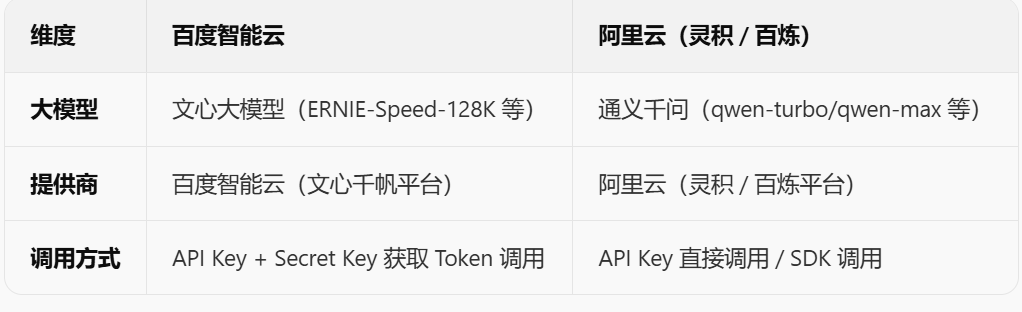
一.百度智能云(文心千帆平台)
百度智能云是作为一个提供商
文心是大模型
百度智能云首页:https://qianfan.cloud.baidu.com/
模型列表:https://console.bce.baidu.com/qianfan/modelcenter/model/buildIn/list
更加详细的列表:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/vliu6vq7u#ernie-speed
其中 ERNIE Speed / Lite / Tiny 都是免费的,是我们用来测试的极佳方案。
其中 ERNIE Speed 的 API 文档:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/6ltgkzya5
OpenAI SDK兼容介绍 - 百度千帆·大模型服务及Agent开发平台
两种使用方式
- 通过 SDK
- 通过 HTTP 请求
使用步骤:
1.安装 Node.js SDK:
- https://github.com/baidubce/bce-qianfan-sdk/tree/main/javascript中查看步骤
- npm install @baidcloud/qianfan
2.完成鉴权
- https://cloud.baidu.com/doc/WENXINWORKSHOP/s/7lte7zhab
- 在这个 URL 下查看 AccessKey 和 SecretKey https://console.bce.baidu.com/iam/#/iam/accesslist
3.初始化
https://cloud.baidu.com/doc/WENXINWORKSHOP/s/7lte7zhab#%E5%88%9D%E5%A7%8B%E5%8C%96
# 初始化的三种方式
# 第一种 通过配置文件 在.env文件中,设置以下内容,安全认证Access Key替换your_iam_ak,Secret Key替换your_iam_sk
QIANFAN_ACCESS_KEY=your_access_key
QIANFAN_SECRET_KEY=your_secret_key# 第二种 通过环境变量
import {setEnvVariable} from "@baidcloud/qianfan";setEnvVariable('QIANFAN_ACCESS_KEY', 'your_access_key');
setEnvVariable('QIANFAN_SECRET_KEY', 'your_secret_key');# 第三种 通过参数
const client = new ChatCompletion({ QIANFAN_ACCESS_KEY: 'your_access_key', QIANFAN_SECRET_KEY: 'your_secret_key' });
4.使用SDK
Token 的定义
Token 是大模型中用来表示中文汉字、英文单词或中英文短语的符号,可以是单个字符,也可以是多个字符组成的序列。您可以使用 token 计算器来计算字符转 token 数。可以用token计算器。
流式输出
异步迭代器:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/AsyncIterator
三种不同的 Role
- System 用于提供设置信息或上下文,以指导模型的行为。这可能包括对话应该如何进行的说明或指导方针。
- User 该角色代表对话中的人类用户。用户的输入引导对话并促使助手做出回应。
- Assistant 这是模型本身的角色,根据系统设定的回应用户的输入。
- https://cloud.baidu.com/doc/WENXINWORKSHOP/s/Ulfmc9dvc 目前百度云支持 user /assistant
-
多轮对话
{ role: 'user', content: '你好' }, { role: "assistant", content: "你好,请问有什么我可以帮助你的吗?" }, { role: "user", "content": "我在北京,周末可以去哪里玩?" },
二.阿里云(灵积/百炼)
通义千问是大模型
体验地址:https://tongyi.aliyun.com/qianwen/
模型提供商:
灵积是原始的模型接口,需要通过 API/SDK 进行调用,是纯开发者视角的。
百炼除了模型本身的 API/SDK,还提供了预置应用模板(如检索增强、AI 妙笔等)、预置业务场景模型(如摘要模型、行业模型等),同时这些功能都有可视化的操作控制台页面,并且还有一系列的大模型应用搭建的可视化工具。
模型列表https://dashscope.console.aliyun.com/model
-
qwen-turbo: 开通即获赠 200 万 tokens 限时免费
-
qwen-plus,qwen-max,qwen-max-longcontext: 开通即获赠 100 万 tokens 限时免费
使用步骤
-
三种使用方式安装阿里云百炼SDK-大模型服务平台百炼(Model Studio)-阿里云帮助中心
-
DashScope SDK(目前有 Java 和 Python 两种方式)
-
HTTP 接口调用
-
兼容 OpenAI SDK
-
-
2 安装 OpenAI Node.js SDK https://github.com/openai/openai-node
-
3 API key https://help.aliyun.com/zh/dashscope/developer-reference/acquisition-and-configuration-of-api-key
-
查看 API Key 大模型服务平台百炼控制台
-
在代码中获取环境变量中的 API key(用的是dotenv(node.js库)) https://www.npmjs.com/package/dotenv这个库是用来从项目根目录的
.env环境变量文件中加载配置,自动注入到process.env让你不用把密钥写在代码里!
-
- 4 初始化 OpenAI 类
// OpenAI 兼容接口详情 https://help.aliyun.com/zh/dashscope/developer-reference/compatibility-of-openai-with-dashscope const client = new OpenAI({ apiKey: process.env['ALI_API_KEY'], // 注意要修改为兼容的 base url baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1' }以下是调用成功控制台的打印。打印了resp。
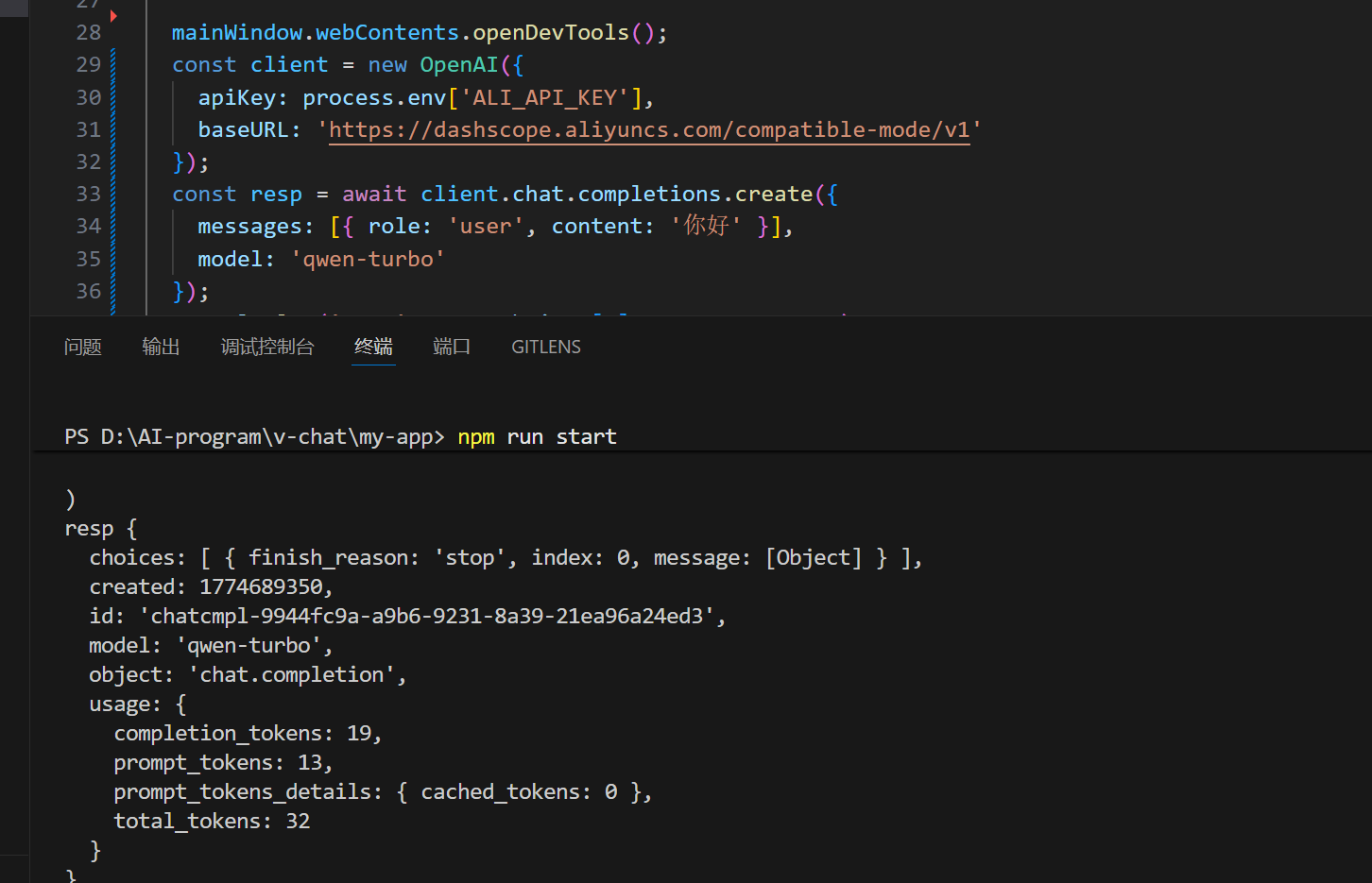
要查看大模型回答的内容,则打印console.log('resp', resp.choices[0].message.content);
其中会发现乱码问题。
如何解决乱码问题:
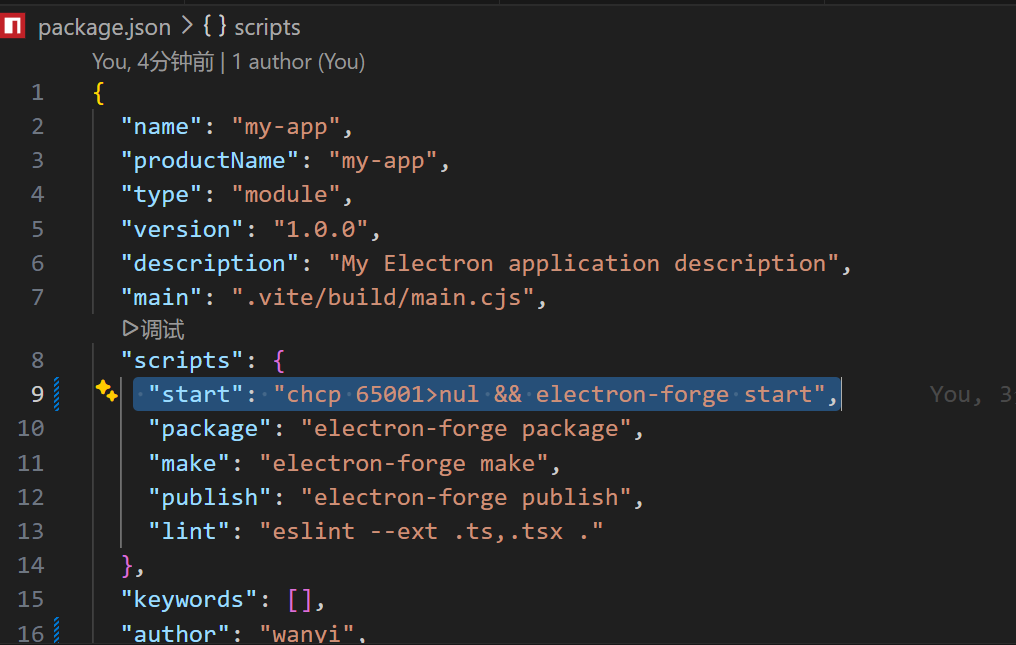
只需要设置chcp 65001
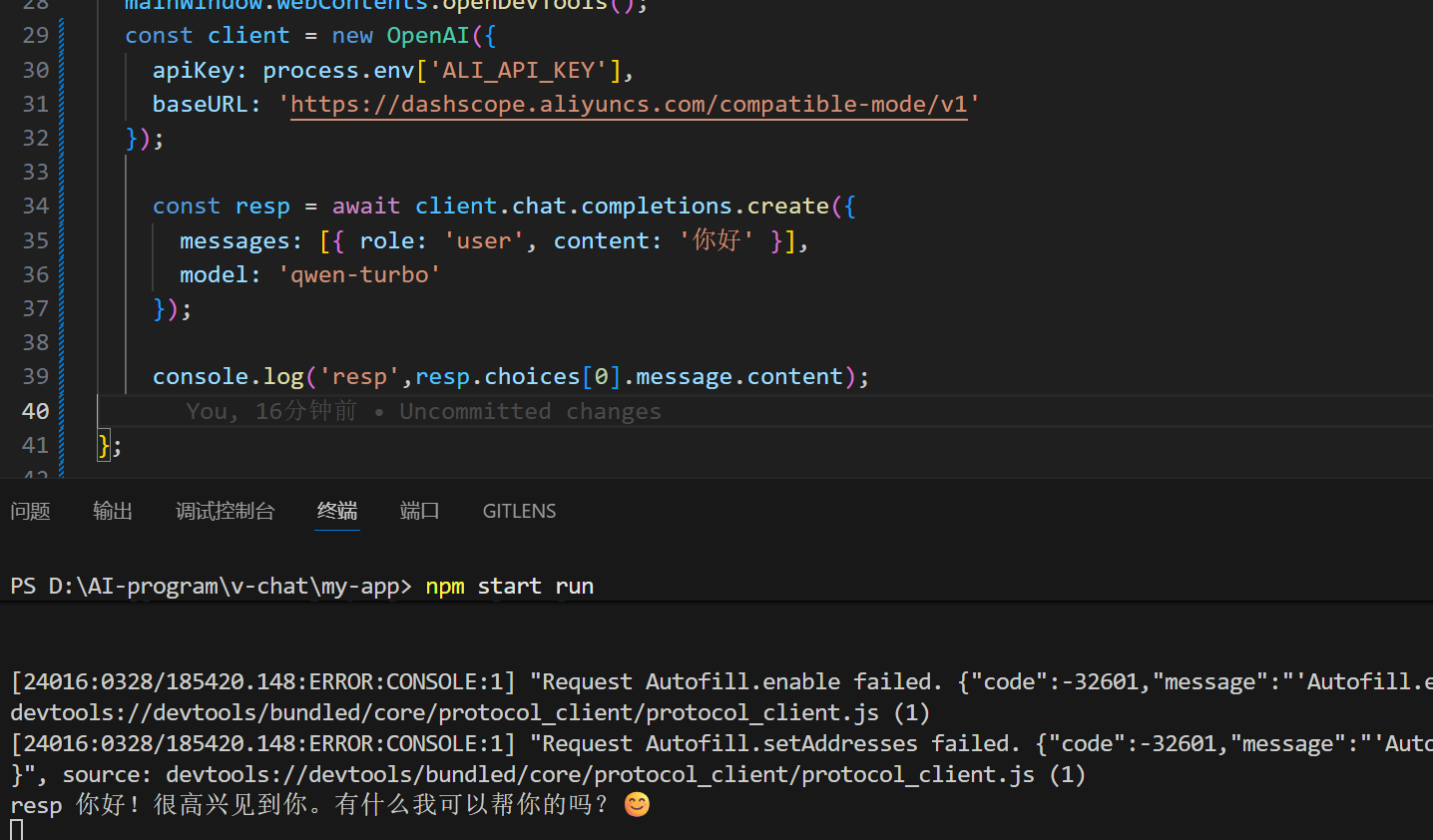
就可以解决乱码问题。还可以流式返回:
流式返回
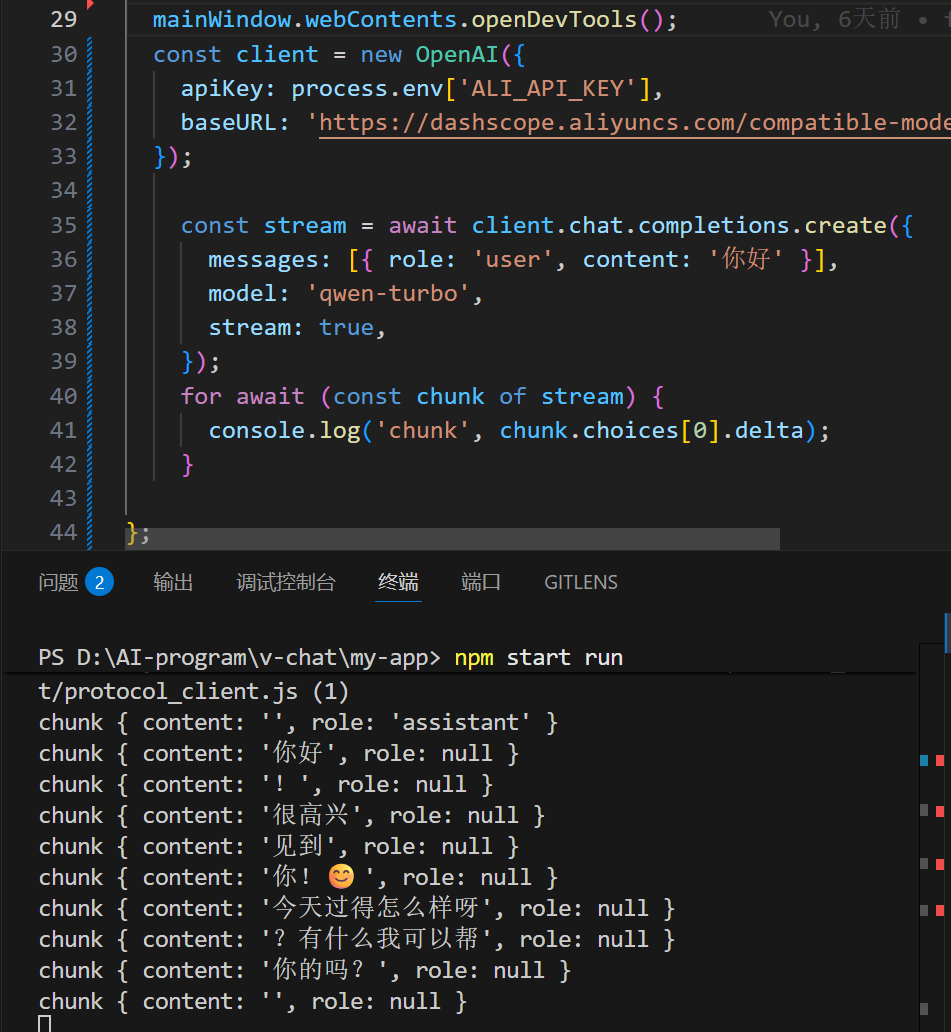
同样也可以设置系统角色,任意发挥
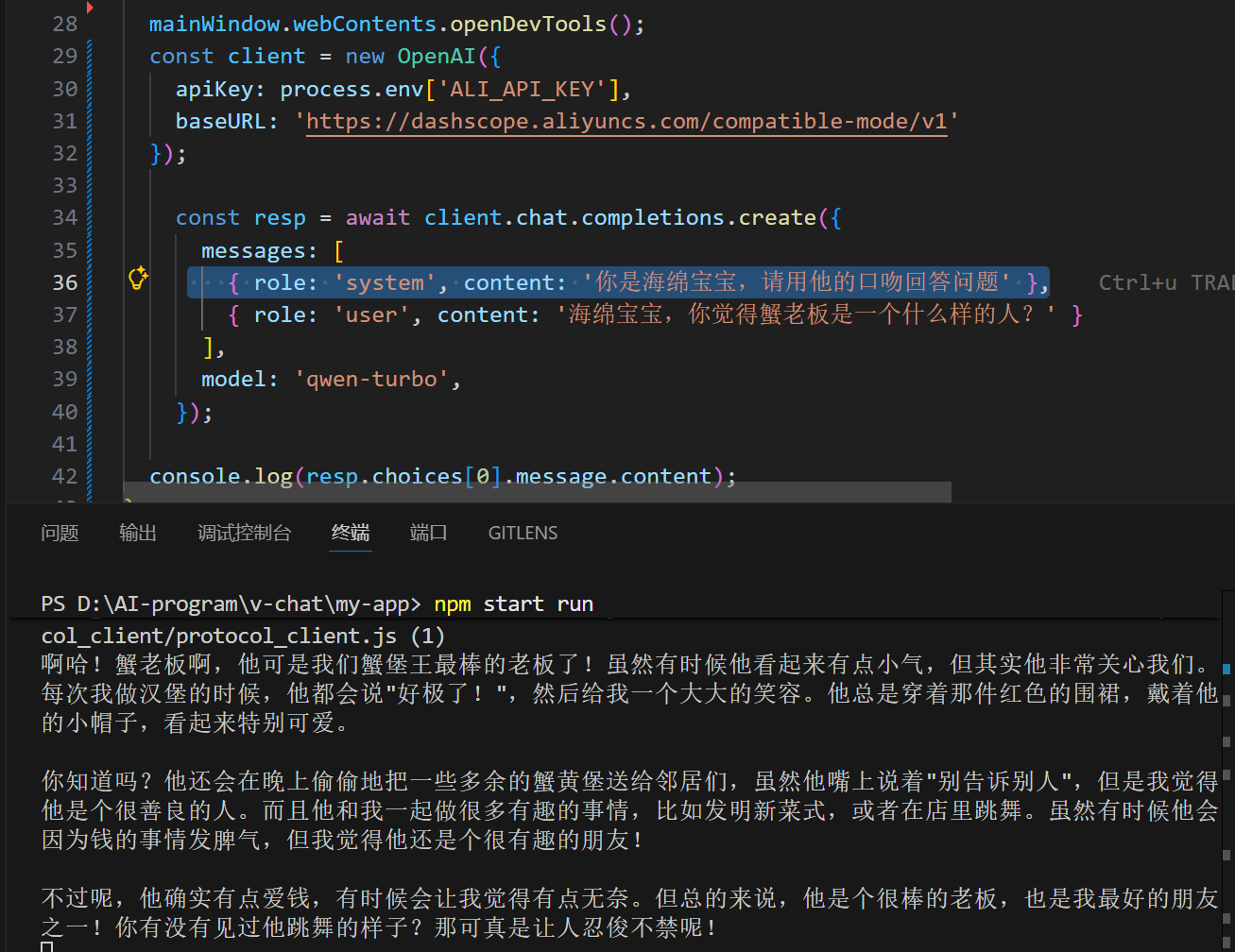
三.尝试使用其他模型
(一)识图
读图模型:通义千问 VL,这个模型:开通 DashScope 即获赠总计 1,000,000 tokens 限时免费使用额度,有效期 30 天。
我自已识图用的是qwen-vl-plus-2025-05-07。也是用免费额度可用。
Base64 图片的格式
data:image/png;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBxSEhUTE
xIWFhUXFxoaGBcXFxgYHhgdGhcdGBgYGBcYHSggGB0lHRUdITEhJSkrLi4uFx8zODM
tNygtLisBCgoKDg0OGhAQGi0fHx8tLS0tLS0rKy0tLS0tLS0tLS0tLS0tLS0rLS0tLS0t...
开头是 /9j/,说明是 JPG 格式的 Base64。
上面代码data:image/png;base64是一种标准。
MIME(Multipurpose Internet Mail Extensions)类型
是一种标准,用于标识互联网上文件的类型和格式。MIME 类型通常由两部分组成,通过斜杠分隔:
- 主类型(Top-Level Type):表示文件的大类,如 text、image、audio、video 等。
- 子类型(Subtype):表示特定于主类型的细分类型。
-
text/plain:纯文本文件。 -
text/html:HTML 文件。 -
text/css:CSS 样式表文件。 -
image/jpeg:JPEG 图像文件。 -
image/png:PNG 图像文件。 -
image/gif:GIF 图像文件。
通俗讲就是mime = 告诉系统 “这个文件是什么类型”
因为要明确告诉大模型你传入的是什么类型的图片,格式必须这样写:
例如:
url: "data:image/jpeg;base64,这里放你的base64字符串"
 我上传的是本地D盘的一张图片
我上传的是本地D盘的一张图片
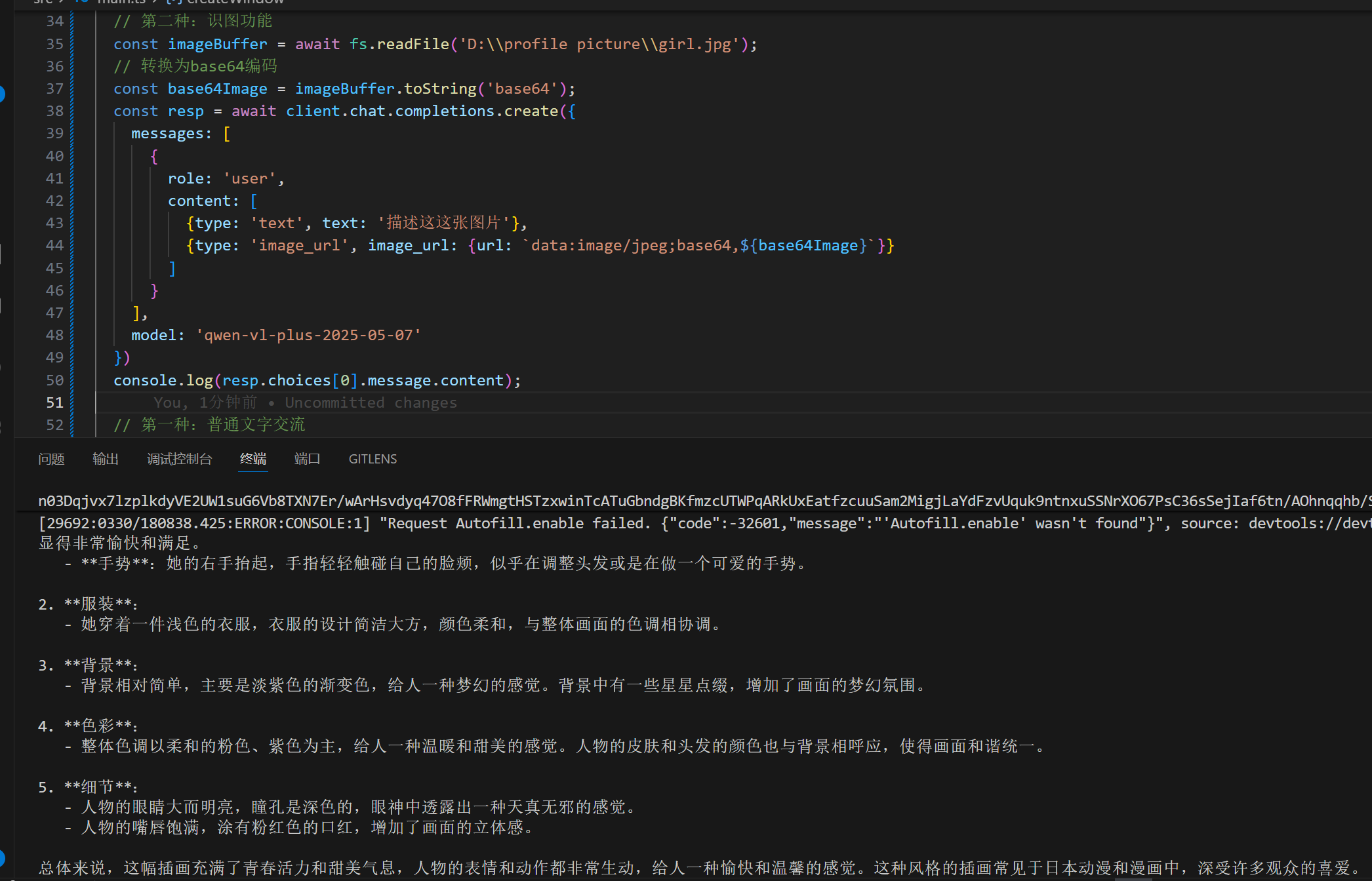
由上图可知,已经成功调用了该大模型。
(二)文件分析
使用 qwen long 进行分析
处理超长文本文档推理-Qwen-Long-大模型服务平台百炼-阿里云
qwen-long 是通义千问模型家族中,提供具备强大长文本处理能力的模型,最大可支持千万 tokens 的对话窗口,并通过与 OpenAI 兼容的模式提供 API 服务(注:Dashscope SDK 调用的方式仍然兼容)。本文提供简单的示例代码,帮助您快速上手并调用 qwen-long 模型服务。
使用文件上传接口
链接:https://help.aliyun.com/zh/model-studio/developer-reference/document-upload-openai-qwen-long
DashScope 提供了帮助用户将文件上传到临时存储空间的功能,用户可以更安全地使用文件输入相关的 API 调用。
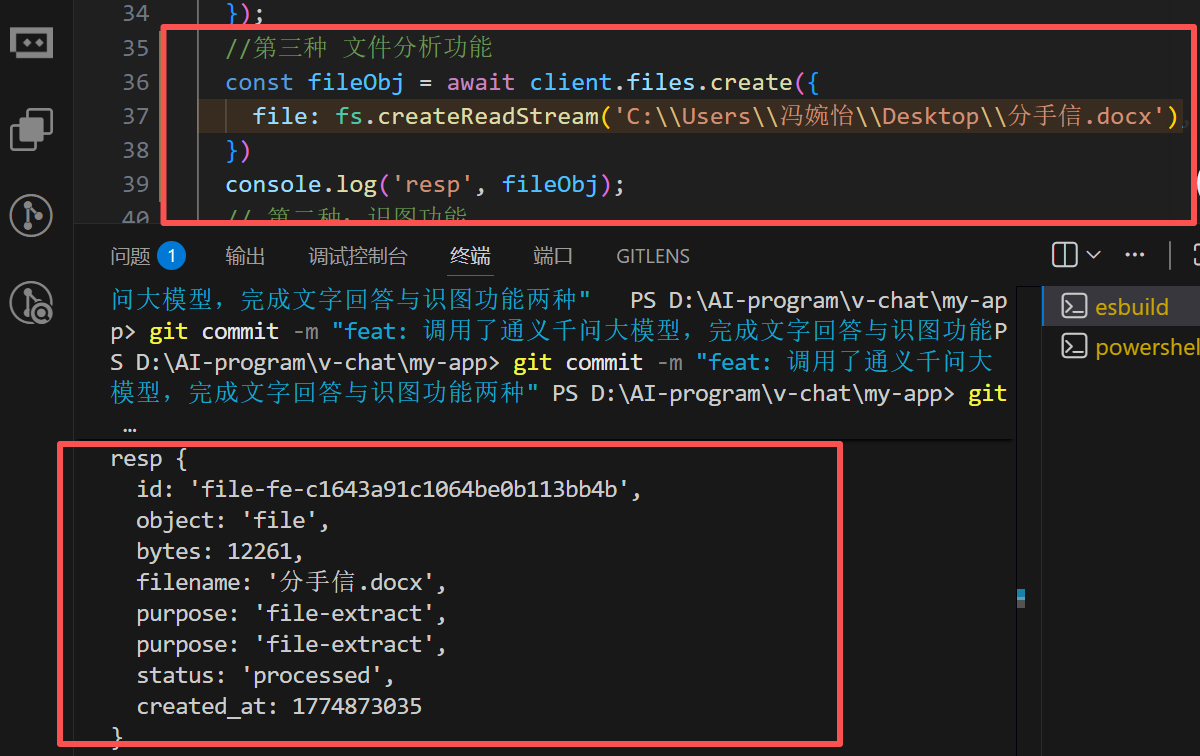
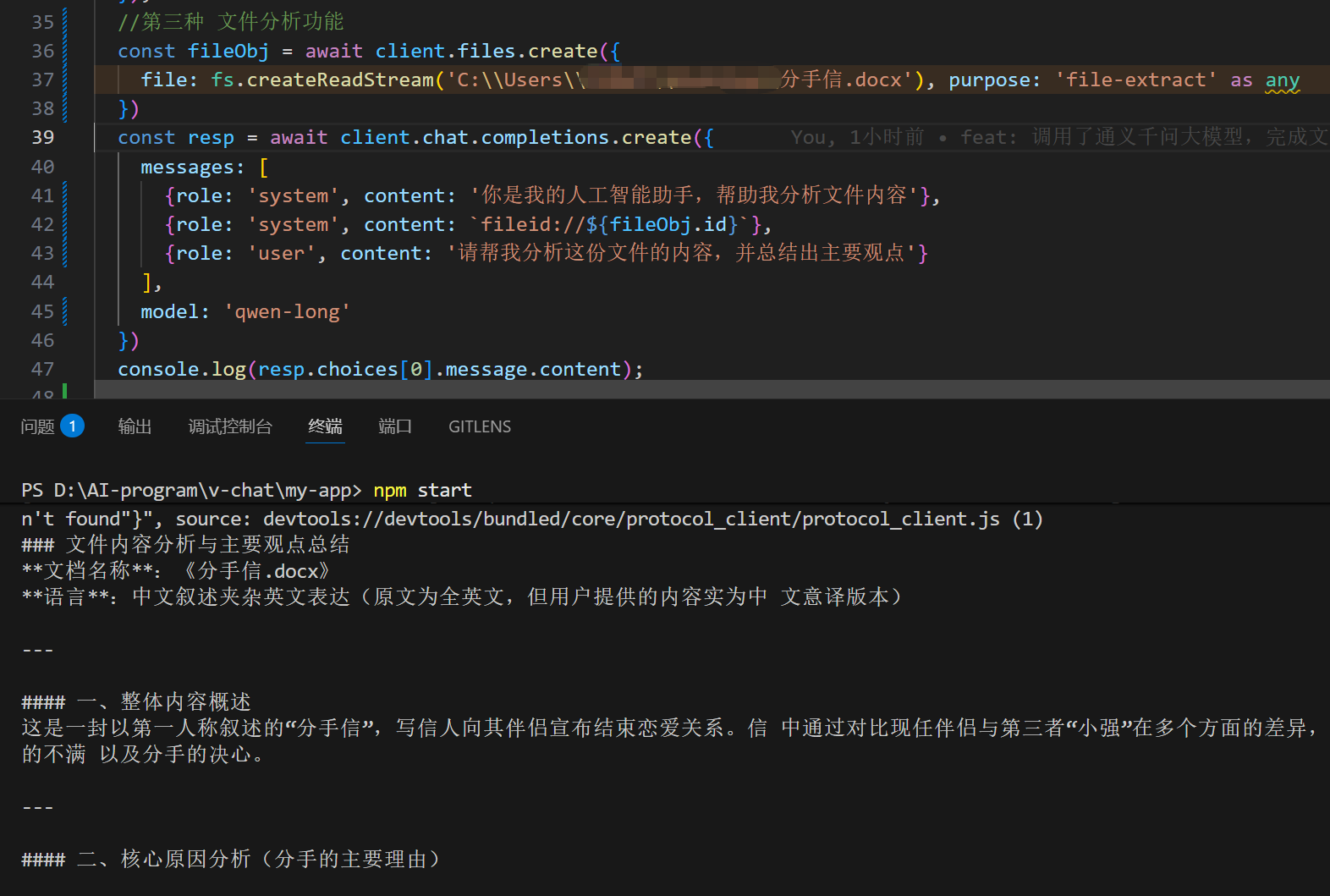
如上,完成完成文件分析操作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)