BLIP的架构蓝本:拆解VLMo的“混合模态专家”设计
论文标题:VLMo: Unified Vision-Language Pre-training with Mixture-of-Modality-Experts
作者:Microsoft (2021)
核心思想:引入“混合模态专家 (MoME)”机制,用一个统一的 Transformer 架构灵活切换三种模态角色,打破了双塔与单塔结构的物理壁垒。
1. 诞生背景与研究动机
自 2019 年多模态预训练(VLP)爆发以来,演化出了两条不同的技术路线。VLMo 的提出,正是为了解决这两条路线“非此即彼”的痛点。
1.1 双塔结构 (Dual-Encoder)
以 OpenAI 的 CLIP 为代表。其动机是假设存在一个共享特征空间,图文对通过独立编码后在该空间对齐。
-
优势:推理极快。图像和文本特征可以预先计算并存储,检索时只需计算余弦相似度。
-
缺点:缺乏深度交互。由于双塔在特征提取阶段完全互不往来,模型难以捕捉复杂的视觉推理信息(如物体间的空间关系、细节属性对应),导致在 VQA 等任务上表现平庸。
1.2 融合类模型 (Fusion-Encoder)
以 ViL-BERT 为代表。这类模型通过深层交互模块(如 Cross-Attention)强制图文在特征层面合体。
-
优势:建模能力极强,擅长处理复杂的推理任务。
-
缺点:计算复杂度爆炸。在图文检索任务中,每一对图文组合都必须共同通过融合层。这意味着
张图和
个文本需要进行
次前向计算,这种平方级的复杂度在海量数据面前几乎不可用。
1.3 VLMo 的解决方法
借鉴了 Switch Transformer 的稀疏激活思想,VLMo 提出了混合模态专家(MoME)。它的目的是:用一个统一的单编码器结构,实现模态间的高效交互,同时保留双塔结构在计算上的线性复杂度优势。
2. 核心架构:MoME-Transformer 详解
VLMo 的技术核心是一个名为混合模态专家 Transformer(Mixture-of-Modality-Experts Transformer,MoME-Transformer)的统一编码架构。理解这个结构,是理解 VLMo 一切设计决策的前提。
2.1 整体结构概览
先用一张图直观感受 MoME-Transformer 的骨架:MoME-Transformer 的每一层由两个子模块叠加而成:
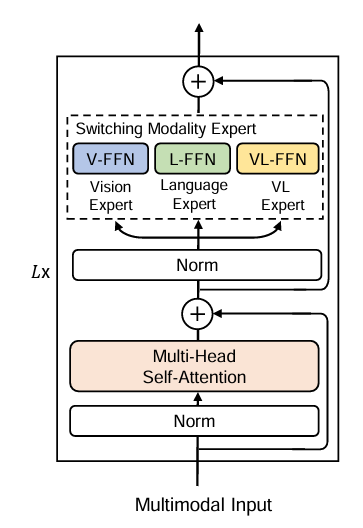
第一部分:共享的多头自注意力层(Shared MSA)。 无论输入是图像、文本还是图文混合数据,都会先通过这一个统一的注意力层。这是"共享"的关键之处——所有模态在此汇聚,相互感知彼此的信息。这与双塔结构形成了鲜明对比:双塔在这一阶段完全是两条平行线,永不相交。
第二部分:模态混合专家层(Switching Modality Expert,SME)。 经过 MSA 之后,不同模态的数据会"分流"到各自对应的前馈网络(FFN)专家中。SME 一共维护三个专家:视觉专家(V-FFN)、语言专家(L-FFN)、视觉-语言专家(VL-FFN),分别对应纯图像、纯文本和图文混合三种输入。每次前向计算,网络只激活其中一个专家,其余两个的参数保持沉默。
这种设计的妙处在于:参数不共享,但架构共享。 不同模态的数据在注意力层共享参数,促进了交互;而在 FFN 层,各模态拥有独立的专家参数,从而保留了各自的模态特异性表达能力。
2.2 三种输入的编码方式
在数据进入 MoME-Transformer 之前,需要先将图像和文本分别转换为 Transformer 可以处理的 token 序列。
图像编码 沿用了 ViT 的经典做法:将一张图片切成若干 patch,每个 patch 线性投影成一个 token 向量,再加上位置嵌入和类型嵌入。同时,在序列最前端加入一个特殊 token [I_CLS],用于聚合整张图的全局语义。
文本编码 则与 BERT 的处理方式几乎相同:使用 BPE 分词,添加 [T_CLS] 和 [T_SEP] 标志,最终的文本表示是词嵌入、位置嵌入与类型嵌入的逐元素相加。
图文混合编码 则更为简单直接——将图像 token 序列和文本 token 序列直接拼接,形成一个统一的多模态序列输入到模型中。
注:原论文中提供了更为严谨的公式化描述,这里为助于理解仅介绍基本思想。具体请参见原论文^_^。
3. 预训练策略
VLMo 的预训练可以从两个维度来理解:一是训练了哪些任务,二是按照什么顺序训练。
3.1 预训练任务一览
VLMo 总共涉及五类预训练任务,涵盖单模态和多模态两大类。
单模态训练分为两个:
-
掩码图像建模(MIM,Masked Image Modeling):源自 BEiT。随机遮盖图像中的部分 patch,让模型根据上下文预测被遮盖的 patch 所对应的视觉 token(visual token 来自 dVAE 的离散化编码)。这一任务专门用于训练视觉专家。
-
掩码语言建模(MLM,Masked Language Modeling):经典 BERT 策略。随机遮盖文本中 15% 的词,让模型预测被遮盖的词。这一任务专门用于训练语言专家。
多模态训练分为三个,具体参见下图:
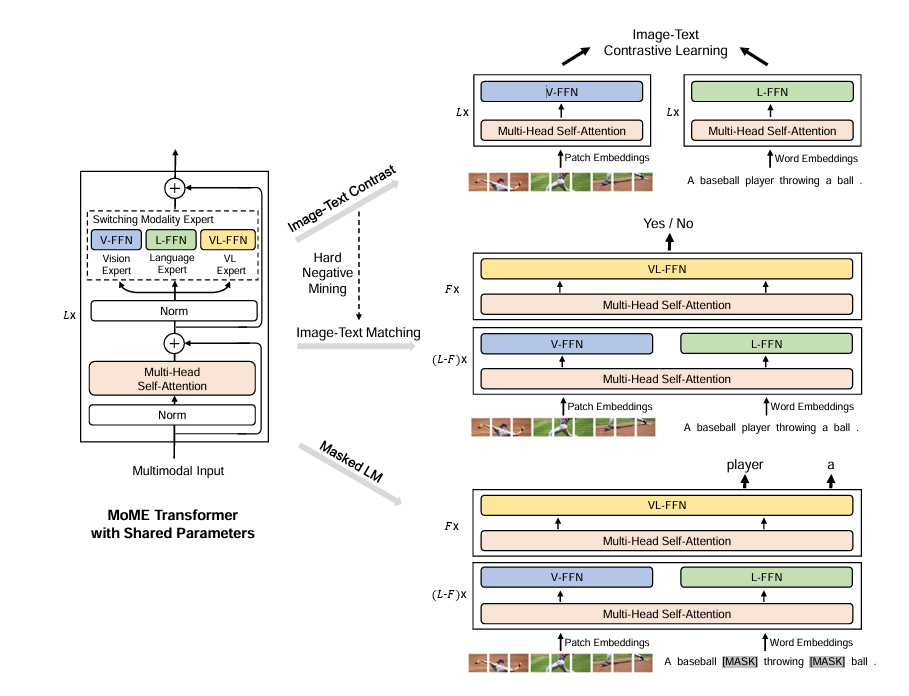
(1)图文对比学习(Image-Text Contrastive Learning,ITC)
给定 个图文对,对比学习构造了
个正样本和
个负样本。通过
[I_CLS] 和 [T_CLS] 两个聚合 token,分别得到图像特征向量 和文本特征向量
,再经过线性映射和 L2 归一化后计算余弦相似度:
通过 softmax 和可学习温度参数 ,得到图文对的匹配概率,并以交叉熵为损失优化。
(2)图文匹配(Image-Text Matching,ITM)
ITM 是一个二分类任务:判断一个图文对是否匹配。VLMo 取 [T_CLS] 对应的输出特征,接一个二分类头输出匹配概率。
值得注意的是,VLMo 借鉴了 ALBEF 的难负样本挖掘策略:不是随机采样负样本,而是利用 ITC 学到的相似度分布,以更高概率采样那些相似度高、但实际不匹配的"混淆样本"(hard negatives)。与 ALBEF 不同的是,VLMo 的难样本挖掘是跨 GPU 进行的,候选池更大,挖掘到的难负样本质量也更高。
(3)掩码语言建模(多模态版 MLM)
与纯文本 MLM 不同的是,多模态 MLM 在遮盖句子中 15% 的词之后,将被遮盖的文本和对应的图像一同输入到模型,让模型融合视觉信息来预测被遮盖的词。这迫使语言专家学会利用图像上下文补全语义缺口。
3.2 阶段预训练(Stagewise Pre-training)
这是 VLMo 在工程上最精妙的设计之一。由于涉及三类输入和三类专家,如果一股脑地同时训练所有任务,很容易出现梯度干扰或专家之间相互拉扯的问题。VLMo 引入了分阶段渐进式预训练来解决这个问题。
整个预训练分三个阶段进行,如下图所示,这三个阶段背后有着清晰的设计逻辑:
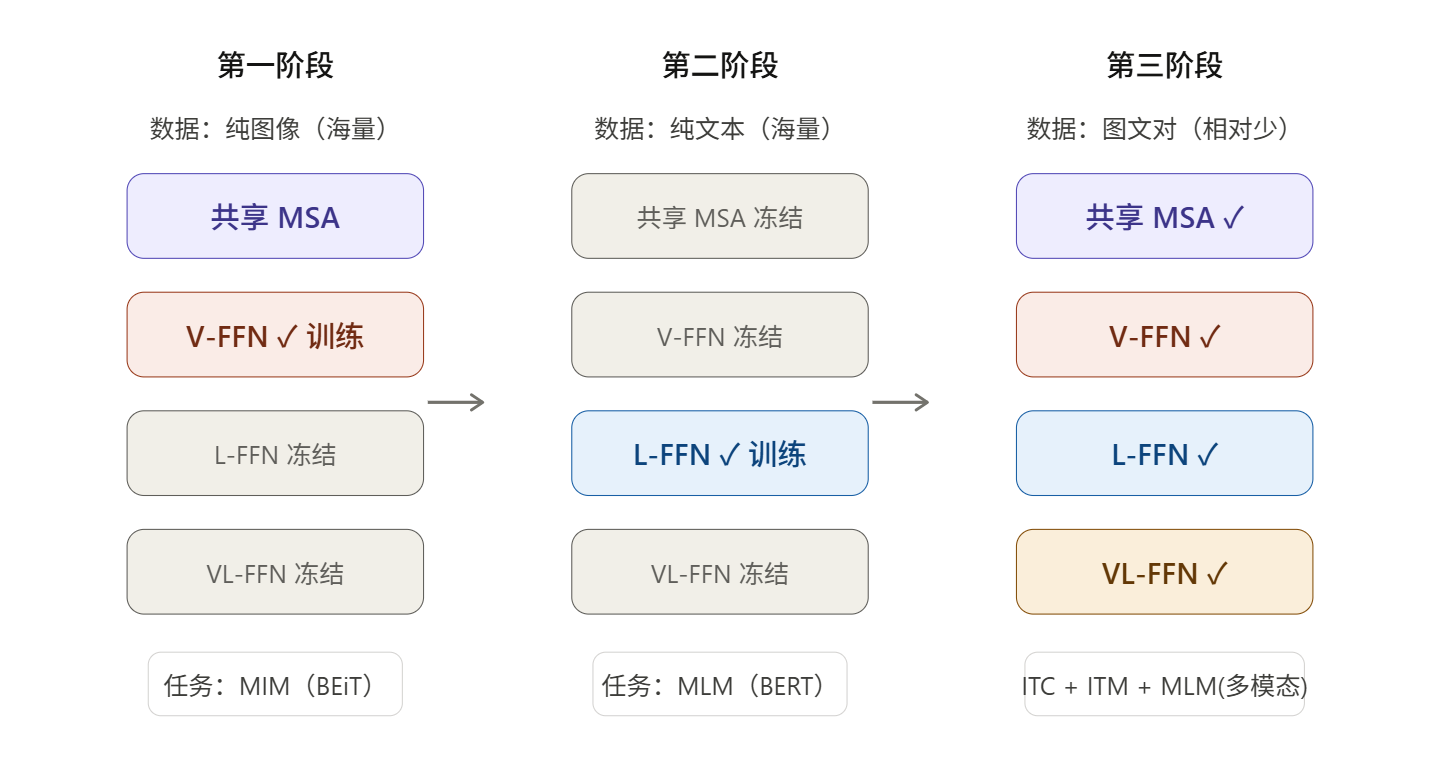
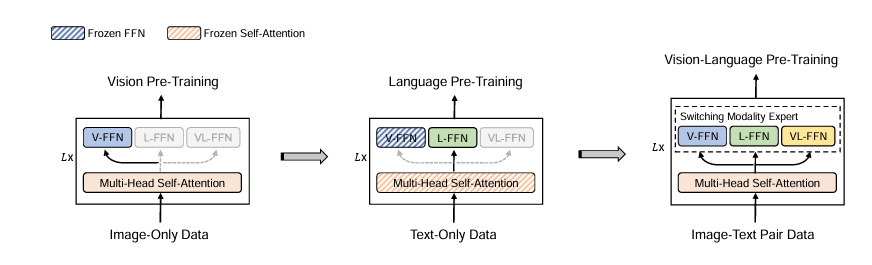
第一阶段:先让模型"看会图"。 利用互联网上海量的纯图像数据,通过 MIM 任务训练视觉专家。此时语言专家和 VL 专家的参数被冻结,等同于独立训练了一个完整的 BEiT 视觉模型。
第二阶段:再让模型"读懂文"。 利用同样海量的纯文本语料,通过 MLM 任务训练语言专家。此时共享 MSA 和视觉专家的参数都被冻结。这个冻结的关键意义在于:我们不希望文本任务的梯度反过来"污染"第一阶段辛苦学来的视觉表示。等同于在 BEiT 的基础上,另起炉灶地训练出了一个质量不错的 BERT。
第三阶段:最后学会"图文融合"。 解冻所有参数,在图文对数据上同时使用 ITC、ITM 和多模态 MLM 三个任务联合训练。由于前两个阶段已经给各专家提供了很好的初始化,这个阶段相当于在一个优质起点上做精细调优,而图文对数据相对较少也不会对已有能力造成过大破坏。
这种先单模态、再多模态的递进训练策略,在利用大规模易得数据和稀缺图文对数据之间取得了极佳的平衡,是 VLMo 在工程实践上的重要贡献。
4. 下游任务微调:一套架构,两种姿态
VLMo 最巧妙的地方之一,是同一套模型架构可以根据任务的特性灵活切换工作模式,无需为不同类型的任务设计不同的模型结构。
4.1 图文检索任务:以双塔模式运行
对于视觉语言检索(Visual Language Retrieval)任务,例如"给定一段文字,找出最匹配的图片",VLMo 将自己变身为一个双编码器。
具体做法是:图像和文本分别独立地通过各自对应的专家(图像走 V-FFN,文本走 L-FFN),得到独立的特征向量。推理时,可以预先离线计算好整个图像库和文本库中所有样本的特征向量,检索时只需用矩阵乘法计算相似度矩阵即可,计算复杂度是线性的 ,完全规避了融合类模型的平方级代价。
4.2 图文分类任务:以融合模式运行
对于视觉问答(VQA)等需要深度理解图文关系的分类任务,VLMo 则切换为融合编码器模式。
此时,图像 token 序列和文本 token 序列被拼接成一个统一输入,经过 VL-FFN 专家进行深度图文交互,最终取 [T_CLS] 对应的输出特征接一个分类头,输出最终的答案类别。
这种自适应的工作方式让 VLMo 真正做到了多任务融合:检索任务用双塔,速度飞快;分类任务用融合,精度有保障。
5. 实验结果与影响
VLMo 在多项主流多模态基准上取得了当时的 SOTA 水平:
- VQA(视觉问答):在 VQA v2 上达到了非常有竞争力的分数,超越了 ViLT 等此前的单编码器方法。
- NLVR2(自然语言视觉推理):在需要深度图文推理的任务上,VLMo 的融合模式显示出了远超双塔结构的能力。
- 图文检索(COCO / Flickr30K):在 Recall@1 指标上同样达到领先水平,且由于双塔推理模式,推理速度远快于纯融合模型。
6. 总结与延伸
回顾 VLMo 的全貌,它的价值不仅在于提升了某几个 benchmark 的数字,更在于它提出了一个清晰且可扩展的设计范式:
- 用共享的注意力层实现模态交互,用独立的专家 FFN 保留模态个性
- 用阶段预训练充分利用不同规模、不同来源的数据
- 用一套架构兼容检索与分类两类截然不同的下游任务
这套"一个架构、多种姿态"的思路,在此后的多模态研究中产生了深远的影响。Microsoft 随后在 BEiT v3 中将专家机制进一步泛化到更多模态与任务,成为 2022-2023 年的标杆工作之一。
而在 VLMo 发表的同年,Salesforce 提出的 BLIP 则从另一个角度继承并发展了这种"一模型,多角色"的理念。BLIP 同样意识到双塔与融合结构之间的张力,但它的切入点不是"专家 FFN",而是共享编码器 + 任务特异性解码头的组合,并引入了一套从嘈杂网络数据中自动生成高质量图文标注的 CapFilt 机制,将数据质量问题也纳入了统一框架的考量。
可以说,VLMo 解决的核心问题是"用一个架构做多件事",而 BLIP 在此基础上进一步追问:"用什么数据训练这个架构"。两者共同构成了这一时期多模态预训练研究从"结构设计"走向"数据-结构协同设计"的重要脉络。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)