Dify入门理解
1.理解Dify
## Dify 向量知识库的作用
简单来说,**向量知识库**是让大语言模型(如 GPT、Claude 等)能够“记住”你的私有数据并基于这些数据回答问题的基础设施。
---
### 一、为什么要用向量知识库?
大语言模型有一个核心限制:**它的知识只截止到训练时的时间点,且不包含你的私有数据**。
举个例子:
- 你问 GPT:“我们公司的员工请假流程是什么?”
- 它无法回答,因为它不知道你们公司的内部规定
**向量知识库的作用**:把你公司的《员工手册》《请假制度》等文档存入知识库,当用户提问时,系统会先去知识库里找到相关内容,然后把这些内容连同问题一起发给大模型,这样模型就能基于你的数据给出准确答案。
---
### 二、向量知识库的工作原理
整个过程可以分为三个阶段:
#### 阶段一:文档入库(索引)
```
原始文档 → 文本分块 → 向量化 → 存入向量数据库
```
1. **文本分块**:把一篇长文档切成多个小片段(通常几百字一段),便于精准检索
2. **向量化**:用 Embedding 模型将每个文本片段转换成一串数字(向量),这个向量代表了文本的语义
3. **存入数据库**:这些向量被存入专门的向量数据库(如 Weaviate、Milvus 等),方便后续快速检索
#### 阶段二:用户提问(检索)
```
用户问题 → 向量化 → 在数据库中搜索最相似的向量 → 返回相关文本片段
```
当用户提出问题时,系统会把问题也转换成向量,然后在数据库中找出最相似的几个向量,对应的文本片段就是“相关上下文”。
#### 阶段三:生成答案
```
用户问题 + 相关文本片段 → 发给大模型 → 生成最终答案
```
大模型结合用户的问题和检索到的相关内容,生成一个准确、基于事实的答案。
---
### 三、向量知识库的核心价值
| 价值 | 说明 |
|------|------|
| **私有数据接入** | 让模型能够处理公司内部文档、个人笔记等私有数据 |
| **时效性** | 解决模型知识过时的问题,知识库更新即可获取最新信息 |
| **降低幻觉** | 模型不再凭空编造,而是基于真实文档回答,大幅提升准确率 |
| **成本可控** | 相比把全部文档塞进上下文,向量检索只取相关内容,节省 Token 消耗 |
| **权限控制** | 可以在知识库层面做访问控制,不同用户看到不同的数据 |
---
### 四、Dify 中的知识库应用场景
在 Dify 里,向量知识库主要用在两类场景:
#### 1. 知识库问答应用
创建一个“知识库问答”类型的应用,上传你的文档(PDF、Word、网页等),用户就可以像使用一个专属客服一样提问。
**常见用途**:
- 企业内部知识库(HR 政策、技术文档、销售话术)
- 产品说明书问答
- 法律法规查询
- 学术论文检索
#### 2. 工作流中的知识库节点
在工作流编排中,可以添加“知识库检索”节点,将检索到的内容传递给后续的大模型节点或其他处理节点。
**常见用途**:
- 智能客服工单处理
- 内容审核辅助
- 多轮对话中的信息增强
---
### 五、一个直观的例子
假设你上传了一份《公司请假制度.pdf》,内容是:
> 员工请假需提前2天申请,由部门主管审批。事假每年不超过15天。
**用户问**:“请假要提前多久?”
**系统内部流程**:
1. 用户问题“请假要提前多久”被向量化
2. 在向量数据库中搜索,找到最匹配的文本片段:“员工请假需提前2天申请”
3. 将该片段和问题一起发给大模型
4. 大模型输出:“根据公司规定,请假需要提前2天申请。”
---
### 六、Dify 支持的向量数据库
Dify 支持多种向量数据库,你可以在 `.env` 文件中通过 `VECTOR_STORE` 配置:
| 数据库 | 特点 |
|--------|------|
| **Weaviate** | 默认选择,开源,适合中小规模部署 |
| **Milvus** | 企业级,支持大规模向量检索,性能强 |
| **Qdrant** | Rust 编写,性能优秀,轻量 |
| **Pgvector** | PostgreSQL 扩展,适合已有 PG 环境的用户 |
| **Chroma** | 轻量级,适合开发测试 |
---
### 总结
**向量知识库 = 大语言模型的“外挂硬盘”**
- 没有它:模型只能靠训练时的记忆回答问题,无法触及你的私有数据
- 有它:你可以把任意文档“喂”给模型,让它变成你专属领域的专家
2.理解 全文检索,向量检索及混合检索,相关参数配置的含义
## 一、三种检索模式的选择策略
在 Dify 的知识库召回设置中,你可以通过调整**权重设置**滑块,在三种检索模式之间灵活切换。选择哪种模式,取决于你的具体场景需求。
### 1. 关键词检索(权重 = 1,语义 = 0)
**工作原理**:基于用户输入的关键词进行全文匹配,使用 BM25 等算法计算文档与查询的词汇匹配度。
**适用场景**:
- 用户知道**确切的信息或术语**,如产品型号、编号、专业术语
- 需要快速在大量文档中检索
- 对计算资源消耗有要求(关键词检索资源消耗较低)
**典型案例**:
- 搜索“Device-X200”这样的精确型号代码
- 查找特定的错误代码“Error 404”
- 检索包含特定术语的法律条文编号
### 2. 向量检索(语义 = 1,关键词 = 0)
**工作原理**:通过 Embedding 模型将文本转换为向量,计算用户问题与知识库内容的向量距离,捕捉语义相似性。
**适用场景**:
- 处理**模糊查询**,用户可能用不同的表达方式描述同一概念
- 需要跨语言搜索(向量检索能捕捉不同语言之间的意义转换)
- 处理非结构化文本和自然语言查询
**典型案例**:
- 搜索“首部上映的星球大战电影”,能匹配到关于《星球大战:新希望》的内容
- 搜索“冬天的衣服”,能推荐羽绒服、大衣等相关商品
- 搜索“心电监护仪”,能匹配到“ECG设备”
**局限性**:可能召回语义相关但实际无关的“伪相关”文档,增加噪声干扰。
### 3. 混合检索(0 < 语义权重 < 1,0 < 关键词权重 < 1)
**工作原理**:同时执行向量检索和关键词检索,将两者的结果进行融合(如加权融合或倒数排名融合 RRF),兼顾精确匹配与语义理解。
**适用场景**:
- 需要**同时兼顾语义理解和精确的关键字匹配**
- 搜索意图同时包含模糊描述和精确术语
- 希望提升召回率的同时保证精准度
**典型案例**:
- 搜索“经济实惠的无线耳机”,同时需要按“低于100美元”过滤
- 技术支持场景:用户说“Python 报错 404”,既要匹配“404”这个精确数字,也要理解“Python”相关的语义内容
- 医疗设备问答:既需要精确匹配设备型号“X200”,也需要理解“如何操作”这样的语义意图
**权重调整技巧**:通过 `semanticRatio` 参数(在 Weaviate 中称为 `alpha`)平衡两种检索的权重:
- 语义权重 = 0 → 纯关键词检索
- 语义权重 = 0.5 → 语义和关键词各占一半
- 语义权重 = 1 → 纯向量检索
## 二、核心召回参数详解
在 Dify 的召回设置中,有两个核心参数需要配置:
### 1. Top K
**作用**:筛选与用户问题相似度最高的 K 个文本片段。
**设置建议**:
- **数值越高**:预期被召回的文本分段数量越多,信息覆盖更全,但可能引入噪声
- **数值越低**:召回结果更精简,但可能遗漏关键信息
- 系统会根据模型上下文窗口大小**动态调整**实际使用的分段数量
**典型值**:3-10 之间,根据业务场景调整。例如,精确问答场景可设为 3-5,综合报告场景可设为 5-10。
### 2. Score 阈值
**作用**:设置文本片段筛选的相似度阈值,只有超过该分数的结果才会被召回。
**设置建议**:
- **数值越高**(如 0.8-0.9):召回结果更精准,但可能遗漏相关内容
- **数值越低**(如 0.3-0.5):召回更多内容,但噪声增加
**典型值**:一般设置在 0.5-0.8 之间,根据对精度的要求调整。
## 三、进阶优化:重排序(Rerank)
当你关联了**多个知识库**时,Dify 会自动启用**多路召回 + Rerank 模式**。
### 为什么需要 Rerank?
当从多个知识库检索时,混合检索返回的结果可能来自不同的数据源,直接合并排序可能不够科学。Rerank 模型会对候选内容列表与用户问题进行**细粒度相关性评估**,将最匹配的内容排在前面。
### Dify 中的 Rerank 设置
Dify 提供两种 Rerank 设置方式:
1. **权重设置**(无需额外成本):通过调整语义/关键词权重比例条,系统自动重排序
2. **Rerank 模型**(需要配置外部模型):使用专门的 Rerank 模型(如 bge-reranker-v2-m3)进行重排序
**使用建议**:
- 对成本敏感、场景较简单 → 使用权重设置
- 追求极致精准度、多知识库复杂场景 → 配置 Rerank 模型
## 四、选择决策流程图
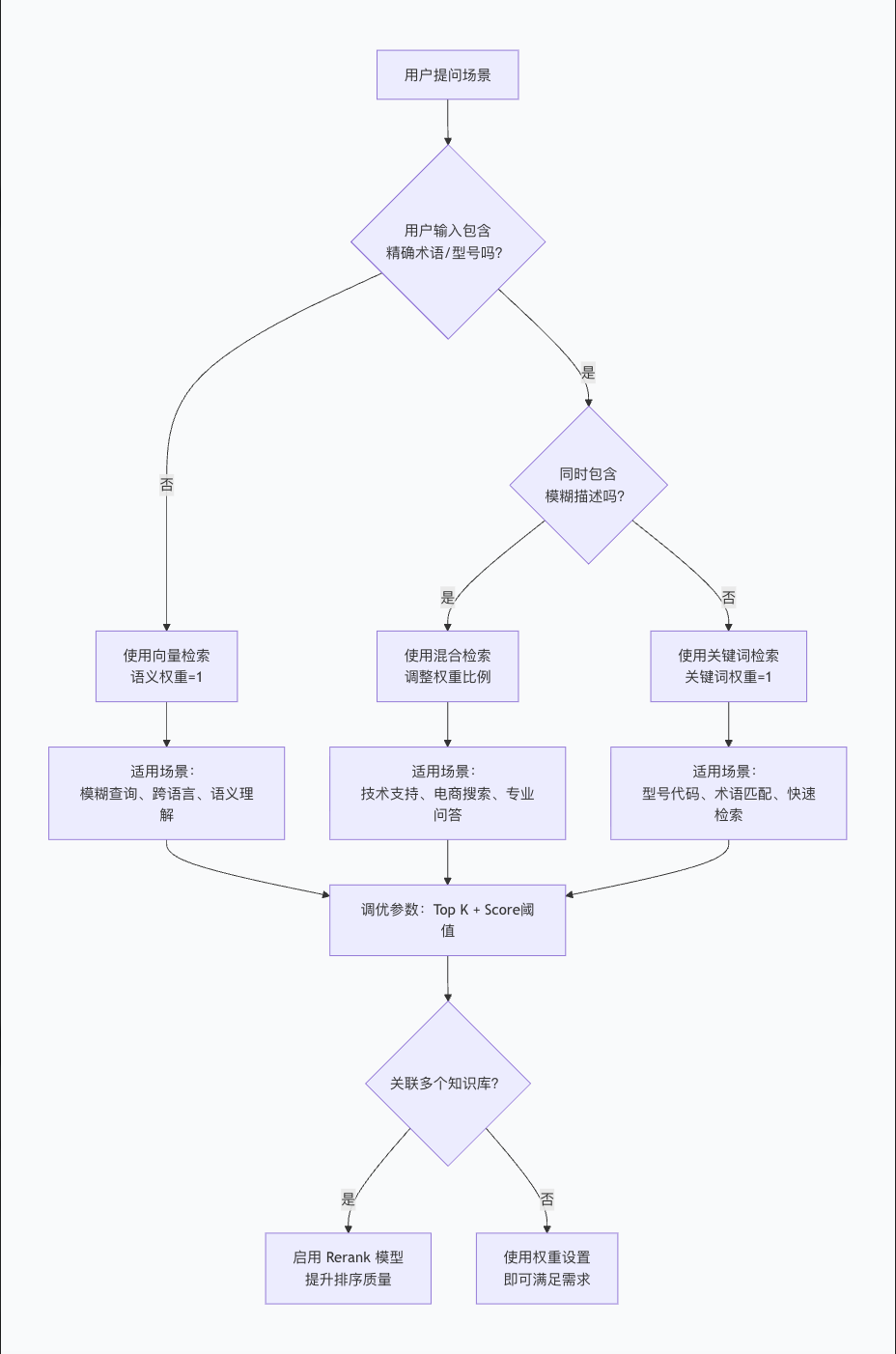
## 总结
| 检索模式 | 关键词权重 | 语义权重 | 最佳场景 |
|---------|-----------|---------|---------|
| 关键词检索 | 1 | 0 | 精确术语匹配、型号代码查询 |
| 向量检索 | 0 | 1 | 模糊查询、跨语言、语义理解 |
| 混合检索 | 0.3-0.7 | 0.7-0.3 | 技术问答、电商搜索、专业领域 |
在实际应用中,建议从混合检索开始(如语义权重 0.7、关键词权重 0.3),然后根据业务场景的反馈,逐步调整权重比例和 Score 阈值,找到最适合你知识库的最佳配置。
题外话!在设计相关业务场景时应注意一些细节.....
大模型 为什么要拆分成不同部分进行并行执行?
提示词好维护:拆分以后,每个提示词只需要写对应的部分,互不干扰,方便维护
并行加快计算时间:每个部分并行执行,比一个大任务执行时间更短。
以上都对,但并不是核心点,核心是因为为了防止“上下文腐烂”:
上下文腐烂(Context Rot)是一个描述大语言模型(LLM)在处理长文本时出现的性能下降现象的专业术语。简单来说,给模型的上下文信息不是越多越好,当输入长度超过某个限度,模型的理解和回答质量反而会变差
理解了问题所在,我们就可以采取更聪明的策略来与大模型协作,而不是盲目地将所有信息都塞给它。
对于普通用户:在与AI进行长对话或分析长文档时,可以有意识地帮助模型聚焦。
关键指令重述:在长对话的中后段,适时地重复最核心的要求和约束条件。
分步处理:将复杂的长任务拆解成几个步骤,一步一步地让模型处理,而不是要求它一次性消化所有信息。
∙先行摘要:如果有一篇很长的文章,可以先让模型或自己先对文章进行分段摘要,然后基于摘要进行提问。
∙对于开发者/AI应用构建者:需要通过系统设计来根本性地解决问题。
检索增强生成(RAG):这是最核心的解决方案。不要将整个知识库塞进上下文,而是先将资料存入向量数据库。当用户提问时,系统先自动检索出与问题最相关的几个信息片段,再将这一小段精准的信息连同问题一起交给模型生成答案。这能极大降低上下文中的噪声36。
上下文总结与剪枝:在RAG的基础上,可以先用一个小模型对检索到的内容进行摘要或删除无关部分,再将精华提交给主模型,进一步压缩上下文。∙赋予模型“外部记忆”:可以为AI设计像“笔记本”一样的工具,让它把重要的信息(如多轮对话的摘要、关键决策)记录在外部的存储空间中,需要时再读取,从而解放上下文窗口。
总而言之,面对上下文腐烂,最有效的策略是转变思维:将大模型视为一个强大的信息处理器,而非一个无限容量的记忆库。我们的目标不是一味地扩展上下文窗口,而是通过精心的“上下文工程”,持续为模型提供一份“少而精”的工作指南
### 一、 什么是父子分片?
“父子分片”的核心逻辑,可以理解为一个**多级索引**或**分治策略**。它的目的是为了在海量数据中进行快速检索,避免每次查询都要遍历所有数据。
它的工作流程大致分为两个阶段:
#### 阶段一:构建父子结构(建库时)
向量数据库会用一种聚类算法(比如K-means),把所有向量数据分成N个组。
* **父节点**:每个组会生成一个中心点(即**“父节点”**),这个中心点相当于这个组的“代表”或“目录”,代表了这群向量的整体语义。
* **子节点**:组内具体的每一个原始向量,就是**“子节点”**。它们不再被逐一比较,而是作为父节点下的一个“条目”被管理起来。
这个过程就像图书馆里**“总书目 -> 分类书架 -> 具体书籍”**的管理方式。
#### 阶段二:利用父子结构进行检索(查询时)
当你发起一个查询时,数据库会利用这个结构来缩小搜索范围,这也是父子分片发挥作用的关键:
1. **选择可能的分片**:系统会先计算你的查询向量,离哪个“父节点”(中心点)更近。它只会选择最接近的几个分片作为搜索目标,而不是搜索所有分片。
2. **在子节点中搜索**:确定目标分片后,系统才会进入这些分片内部,在有限的“子节点”(具体向量)中进行更精细的比对,找出最终的相似项。
这种“先粗后细”的父子结构,是实现高速向量搜索的基石。
---
### 二、 为什么向量库检索前要加载?
你感觉到的“检索前要加载”,其实是向量数据库在进行**预热**,或者更准确地说是**将索引加载到内存**的过程。这同样是为了追求速度。
向量检索的核心是**计算**。为了快速找到最近邻,数据库需要**索引**(比如上面提到的HNSW或IVF)。这些索引本质上是复杂的数据结构(如图或树),访问它们时**对延迟极度敏感**。
* **在磁盘上,太慢了**:如果把索引放在硬盘上,每次检索都要进行大量的随机磁盘I/O,延迟会高达毫秒甚至秒级,这对AI应用来说是难以接受的。
* **在内存中,飞速运转**:因此,数据库设计者会把索引尽可能地加载到**内存(RAM)** 中。CPU访问内存的速度比访问磁盘快几个数量级(纳秒级 vs 毫秒级)。
#### 为何会有“加载”这个动作?
* **首次访问/冷启动**:数据库刚启动时,索引还在磁盘上,第一次查询会触发“加载”动作,将索引调入内存,所以你会感觉到延迟。
* **数据量大,内存有限**:对于超大规模的数据,索引可能大到无法完全放进内存。这时,数据库就必须采用“父子分片”的策略,只把当前最可能需要用到的“父节点”和部分“子节点”分片加载进内存。
### 总结
* **父子分片**:是一种**逻辑分区策略**。它通过“先找目录,再翻书”的方式,避免了大海捞针式的全量搜索,解决了**“如何快”**的问题。
* **检索前加载**:是一种**物理部署手段**。它将索引数据提前放入CPU能直接高速访问的内存中,解决了**“如何更快”**的问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)