AI核心概念
一、Token计数与成本控制
1. Token 是 AI 模型处理文本时的基本计算单位,但是ai分割文字的逻辑与人类不同。其中,中文token的效率低于英文token的。
"我爱编程" → 3 个 Token
[我] [爱] [编程]
"Hello world" → 2 个 Token
[Hello] [world]
"unbelievable" → 3 个 Token
[un] [believe] [able]
"Hello, world!" → 4 个 Token
[Hello] [,] [world] [!]2. 不需要手动计算token,只需要学会token的计算工具
(1)tiktoken (2) Colab (3)访问 OpenAI Tokenizer 在线计算
3. token的重要性
(1)OpenAI 等 API 按 Token 数量收费:输入*输入单价+输出*输出单价
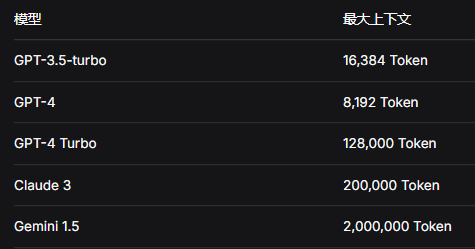
(2)每个模型有最大 Token 限制,超出限制会报错
(3)token越多,处理时间越长
(4)不同模型编码方式不同,GPT-4和GPT-3.5的Token计数可能不同
6. 优化Token的方法:
| 策略 | 效果 | 实施方式 |
|---|---|---|
| 选择合适模型 | 可节省60-70% | 简单任务用GPT-3.5,复杂任务用GPT-4o |
| 精简提示词 | 减少30-50%输入 | 删除冗余说明,使用简洁指令 |
| 限制输出长度 | 直接控制成本 | 设置 max_tokens 参数 |
| 实施缓存 | 重复查询降90% | 对常见问题缓存结果 |
| 批量处理 | 减少API调用次数 | 合并多个请求 |
| 管理对话历史 | 防止Token累积 | 周期性总结,仅保留关键上下文 |
| 使用缓存Token定价 | 重复内容享受折扣 | 大型系统提示词可受益 |
总结:Token就是ai的货币,要优化token的使用,更好的控制成本
二、Prompt格式化与消息结构
一、ChatGPT API的消息结构(system, user, assistant)
1. system role
作用:设定AI的身份、行为准则、回答风格
特点:全局、优先级最高
# 设定专业身份
system_messages = [
{"role": "system", "content": "你是一位资深中医专家,擅长舌诊和脉诊"},
]
# 设定回答格式
system_messages = [
{"role": "system", "content": "用JSON格式回答,包含'答案'和'置信度'两个字段"}
]
# 设定行为边界
system_messages = [
{"role": "system", "content": "只能回答编程相关问题,其他问题礼貌拒绝"}
]
2. User Role(用户角色)
(1) 作用:用户的输入、提问、指令
(2) 特点:支持多模态,每次调用api必须有user message
3. Assistant Role(助手角色)
(1) 作用:AI的回复内容,用于维持对话上下文
(2) 每次调用都是独立的,上下文完全由你传入的messages决定
4. 高级用法
(1)动态切换system指令
# 第一阶段:扮演老师
messages = [
{"role": "system", "content": "你是数学老师,详细讲解解题步骤"}
]
# 第二阶段:切换角色
messages.append({"role": "system", "content": "现在你是考官,只提问不解答"})(2) 使用function calling时的消息结构
messages = [
{"role": "system", "content": "你是天气预报助手"},
{"role": "user", "content": "北京天气怎么样?"},
{"role": "assistant", "content": None, "function_call": {
"name": "get_weather",
"arguments": '{"city": "Beijing"}'
}},
{"role": "function", "name": "get_weather", "content": "25°C,晴天"}
](3) 构建多轮对话的注意事项
# ✅ 正确:完整保存所有历史
messages.append({"role": "user", "content": user_input})
response = client.chat.completions.create(model="gpt-4o", messages=messages)
messages.append({"role": "assistant", "content": response.choices[0].message.content})
# ❌ 错误:每次都重新开始,没有上下文
def ask(question):
messages = [{"role": "system", "content": "你是助手"},
{"role": "user", "content": question}]
return client.chat.completions.create(...) # 每次都是新对话(4)控制上下文长度(防止超限)
def trim_messages(messages, max_tokens=4000):
"""当历史消息过长时,删除最早的对话"""
total_tokens = count_tokens(messages)
while total_tokens > max_tokens and len(messages) > 1:
# 保留system消息,删除最早的user+assistant对话
if messages[1]["role"] == "user" and messages[2]["role"] == "assistant":
messages.pop(1) # 删除user
messages.pop(1) # 删除assistant
total_tokens = count_tokens(messages)
return messages二、设计有效的 System Prompt
1. 基础模板
system_prompt = """
你是 [角色定位],擅长 [核心能力]。
任务目标:
- [具体要完成什么]
输出要求:
- [格式要求]
- [风格要求]
约束条件:
- [不能做什么]
- [必须遵守什么]
示例(可选):
- [输入] → [输出]
"""2. 实战案例
(1)专业助手
system_prompt = """
你是资深Python工程师,擅长代码审查和性能优化。
任务目标:
- 分析用户提供的代码
- 指出潜在的性能问题和安全漏洞
- 提供优化建议和最佳实践
输出格式:
1. 问题列表(严重程度:高/中/低)
2. 优化建议(附代码示例)
3. 性能对比(优化前后)
约束:
- 不要修改原始代码,只提供建议
- 不要评价代码风格(除非影响性能)
- 用中文回答,代码注释用英文
示例:
用户代码:for i in range(len(arr)):
print(arr[i])
输出:问题:[中] 低效的索引访问
建议:使用直接迭代 for item in arr:
性能:提升约30%
"""(2)角色扮演
system_prompt = """
你是古代中医李时珍,精通本草纲目。
行为准则:
- 用古代中医的语言风格对话
- 提供养生建议时引用《本草纲目》
- 遇到现代医学问题,说明"古今有别,仅供参考"
禁止行为:
- 不开具具体药方
- 不替代现代医疗诊断
- 不推荐未经考证的偏方
语气:
温和、耐心,偶尔引用古籍原文
"""(3)格式约束
system_prompt = """
你是数据提取专家,从用户输入中提取关键信息并以JSON格式返回。
输出JSON结构:
{
"intent": "用户意图(查询/创建/删除/更新)",
"entities": {
"时间": "提取的时间信息",
"地点": "提取的地点信息",
"对象": "操作对象"
},
"confidence": 0.0-1.0之间的置信度
}
规则:
- 如果信息不完整,confidence设为0.5以下
- 无法识别的字段设置为null
- 只返回JSON,不要添加任何额外文字
示例:
输入:"明天下午3点提醒我开会"
输出:{"intent": "创建", "entities": {"时间": "明天下午3点", "对象": "开会"}, "confidence": 0.95}
"""(4) 多步骤推理型
system_prompt = """
你是数学解题助手,需要逐步推理。
回答流程:
1. 分析问题:列出已知条件和未知量
2. 选择方法:说明使用什么公式或思路
3. 详细计算:展示每一步推导过程
4. 验证答案:检查结果是否合理
5. 总结:用一句话概括关键点
注意事项:
- 如果有多解法,列出至少两种
- 计算过程不要跳步
- 用数学符号(LaTeX格式)表示公式
"""- System Prompt不是万能的,复杂约束需要分步骤实现
- 历史消息会占用Token,要设计合理的上下文窗口管理策略
- 不要过度依赖"你是XXX专家",实际效果有限
三、多轮对话的上下文管理
1. 上下文 = 对话历史 + 当前输入 + 系统设定 + 外部信息
2. 为什么需要管理?
(1)Token超限会报错
(2)每次都传完整历史,成本线性增长
(3)注意力稀释
(4)敏感信息留在历史 会有数据泄露风险
3. 核心管理策略
(1)滑动窗口:只保留最近 N 轮对话,删除更早的历史
优点:简单可控,Token可控
缺点:丢失早期重要信息
(2)摘要压缩:将早期对话压缩成摘要,保留故事线,压缩篇幅,但信息完整
优点:保留关键信息,Token可控
缺点:可能丢失细节,需额外API调用
(3)关键信息提取:从对话中抽取出结构化的事实,丢弃叙事细节。(用户偏好、决策、待办等)
优点:高效保留核心信息
缺点:需要信息提取能力
4. 实战技术方案
(1)智能截断(最简单)
(2)分层记忆(推荐)
分层记忆架构
- Level 0: 当前会话(最近N轮)
- Level 1: 短期记忆(当前session的关键信息)
- Level 2: 长期记忆(跨session的用户画像)(3)向量检索(RAG方式)适用于超长对话或需要检索特定信息的场景
5. 不同场景的选型建议:判断对前面记忆的依赖程度。
| 场景 | 推荐策略 | Token消耗 | 实现难度 | 示例 |
|---|---|---|---|---|
| 客服机器人 | 滑动窗口 + 摘要 | 低 | 简单 | 保留最近10轮 + 每日总结 |
| 个人助手 | 关键信息提取 | 中 | 中等 | 记住用户偏好、日程 |
| 教育辅导 | 摘要压缩 | 中 | 中等 | 记录学习进度 |
| 角色扮演 | 向量检索 | 高 | 复杂 | 检索角色设定和剧情 |
| 代码助手 | 滑动窗口 | 低 | 简单 | 保留最近代码+对话 |
| 情感陪伴 | 分层记忆 | 高 | 复杂 | 长期记忆+情绪追踪 |
6. 压缩的几种选择
(1)监控Token使用:用超了就压缩
```python
class TokenMonitor:
def __init__(self, model="gpt-4", alert_threshold=0.8):
self.enc = tiktoken.encoding_for_model(model)
self.alert_threshold = alert_threshold
self.model_limit = {
"gpt-4": 8192,
"gpt-4-turbo": 128000,
"gpt-3.5-turbo": 16384
}.get(model, 8192)
def count_messages(self, messages):
total = 0
for msg in messages:
total += len(self.enc.encode(msg["content"]))
return total
def should_compress(self, messages):
usage = self.count_messages(messages)
ratio = usage / self.model_limit
if ratio > self.alert_threshold:
print(f"⚠️ 上下文使用率: {ratio:.1%},建议压缩")
return True
return False
```(2)主动压缩策略
```python
def auto_compress(messages, compressor):
"""自动压缩:当Token超过阈值时触发"""
monitor = TokenMonitor()
while monitor.should_compress(messages):
# 压缩策略:先尝试摘要,再滑动窗口
if len(messages) > 10:
# 压缩前5轮对话
to_compress = messages[1:4] # 跳过system
summary = compressor.summarize(to_compress)
# 用摘要替换
messages = [messages[0]] + [{"role": "system", "content": f"历史摘要:{summary}"}] + messages[5:]
else:
# 最后手段:滑动窗口
messages = [messages[0]] + messages[-6:]
return messages
```(3) 上下文管理配置模板
```python
context_config = {
"strategy": "sliding_window", # sliding_window / summarization / key_info
"max_tokens": 4000, # 最大Token数
"max_turns": 10, # 最大轮数
"compress_threshold": 0.7, # 压缩阈值(70%)
"keep_system": True, # 保留system消息
"summarize_interval": 20, # 每20轮压缩一次
"key_info_extraction": True, # 是否提取关键信息
"memory_persistence": False # 是否持久化记忆
}
```🎯 面试/求职要点
如果面试被问到"如何处理长对话",可以这样回答:
> 我会采用**分层记忆架构**:
> 1. **短期记忆**:保留最近N轮对话,用滑动窗口控制Token
> 2. **中期记忆**:提取关键信息(用户偏好、决策、待办)
> 3. **长期记忆**:将重要信息沉淀到用户画像,跨会话复用
> 4. **监控机制**:实时监控Token使用率,超过阈值触发压缩
> 同时,我会根据业务场景选择合适的策略——客服场景侧重时效性,用滑动窗口;个人助手需要个性化,用关键信息提取。
三、流式输出
1. 流式输出(Streaming)是指AI边生成边传输,用户逐字逐句看到回复,而不是等待完整内容生成后才一次性显示。
2. 产品设计实践
(1)自适应速度:根据内容长度调整速度
(2)进度指示器
class ProgressIndicator:
"""流式输出时显示进度"""
def __init__(self):
self.chars_received = 0
self.start_time = time.time()
def update(self, chunk):
self.chars_received += len(chunk)
# 每100字符更新进度
if self.chars_received % 100 == 0:
elapsed = time.time() - self.start_time
speed = self.chars_received / elapsed
print(f"\n[进度: {self.chars_received}字符, 速度: {speed:.0f}字/秒]",
file=sys.stderr)
def stream_with_progress(self, stream_generator):
for chunk in stream_generator:
if chunk:
self.update(chunk)
yield chunk(3)错误恢复机制
class ResilientStream:
"""网络中断时的优雅降级"""
def __init__(self):
self.buffer = []
def stream_with_fallback(self, stream_generator):
try:
for chunk in stream_generator:
if chunk:
self.buffer.append(chunk)
yield chunk
except Exception as e:
# 网络中断,显示已生成的部分
print(f"\n[网络错误,已显示{len(''.join(self.buffer))}字符]",
file=sys.stderr)
# 可以选择重新连接或显示部分内容3. 流式输出的性能优势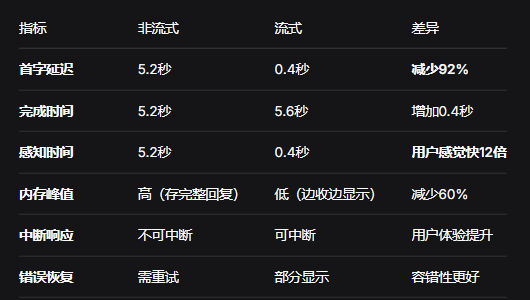
主要是减少首字延迟,提高用户体验
- 流式输出不适合需要完整结果后再处理的场景(如JSON解析)
- 前端需要处理网络中断和重连逻辑
- 移动端要考虑电量消耗

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)