MinerU-Diffusion发布:我们想重新回答,文档 OCR 到底该怎么做
在大模型、知识库和智能文档应用快速发展的今天,OCR 已经不再只是一个“把图片里的文字识别出来”的基础工具。对科研论文、财报、专利、合同等高价值文档来说,OCR 的效果直接决定了后续信息抽取、知识建库和智能问答的质量。也正是在这一过程中,我们越来越清楚地意识到,文档 OCR 面临的核心问题,已经不只是“能不能识别”,而是“能不能以更高效率、更强稳定性和更好结构一致性,把复杂文档真正解析出来”。
长期以来,行业中相当一部分 OCR 系统仍沿用自回归解码范式,将文本识别建模为从左到右逐 token 生成的序列问题。这是一种成熟而常见的技术路径,但我们认为,它与文档 OCR 的任务本质并不完全一致。文档并不是天然的一维文本流,而是包含阅读顺序、页面布局、表格、公式等信息的二维视觉对象;最终输出的文本,本质上更像是对这些结构的线性化还原,而不是一次语言意义上的“创作”或“续写”。正是这种任务本质与建模方式之间的错位,使得传统路径在实际应用中逐渐暴露出推理串行、误差累积、过度依赖语言先验等问题。
基于这样的判断,上海人工智能实验室 OpenDataLab 团队(我们)提出了 MinerU-Diffusion——一种基于掩码扩散语言模型的OCR框架。我们希望改变的,并不是传统 OCR 流程中的某一个局部模块,而是更底层的建模思路:不再把文档 OCR 主要看作语言驱动的序列生成问题,而是将其重新定义为一种在视觉约束下逐步恢复文本结构的“逆向渲染”过程。换句话说,我们更关注模型如何依据整页文档的视觉信息,把原本已经存在于文档中的结构化文本并行恢复出来,而不是依赖固定顺序去逐步“猜测”下一个 token。
🧾 论文链接:https://arxiv.org/abs/2603.22458
⭐ 开源仓库:https://github.com/opendatalab/MinerU-Diffusion
🔗 开源模型: https://huggingface.co/opendatalab/MinerU-Diffusion-V1-0320-2.5B
🧰在线demo: https://huggingface.co/spaces/opendatalab/MinerU-Diffusion-V1-0320-2.5B
MinerU-Diffusion处理速度展示
MinerU-Diffusion与 MinerU2.5 对复杂文档解析速度对直观对比
一、当行业还在逐字生成时,我们选择从“恢复结构”出发
围绕这一思路,MinerU-Diffusion 采用离散扩散解码来替代传统自回归解码。与行业中更常见的串行生成方式不同,扩散解码不依赖严格的从左到右顺序,而是在多个位置上同时进行预测与修正,使文本在视觉信息和上下文约束下被逐步还原。我们认为,这种方式更符合文档 OCR 的任务特征:文档中的 token 关系主要受空间结构约束,而不完全来自语言上的因果依赖。因此,采用并行恢复的方式,不仅更自然,也更有机会同时提升效率和全局一致性。
这也是 MinerU-Diffusion 与行业通行做法最核心的区别。传统方法的优势在于路径成熟、工程经验丰富,但它天然受到串行解码的约束,面对长文档、复杂版式以及大规模生产场景时,速度和成本压力会更加明显;同时,在表格、公式、跨行排版等结构化内容中,一旦前序 token 预测出现偏差,错误也更容易沿生成链路逐步放大。相比之下,我们的方法更强调直接利用整页视觉证据和全局结构信息,减少对语言先验补偿的依赖,从而在复杂结构场景下获得更稳定的表现。

图1:扩散解码在视觉条件约束下,从被掩码的标记中逐步重建结构化文本:黑色标记已确认,红色标记正在更新,黄色标记仍处于掩码状态,这实现了具有全局一致性的并行生成,与自回归的从左到右解码形成对比。
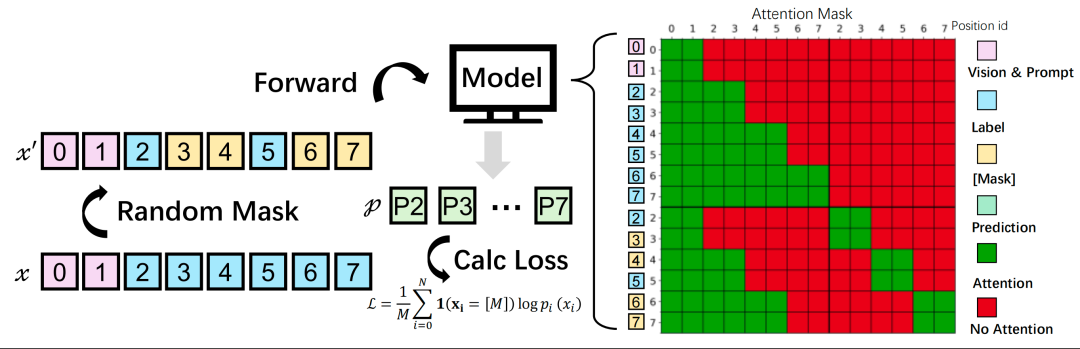
图2:MinerU-Diffusion的训练过程。左图:对目标标记序列进行随机掩码处理,形成部分可见的输入,模型在视觉和提示条件的约束下仅对掩码位置进行预测。右图:训练过程中使用的结构化块注意力掩码,其中标记在每个块内进行双向注意力计算,对所有先前的块进行因果注意力计算,这使得块内能够进行并行扩散优化,同时保留块间的粗略自回归结构。
二、更快,不靠牺牲精度来换
从公开结果来看,这一路径带来了较为明显的实际收益。MinerU-Diffusion 的 TPS (Throughput Per Second)最高可达到 MinerU2.5 的 3.26 倍;在 99.9% 相对精度下,仍可实现 2.12 倍加速;在 98.8% 相对精度下,可实现 3.01 倍加速。2.5B 参数模型在基础配置下,相较 1.2B 自回归模型实现了 5.1 倍推理速度提升。对真实业务场景来说,这意味着我们并不是单纯为了追求速度而牺牲质量,而是在尽可能保持高精度的前提下,显著缓解了文档解析中的时延和成本压力。
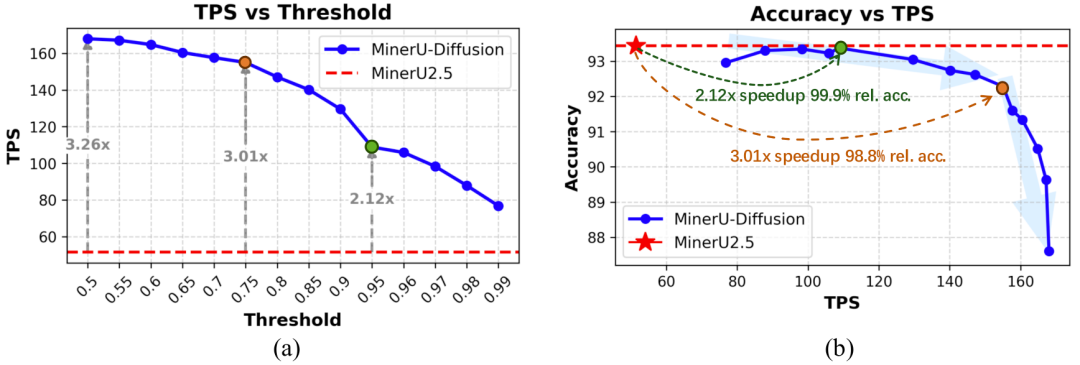
图3:MinerU-Diffusion通过阈值控制提供了灵活的精度-吞吐量权衡。与MinerU2.5相比,它的TPS(Token Per Seconds)最高可达3.26倍,同时还提供了实用的trade-off point,例如在99.9%的相对精度下实现2.12倍的加速,以及在98.8%的相对精度下实现3.01倍的加速。
除了速度,稳定性同样重要。在 Semantic Shuffle 语义扰动测试中,随着扰动程度增加,基于自回归解码的模型性能下降更为明显,而 MinerU-Diffusion整体表现更稳定。这个结果说明,我们的方法在预测时更直接依赖视觉信号,而不是主要依靠语言先验来“补全”结果。对于复杂文档解析而言,这种差异具有很强的现实意义,因为企业和科研场景真正关心的,往往不是平均条件下的表现,而是在复杂版面、异常排版和受扰动输入条件下,系统是否仍然能够保持可靠输出。
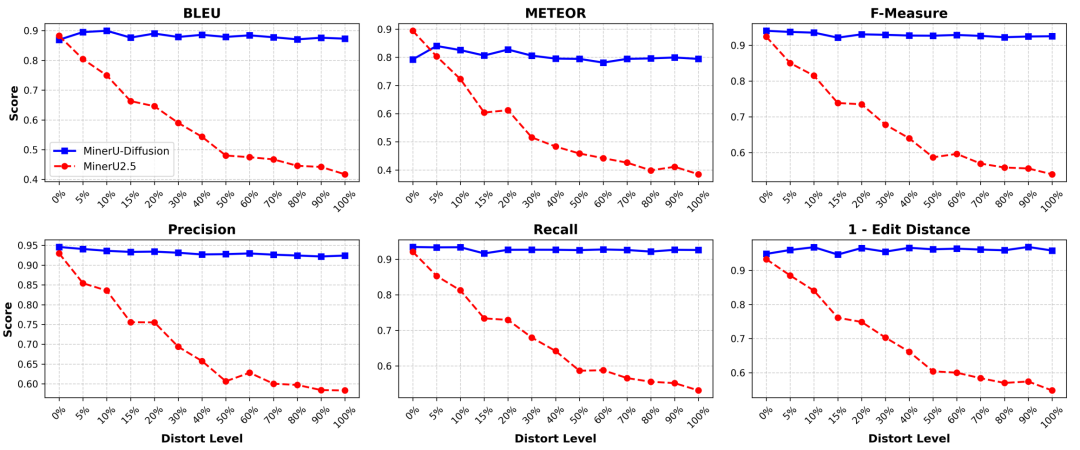
图4:不同失真程度下的Semantic Shuffle基准测试结果。
为了兼顾并行恢复能力和结构一致性,我们在训练过程中还引入了结构化块注意力机制,在块内进行双向注意力计算,同时在块间保留有序约束。我们这样设计,并不是为了单纯增加模型复杂度,而是希望在提升并行效率的同时,依然维持长文本结构上的整体连贯性。因为对文档任务来说,真正有价值的从来不是孤立的字符识别能力,而是能否把页面中的层级、顺序和结构一起稳定还原出来。
三、我们想证明的,是文档 OCR 可以有一条新路径
从更大的视角看,MinerU-Diffusion 的意义并不只是一次性能优化。我们更希望它能够说明,文档 OCR 这类任务未必必须沿着行业已经熟悉的自回归语言生成路径继续演进。对于文档解析而言,如果问题的本质是从二维视觉结构到一维文本序列的确定性映射,那么更贴近任务本质的建模方式,理应来自视觉驱动的结构恢复,而不只是语言驱动的顺序生成。我们认为,这种重新定义,不仅有助于提升复杂版面理解、表格与公式识别、结构化信息抽取等能力,也会为 RAG 知识库构建等下游应用提供更可靠的底层支持。
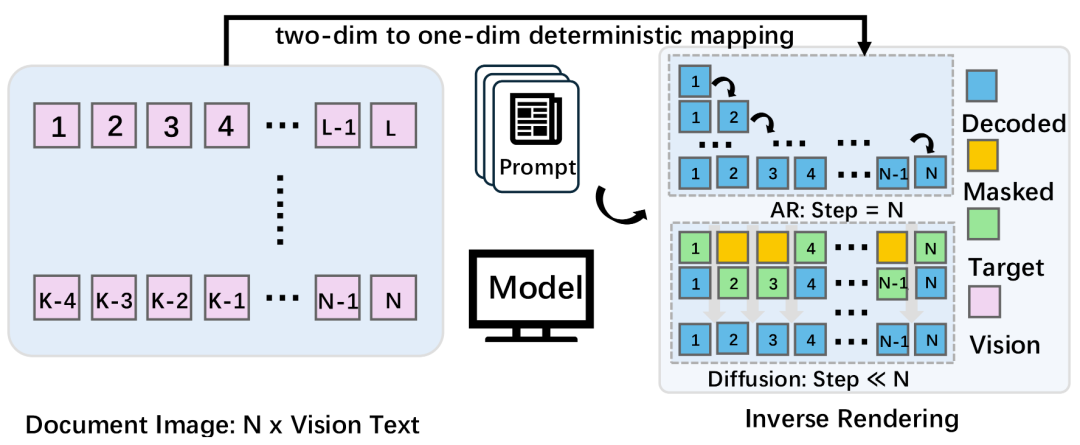
图5:文档 OCR 逆渲染推理过程在不同解码方法下的概述。模型将二维文档图像映射为一维的 token 序列,并通过自回归方法和基于扩散的方法进行解码。
对我们而言,MinerU-Diffusion的价值不只是“更快了一些”,而是证明了一条新的技术路径是可行的:当我们不再把 OCR 简单视为生成文本,而是把它看作恢复结构,很多长期被视为理所当然的瓶颈,就有机会被真正改写。这也是我们希望通过这项工作传递出的核心信息——在文档智能进入更深应用阶段的当下,重新理解问题本身,往往比单纯优化旧路径更重要。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)