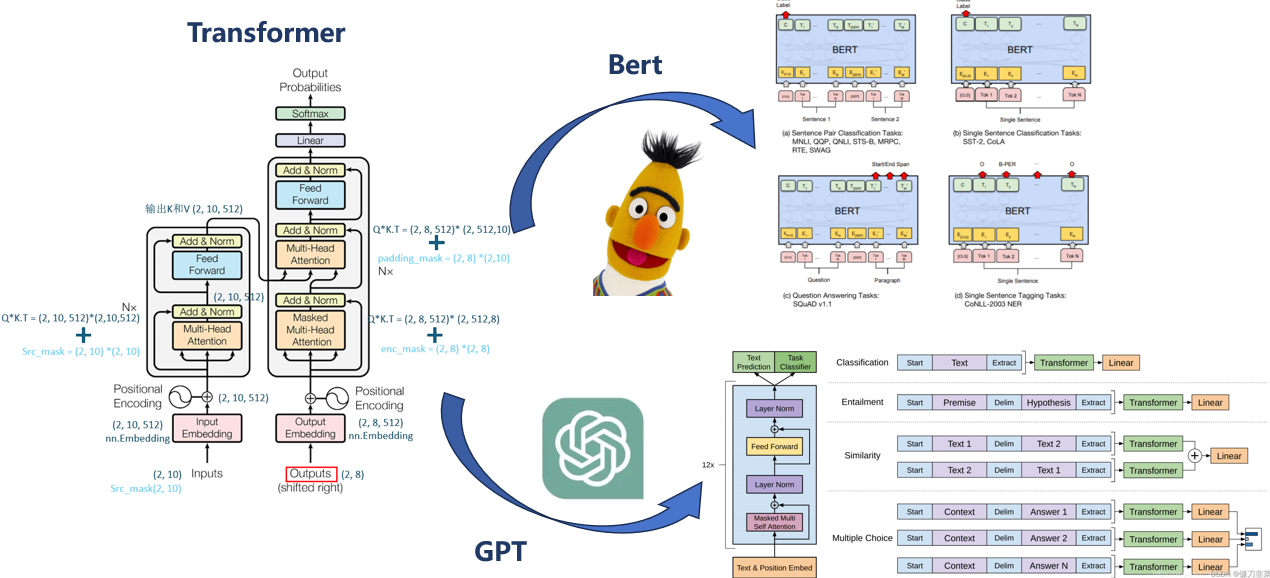
【2】LLM篇 事无巨细!手把手带你用transformer做一个中英翻译模型从原理到实战一网打尽
0.前言
爽玩了一个星期,感觉整个人都放松了。收收心新的一周又开始了,这个一期打算用很通俗的方法把transformer的结构讲一下,中间我会用我自己对这个东西的理解,去讲解一下。如果有不对的地方请批评指正。没看过上一篇请跳转
【1】LLM篇 事无巨细!手把手带你用transformer做一个中英翻译模型从原理到实战一网打尽-CSDN博客
1. transformer结构
讲模型其实很多博主或者论文讲的东西其实都有点问题
误区一 他会告诉你,这个结构怎么怎么样,有什么什么效果。如果不是很权威实验,这些基本都是它瞎猜的,模型训练出来的结构,真正赋予它意义的是损失函数,而非模型本身。模型只是做一些简单的矩阵运算,是损失函数强制让真值往最小的损失方向去靠,模型不具备这个能力。很多水yolo模型的论文可以看到,越前面的卷积拥有丰富的位置信息,后面的卷积拥有丰富的语义信息。那我随机从backbone里抽出一个,和head抽出一个,我不见得谁比谁卷积多了什么,他们是相互的一个整体。你又要问,增加注意力模型,涨点了怎么解释。涨点说明模块在参数更新的时候让模型更加偏向于val数据集的真实分布,而非你认为模型有什么语义信息,所以增加模块会怎么样。这纯属胡扯。
误区二 模型并不是学习,只是在用各种函数去拟合你给的训练集的特征分布,你训练一个模型认识苹果,他只会让这个函数提取一张具有真实苹果的图片来拟合苹果这个标签。推理的时候,模型遇到一个图片,放入函数的时候如果和标准答案分布很像的时候,就会告诉你这是苹果。而且赋予模型拟合的东西叫做损失函数,损失函数约定谁和谁的差值,才是这个模型真正拟合的东西。
所以在我的博客中,我会告诉你这是在训练过程还是推理过程,还会用通俗易懂的例子让你去记住这个是什么东西。
1.1 整体看一下这个模型
对于最开始的模型来说,他有编码器也有解码器。但是这个参数大,推理缓慢,所以最后就分为两大阵营(encoder和decoder),今天的话我们还是讲一讲地地道道的transformer,后续在讲一讲他的变体。
1.2 词嵌入
上一期我们已经讲到,数据主要被分为了一串固定id的数字,比如【256,125,365,0,0】,这时候其实模型也没法训练,你说256和125有啥关系呢。为啥没关系,就是因为没有特征!!还是用简单的分类模型来说,[b,c,h,w]是里面的数据结构,既然一张图h和w就可以告诉你是一张图了。为啥要c这个维度,因为c是每个图的特征。比如h和w都取第一个和最后一个像素点,他俩都是0.7,抛去卷积有平移不变性,这两个0.7除了表示亮度,能区他俩这个0.7有不同吗?是不是不能,那如果c这个维度上有512个值,最后一个像素点和第一个像素点,就有512个值。即使大家都是0.7,但是后续511个值都不一样,就可以有区分。
19和18固然近,但是19和17也一样近,你不能说18和17对应的字是一样的吧。所以我们要想办法让这些一连串的数字增加一个维度,让他们不再是一维坐标里的值。这时候就引用一个东西词嵌入,在pytorch就是一行 nn.embedding(vocal,dim)内部结构呢,其实就是查表。
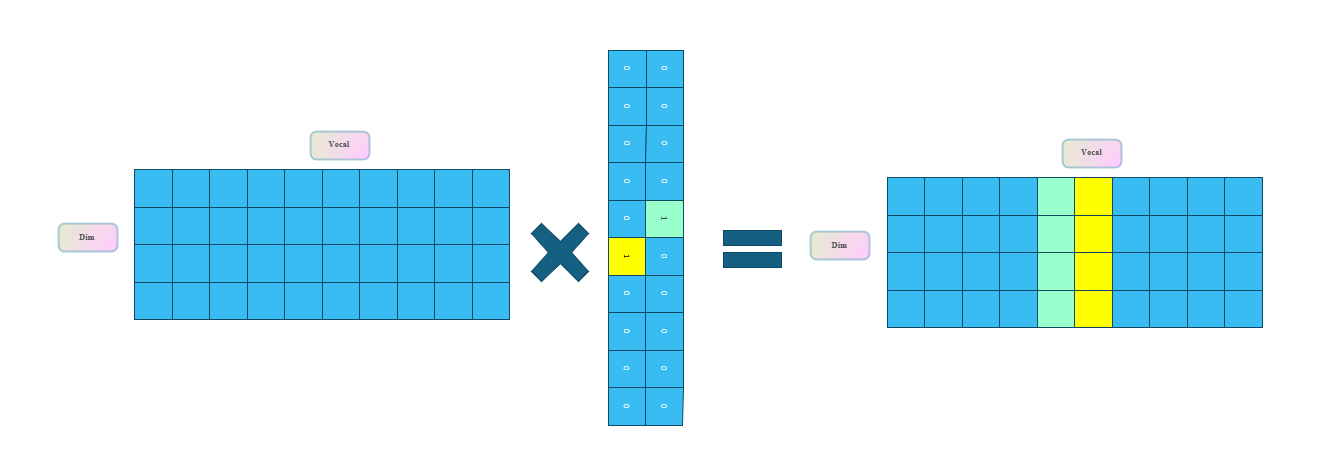
比如说现在就训练了10个词,每个词4个维度。这时候5和6出现,先把5和6变成onehot,然后你去和矩阵相乘(查表),你会发现只有5号和6号的维度是起作用的,其他都为0,所以反向传播的时候之后5和6会被更新,其他的不变。就那么简单。没那么多弯弯绕绕。
1.3位置编码
还是一样,为啥要位置编码。类比卷积,我们知道卷积具有平移不变性,先卷左上角,再卷了右下角,结果绝对是左上角还是在右下角的上面偏左。这就是位置关系,他不会因为你卷了谁,位置关系变了。但是transformer没有,它是注意力机制,后面讲到注意力的时候我再详细的说运算过程。反正就是做完注意力的时候,他们字和字之间相互计算相关性,并不会考虑第一个字应该在第二个字左边或者先说出来,他们只知道第二个字和第一个字有多少相关性。比如 爱你 这两个相关性0.8,那反过来 你爱 相关性一样是0.8,就这个意思。所以在计算注意力得分之前就要赋予位置信息。这边还是用正余弦编码,以后讲llama再说旋转位置编码。
位置编码,就一个要求,在 位置 和 维度 两个方向上不能重复。
如下面的图,横向的是维度,纵向的是位置(就是一句话的第几个次),就那么简单。

这个代码是去年实习的时候,自己手敲的,现在我自己都敲不出来了哈哈哈哈
class Positionembedding(nn.Module):
def __init__(self, len_max, emb_dim):
super(Positionembedding, self).__init__()
self.len_max = len_max
self.emb_dim = emb_dim
self.block = torch.zeros(len_max, emb_dim)
pos = torch.arange(0, len_max).unsqueeze(1) # -> (len_max, 1)
emb_i = torch.pow(1000, (torch.arange(0, emb_dim, 2) / emb_dim)).unsqueeze(0) # ->(1, emb_dim)
self.block[:, 0::2] = torch.sin(pos / emb_i)
self.block[:, 1::2] = torch.cos(pos / (emb_i if emb_dim % 2 == 0 else emb_i[0, :-1]))
def forward(self, x):
'''
x.shape -> (b, len_q, emb_dim)
'''
len_q = x.shape[-2]
block = self.block[0:len_q, :]
return (x + block)1.4 自注意力机制
这个算重中之中了,论文的核心。但是先别急,就记住几句话,然后我再细讲。
1.计算注意力得分的时候,没有任何的参数更新(包括反向传播),只是矩阵的信息聚合
2.多头只是切割维度方向,不增加额外的参数
3.注意力机制前后,张量维度不发生改变。
4.在解码器中,你的由于是一个字一个字的解码,所有q决定字的长度,可以随意变化,不影响相关性的计算。
就这三句话直接让你彻底明白注意力机制在干什么。首先对于参数,qkv三个键的参数是在输入到注意力模块之前,要经过一个线性层,形成的三个qkv矩阵,更新的是这个矩阵!!!并非在计算相关性的时候有什么参数可以更新。
然后qkv可以这样理解,q是一个查询的人,kv是一本书,k是书的目录,里面有大致内容,然后q和k做相关性计算,相关性高的就是我要找的内容,然后再乘以v,这样结果就得到了。
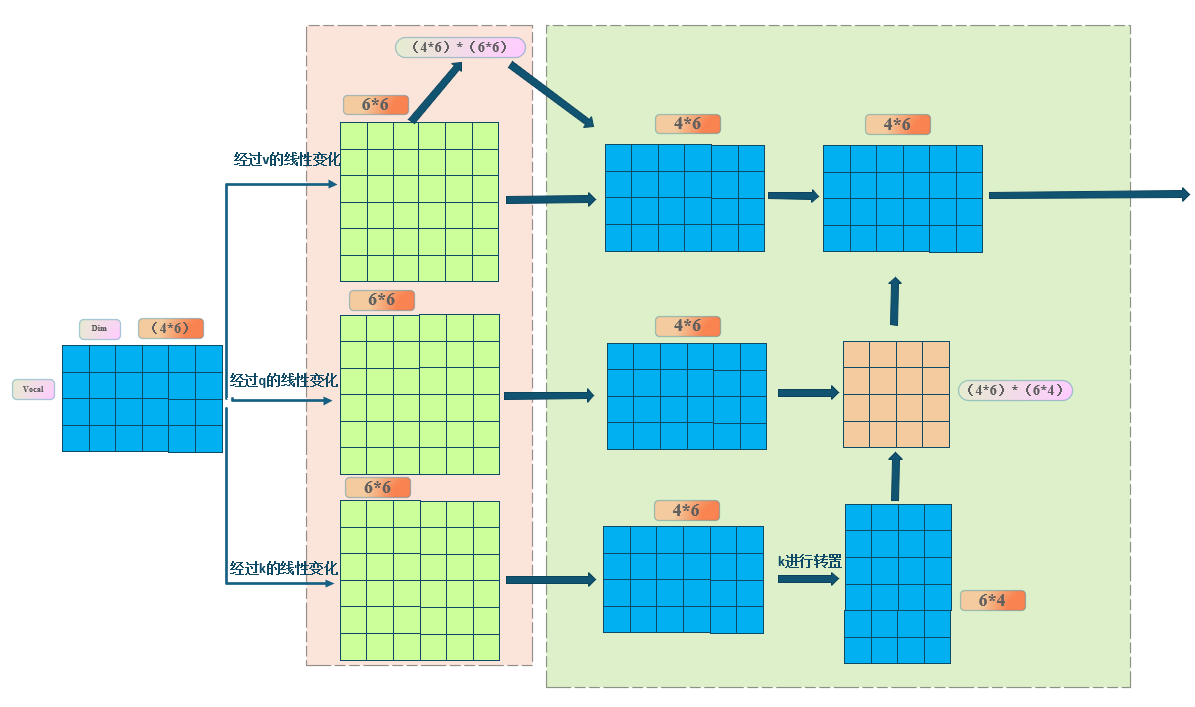
从上面的图来看,假如输入是一句话,4个词,每个词6个字。经过三个不同的nn.linear(6,6),就会得到qkv三个值。这个nn.linear(6,6)就是我们要更新的参数(绿色部分),后续那些变化和参数更新无关!然后你对k进行转置和q相乘,就是我说的,q去查询k相关的部分,得到一个4*4的矩阵,然后再去和v相乘,得到具体的值。就那么简单!
总结出几个规律:
1. 输入维度是什么,输出维度是什么,比如输入4*6,输出就是4*6
2.k和q的相关性,意思就是q去查询k,纵坐标每一行,代表一个字,和上面一一对应
3.q的句子长度可以变化,如果q是3*6,kv是4*6,输出必然是3*6(你自己验证一下按照上面的图)
1.5多头注意力机制
这个更简单了,纯矩阵的运算推导。
你自己尝试一下把维度,就是上面的4*6,拆成两个4*3,是不是输出还是两个4*3,最后拼接在一起,就变成了4*6
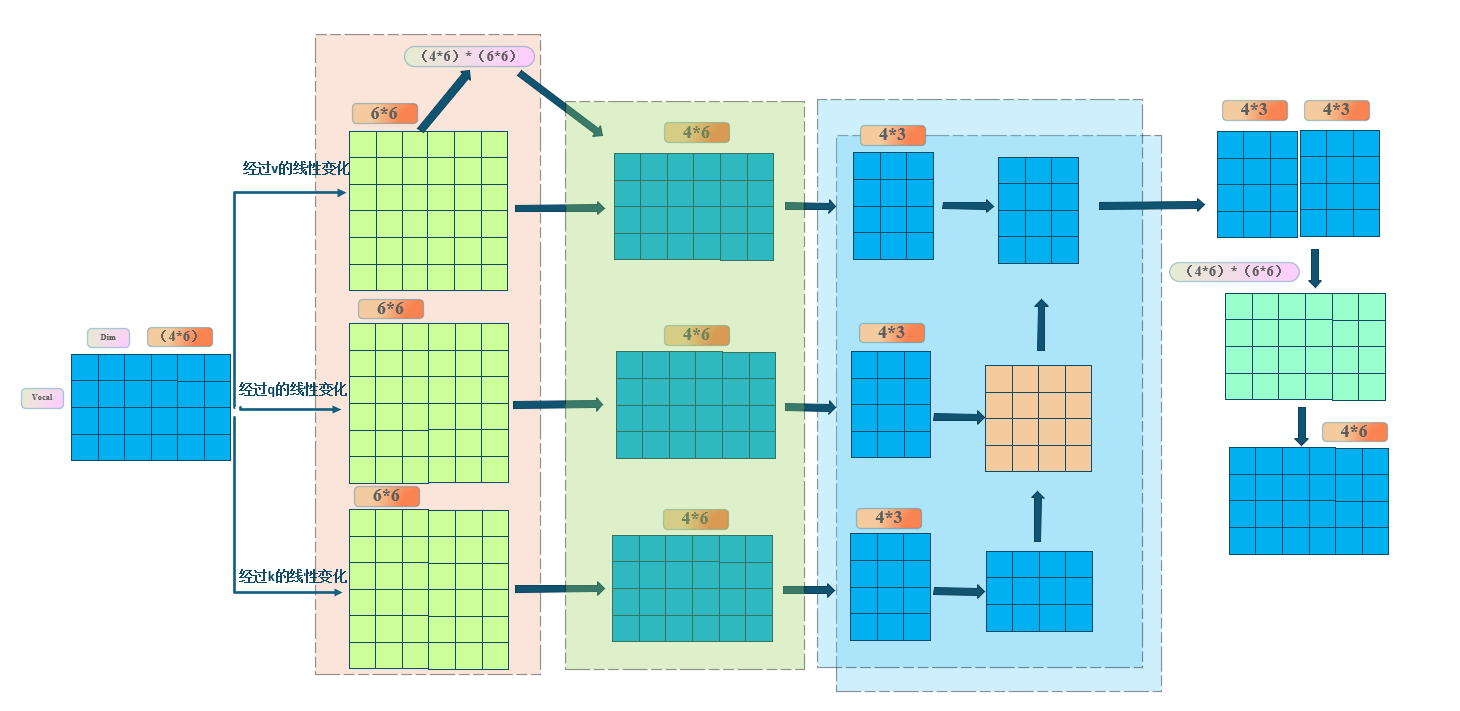
啥意思呢,就是你有几个头,那就把dim分成几份。蓝色部分就重复几次,最后把他们拼接在一起,通过一个线性层,就可以直接输出啦。它也是同样,输入是什么维度输出就是什么维度,head的多少不影响参数的变化,head多可以捕捉到不同的相关性,但是是啥就不确定了。比如,我爱你,这三个字,第一个head捕捉到的是主谓宾,第二个是出现概率,反正就是巴拉巴拉。这时候你就说,啊head越多不越好吗。那512个维度,你除以512个头,不又变成了最初说的问题,低纬度很难表示复杂信息的关系。所以这个head的数量,需要你自己探索,多了也不好,少了也不好。
class MutilHeadAttention(nn.Module):
"""
这里的自注意机制输入等于输出
"""
def __init__(self, dim, dim_q=None, dim_v=None, num_heads = 1, dropout=0.1):
super(MutilHeadAttention, self).__init__()
dim_q = dim if dim_q == None else dim_q # 在这里三元表达式写错了
dim_v = dim if dim_v == None else dim_v
self.dim = dim
self.dim_q = dim_q
self.dim_v = dim_v
self.num_heads = num_heads
# 一般来说KQ的dim输出是相同的,v根据任务调整
self.Linear_k = nn.Linear(dim, dim_q)
self.Linear_q = nn.Linear(dim, dim_q)
self.Linear_v = nn.Linear(dim, dim_v)
self.Dropout = nn.Dropout(dropout)
def forward(self, K, Q, V, mask=None):
'''
KQV ->(B, len_q, emb_dim)
'''
len_K = K.shape[-2]
len_Q = Q.shape[-2] # 这里必须是[],不能呢个()
# (B, len_q, emb_dim) -> (B, len_q, head, dim_q/head) ->-> (B, head, len_q, dim_q/head)
K = self.Linear_k(K).view(-1, len_K, self.num_heads, self.dim_q // self.num_heads).transpose(1, 2) # view必须整处
V = self.Linear_v(V).view(-1, len_K, self.num_heads, self.dim_v // self.num_heads).transpose(1, 2)
Q = self.Linear_q(Q).view(-1, len_Q, self.num_heads, self.dim_q // self.num_heads).transpose(1, 2)
# q求相似度(q*kt)(B, head, len_q, dim_q/head) ->> (B, head, len_q, len_k)
atten = torch.matmul(Q, K.transpose(-2, -1)) / (self.dim ** 0.5)
if mask is not None:
atten = atten.transpose(0, 1).masked_fill(mask, float('-1e20')).transpose(0, 1)
atten = torch.softmax(atten, dim=-1)
atten = self.Dropout(atten) # 使得softmax的得分部分为0
output = torch.matmul(atten, V).transpose(1,2).contiguous()
# (B, head, len_q, len_q) ->> (B, head, len_q, dim_q/head) _>>(B, len_q, head, dim_q/head)
output = output.view(-1, len_Q, self.dim_q)
# (B, len_q, head, dim_q/head) -> (B, len_q, dim_q)
return output1.6掩码
对于纯种transformer来说,有三个地方会出现两种掩码。
1.在编码器的自注意力机制中存在填充掩码(编码器的填充)
2.在解码器的自注意力机制中存在因果掩码+填充掩码(推理过程没有填充掩码)
3.在解码器的交叉注意力机制中存在填充掩码(编码器的填充)
我们一层一层来讲。填充掩码是什么意思呢,上一篇文章中说了,对于一个batch来说,如果句子的长度不同,我们就要对短的句子进行填充<pad>这个pad和文字之间可没有什么关系,所以我们就要对他进行填充一个无穷小的数,意思就是让他们之间不存在关系。
因果掩码是什么东西呢,就是在训练过程中,transformer可不是一个字一个字的找相关性,她是一整句话全部放进去,然后再相关性计算的过程中,让未来的词语进行遮蔽,这样比如一句话5个字,第一行是第一个字和自己做计算,第二行是第二个字和第一个第二个字做计算,以此类推,一次性就会计算5次相关性。
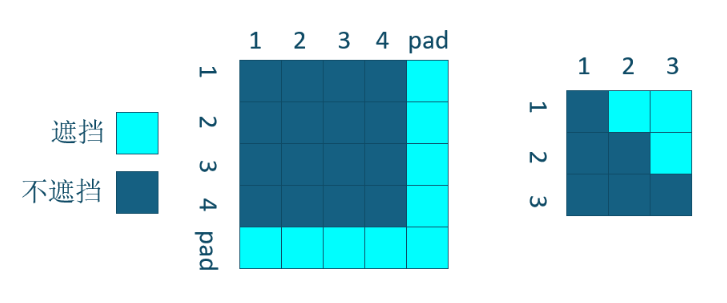
就像这样,1和1做,2和12做,3和123做,这样效率直接爆炸提升!为啥推理不需要呢,因推理过程中,没有真实值,我下一个字是需要我预测出来的,训练过程下一个字是知道的,所以要遮蔽。
ok,两种掩码说完了,那就说说位置喽,编码器因为一个batch全丢进去,所以必须存在填充掩码。解码器的自注意力机制,因为需要屏蔽未来值,还需要屏蔽batch里面真值不同的长度的句子的pad,所以两个填充都需要。交叉注意力机制,它的q来自于解码器,kv来自于编码器,所以编码器自带的mask必须存在,但是q就不需要了,因为q需要去查询整个编码器编码的信息。
注意:在算法实现中有几个点
1.传入模型里面的因果掩码,一般是二维的。传入的填充掩码是一维的。想想看为什么呢。
2.对于填充掩码,其实只屏蔽列,不屏蔽行。列是被查询者,行是查询者。我的mask本身就确实可以看到所有信息,为什么在运算中要屏蔽它。最后计算loss的时候在忽略不就行了,所以在计算相关性得分的时候不屏蔽行。
class mask_utils:
def __init__(self, len_now, src_mask=None):
self.len = len_now
self.len_now = len_now.shape[1]
self.src_mask = src_mask
def atten_mask(self):
mask = torch.triu(torch.ones(self.len_now, self.len_now), 1).bool()
# 生成上三角,意思就是保留上部分及其中心线 下三角是torch.tril
return mask
def mask_padding(self, mask1, mask2):
mask = (mask1.unsqueeze(-1) * mask2.unsqueeze(1)).bool()
mask = ~mask
return mask
def mask_all(self):
if self.src_mask == None:
enc_mask = self.atten_mask()
src_mask = None
cross_mask = None
return enc_mask, src_mask, cross_mask
if self.src_mask != None:
enc_mask = self.atten_mask()
src_mask = self.mask_padding(self.src_mask, self.src_mask)
cross_mask = self.mask_padding(self.len, self.src_mask)
return src_mask, enc_mask, cross_mask1.7前馈神经网络和层归一化
这个都没啥讲的我觉得,前馈神经网络ffn就是一个线性层。就这样
层归一化还是说一下吧。我们之前在分类网络中都知道需要归一化,分类的归一化啥意思呢。它其实是让每一层进行归一化,比如RGB三个通道,R通道所在在h*w进行归一化。。。这样是不是每一个通道所在的层都是在0-1之间喽。
那放在文本特征来说可以做到吗,应该不行,因为文本没有通道这个概念。所以我们就要在特征维度进行归一化就更加合理。比如3个字,每个字512个特征,那这个单独的字,512维度上进行归一化,把它归一化到0-1不就行了。这就是层归一化。
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.5):
super(FeedForward, self).__init__()
self.dim = dim
self.hidden_dim = hidden_dim
self.Dropout = nn.Dropout(dropout)
self.Linear_in = nn.Linear(dim, hidden_dim)
self.Linear_out = nn.Linear(hidden_dim, dim)
self.act = nn.ReLU()
def forward(self, x):
x = self.act(self.Linear_in(x))
x = self.Dropout(x)
x = self.Linear_out(x)
return x
2.实战实战!!! 未完待续...

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)