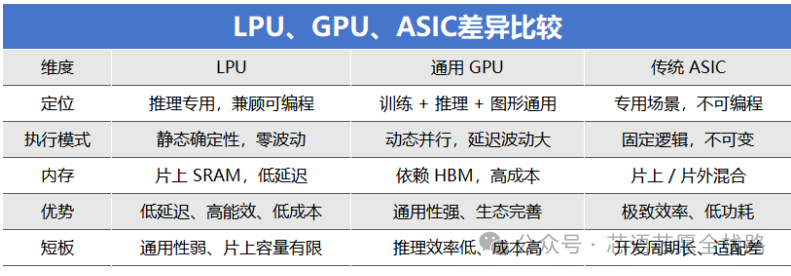
LPU:为 AI 推理而生的芯片革命
一、从一个问题出发
你有没有注意过,使用 ChatGPT 时,文字是一个字一个字"蹦出来"的,而不是一次性显示?这不是故意做的动画效果——而是 AI 真的在逐字生成,每输出一个词(token),都要完成一次完整的神经网络计算。这个过程,叫做大语言模型推理(LLM Inference)。
现在有一种专为这个过程设计的芯片,叫做LPU(Language Processing Unit,语言处理单元)。它由 AI 芯片公司Groq发明,能让 AI 说话的速度快到令人咋舌——运行 Llama 3 70B 这样的大模型时,输出速度可以超过280–300 个 token/秒,而同等配置的 NVIDIA H100 GPU 通常只能达到 60–100 个 token/秒。要理解 LPU 为什么这么快,我们需要从它的"对手"GPU 说起。
二、GPU 的问题:大炮打蚊子
GPU 最初是为游戏图形渲染设计的。渲染画面需要同时计算数百万个像素——这是一种天然的并行任务,GPU 的几千个核心同时开工,效率极高。
后来,深度学习研究者发现,神经网络的矩阵乘法运算跟图形渲染有相似之处,于是 GPU 被借来训练 AI 模型。训练阶段确实很适合 GPU——几千个样本同时处理,并行性强。但推理阶段完全是另一回事。
https://www.eet-china.com/mp/a480143.html
LLM 生成文字时,有一个根本约束:第 N 个 token 必须等第 N-1 个 token 生成后,才能开始计算。你不知道"苹果"后面是"很甜"还是"公司",直到"苹果"这个词出现。这是一种天然的顺序依赖,GPU 的并行架构对此束手无策。更严重的问题是内存墙(Memory Wall)。
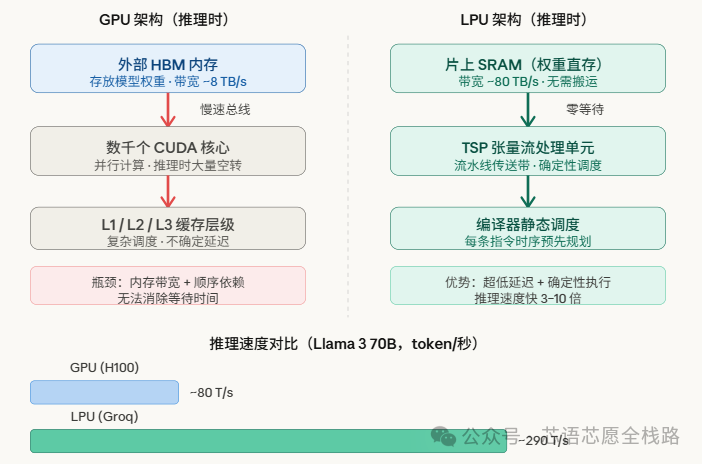
GPU 的计算核心(CUDA Core)速度很快,但模型的权重参数存放在外部高带宽内存(HBM)中。每次计算,数据都要从 HBM 搬运到计算核心,再搬回去。Groq 的片上 SRAM 内存带宽高达 80 TB/s,而 GPU 的外部 HBM 只有约 8 TB/s——光这一项差距,就给 LPU 带来了高达 10 倍的速度优势。
https://www.jaeaiot.com/news/detail/337.html
三、LPU 的核心设计:流水线装配工厂
下面这张图展示了 LPU 与 GPU 在推理时的根本架构差异:
1. 流水线传送带(Streaming Assembly Line)
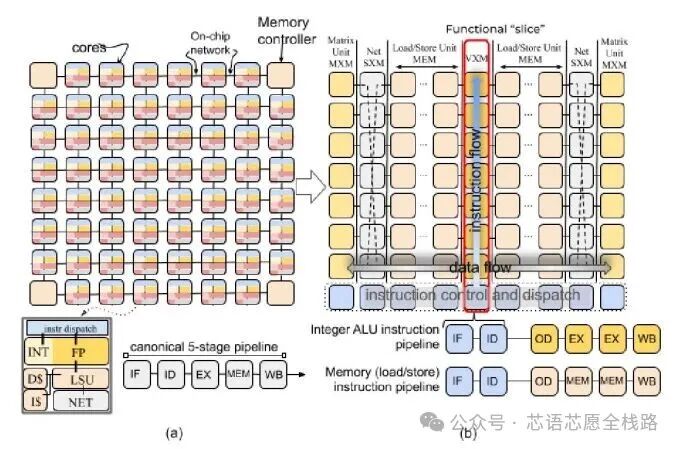
LPU 最核心的定义特征是它的可编程流水线架构。LPU 内部有数据"传送带",在芯片的各个 SIMD(单指令多数据)功能单元之间传输指令和数据。在流水线的每一步,功能单元从传送带获取指令,指令告诉它:从哪条传送带取输入数据、执行什么函数、把结果放到哪条传送带。整个过程完全由软件控制,硬件内部无需任何同步。
这就像一条汽车装配流水线——发动机工位、喷漆工位、检测工位各司其职,前一台车刚离开,下一台车立刻进入,永不停歇。
2. 确定性执行(Deterministic Execution)
普通 GPU 内部有大量"不确定性"机制:分支预测器、乱序执行缓冲区、动态调度器……这些组件让 GPU 在通用计算中灵活高效,但代价是延迟不可预测。
LPU 通过刻意回避传统的响应式硬件组件(分支预测器、仲裁器、乱序缓冲、缓存),并将所有执行控制权交给编译器,从而实现确定性执行,保证 LPU 程序的每一步都精确按时发生。这意味着:第 1 毫秒做什么、第 2 毫秒做什么,全都在芯片运行之前就由编译器安排好了。没有等待,没有浪费。
3. 片上 SRAM:把仓库搬进工厂
这是 LPU 速度最大的来源之一。LPU 将数百 MB 的 SRAM 作为主权重存储(而非缓存)直接集成在芯片上,从而削减延迟,让计算单元以全速获取权重。这与 GPU 依赖外部 HBM 内存的做法截然不同。一个类比:GPU 就像工人在工厂干活,但零件全放在两公里外的仓库,每次都要开车去取;LPU 则把所有零件放在工人手边,伸手就能拿到。
4. 软件优先(Software-First)
Groq 在设计第一代芯片时,先设计编译器架构,再触碰芯片设计。这与业界惯例相反——通常是先造硬件,再写软件适配。这使得 LPU 的硬件和软件深度协同,编译器能以纳秒级精度规划每一条指令的执行时序。
四、LPU 的核心单元:TSP
LPU 的基础计算单元叫做TSP(Tensor Streaming Processor,张量流处理器)。TSP 是 LPU 的基础单元,多个 TSP 以机架形式组合,多个机架再互联,形成能提供大规模吞吐量的分布式系统。TSP 系统同样围绕确定性数据流和指令执行、以及节点之间的低延迟通信来设计。
第一代 LPU(TSP)在 14nm、25×29 mm 芯片上实现了每平方毫米超过 1 TeraOp/s 的计算密度,工作频率为 900 MHz。第二代 LPU 将采用三星 4nm 制程制造。
五、LPU 不擅长什么?
LPU 并非万能。它的专用性既是优势,也是局限:
-
不适合训练:模型训练需要大批次、高并行的矩阵运算,GPU 在此场景仍是最佳选择。
-
通用性差:LPU 只针对线性代数推理优化,无法像 GPU 那样运行图形渲染、物理仿真等通用任务。
-
规模代价:由于没有外部内存(如 HBM),Groq 需要集成数百颗芯片才能高效加速参数量达数百亿的实用 LLM(例如,运行 Llama2-70B 需要 512 颗芯片),这带来了相当大的通信开销。
六、行业影响与近期动态
2024 年 8 月,Groq 完成由贝莱德私募股权基金领投的 6.4 亿美元 D 轮融资,估值达 28 亿美元。2025 年 2 月,Groq 宣布获得沙特阿拉伯 15 亿美元的承诺投资,用于扩建基于 LPU 的 AI 推理基础设施,并在达曼建立新的 GroqCloud 数据中心。
2025 年 12 月,英伟达同意以约 200 亿美元收购 Groq 的部分资产,这是英伟达迄今规模最大的一笔交易。Groq 将此描述为一项非排他性许可协议,Groq 创始人 Ross 和总裁 Sunny Madra 将加入英伟达。这笔交易本身就说明了 LPU 技术的价值。
七、一句话总结
LPU 是为 AI 推理"量身定制"的芯片:用流水线传送带代替无序调度,用片上 SRAM 代替外部内存,用编译器静态规划代替硬件动态决策——用专用换来了极致速度。
它不打算替代 GPU 训练模型,而是要让训练好的模型在推理时更快、更省、更稳定地服务用户。
参考来源
- Groq 官方技术白皮书
— What Is a Language Processing Unit?
https://groq.com/blog/the-groq-lpu-explained - Groq 官方技术博客
— Inside the LPU: Deconstructing Groq's Speed
https://groq.com/blog/inside-the-lpu-deconstructing-groq-speed - Groq LPU Architecture
— 官方架构说明页
https://groq.com/lpu-architecture - Abhinav Upadhyay
— The Architecture of Groq's LPU(基于 Groq 在 ISCA 2020/2022 发表的学术论文)
https://blog.codingconfessions.com/p/groq-lpu-design - HyperAccel 学术论文
— LPU: A Latency-Optimized and Highly Scalable Processor for Large Language Model Inference(arXiv:2408.07326)
https://arxiv.org/html/2408.07326v1 - Wikipedia — Groqhttps://en.wikipedia.org/wiki/Groq
- Groq 产品白皮书 PDF
— GroqThoughts: What Is a LPU?
https://groq.humain.ai/wp-content/uploads/2024/07/GroqThoughts_WhatIsALPU-vF.pdf - Zheng "Bruce" Li, Medium
— Groq's Deterministic Architecture is Rewriting the Physics of AI Inference(含 Artificial Analysis 独立评测数据)
https://medium.com/the-low-end-disruptor/groqs-deterministic-architecture-is-rewriting-the-physics-of-ai-inference-bb132675dce4

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 1
1- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)