【kaggel学习笔记】Regularized Linear Models-正则化线性模型
本文用于对kaggel项目:House Prices - Advanced Regression Techniques 的学习
一.参考资料
二.notebook解读
原文:这个notebook不用 XGBoost,不用随机森林,不用集成学习,只用正则化线性回归(Lasso / Ridge)
嗯其实他都用了
1.库导入,数据加载
# 1. 导入数据分析必备库
import pandas as pd # 表格处理神器
import numpy as np # 数值计算
import seaborn as sns # 画图(好看)
import matplotlib # 画图基础库
import matplotlib.pyplot as plt # 画图主工具
from scipy.stats import skew # 计算偏度(看数据是否正态)
from scipy.stats.stats import pearsonr # 计算相关系数
# 让图片高清显示
%config InlineBackend.figure_format = 'retina'
# 让图表直接在 notebook 里展示
%matplotlib inline
# 2. 读取训练集、测试集数据
train = pd.read_csv("../input/train.csv") # 带房价的训练数据
test = pd.read_csv("../input/test.csv") # 不带房价的测试数据
# 3. 展示训练集前5行,看看数据长啥样
train.head()
# 4. 合并数据集
all_data = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'],
test.loc[:,'MSSubClass':'SaleCondition']))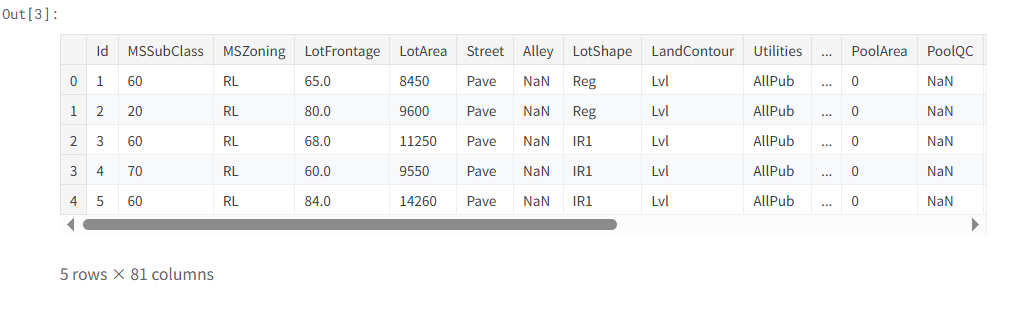
- train = pd.read_csv("../input/train.csv") 这里的文件输入方式值得学习,以前我一直使用的绝对路径避免出错
-
train.head()官方默认显示前五
-
为什么要合并数据集?因为要让两套数据经过完全一样的预处理
-
独热编码要一致
-
缺失值填充/标准化要一致
-
特征工程要一致
-
2.数据预处理
原文:我们这里不做花里胡哨的操作,只做 3 件事:
1. 对偏态的数值特征做 log(特征 + 1) 变换 → 让数据分布更接近正态分布
2. 对分类特征创建哑变量(独热编码) → 把文字变成数字
3. 用均值填充数值型特征的缺失值
因变量处理
# 1. 设置全局图表的大小:宽度12,高度6(让图更大更清晰)
matplotlib.rcParams['figure.figsize'] = (12.0, 6.0)
# 2. 创建一个新的DataFrame,存放【原始房价】和【log变换后的房价】
# 方便我们画直方图对比分布变化
prices = pd.DataFrame({
"price": train["SalePrice"], # 第一列:原始房价(未处理,偏态)
"log(price + 1)": np.log1p(train["SalePrice"]) # 第二列:log(房价+1),正态化处理
})
# 3. 对上面两列数据画直方图(左右并排对比)
# 左边:原始价格分布
# 右边:log变换后的价格分布
prices.hist()out:array([[<AxesSubplot:title={'center':'price'}>,
<AxesSubplot:title={'center':'log(price + 1)'}>]], dtype=object)
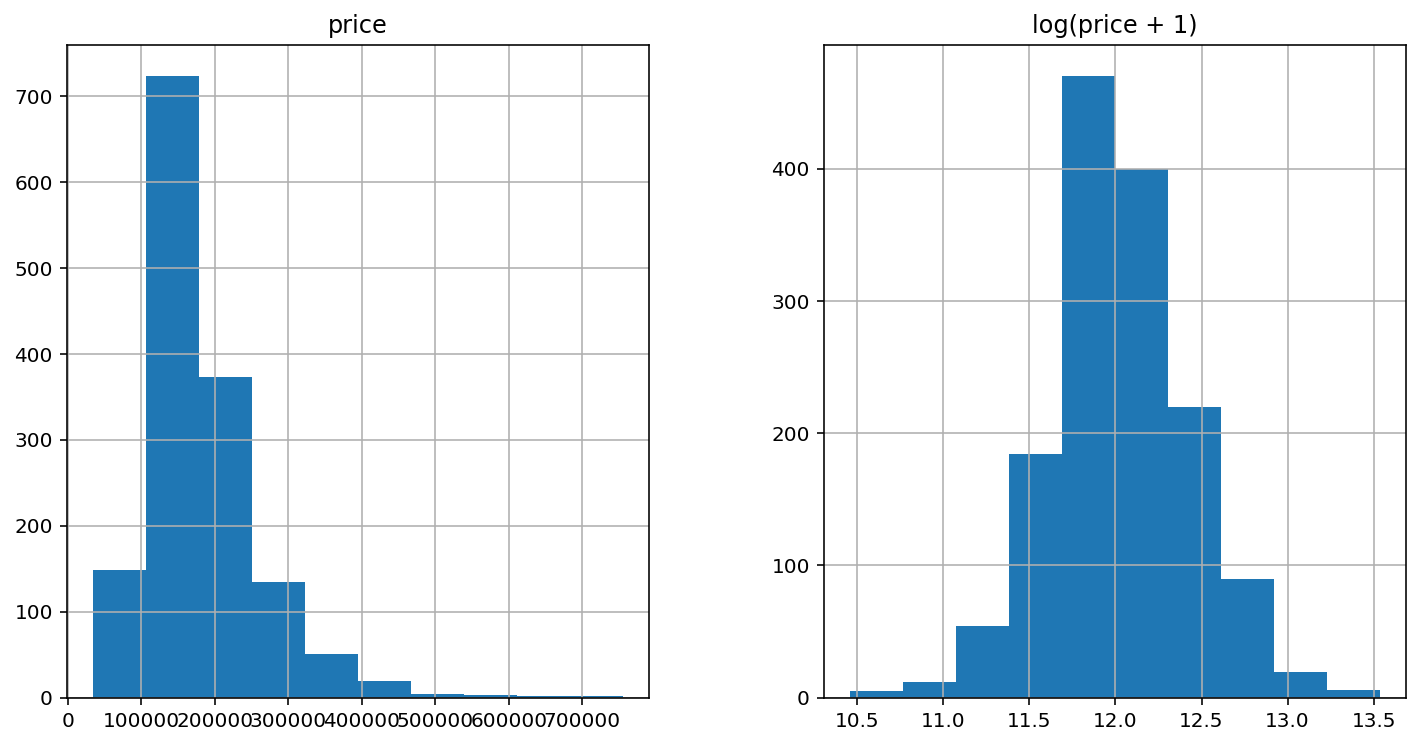
Q1:.hist()结合之前学习的
| 图表名称 | 代码常见写法 | 核心作用(一句话记住) |
|---|---|---|
| 1. 直方图 Histogram | .hist() |
看单列数据分布、是否正态、偏不偏 |
| 2. 散点图 Scatter | plt.scatter() |
看两个变量有没有线性相关关系 |
| 3. 箱线图 Boxplot | .boxplot() |
快速找异常值、看数据四分位范围 |
| 4. 热力图 Heatmap | sns.heatmap() |
看多个变量之间的相关系数强弱 |
Q2:np.log1p和pd.DataFrame的作用:
- np.log1p(x) == np.log(x + 1)对数变换
- pd.DataFrame(字典)是创建一个新表格,方便画图、对比、查看数据;字典格式: { "列名1": 数据列1, "列名2": 数据列2, "列名3": 数据列3 }
对数值型特征作log1p正态化处理
#log transform the target:
# 对预测目标【房价标签】做对数正态化修正
train["SalePrice"] = np.log1p(train["SalePrice"])
#log transform skewed numeric features:
# 筛选出所有【数值型特征】列名(排除字符串object类型)
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
# 遍历所有数值特征:先删掉缺失值,再计算每一列的偏度skew
skewed_feats = train[numeric_feats].apply(lambda x: skew(x.dropna()))
# 过滤保留:偏度大于0.75、明显右偏的特征
skewed_feats = skewed_feats[skewed_feats > 0.75]
# 只取出筛选后这些偏态特征的列名索引
skewed_feats = skewed_feats.index
# 在合并后的全量数据集上,对所有高偏度特征统一做log1p对数变换
all_data[skewed_feats] = np.log1p(all_data[skewed_feats])Q1:解读skewed_feats = train[numeric_feats].apply(lambda x: skew(x.dropna()))
.apply( )对每一列分别执行后面的函数lambda x表示当前正在处理的某一列数据,对这一列做下面的操作x.dropna()把这一列里的空值 NaN 删掉,因为计算偏度时不能有空值skew( )计算这一列数据的偏度
Q2:为什么大于0.75是严重右偏,以及其他判断依据?
- 0.75是Kaggle 房价赛经验阈值
- 数据分析通用规则:
- Skew = 0:完美正态分布,完全对称
- 0 < Skew < 0.5:轻微右偏,几乎不用处理
- 0.5 ≤ Skew < 0.75:中度右偏,可选x = np.sqrt(x)微调,也可以不处理
- Skew ≥ 0.75:重度强右偏 → 必须 log 变换
独热编码处理分类特征
# 把文字类型(如街道类型、建材风格)转换成 0/1 数字矩阵
all_data = pd.get_dummies(all_data)缺失值填充
# 用【每一列自己的平均值】填充该列的缺失值(NaN)
all_data = all_data.fillna(all_data.mean())数据划分
# 为 sklearn 机器学习模型创建特征矩阵(数据格式转换)
X_train = all_data[:train.shape[0]] # 取前 训练集行数 的数据 → 训练集特征
X_test = all_data[train.shape[0]:] # 取 训练集行数之后 的数据 → 测试集特征
y = train.SalePrice # 训练集的目标变量(房价)Q1:这里为什么不需要把y转成竖着的二维张量tensor?
因为这里用的是 scikit-learn(sklearn)模型,不是 PyTorch / TensorFlow 深度学习模型
sklearn 接受的输入就是:
- X:DataFrame 或 numpy 数组
- y:一维 numpy 数组 /pandas Series
Q2. 什么时候才需要转 tensor?
- 用深度学习框架时才需要如PyTorch,TensorFlow / Keras,CNN、RNN、Transformer 等神经网络
- 它们要求:必须是 tensor,维度必须严格匹配,常常需要
y.reshape(-1,1)或unsqueeze
Q3:为什么 sklearn 不用?
- 因为 sklearn 是传统机器学习:线性回归,随机森林,XGBoost,岭回归 / Lasso
- 它们原生支持 DataFrame /numpy自动处理维度,不需要手动调整 y 的形状
3.sklearn模型搭建(重点)
原文:现在我们要使用 scikit-learn 里的 正则化线性回归模型。 我会尝试两种:
- L1 正则化(Lasso)
- L2 正则化(Ridge)
我还会定义一个函数,用来返回 交叉验证的 RMSE 误差。 这样我们就能评估模型,并且选出最好的超参数。
验证函数
# 导入需要的机器学习模型(正则化线性回归)
from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, LassoCV, LassoLarsCV
# 导入交叉验证工具(用来评估模型)
from sklearn.model_selection import cross_val_score
# 定义一个函数:输入模型,输出 5折交叉验证的 RMSE 误差
# RMSE 越小,模型越好
def rmse_cv(model):
# 计算交叉验证分数 → 转成 RMSE
rmse = np.sqrt(-cross_val_score(model, X_train, y, scoring="neg_mean_squared_error", cv=5))
# 返回 RMSE 结果
return rmseQ1:np.sqrt(-cross_val_score(model, X_train, y, scoring="neg_mean_squared_error", cv=5))解读
cross_val_score:5 折交叉验证scoring="neg_mean_squared_error":用负均方误差打分- 加
-号、开根号np.sqrt→ 变成 RMSE
Q2:RMSE是啥?怎么算?
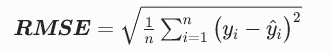
- 均方误差 MSE开根号
Ridge 模型
# 初始化 Ridge 回归模型(L2 正则化线性回归)
model_ridge = Ridge()原文:Ridge 模型最核心的调节参数叫做 alpha,alpha 是一个**正则化强度参数**,用来控制模型的灵活程度,alpha 越大 → 正则化越强 → 模型越简单 → 越不容易过拟合,但是 alpha 太大会让模型变得太简单,可能学不到数据里的规律(欠拟合)
# 定义一组待测试的正则化参数 alpha 值
alphas = [0.05, 0.1, 0.3, 1, 3, 5, 10, 15, 30, 50, 75]
# 遍历每个 alpha,训练 Ridge 模型,计算 5 折交叉验证 RMSE 的平均值
cv_ridge = [rmse_cv(Ridge(alpha = alpha)).mean()
for alpha in alphas]-
cv_ridge = [...]这是一个列表推导式,作用是循环测试每一个 alpha。 -
Ridge(alpha = alpha)用当前循环到的 alpha 创建一个 Ridge 模型。 -
rmse_cv(...)把模型放进你之前定义的函数里,做5 折交叉验证,得到一组 RMSE。 -
.mean()对 5 次验证的 RMSE 取平均值,让结果更稳定。
# 把交叉验证得到的RMSE结果转换成Pandas序列,索引就是对应的alpha值
cv_ridge = pd.Series(cv_ridge, index = alphas)
# 绘制折线图,展示不同alpha对应的RMSE变化,标题为"Validation - Just Do It"
cv_ridge.plot(title = "Validation - Just Do It")
# 设置X轴(横轴)标签为alpha
plt.xlabel("alpha")
# 设置Y轴(纵轴)标签为rmse
plt.ylabel("rmse")out:Text(0, 0.5, 'rmse')
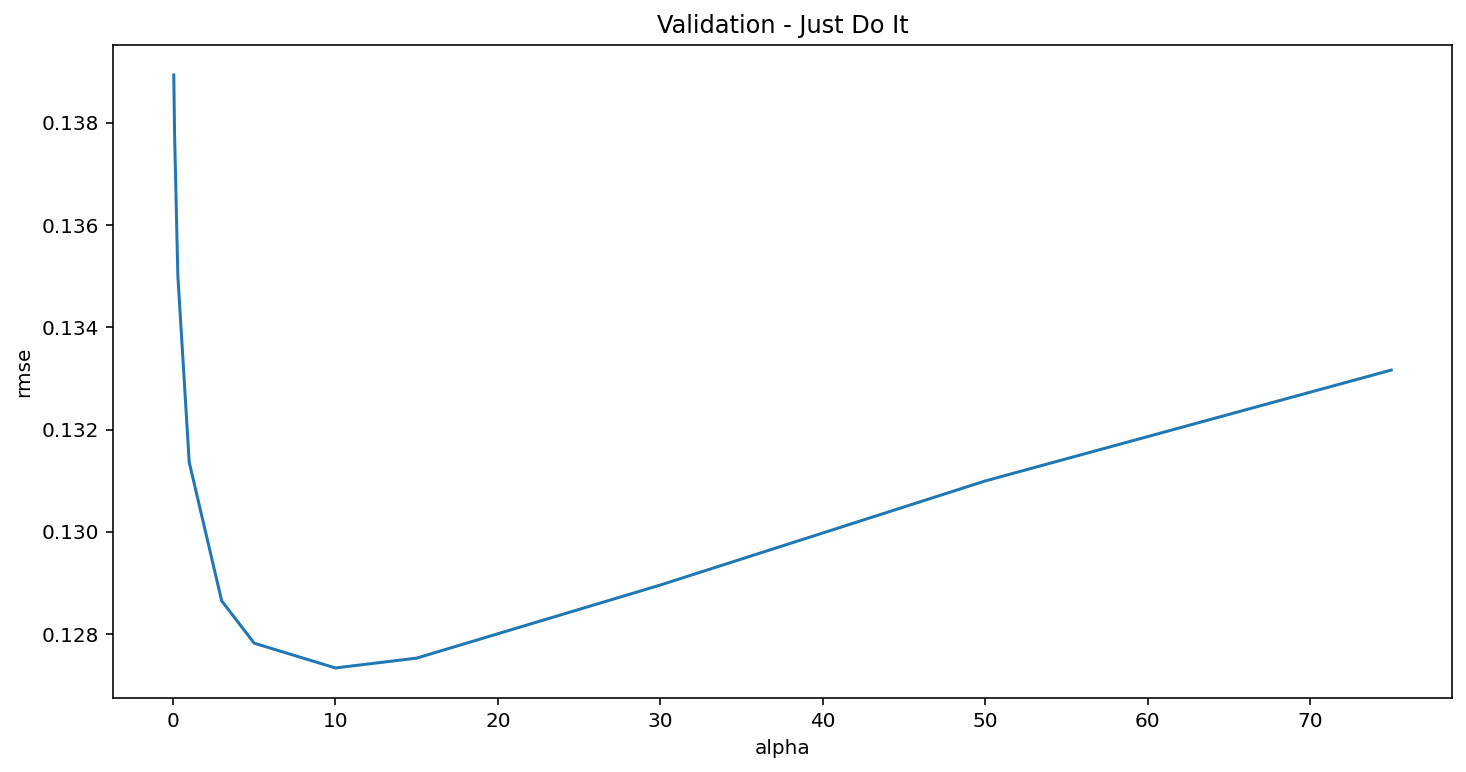
-
cv_ridge = pd.Series(cv_ridge, index = alphas)- 将之前计算好的平均 RMSE 列表转换成 Pandas 序列
- 用
alphas作为索引,实现alpha 值 ↔ RMSE 值一一对应
-
cv_ridge.plot(...)- 自动绘制折线图
- X 轴:alpha(正则化参数)
- Y 轴:RMSE(模型误差,越小越好)
- 作用:可视化找最优 alpha(RMSE 最低点对应的 alpha)
-
plt.xlabel/ylabel- 给坐标轴加文字说明,让图表更易读
从图中能看出:alpha=10 处在 U 型最低点,误差最小,是最优参数
# 求出刚才所有 alpha 对应的 RMSE 中【最小的那个值】
cv_ridge.min()out:0.12733734668670768
Lasso 模型
原文:刚才 Ridge 模型的最优结果:RMSE 大约 0.127(非常优秀),现在我们试试 Lasso 模型,这次用不一样的方法:直接用 LassoCV 自动找最优 alpha。重点:LassoCV 里的 alpha 和 Ridge 是反过来的。
总结:Ridge vs Lasso 参数完全相反
- Ridge:
alpha=10→ 正则化强 - LassoCV:
alpha=0.001→ 正则化强(Lasso 的 alpha 很小 = 惩罚很强)
为什么用 LassoCV?
因为它全自动:不用自己写循环试 alphas,不用画图。直接算出最好的 alpha,还直接训练好模型
# 初始化 LassoCV 模型(自动交叉验证选最优 alpha)
# 传入一组待测试的 alpha 参数
model_lasso = LassoCV(alphas = [1, 0.1, 0.001, 0.0005]).fit(X_train, y)1.LassoCV(alphas=[...])
- LassoCV:自带交叉验证自动选参的 Lasso 模型
- 不用自己循环、不用画图
- 自动帮你试每个 alpha,找出RMSE 最小的那个
2. alphas = [1, 0.1, 0.001, 0.0005]
- Lasso 专用的参数列表
- 数字越小,正则化越强
- 所以 Lasso 一般都用 0.001、0.0005 这种极小值
3. .fit(X_train, y)
-
用训练集数据训练模型
-
训练过程中:自动尝试所有 alpha,自动做交叉验证,自动保存最优模型
rmse_cv(model_lasso).mean()out:0.12256735885048131
原文:太好了!Lasso 模型表现得更好,所以我们直接用它来在测试集上做预测,Lasso 还有一个很棒的优点:它会自动帮你做特征选择,不用人工删特征,模型自己判断哪些有用、哪些没用。把它认为不重要的特征的系数直接设为 0,我们来看看这些系数。
# 把模型训练好的系数 拿出来,做成带特征名的 Series
coef = pd.Series(model_lasso.coef_, index = X_train.columns)
# 打印:Lasso 选了多少个有用特征,删了多少个没用特征
print("Lasso picked " + str(sum(coef != 0)) + " variables and eliminated the other " + str(sum(coef == 0)) + " variables")
out:Lasso picked 110 variables and eliminated the other 178 variables
原文:干得漂亮,Lasso!(夸它自动删了 178 个没用特征),但是有一点要注意:Lasso 选出来的特征,不一定就是 100% 绝对正确的。特别是因为数据里有很多共线性特征,一个可以尝试的思路:在不同的抽样数据上多跑几次 Lasso,看看特征选择稳不稳定。
Q1:model_lasso.coef和.columns
训练完成后,模型自动生成:
model_lasso.coef_→ 所有特征的系数model_lasso.alpha_→ 最优 alphamodel_lasso.intercept_→ 截距
这些都是 scikit-learn 模型训练完自带的属性
.columns → 获取所有列的名字
Q2:思维扩展1(见后文)
# 取出系数排序后 最小的10个 + 最大的10个,合并成重要系数
imp_coef = pd.concat([coef.sort_values().head(10),
coef.sort_values().tail(10)])
# 设置图表大小:宽度8,高度10
matplotlib.rcParams['figure.figsize'] = (8.0, 10.0)
# 画水平条形图,展示Lasso模型的重要特征
imp_coef.plot(kind = "barh")
# 设置图表标题
plt.title("Coefficients in the Lasso Model")out:Text(0.5, 1.0, 'Coefficients in the Lasso Model')
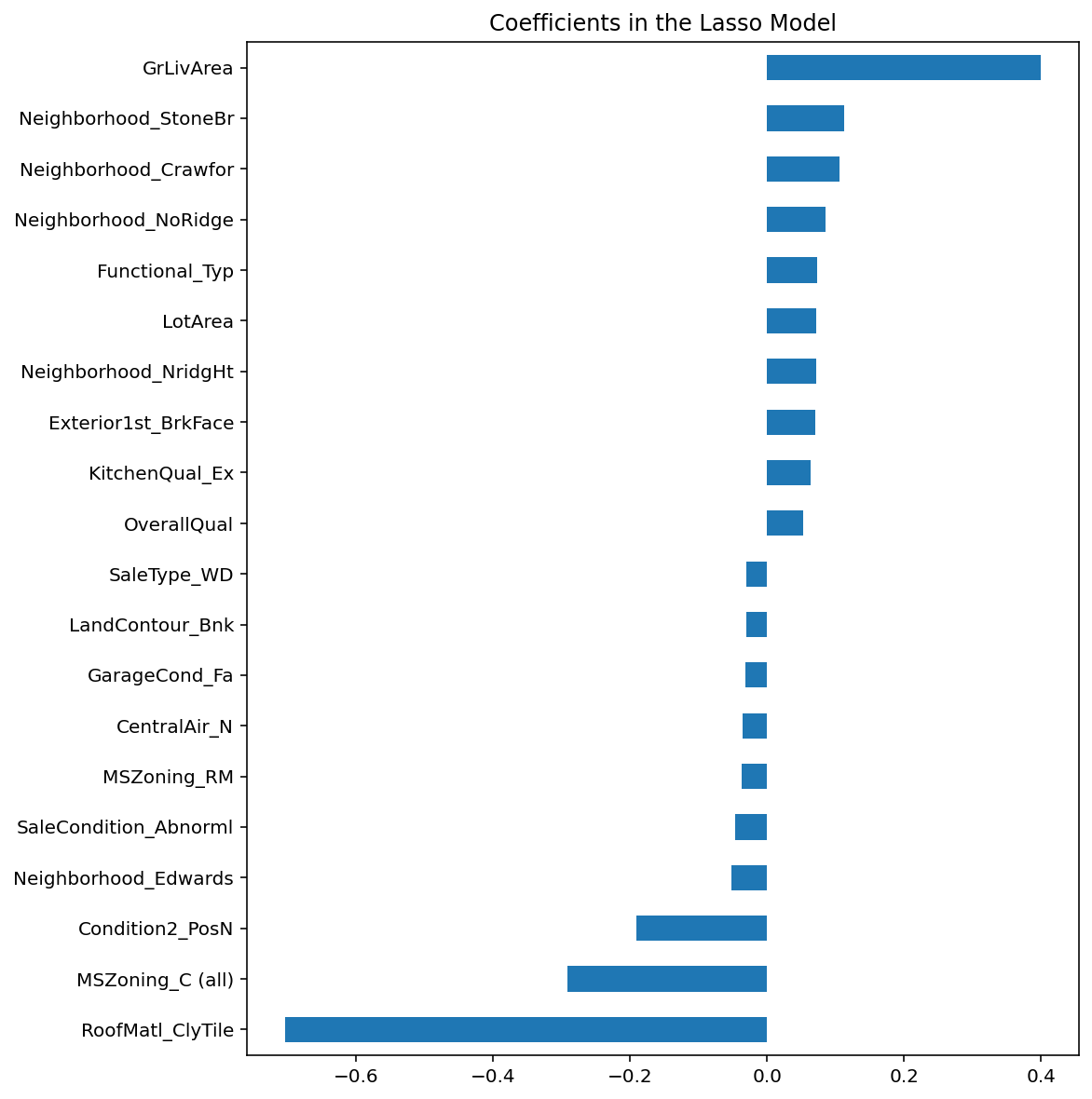
1. coef.sort_values()把所有特征的系数从小到大排序
2. .head(10)取系数最小(最负)的 10 个特征
3. .tail(10)取系数最大(最正)的 10 个特征
4. pd.concat([...])把正负各 10 个特征拼在一起,画出最有影响力的特征
5. plot(kind="barh")画水平条形图,能清楚看到:#没有kind默认是折线图,跟之前一样
- 条形越长 → 特征对房价影响越大
- 向右 → 正向影响(抬高房价)
- 向左 → 负向影响(拉低房价)
原文:最重要的正向特征是GrLivArea—— 地面以上的居住总面积(平方英尺)。这完全符合现实逻辑。其余一些地段、房屋品质类特征,也对房价起到正向推动作用。部分负向系数的特征逻辑很难解释,值得进一步排查;这大概率来自分布不均衡的类别特征。类别特征如果某一类样本极少(数据不平衡),模型会学到奇怪的负相关规律,不具备实际业务意义。还要注意:和随机森林的特征重要性不同,Lasso 输出的是真实可解释的模型系数。因此你能精准拆解:模型为什么预测出这个房价。唯一的问题:我们对目标值(房价)和数值特征都做了对数变换,导致系数大小很难直接按原始金额解释。
极简核心总结:
- 强正向特征
GrLivArea符合买房常识;异常负向特征大概率是类别数据不平衡导致; - Lasso 系数比随机森林重要性更可精准溯源解释;
- 对数变换:破坏了原始线性加法逻辑,变成乘法关系,降低了系数的直观解读性。
# 我们也来看看残差(模型预测的误差分布)
#let's look at the residuals as well:
# 设置图表大小为 6x6
matplotlib.rcParams['figure.figsize'] = (6.0, 6.0)
# 1. 创建一个表格:存放【模型预测值】和【真实值】
preds = pd.DataFrame({
"preds": model_lasso.predict(X_train), # 模型预测的房价
"true": y # 真实的房价(已经取过log)
})
# 2. 计算【残差】= 真实值 - 预测值
# 残差 = 模型没预测准的部分(误差)
preds["residuals"] = preds["true"] - preds["preds"]
# 3. 画散点图:x轴是预测值,y轴是残差
preds.plot(x = "preds", y = "residuals", kind = "scatter")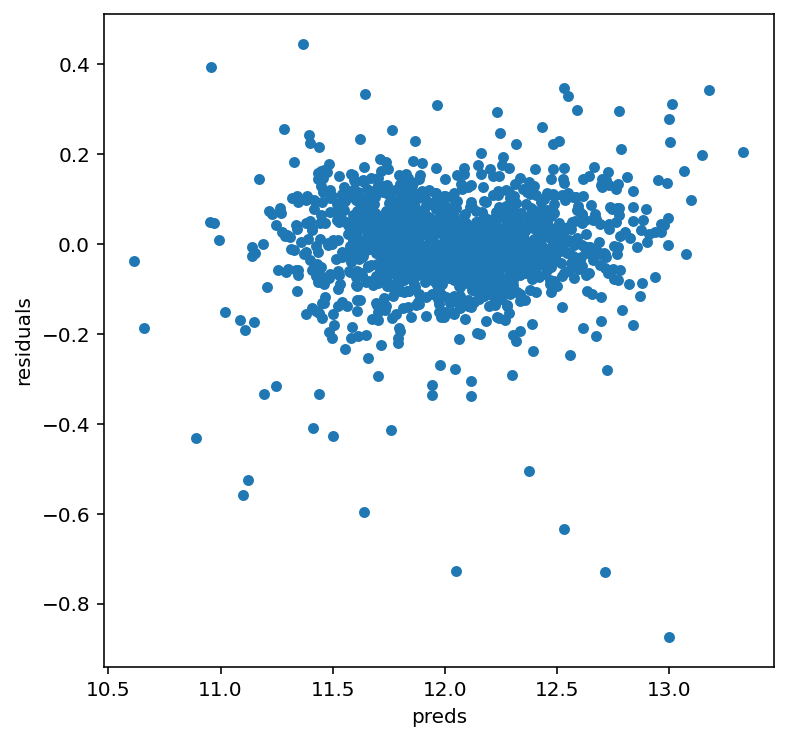
误差随机分布,没有明显规律,说明模型很健康、没有大问题,可以放心拿去做最终预测。
4.加入XGBoost 模型
原文:我们在线性模型(Lasso)的基础上,再加入一个 XGBoost 模型,看看能不能让分数更高、预测更准!
xgb.cv
import xgboost as xgb
# 把训练数据转换成 XGBoost 专用格式(更快、更稳定)
dtrain = xgb.DMatrix(X_train, label = y)
dtest = xgb.DMatrix(X_test)
# 设置 XGBoost 核心参数
params = {"max_depth":2, "eta":0.1}
# 交叉验证(自动试模型,找最优训练轮数)
model = xgb.cv(params, dtrain, num_boost_round=500, early_stopping_rounds=100)
# 画出训练集 & 测试集的误差曲线
model.loc[30:,["test-rmse-mean", "train-rmse-mean"]].plot()out:<AxesSubplot:>
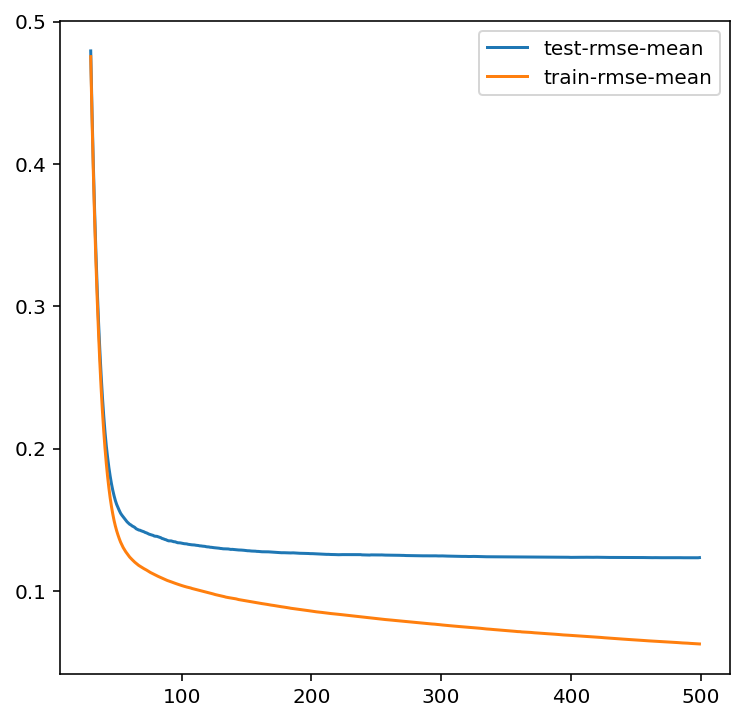
Q1:代码解读
1. dtrain = xgb.DMatrix(...)
- XGBoost 有自己专用的数据格式 DMatrix
- 作用:加速训练、支持缺失值、效率更高
2. params = {"max_depth":2, "eta":0.1}
- max_depth=2:树的深度(越小越简单,防止过拟合)
- eta=0.1:学习率(越小学得越精细)
3.model = xgb.cv(...) cv = 交叉验证:
- 自动在训练集里反复切分验证
- 自动找最优迭代次数
- 自动在误差不再下降时停止(early_stopping)
- 防止过拟合
4.model.loc[30:].plot()
model是 xgb.cv () 运行完输出的表格,里面记录了:- 每一轮迭代的训练集误差
- 每一轮迭代的测试集误差
- loc [30:]从第 30 行开始,取后面所有行,前 30 轮模型还没学好,误差很大,画出来图不好看。
.loc是 pandas DataFrame(表格)最常用的选取工具 - [30:, ["test-rmse-mean", "train-rmse-mean"]]取两列
- .plot ()画折线图
Q2;图像结果分析
1.关键趋势解读
- 前 50 轮:两条线都急剧下降 → 模型在快速学习,误差大幅缩小
- 50~500 轮:
- 蓝色线(验证集):先缓慢下降,之后趋于平稳,几乎不再变化
- 橙色线(训练集):持续缓慢下降,和蓝色线的差距逐渐拉大
- 终点(500 轮):
- 验证集 RMSE ≈ 0.125
- 训练集 RMSE ≈ 0.06
- 两者差距约 0.065
2.模型状态判断
- 没有明显过拟合:验证集误差没有后期上升,说明模型没有 “背答案”
- 收敛稳定:验证集在约 100 轮后就基本平稳,继续训练几乎不再提升
- 存在轻微过拟合倾向:训练集误差持续低于验证集,且差距缓慢扩大,说明模型在逐渐 “记住” 训练数据细节
3. 接下来该怎么做
- 最优迭代轮数:验证集在 100~200 轮 就已经收敛,没必要跑到 500 轮。实际训练时可以取
num_boost_round=200左右,既保证效果又节省时间。 - 参数调整建议:
- 若想缩小训练 / 验证集的差距(减轻过拟合):
- 调小
max_depth(比如从 2 改到 1) - 调小
eta(比如从 0.1 改到 0.05) - 增加
subsample/colsample_bytree(随机采样特征 / 样本)
Q3:如何添加subsample/colsample_bytree(可选)
-
params = { "max_depth": 2, "eta": 0.1, "subsample": 0.7, # 每棵树用70%样本 "colsample_bytree": 0.7 # 每棵树用70%特征 }
通用值subsample: 0.7 ~ 0.8 colsample_bytree: 0.7 ~ 0.8
xgb.XGBRegressor
# 定义 XGBoost 回归模型,传入通过交叉验证(xgb.cv)调整好的参数
model_xgb = xgb.XGBRegressor(n_estimators=360, max_depth=2, learning_rate=0.1) #the params were tuned using xgb.cv
# 使用训练集数据 (X_train, y) 训练模型
model_xgb.fit(X_train, y)out:XGBRegressor(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.1, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=2, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=360, n_jobs=0,
num_parallel_tree=1, predictor='auto', random_state=0, reg_alpha=0,
reg_lambda=1, ...)
Q1:代码解读
1.model_xgb = xgb.XGBRegressor(...)
- 创建一个 XGBoost 回归模型,Regressor = 回归器,因为是回归预测任务
n_estimators=360:迭代次数(树的数量),从之前交叉验证曲线图中选出最优值,n_estimators是不是和num_boost_round一样都是轮数,只不过模型接口的叫法不同max_depth=2:树的最大深度,控制模型复杂度learning_rate=0.1:学习率,控制每一步更新的幅度- 注释说明:这些参数都是通过 xgb.cv 调试出来的最佳参数
2.model_xgb.fit(X_train, y)
- 用训练集特征 X_train 和训练集标签 y 训练模型
- 训练完成后,model_xgb 就可以用于预测
Q2:我能不能理解成XGBRegressor就是专门的预测模型,那为什么还要重新用预测模型来再训练一次train.data?
- 前面的 xgb.cv () 只是 “测试、调参”,没有生成真正能用的模型,只是为了帮你找到最好的参数:n_estimators, max_depth, learning_rate
- 现在的XGBRegressor.fit () = 正式训练(产生可预测模型)
5.预测并提交
# XGBoost模型预测测试集,并对对数化的结果进行指数还原
xgb_preds = np.expm1(model_xgb.predict(X_test))
# Lasso模型预测测试集,并对对数化的结果进行指数还原
lasso_preds = np.expm1(model_lasso.predict(X_test))
# 将两个模型的预测结果保存到DataFrame中
predictions = pd.DataFrame({"xgb":xgb_preds, "lasso":lasso_preds})
# 绘制散点图,查看两个模型预测结果的相关性
predictions.plot(x = "xgb", y = "lasso", kind = "scatter")
<AxesSubplot:xlabel='xgb', ylabel='lasso'>out:<AxesSubplot:xlabel='xgb', ylabel='lasso'>
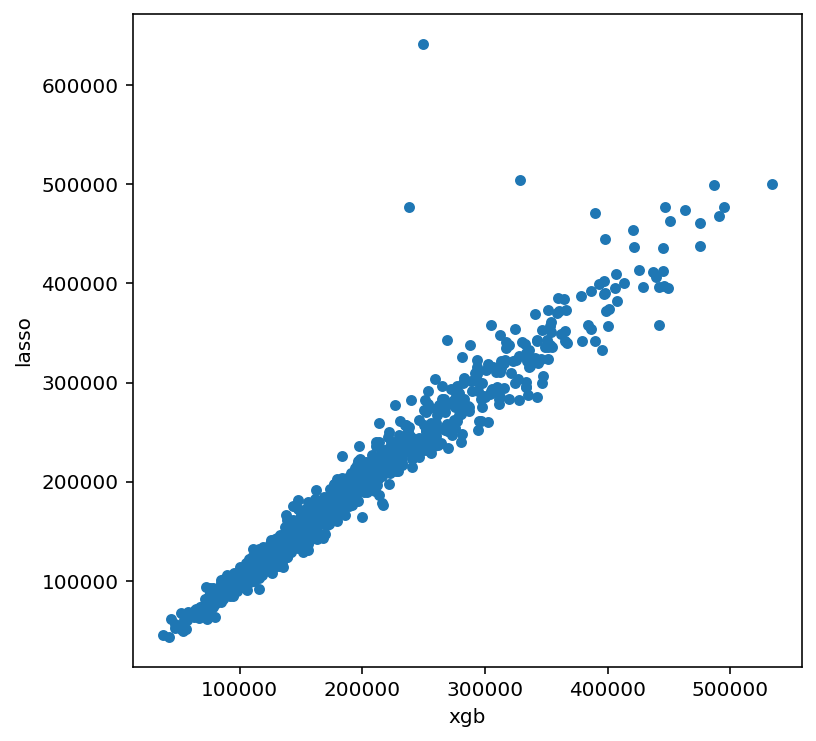
Q1:代码层面
- fit() = 学习 / 训练
- .predict() = 预测 / 做题
Q2:图该怎么看
- 点越贴近对角线 → 两个模型预测越一致
- 点分散 → 两个模型有互补性,融合后分数会更高
原文:多数情况下,对相关性低的模型预测结果做加权平均融合是很合理的做法;这通常能提升模型分数,不过在当前数据集里,融合带来的提升并不会特别大。这里我们只用一个随手选定的固定权重来做加权平均。我们其实也可以用交叉验证网格搜索,来选出最优融合权重。
# 模型融合:对 Lasso 和 XGBoost 的预测结果做加权平均
# 70% 权重给 Lasso,30% 权重给 XGBoost
preds = 0.7*lasso_preds + 0.3*xgb_preds
# 构造提交文件:包含 房屋ID 和 最终预测房价
solution = pd.DataFrame({"id":test.Id, "SalePrice":preds})
# 保存为 CSV 文件,用于上传 Kaggle 排行榜
solution.to_csv("ridge_sol.csv", index = False)Q1;思维扩展2(见后文)
三.思维扩展
思维扩展1:lasso模型岂不是可以拿来做EDA,如何保证lasso不错误的删除有用的特征,删除逻辑是啥?
1. Lasso 删除特征的真正逻辑
Lasso 的核心公式:
损失函数 = 预测误差 + alpha * |所有特征权重之和|
① 尽量让预测准
② 同时尽量让特征权重变小(越小越好,最好变成 0)
当权重变成 0 = 特征被删除
Lasso 删特征的真实规则:
规则 1:两个特征高度相关 → 只留一个,删另一个
比如:地上面积,居住面积
两个几乎一样 → Lasso 随便删一个,不是因为没用,是重复了。
规则 2:特征对预测没帮助 → 直接删
比如 ID、乱码、无关列。
规则 3:噪声特征、随机波动特征 → 强制删
规则 4:alpha 越大 → 删得越狠
那 Lasso 会不会误删有用特征?
会!而且非常容易!主要 2 个原因:
-
特征共线性(最常见)A 和 B 高度相关 → Lasso 删一个,不是它没用,是重复了。
-
alpha 选得太大正则太强 → 删太多 → 欠拟合。
如何保证 Lasso 不错误删除有用特征?
方法 1:用 LassoCV,不要手动设 alpha(最重要)
model_lasso = LassoCV(alphas=[...]).fit(X_train, y)
LassoCV 自动选最温和、最不容易误删的 alpha→ 这是防误删第一神器
方法 2:看系数稳定性(不要只跑一次)
跑多次 Lasso,看:每次都保留 → 真重要,每次都变 → 共线特征
方法 3:不要只看 “删不删”,要看权重大小
-
权重接近 0 → 不重要
-
权重大 → 重要
-
权重 = 0 → 被删除
方法 4:结合业务知识判断(EDA 核心)
比如:Lasso 删了 “卧室数”,但常识知道卧室数很重要 →说明它和面积共线了
方法 5:特征先做标准化(必须做)
Lasso 对量纲敏感不标准化 → 容易误删数值小的特征
方法 6:用 Stability Selection / 自助采样(高级防误删)
多次抽样、多次跑 Lasso:
-
出现频率高 → 真重要
-
偶尔出现 → 共线 / 不稳定
4. 最关键的一句话总结
Lasso 删特征不是看 “有没有用”,而是看 “在所有特征里,这个特征是否带来增量信息”。
重复的、没用的、噪声的 → 都会被删。只要用 LassoCV + 观察稳定性,就能避免 99% 的误删。
思维扩展2:如何用CV Grid Search(交叉验证网格搜索)自动找最优融合权重
# 导入数值计算库,用于数组、数学计算
import numpy as np
# 导入表格处理库,用于数据整理
import pandas as pd
# 导入网格搜索 + 交叉验证工具,用来自动找最优参数
from sklearn.model_selection import GridSearchCV
# 导入自定义模型必须继承的两个基础类(固定写法)
from sklearn.base import BaseEstimator, RegressorMixin
# ---------------------------
# 1. 定义一个融合模型(专门用来网格搜索)
# ---------------------------
# 自定义一个“模型融合类”,继承 sklearn 的标准格式,才能被 GridSearchCV 使用
class BlendModel(BaseEstimator, RegressorMixin):
# 初始化函数:创建模型时会自动运行
# alpha 是 Lasso 的权重,默认 0.5
def __init__(self, alpha=0.5):
self.alpha = alpha # 把权重 alpha 存到模型里,后面网格搜索会自动修改它
# 训练函数:sklearn 要求必须有,但我们这里只是融合,不需要训练
def fit(self, X, y=None):
# 什么都不用做,直接返回自己就行(固定写法)
return self
# 预测函数:真正执行 模型融合 计算的地方
def predict(self, X):
# X 是一个二维数组
# X[:,0] = 第一列 → Lasso 模型的预测值
lasso = X[:, 0]
# X[:,1] = 第二列 → XGBoost 模型的预测值
xgb = X[:, 1]
# 核心公式:加权平均融合
# 最终预测 = alpha * Lasso预测 + (1-alpha) * XGB预测
return self.alpha * lasso + (1 - self.alpha) * xgb
# ---------------------------
# 2. 构造输入:把两个模型的预测结果拼在一起
# ---------------------------
# 注意:这里必须用【训练集的交叉验证预测值】,绝对不能用测试集!
# 你需要提前生成:
# oof_lasso = Lasso 在训练集上做交叉验证得到的预测值
# oof_xgb = XGBoost 在训练集上做交叉验证得到的预测值
# 把两个模型的预测值 左右拼起来,变成 2列 的数据
# 第一列:Lasso预测
# 第二列:XGB预测
X_blend = np.column_stack((oof_lasso, oof_xgb))
# 真实的房价标签(训练集的y,已经log处理过)
y_true = y
# ---------------------------
# 3. 网格搜索最优 alpha
# ---------------------------
# 定义要搜索的参数范围:
# alpha 从 0.1 到 0.9,每隔 0.05 取一个值试一遍
param_grid = {"alpha": np.arange(0.1, 1.0, 0.05)}
# 创建网格搜索对象
grid = GridSearchCV(
estimator=BlendModel(), # 要搜索的模型:我们自定义的融合模型
param_grid=param_grid, # 要搜索的参数范围
cv=5, # 5折交叉验证(把数据分成5份,轮流验证)
scoring="neg_mean_squared_error", # 用均方误差评估模型好坏
n_jobs=-1 # 使用所有CPU核心,加速计算
)
# 开始暴力搜索:遍历所有alpha,自动计算哪个分数最好
grid.fit(X_blend, y_true)
# ---------------------------
# 4. 输出最优权重
# ---------------------------
# 输出网格搜索找到的最优 alpha 值
print("最优 alpha:", grid.best_params_['alpha'])
# 输出最优模型的交叉验证误差(RMSE),越小越好
print("最优交叉验证误差:", np.sqrt(-grid.best_score_))四.总结
原来搭建模型训练比我想象的要简单的多,全都是封装好的接口函数,重要的是模型的选择,经验和思路,简单的模型,比如本文中的,用的好的话照样能有不错的效果,其次,可以用多个模型进行预测,然后交叉验证融合模型,可以进一步减小loss提升分数。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)