Python SQLAlchemy ORM 完整使用流程(附代码+图文说明)
Python SQLAlchemy ORM 完整使用流程(附实战代码+图文说明)
前言:SQLAlchemy 是 Python 中最常用的 ORM(对象关系映射)框架,核心优势是将 Python 类与数据库表进行映射,无需编写原生 SQL 语句,就能完成数据库的增删改查操作,大幅提升开发效率、降低代码冗余。本文将从安装到实战,一步步讲解 SQLAlchemy ORM 的完整使用流程,代码可直接复制运行,新手也能快速上手。
目录
-
1. 环境准备(安装 SQLAlchemy)
-
2. SQLAlchemy ORM 核心流程拆解
-
3. 完整实战代码(附详细注释)
-
4. 关键注意事项(避坑指南)
-
5. 常见问题排查
1. 环境准备(安装 SQLAlchemy)
首先需要安装 SQLAlchemy 框架,同时根据自己使用的数据库(如 MySQL、SQLite、PostgreSQL),安装对应的数据库驱动(本文以 MySQL 和 SQLite 为例,覆盖大部分开发场景)。
1.1 安装命令(pip 方式)
# 安装 SQLAlchemy 核心框架
pip install sqlalchemy
# 若使用 MySQL,需安装 pymysql 驱动(本文实战用这个)
pip install pymysql
# 若使用 SQLite,无需额外安装驱动(Python 自带)
# 若使用 PostgreSQL,安装 psycopg2-binary
# pip install psycopg2-binary
1.2 导入核心模块
安装完成后,在代码中导入 SQLAlchemy ORM 所需的核心模块,后续所有操作都基于这些模块展开:
# 导入数据库连接引擎、字段类型
from sqlalchemy import create_engine, Column, Integer, String, DateTime
# 导入 ORM 基类(所有模型类必须继承)
from sqlalchemy.ext.declarative import declarative_base
# 导入会话工厂(操作数据库的入口)
from sqlalchemy.orm import sessionmaker
# 可选:导入时间模块,用于设置默认时间
from datetime import datetime
2. SQLAlchemy ORM 核心流程拆解
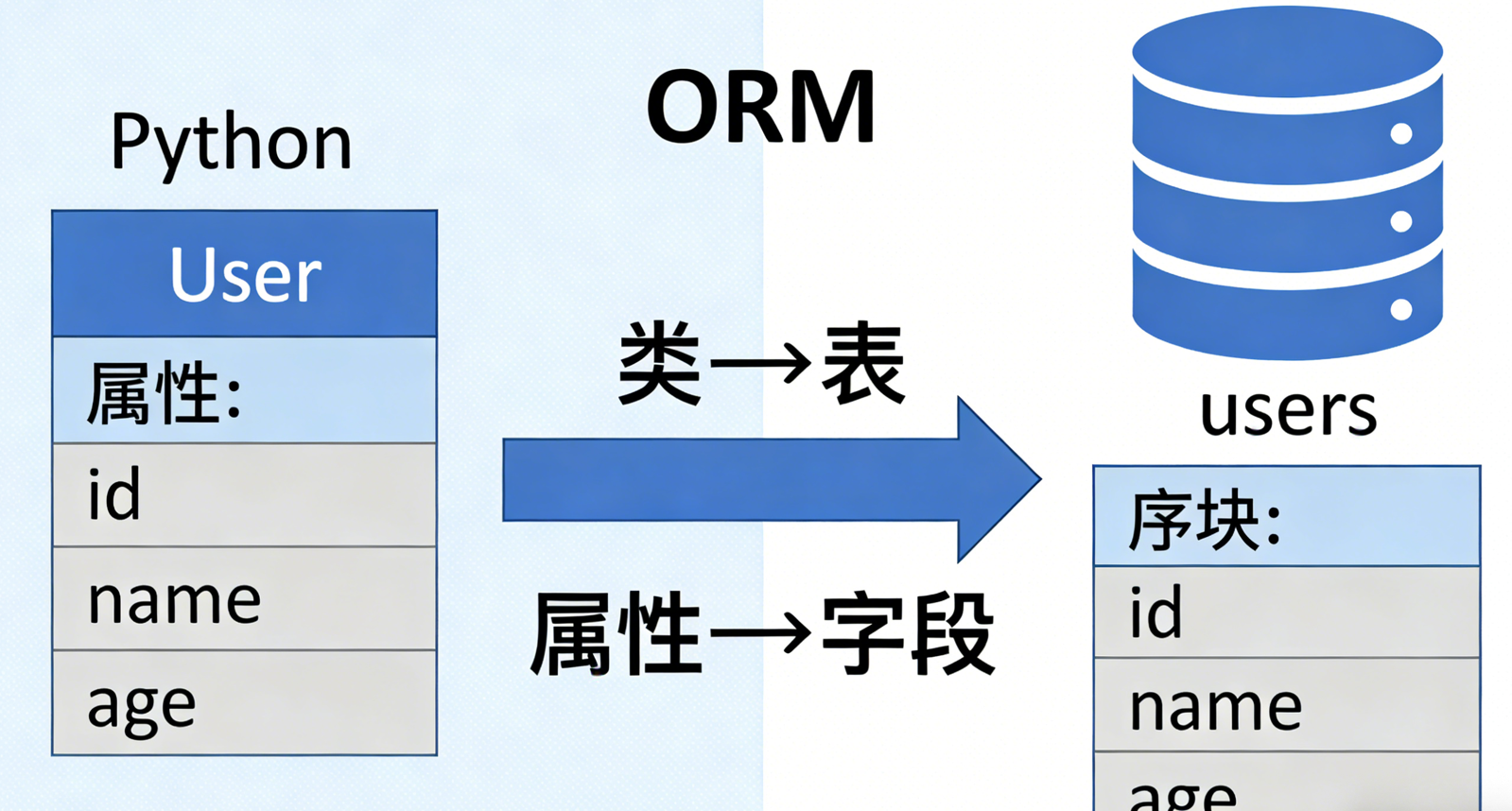
SQLAlchemy ORM 的使用流程非常固定,核心分为 5 个步骤,记住这个流程,就能应对绝大多数数据库操作场景,如下图所示(配图建议:用思维导图或流程图展示,可参考下方文字流程绘制):

步骤1:创建数据库连接引擎(Engine)
Engine 是 SQLAlchemy 与数据库之间的连接核心,负责管理数据库连接池、执行 SQL 语句(底层自动处理),无需我们手动管理连接。
不同数据库的引擎连接格式不同,本文给出最常用的 2 种(MySQL 和 SQLite),直接替换参数即可使用:
# 方式1:MySQL 连接(推荐,实际开发常用)
# 格式:mysql+pymysql://用户名:密码@主机地址:端口号/数据库名?字符集
engine = create_engine(
"mysql+pymysql://root:123456@localhost:3306/test_db?charset=utf8mb4",
echo=True, # echo=True 表示打印底层执行的 SQL 语句,便于调试(生产环境可关闭)
pool_size=5, # 连接池大小,默认5,可根据需求调整
max_overflow=10 # 连接池最大溢出数,超出pool_size的临时连接数
)
# 方式2:SQLite 连接(无需安装驱动,适合本地测试、小型项目)
# 格式:sqlite:///数据库文件路径(相对路径/绝对路径)
# engine = create_engine("sqlite:///test.db", echo=True)
注意:MySQL 连接时,需先确保本地 MySQL 服务已启动,且已创建对应的数据库(如上述的 test_db),否则会报错。
步骤2:创建 ORM 基类(Base)
declarative_base() 会创建一个基类,所有需要映射到数据库表的 Python 类,都必须继承这个基类。基类会自动管理所有子类(模型),后续的建表、查表等操作,都依赖这个基类。
# 创建 ORM 基类(所有 ORM Model 继承此类)
class Base(DeclarativeBase):
pass
步骤3:定义 ORM 模型(映射数据库表)
这一步是 ORM 的核心:将 Python 类与数据库表进行映射,类名对应表名,类的属性对应表的字段。
模型类必须满足 2 个要求:① 继承 Base 基类;② 定义 __tablename__ 属性(指定映射的数据库表名);③ 至少定义一个主键字段(primary_key=True)。
# 定义 User 模型(映射数据库中的 users 表)
class User(Base):
# __tablename__:指定映射的数据库表名,必须有
__tablename__ = "users"
# 定义字段:字段名 = Column(字段类型, 约束条件)
id = Column(Integer, primary_key=True, autoincrement=True, comment="用户ID(主键,自增)")
name = Column(String(50), nullable=False, comment="用户名(非空)")
age = Column(Integer, nullable=True, default=18, comment="用户年龄(默认18)")
email = Column(String(100), unique=True, comment="用户邮箱(唯一)")
create_time = Column(DateTime, default=datetime.now, comment="创建时间(默认当前时间)")
# 可根据需求定义多个模型(如 Order、Product 等),每个模型对应一张表
class Order(Base):
__tablename__ = "orders"
order_id = Column(Integer, primary_key=True, autoincrement=True, comment="订单ID")
user_id = Column(Integer, comment="关联用户ID(与users表的id对应)")
order_name = Column(String(100), nullable=False, comment="订单名称")
步骤4:创建数据库表
通过 Base 基类的 metadata.create_all(engine) 方法,会自动根据模型类,在数据库中创建对应的表(如果表已存在,则不会重复创建,避免覆盖数据)。
# 根据模型类,自动创建数据库表(若表已存在,不重复创建)
Base.metadata.create_all(engine)
执行这行代码后,打开 MySQL 客户端(如 Navicat、DBeaver),就能看到 test_db 数据库中,自动创建了 users 和 orders 两张表,字段、约束、注释都与模型类一致。
步骤5:创建会话(Session)
Session 是 SQLAlchemy ORM 操作数据库的入口,相当于一个“数据库操作会话”,所有的增删改查操作,都需要通过 Session 来完成,同时 Session 负责管理事务(提交、回滚)。
# 创建会话工厂(绑定引擎)
Session = sessionmaker(bind=engine)
# 创建一个会话实例(每次操作数据库,都需要创建会话)
session = Session()
步骤6:通过 Session 执行增删改查操作
会话创建完成后,就可以通过 session 对象,执行各种数据库操作,无需编写原生 SQL,全程用 Python 语法操作即可。
6.1 新增数据(insert)
# 方式1:新增单条数据
user1 = User(name="张三", age=22, email="zhangsan@163.com")
session.add(user1) # 将数据添加到会话
# 方式2:新增多条数据(效率更高)
user2 = User(name="李四", age=25, email="lisi@163.com")
user3 = User(name="王五", age=20, email="wangwu@163.com")
session.add_all([user2, user3]) # 批量添加
# 注意:此时数据还在会话中,未写入数据库,需要执行 commit() 提交事务
session.commit()
6.2 查询数据(select)
查询是最常用的操作,SQLAlchemy ORM 提供了丰富的查询方法,以下是最常用的几种:
# 1. 查询所有数据(返回列表,元素是 User 对象)
all_users = session.query(User).all()
for user in all_users:
print(f"用户ID:{user.id},用户名:{user.name},邮箱:{user.email}")
# 2. 查询单条数据(返回第一个匹配的对象,没有则返回 None)
user = session.query(User).filter(User.name == "张三").first()
print(f"查询到的用户:{user.name},年龄:{user.age}")
# 3. 条件查询(多条件,用 and_ / or_ 连接,需导入)
from sqlalchemy import and_, or_
users = session.query(User).filter(and_(User.age > 20, User.name != "张三")).all()
# 4. 排序查询(按 age 升序,desc() 表示降序)
users_order = session.query(User).order_by(User.age).all() # 升序
# users_order = session.query(User).order_by(User.age.desc()).all() # 降序
# 5. 分页查询(skip 跳过前2条,limit 取3条,适合分页场景)
users_page = session.query(User).skip(2).limit(3).all()
6.3 修改数据(update)
修改数据的思路:先查询到需要修改的对象,再修改对象的属性,最后提交事务。
# 1. 先查询到需要修改的对象
user = session.query(User).filter(User.name == "李四").first()
if user:
# 2. 修改对象的属性(直接赋值即可)
user.age = 26
user.email = "lisi_new@163.com"
# 3. 提交事务(修改生效)
session.commit()
print("修改成功")
6.4 删除数据(delete)
删除数据的思路:先查询到需要删除的对象,再通过 session.delete() 删除,最后提交事务。
# 1. 先查询到需要删除的对象
user = session.query(User).filter(User.name == "王五").first()
if user:
# 2. 删除对象
session.delete(user)
# 3. 提交事务(删除生效)
session.commit()
print("删除成功")
步骤7:提交/回滚事务
所有增删改操作,都必须通过 session.commit() 提交事务,才能真正写入数据库;如果操作过程中出现错误,可通过 session.rollback() 回滚事务,恢复到操作前的状态。
try:
# 执行增删改操作
user = User(name="赵六", age=28, email="zhaoliu@163.com")
session.add(user)
# 提交事务
session.commit()
print("操作成功")
except Exception as e:
# 出现错误,回滚事务
session.rollback()
print(f"操作失败,已回滚:{str(e)}")
步骤8:关闭会话
数据库操作完成后,必须关闭会话,释放数据库连接,避免连接泄露(尤其是生产环境,否则会导致数据库连接耗尽)。
# 关闭会话
session.close()
3. 完整实战代码(附详细注释)
将上述所有步骤整合,给出完整可运行的实战代码,复制到 Python 文件中,替换 MySQL 连接参数,即可直接运行:
from sqlalchemy import create_engine, Column, Integer, String, DateTime, and_
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from datetime import datetime
# 1. 创建数据库引擎(MySQL 连接,替换为自己的数据库参数)
engine = create_engine(
"mysql+pymysql://root:123456@localhost:3306/test_db?charset=utf8mb4",
echo=True,
pool_size=5,
max_overflow=10
)
# 2. 创建 ORM 基类
Base = declarative_base()
# 3. 定义模型类(映射数据表)
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, autoincrement=True, comment="用户ID(主键,自增)")
name = Column(String(50), nullable=False, comment="用户名(非空)")
age = Column(Integer, nullable=True, default=18, comment="用户年龄(默认18)")
email = Column(String(100), unique=True, comment="用户邮箱(唯一)")
create_time = Column(DateTime, default=datetime.now, comment="创建时间")
# 4. 自动创建数据表(若已存在则不创建)
Base.metadata.create_all(engine)
# 5. 创建会话
Session = sessionmaker(bind=engine)
session = Session()
try:
# 6. 增:新增数据
user1 = User(name="张三", age=22, email="zhangsan@163.com")
user2 = User(name="李四", age=25, email="lisi@163.com")
session.add_all([user1, user2])
# 查:查询数据
all_users = session.query(User).all()
print("所有用户:")
for user in all_users:
print(f"ID: {user.id}, 姓名: {user.name}, 邮箱: {user.email}")
# 改:修改数据
user = session.query(User).filter(User.name == "李四").first()
if user:
user.age = 26
print("修改后李四的年龄:", user.age)
# 删:删除数据(注释掉,避免误删,需要时取消注释)
# user_del = session.query(User).filter(User.name == "张三").first()
# if user_del:
# session.delete(user_del)
# print("删除成功")
# 7. 提交事务
session.commit()
print("所有操作执行成功")
except Exception as e:
# 出错回滚
session.rollback()
print(f"操作失败,已回滚:{str(e)}")
finally:
# 8. 关闭会话(无论成功失败,都要关闭)
session.close()
print("会话已关闭")
4. 关键注意事项(避坑指南)
-
⚠️ 会话管理:每次操作数据库后,必须关闭会话(建议用 try-finally 确保关闭),避免连接泄露。
-
⚠️ 事务提交:增删改操作必须执行 session.commit(),否则数据不会写入数据库(仅停留在会话中)。
-
⚠️ 模型约束:定义模型时,主键(primary_key)必须有;unique(唯一)、nullable(非空)等约束,要根据业务需求设置,避免数据异常。
-
⚠️ 数据库驱动:使用 MySQL 必须安装 pymysql,使用 PostgreSQL 必须安装 psycopg2-binary,否则会报错“no module named xxx”。
-
⚠️ echo 参数:开发环境可设为 True(打印 SQL),便于调试;生产环境建议设为 False,避免日志冗余。
5. 常见问题排查
问题1:连接 MySQL 时报错“Access denied for user 'root'@'localhost' (using password: YES)”
解决方案:检查 MySQL 用户名、密码是否正确;检查 MySQL 服务是否已启动;检查 root 用户是否有访问 test_db 数据库的权限。
问题2:创建表时报错“Table 'users' already exists”
解决方案:Base.metadata.create_all(engine) 会自动判断表是否存在,无需手动删除;若确实需要重新建表,可先删除原有表,再执行建表语句(生产环境慎用)。
问题3:新增数据时报错“Duplicate entry 'zhangsan@163.com' for key 'users.email'”
解决方案:email 字段设置了 unique=True(唯一约束),避免重复插入相同邮箱;可先查询邮箱是否已存在,再执行新增操作。
结尾
以上就是 Python SQLAlchemy ORM 的完整使用流程,从环境准备、引擎创建、模型定义,到会话操作、增删改查,覆盖了新手入门到实战的所有核心内容。掌握这个流程后,就能轻松用 ORM 操作数据库,摆脱原生 SQL 的繁琐。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)