浙大团队提出PowerGPT:面向电力巡检的多模态基础模型,构建20万张图像数据集与专用评估基准

导读:
———————————————————————————————————————————
电力巡检是保障电网安全运行的关键环节,但当前智能化巡检面临一个尴尬局面:绝缘子缺陷检测需要一个模型、安全帽识别需要另一个模型、红外过热分析又是一个模型——每个任务各自训练、各自部署,成本不断膨胀。能否用一个多模态基础模型统一处理所有电力巡检任务?浙江大学团队给出了他们的方案:PowerGPT。
这项工作的价值不仅在于模型本身,更在于它为电力巡检领域构建了一套完整的基础设施——包含约20万张图像、80万条指令-回答对的 PSID数据集,覆盖70个真实安全场景的 PowerBENCH评估基准,以及融合自适应视觉提示、知识检索增强的 PowerGPT模型。在PowerBENCH上,PowerGPT在5项任务中均取得最高分—Grounded Caption得分9.6(LLaVA为5.0),计数任务得分9.2(LLaVA为5.9),全面领先同等规模的通用模型。消融实验显示,仅PSID数据集微调就带来了平均+13.82分的提升,验证了领域数据的核心价值。
论文信息
———————————————————————————————————————————
标题: PowerGPT: A multimodal foundation model for power inspection
作者: Yangyang Zhong, Pengxin Luo, Yunfeng Yan, Tong Jia, Donglian Qi
机构: 浙江大学海洋学院 / 浙江大学电气工程学院 / 浙江大学海南研究院 / 东北大学信息科学与工程学院
期刊: Applied Soft Computing Journal 186 (2026) 113939
DOI: https://doi.org/10.1016/j.asoc.2025.113939
一、电力巡检智能化的三重瓶颈
———————————————————————————————————————————
电力巡检场景的智能化面临三个层面的挑战。
- 数据稀缺:电力设备图像的获取和标注门槛较高,公开可用的标注数据集十分有限,导致模型难以获得足够的领域知识来实现泛化。
- 任务碎片化:电力巡检涵盖多种视觉任务——绝缘子缺陷检测、人员安全行为识别、设备过热分析、施工设施监测等。传统做法是为每个任务训练独立模型,训练和部署成本随任务数量线性增长。
- 领域推理能力不足:通用多模态大语言模型(MLLM)虽然具备一定的视觉理解能力,但在电力领域的专业术语和安全规范方面缺乏知识储备,容易产生幻觉(hallucination),难以直接用于生产环境。
PowerGPT的设计思路是:先用大规模领域数据集解决数据稀缺问题,再用统一的多模态模型架构覆盖多种巡检任务,最后通过知识检索增强机制补充领域专业知识。

二、PSID数据集与PowerBENCH评估基准
PSID数据集
PSID(Power Safety Instruction Dataset)是这项工作构建的电力巡检领域指令微调数据集,包含约 200,000张图像和 800,000条指令-回答对。
数据来源于全国各地变电站和输电站的运维摄像头,覆盖四大类场景:
|
场景类别 |
内容描述 |
|---|---|
|
设备状态与环境异常 |
绝缘子缺陷、线路断股、鸟巢等 |
|
人员与动物行为异常 |
安全帽佩戴、违规操作、动物入侵等 |
|
设备过热 |
红外热像图中的温度异常 |
|
大型施工设施 |
无人机航拍视角下的施工现场监测 |
数据生成流程分三步:
元数据准备:人工标注原始图像的目标类别和位置信息
种子指令生成:通过New Bing API为每张图像生成多样化的指令模板
标准化转换:使用GPT-3.5 Turbo将种子数据转换为标准化的指令-回答格式
质量控制方面,10位电力专业人员对生成数据进行抽样质检,**错误率低于1%**。
PowerBENCH评估基准
PowerBENCH是面向电力巡检的标准化评估基准,覆盖 70个真实电力安全场景,包含5项视觉任务:
|
任务 |
缩写 |
评估能力 |
|---|---|---|
|
Grounded Caption |
GC |
图像描述+目标定位 |
|
Referential Expression Comprehension |
REC |
给文字描述定位目标 |
|
Referential Expression Generation |
REG |
给目标生成文字描述 |
|
Counting |
Count |
目标计数 |
|
Knowledge QA |
KNO |
电力领域知识问答 |
评估方式采用GPT-4作为评估器,对模型输出进行0-10分打分。GPT-4评分与人类专家评分的 Pearson相关系数达到0.85以上,验证了这一评估方式的可靠性。
三、PowerGPT模型架构:四个模块如何协同工作
———————————————————————————————————————————
PowerGPT基于LLaVA架构扩展,由四个核心模块构成,语言模型底座为 Vicuna-v1.1-7B。
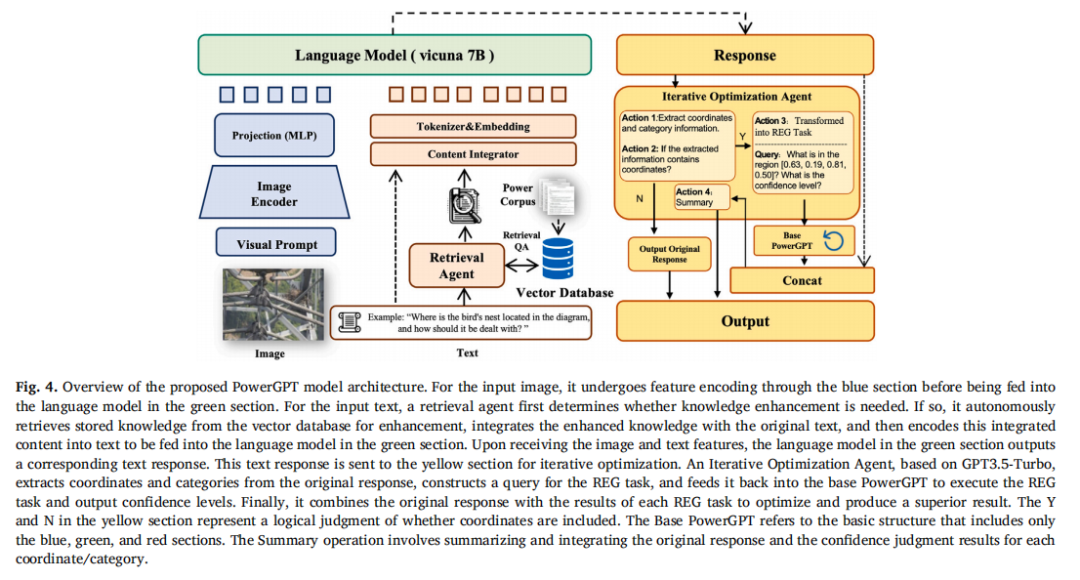
1. 自适应视觉提示(Adaptive Visual Prompt, AVP)
电力巡检图像中目标的空间分布差异很大——变电站内设备排列规整,适合笛卡尔坐标系描述;而输电线路沿弧线分布,极坐标可能更合适;有些场景则不需要额外坐标提示。
AVP模块使用一个 ResNet-18分类器,根据输入图像自动选择最优的坐标提示类型(极坐标、笛卡尔坐标或无提示),并将选定的坐标轴叠加到原图上,增强模型的空间感知能力。
2. 图像编码器(Image Encoder, IE)
为了在保留细节的同时控制计算开销,图像编码器采用分块处理策略:
将输入图像固定分割为 9块
每块resize到 448x448
通过 CLIP-ViT-L/14编码
使用 Perceiver Resampler将每块的视觉token压缩为固定长度(每块64个token,维度4096)
这种设计使模型能够处理高分辨率图像中的小目标(如绝缘子裂纹),同时将视觉token总数控制在可接受范围内。
3. 知识检索增强(Knowledge Retrieval Enhancement, KRE)
通用MLLM在电力领域专业知识上的不足通过外部知识库补偿。KRE模块基于 LangChain + QDRANT向量数据库,存储约 200万token的电力领域知识(包括设备规范、安全标准等)。
检索时使用 MultiQueryRetriever,从多个角度对用户查询进行改写,提高检索召回率。检索到的相关知识作为上下文拼接到LLM输入中。
4. 迭代优化Agent(Iterative Optimization Agent, IO)
IO模块用于提升模型输出中坐标和类别的准确性。其工作流程为:
基于GPT-3.5 Turbo从初始输出中提取坐标和类别信息
构造REG(Referential Expression Generation)验证任务
将验证任务送入Base PowerGPT获取置信度
根据置信度合并和优化最终输出
训练配置
4块 NVIDIA A100 GPU
视觉编码器(CLIP-ViT-L/14)参数冻结
压缩层和LLM进行微调
训练1个epoch,batch size 32,学习率2e-5,优化器AdamW
【插图建议:Fig. 4 — PowerGPT模型架构图,插入本节开头】
四、消融实验:领域数据微调贡献最大,各模块逐步叠加
———————————————————————————————————————————
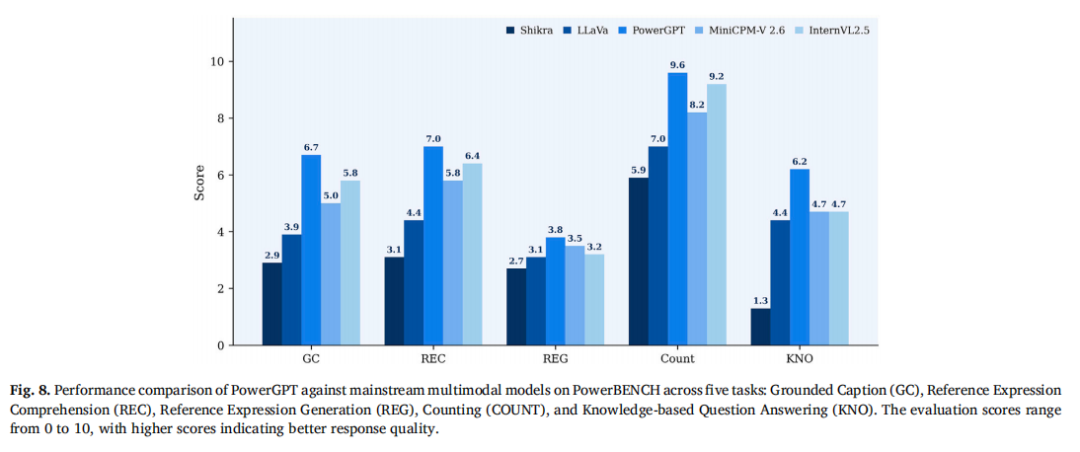
PowerBENCH主实验
在PowerBENCH基准上,PowerGPT与4个对比模型的结果如下(GPT-4评分,0-10分):
|
任务 |
Shikra |
LLaVA |
MiniCPM-V2.6 |
InternVL2.5 |
PowerGPT |
|---|---|---|---|---|---|
|
GC |
2.9 |
5.0 |
3.9 |
6.7 |
9.6 |
|
REC |
3.1 |
3.8 |
5.8 |
4.4 |
7.0 |
|
REG |
2.7 |
3.1 |
3.8 |
3.5 |
6.4 |
|
Count |
3.2 |
5.9 |
8.2 |
7.0 |
9.2 |
|
KNO |
1.3 |
4.4 |
4.7 |
4.7 |
6.2 |
PowerGPT在所有5项任务上均取得最高分。与同为7B参数量级的LLaVA相比,各项绝对分差为:
GC: +4.6分
REC: +3.2分
REG: +3.3分
Count: +3.3分
KNO: +1.8分
与InternVL2.5相比,PowerGPT在GC上高出+2.9分,在KNO上高出+1.5分。
统计显著性检验(配对双尾t检验)显示,所有任务的差异均达到统计显著水平(p<0.05):GC p=0.0004, REC p=0.0008, Count p=0.028, REG p=0.038。
各模块贡献的消融实验
在500样本子集上(0-100分制),逐步叠加各模块的效果如下:
|
配置 |
GC |
REC |
REG |
Count |
KNO |
平均 |
|---|---|---|---|---|---|---|
|
LLaVA (基线) |
38.58 |
44.34 |
31.91 |
70.28 |
43.68 |
46.56 |
|
+FT (PSID微调) |
61.01 |
63.81 |
39.71 |
83.29 |
54.08 |
60.38 |
|
+FT+IE |
65.21 |
66.81 |
40.95 |
89.59 |
54.08 |
62.98 |
|
+FT+IE+AVP |
66.01 |
68.67 |
37.04 |
94.54 |
54.08 |
63.67 |
|
+FT+IE+AVP+IO |
67.89 |
70.80 |
38.83 |
96.83 |
54.08 |
65.69 |
|
+FT+IE+AVP+IO+KRE |
67.89 |
70.80 |
38.83 |
96.83 |
62.50 |
67.37 |
几个关键发现:
- PSID微调是最大的单一贡献因素:仅数据集微调就将平均分从46.56提升到60.38(+13.82分),GC提升+22.43分,REC提升+19.47分。这说明在垂直领域,高质量标注数据的价值大于模型架构的精巧设计。
- 图像编码器(IE)在计数任务上提升明显:IE模块在Count上带来+6.3分提升,分块高分辨率处理对识别和计数密集排列的电力设备较为有效。
- 自适应视觉提示(AVP)在REG上出现性能下降:AVP使REG从40.95降至37.04(-3.91分)。论文解释为坐标轴叠加可能遮挡小目标缺陷(如绝缘子裂缝),影响对细小目标的描述生成。不过AVP在Count上带来了+4.95分的提升,整体平均仍有增益。
- KRE对知识问答的提升是独立于微调的:KRE仅对KNO有影响(+8.42分,从54.08到62.50),这符合预期——KRE通过外部知识库在推理时注入领域知识,不改变模型已有的视觉理解能力。论文还报告,即使不做PSID微调,仅加入KRE也能将KNO从43.9提升到59.1(+15.2分),说明知识检索增强本身就是一条有效路径。
自适应提示 vs 固定提示
|
策略 |
GC |
REC |
REG |
Count |
|---|---|---|---|---|
|
无提示 |
66.01 |
66.81 |
40.95 |
89.59 |
|
固定极坐标 |
65.96 |
66.03 |
35.28 |
89.23 |
|
固定笛卡尔坐标 |
65.77 |
66.89 |
35.01 |
89.85 |
| AVP(自适应) | 66.01 | 68.67 |
37.04 |
94.54 |
固定使用某种坐标提示的效果并不稳定——极坐标和笛卡尔坐标在不同任务上互有优劣,且都在REG上造成明显下降。自适应策略通过学习为不同图像选择最合适的提示类型,在REC和Count上取得了最优结果,整体表现最为稳健。
五、总结与思考
———————————————————————————————————————————
PowerGPT这项工作的核心贡献在于为电力巡检领域构建了一套从数据、评估到模型的完整基础设施:
PSID数据集(约20万张图像、80万条指令-回答对)填补了电力巡检领域大规模指令微调数据的空白
PowerBENCH(70个场景、5项任务)为领域内模型对比提供了统一的评估标准
PowerGPT模型用单一模型覆盖了多种巡检任务,避免了任务碎片化带来的部署成本膨胀
从实验结果看,几个值得关注的点:
- 领域数据的价值再次得到验证。消融实验中,PSID微调带来的平均+13.82分提升远超任何单个模块的贡献,这与许多垂直领域工作的结论一致——在数据稀缺的专业领域,构建高质量数据集往往比设计新架构更能带来实质性的性能提升。
- 知识检索增强是一种低成本的领域适配手段。KRE模块无需额外微调,仅通过推理时注入外部知识就能将KNO提升+15.2分。对于需要快速适配新领域但缺乏微调资源的场景,这是一条值得考虑的路径。
- 自适应视觉提示的设计思路有参考价值,但也暴露了局限性。不同场景下最优的坐标提示类型确实不同,自适应选择优于固定策略。但AVP在REG任务上的性能下降(-3.91分)提示,坐标轴叠加对小目标场景可能产生负面影响,后续工作可能需要更精细的遮挡规避策略。
- 对比实验的局限性。PowerGPT在PowerBENCH上全面领先通用模型,但这一优势很大程度上来自PSID领域数据微调。如果将InternVL2.5或MiniCPM-V2.6也在PSID上微调,差距可能会缩小——消融实验中PSID微调贡献了平均+13.82分,远超各架构模块的增量。此外,论文未公开PSID数据集和模型权重,对后续工作的复现和扩展构成一定限制。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)