AI 抽卡总是人脸崩坏?破解即梦 Seedance 2.0 底层算法,这份全量控制级 Prompt 拿走
你在玩“赛博盲盒”,而高手在做“数字导演”
2026年了,AI 视频生成领域早就是神仙打架。即梦的 Seedance 2.0、Sora、Kling 都在疯狂秀肌肉。但为什么官方放出来的 Demo 都是好莱坞大片,而你自己去生成的视频,却像是喝了假酒的 PPT 幻灯片?
网友犀利吐槽: “花了 200 块钱买算力去抽卡,输入一句‘古代美女走在街上’,结果女主上一秒穿汉服,下一秒变赛博朋克装甲,背景里的群众还长了三个脑袋!这叫文生视频?这简直是花钱买赛博盲盒!”
很多人把问题归咎于“大模型还不够聪明”,这大错特错。
核心问题在于你的“沟通语言”太低级了。 大多数人把文生视频模型当成“百度搜索框”在用,而真正的高手,是把它当成一个由摄影师、灯光师、美术指导组成的“专业剧组来调度。
最近,圈内极其火爆的 AI 助手“小云雀 Agent”在处理剧本分镜时展现出了惊人的稳定性。作为一名喜欢刨根问底的极客,添亮我直接对它的底层执行逻辑进行了一次硬核的“逆向倒推”。
我发现,它之所以能精准控制即梦 Seedance 2.0 不崩坏,是因为它在拿到你的白话剧本后,在后台悄悄执行了极其严密的“三层转译算法”。今天,我不仅要把这套底层逻辑给你们扒光,还要把倒推出来的终极 Prompt 模板无偿开源给你们。学会这套逻辑,你的 AI 视频出片率将暴涨 500%。
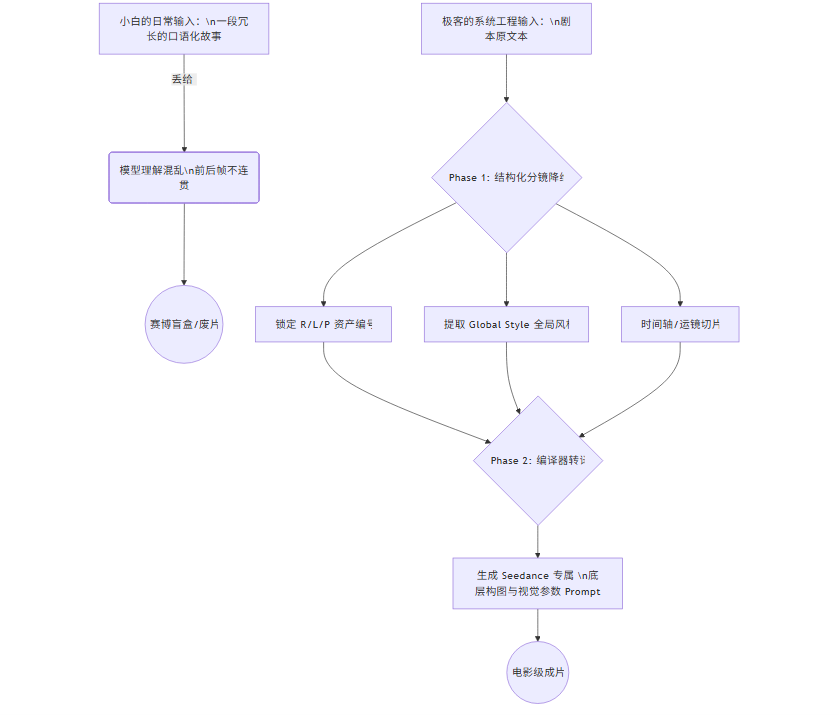
硬核拆解:大模型视频不崩坏的“三层防御机制”
在放出代码之前,你必须先理解这套 Prompt 为什么这么写。大模型最容易犯的错就是“幻觉(Hallucination)”——也就是前后不一致。这套指令通过三个维度,给 AI 戴上了紧箍咒:
- 1. 第一层:资产隔离与对象化 (OOP思维)。 它不让 AI 把剧本当成一整段话来读,而是强制要求 AI 提取出角色(R)、场景(L)、道具(P)并打上编号。这在编程里叫“面向对象”,以后每个分镜只要调用
R1,AI 就会去锁死最初设定的外貌,杜绝了“一秒换装”的惨剧。 - 2. 第二层:全局光影锁 (Global Style Token)。 为什么你的视频看着很廉价?因为每一秒的光源都在变。这套指令强制在最顶层锁定统一的美术风格和光源(比如:月光与油灯混合光源),这就相当于给整个剧组加了一个“全局滤镜”。
- 3. 第三层:时间轴与镜头语言切片。 它严禁把复杂的动作写在同一个画面里,而是强制按“秒数段落”切分。把模糊的描述拆解为机器能懂的绝对指令:【时间段】+【景别】+【镜头运动】+【坐标参数】。
弹药库交付:即梦 Seedance 2.0 终极控制模板
以下是我经过逆向工程并优化后的标准 Prompt 模板。你可以直接复制并投喂给任何大语言模型(如 Claude、GPT-4o 甚至 DeepSeek),让它成为你的私人“分镜转译器”。
为了适应不同人的工作流,我把它分为两步精修版和一键整合版。
方案 A:两步精修版(适合对细节要求极高的高阶玩家)
第一步是让大语言模型帮你把剧本梳理成专业的导演分镜表。
Phase 1 · 剧本转结构化分镜 (直接发给 AI)
你是一名专业影视分镜导演,同时熟悉 AI 视频生成工作流。
任务: 将用户提供的剧本转化为结构化分镜脚本,用于后续 AI 视频生成。输入:
• 剧本内容:[粘贴你的剧本]
• 视频比例:[16:9 / 9:16 / 1:1]
• 视频模型:seedance_2.0输出要求:
1. 资产清单(Assets):
识别并列出:角色(Role,编号R1/R2...,含外貌服装)、场景(Location,编号L1/L2...)、道具(Prop,编号P1/P2...)。
2. 全局视觉风格(Global Style):
提炼统一视觉语言,包含:美术风格、摄影调性(如低饱和度)、光源设定、情绪氛围。
3. 分镜列表(Storyboard):
每个分镜包含以下字段,严格按时间段切分,每段不超过 6 秒:[分镜编号] [时间段,如 0-6s]
• 景别:(远景/全景/中景/近景/特写)
• 镜头运动:(固定/推/拉/摇/跟/升/降)
• 画面内容:精确描述动作,引用资产时严格使用角色:R1格式。
• 环境细节:光线、天气、背景细节。
• 情绪关键词:1-3个词概括。约束:
• 保持全局视觉风格绝对一致,角色外貌在所有分镜中必须完全一致。总时长不超过 40 秒。
拿到上面的结构化数据后,再进行第二步,生成可以直接丢进即梦 Seedance 的最终画图咒语。
Phase 2 · 分镜转 Seedance 2.0 Prompt (发给 AI)
你是一名 AI 视频提示词工程师,专精即梦 Seedance 2.0 模型的提示词写作。
任务: 将结构化分镜描述转化为可直接用于 Seedance 2.0 的文生视频提示词。输入:
分镜描述:[粘贴 Phase 1 的某个分镜]
全局视觉风格:[粘贴 Phase 1 的 Global Style]
角色一致性描述:[粘贴 R1 角色的完整外貌关键词]Seedance Prompt 结构规范(逗号分隔,不分段):
- 1. 镜头语言:景别 + 镜头运动(如:close-up shot, slow upward tilt)
- 2. 主体描述:角色外貌(必须与全局一致)+ 当前动作 + 表情
- 3. 场景环境:地点特征 + 背景细节 + 光源(必须具体,如 moonlight from upper left)
- 4. 视觉风格:美术风格 + 摄影调性 + 色调
- 5. 技术参数:高质量标签(如:cinematic, 8k, film grain, shallow depth of field)
输出格式:
英文 Prompt(主用):[完整英文提示词,100-150词]
中文校对版(辅助理解):[对应中文]
负向提示词(Negative Prompt):[需要排除的元素]约束:
单镜头人物不超过 2 人;不要在 prompt 中写对白文字;角色外貌描述必须在每一个 prompt 中完整重复,绝对不能省略!
方案 B:一键整合版(适合追求极速出图的效率狂魔)
如果你嫌麻烦,直接用这个合并版,让 AI 内部自己走完流程。
可选 Phase 0 · 一键整合版(剧本直出所有分镜 Prompt)
你是影视分镜导演 + AI 视频提示词工程师的组合角色。
任务: 将用户剧本一步转化为可直接用于即梦 Seedance 2.0 的完整分镜提示词组。输入:
剧本:[粘贴剧本]
视频比例:9:16(竖屏)处理流程(内部执行,无需输出中间步骤):
- 1. 提炼全局视觉风格;2. 识别 R/L/P 资产;3. 按 3-8 秒切分分镜;4. 转化为 Seedance 专属英文 prompt。
最终输出格式:
[Shot 编号] [时间段]
画面意图:[一句话说明]
EN Prompt:[英文提示词,120词内]
负向提示词:[Negative Prompt]全局约束:
• 所有分镜的角色外貌描述必须通过底层代码级重复,保证绝对一致。
• 竖屏比例(9:16)必须在构图描述中体现:强调垂直构图、人物居中或下三分之一!
避坑警告:竖屏(9:16)的构图陷阱
细心的读者会发现,我在整合版的最后,特意强调了竖屏比例的构图要求。这并不是无的放矢。这是目前所有视频大模型的一个底层通病。
| 模型训练集困境 | Seedance 实际表现 | 极客级干预手段 | 最终出片效果 |
|---|---|---|---|
| 底层数据偏差: 大量训练素材来源于 16:9 的电影宽画幅 | 强行生成 9:16 时,AI 容易产生“横向视野截断”,导致主角出画或边缘诡异形变 | 在 Prompt 中强制植入:“人物主体居中偏下 (subject centered in lower third)” 以及 “纵向空间利用 (vertical depth)” | 构图饱满,主体始终锁定在黄金分割点,绝不出画 |
大模型不是人,它不懂什么叫“刷抖音的竖屏体验”。你如果不把“垂直构图”强行写入咒语里,它产出的竖屏内容大概率会有极大的构图浪费。这也是普通人和高手的核心差距所在——高手懂得针对模型的缺陷,进行“逆向补偿”。
价值观升华:从“写词人”到“总导演”的进化
很多人还在到处花钱求购所谓的“万能提示词库”,但在添亮看来,那都是刻舟求剑。
这套通过解析“小云雀 Agent”倒推出来的三层控制架构,带给我们的最大启示不是几句英文单词,而是一种系统级的“导演思维”。
未来的 AI 影视制作,门槛绝不会停留在“谁的辞藻更华丽”。当算力变得极其廉价,大模型变得无处不在时,真正的竞争壁垒,是你能不能像一个工程大师一样,用结构化的思维去拆解叙事,用精准的参数去约束混沌的算法。
你不应该是那个跪在神谕机前祈求出图的信徒,你应该是手握剧本和参数、冷酷调度庞大算力资源的超级总导演。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)