从“显存到底去哪了?”到 MemScope:把训练显存讲明白的一套办法
训练大模型最让人崩溃的时刻,往往不是 loss 不降,而是那句熟悉的 CUDA out of memory。更难受的是:你明明知道“显存不够”,但你不知道显存到底被谁吃掉了。是某一层 attention 的临时 workspace?是 step0 optimizer 初始化突然把基线抬高?还是某个模块里“分配—释放”发生得太快,你的日志根本捕捉不到?
我做过不少次这种排查:看了半天 nvidia-smi,看了半天训练日志,最后结论还停留在“好像是 attention / 好像是 optimizer / 要不减 batch 吧”。这类问题的本质是——我们缺一份“可解释”的证据链:既能告诉你整体水位怎么走,又能告诉你峰值靠近哪里,还能把静态估算和真实运行对照起来,避免拍脑袋。
MemScope就是从这个痛点里长出来的工具:它把“静态估算 + 运行时追踪 + 一页 HTML 可视化”串成闭环,让显存问题从“玄学”变成“有迹可循”。
先看效果:一张图把“台阶”和“峰值”讲清楚
MemScope 运行后会产出 runtime_report.json,同时可以一键渲染出一个离线 HTML 页面。这个页面里我最常看的就是 Step-level memory timeline:它在 step 的关键边界点(step start / forward+backward end / optimizer step start/end / step end)采样显存水位,然后画出两条曲线:
allocated:PyTorch 当前真正持有的显存(更符合“我到底用了多少”)
reserved:caching allocator 向驱动申请并保留的显存(包含缓存、碎片,通常更高)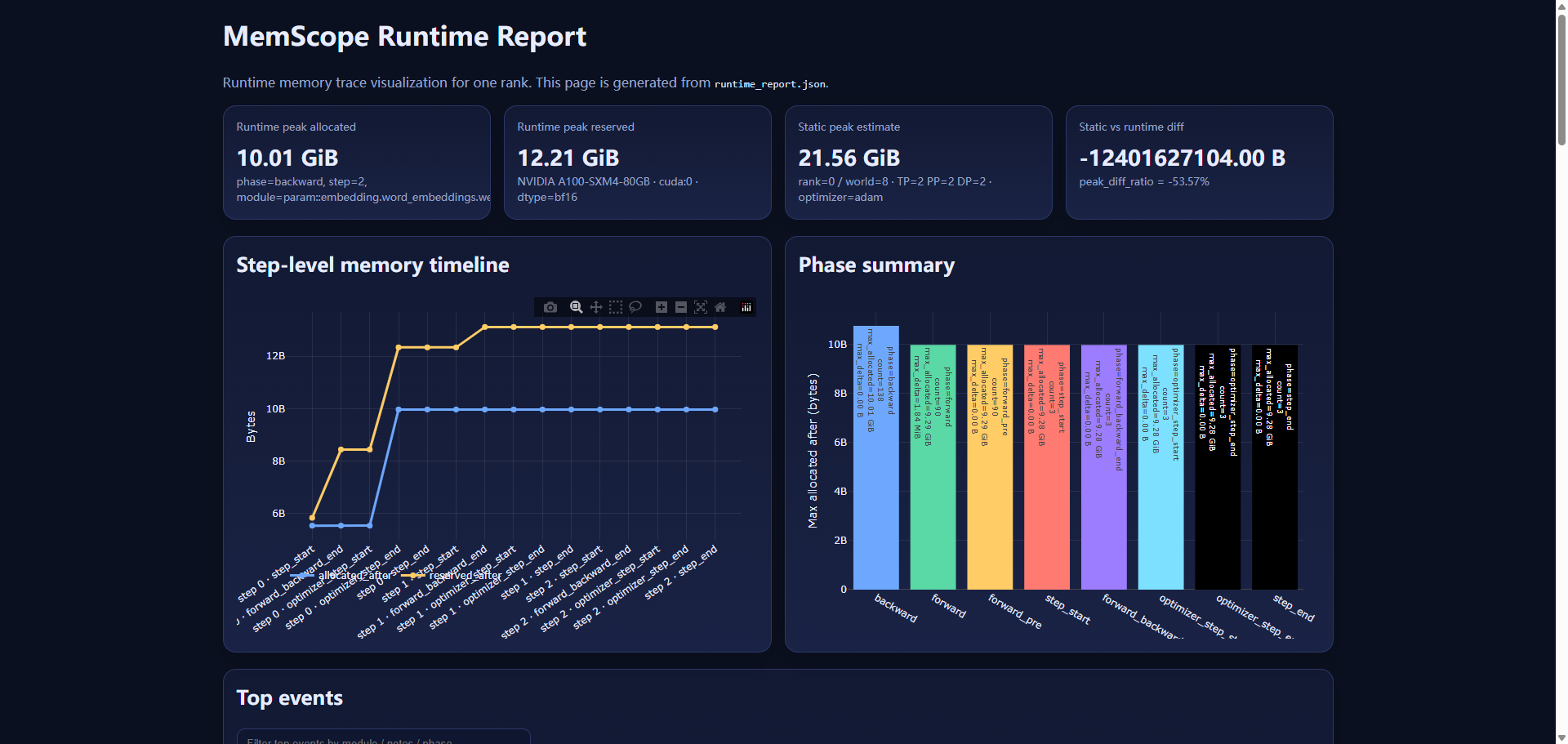
 这张图非常直观地把两种典型问题分开了:
这张图非常直观地把两种典型问题分开了:
一种是“台阶”,比如 step0 optimizer 之后 allocated 基线突然抬高,然后后续保持稳定——这往往是 Adam 状态(m/v 等)第一次初始化造成的常驻增长,不是泄漏;另一种是“峰值”,比如 backward 附近冲到最高,说明激活/梯度相关的暂态开销在顶峰。
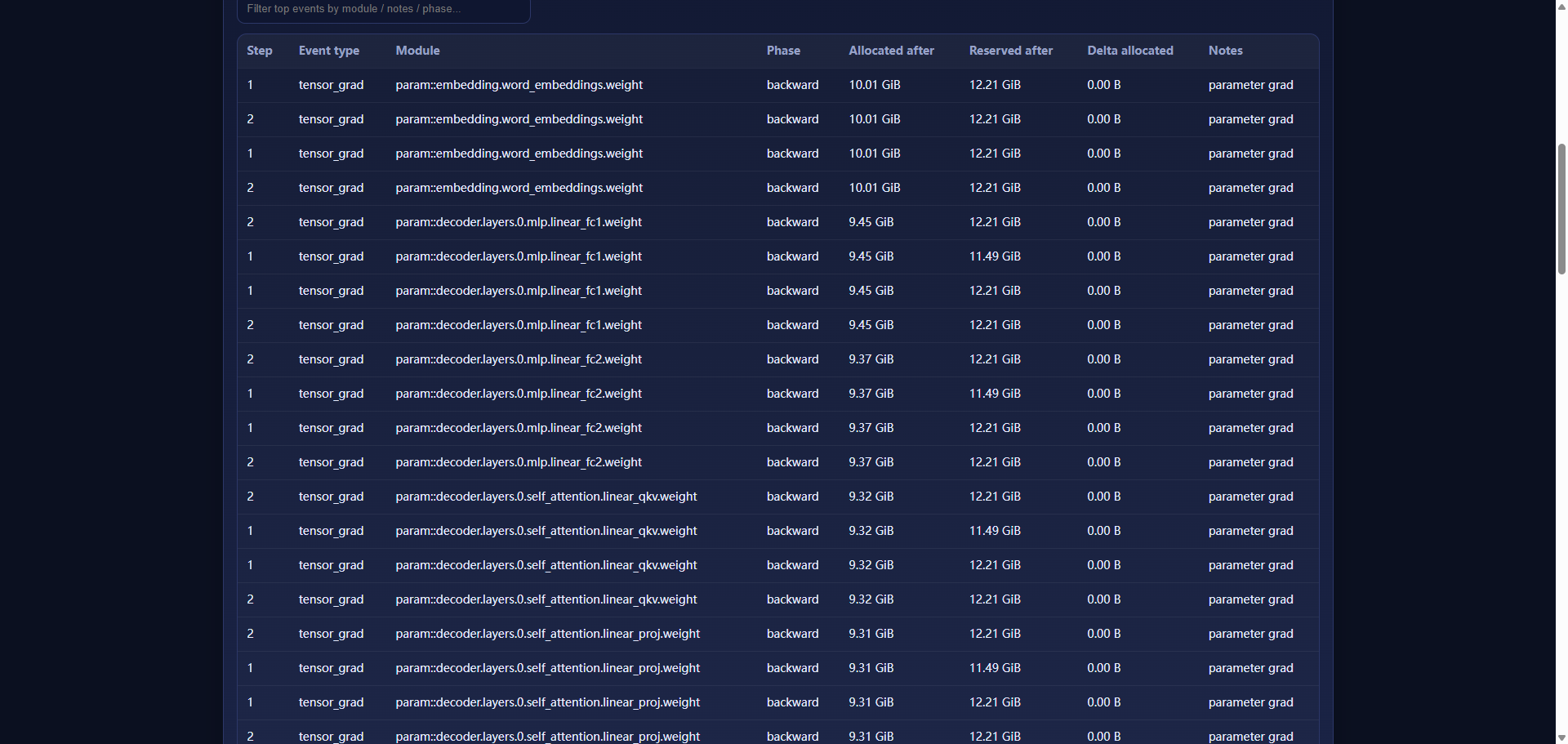
页面里还有两块信息非常好用:一个是 Top events(按当时 allocated 水位最高排序),你可以快速定位峰值发生在什么 step、什么 phase、靠近哪个模块;另一个是 Module aggregate(按模块聚合,给出 max_delta_allocated),当你想知道“到底哪个模块 forward 结束后净增量最大”时,它比盯着一长串原始日志舒服太多。
说白了,这页报告解决的是“看见”和“定位”:你不再只知道“显存爆了”,你能看到爆之前显存怎么涨、在哪个阶段涨得最凶、峰值落在哪个模块附近。
架构图:MemScope 其实就是四个东西串起来
为了让这件事不变成“又一个黑盒监控脚本”,我把 MemScope 的结构做得很工程化:训练侧只需要在合适的位置调用回调,剩下的事情都由 MemScope 自己完成。整体可以用一张简单的图概括:
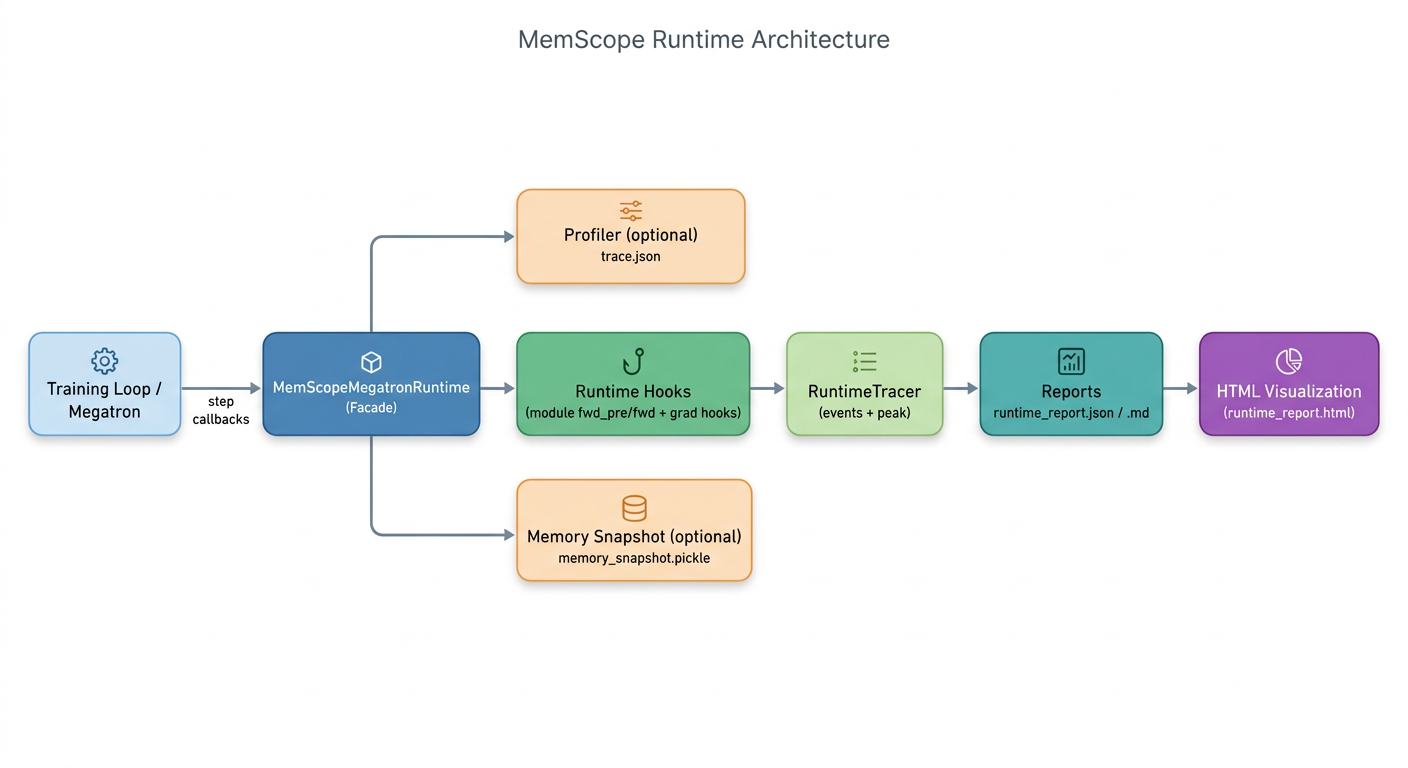
这里的关键点只有两个:
第一,Hooks负责把训练过程切成一串“事件”(模块前后、梯度回传、step 边界),每个事件都带一份显存快照;第二,Tracer把事件按时间顺序收集起来,同时维护一个全局峰值(peak allocated/reserved + 发生位置),最终落盘成 JSON/Markdown。可视化只是读 JSON 做渲染,离线可打开、不需要服务端。
Profiler 和 snapshot 是可选项:如果你只想看基线、台阶、峰值位置,hooks + tracer 就够;如果你要抓到更细的“算子级瞬时尖峰”或做 allocator 级归因,再打开 profiler/snapshot 即可。
跑起来:从 JSON 到一页 HTML
MemScope 运行时会在输出目录按 rank 存放产物。你通常会看到类似结构:
memscope_outputs/
rank00000/
runtime_report.json
runtime_report.md
runtime_report.html # 可视化生成后
trace.json # 如果开 profiler
memory_snapshot.pickle# 如果开 snapshot可视化这步不需要 GPU,也不需要重新跑训练,纯离线把 JSON 变成 HTML:
python -m memscope.cli visualize-runtime \
--report memscope_outputs/rank00000/runtime_report.json 不传 --out 的话,会默认生成同名 .html,例如 runtime_report.html。打开浏览器看就行。
我自己看报告一般就三个动作:先看 timeline 有没有台阶、峰值大概在哪个阶段;再看 Top events 找峰值附近的模块名;最后去 Module aggregate 看“谁的净增量最大”,很多时候这就够你做下一步优化了(比如开 checkpoint、调 bucket、改某层实现、或者确认 optimizer 初始化是正常台阶)。
两个“为什么它能用”的技术细节
这里我只挑两点讲,因为它们直接决定了 MemScope 的报告是不是“能解释”的。
第一点是模块级净增量的计算方式。很多工具只会在某个大阶段结束时采一次显存,比如 forward 结束看一眼。但这样你最多得到“现在很高”,得不到“是谁造成的”。MemScope 在模块 forward 上做的是pre/post 配对:forward_pre 采一次显存,forward 结束再采一次显存,然后用模块名把两次配对起来算 delta_allocated。这就让你能回答“这个模块跑完,显存净增了多少”。它不完美——模块内部如果出现“分配大块临时内存、结束前释放”,净增量可能接近 0,这种瞬时尖峰仍可能漏掉——但它足够实用:绝大多数“常驻增量”和“阶段性抬升”都能被这套机制定位出来。
第二点是同时记录 allocated 和 reserved。这件事看起来很基础,但真能救命。很多人第一次看显存曲线,会把 reserved 当成“泄漏”。实际上 caching allocator 预留显存、碎片化、缓存复用都会让 reserved 维持在高位甚至阶梯上升,而 allocated 才更接近“当前真正用着的张量显存”。MemScope 把两者放在一张 timeline 上,让你不至于只看一个指标就下结论。更进一步,如果你想知道 reserved 的内部构成(到底是谁导致 allocator 申请了新大块),那就轮到 snapshot 出场——MemScope 已经把 _record_memory_history / _dump_snapshot 这条链路打通了,你需要更深的证据时可以再开,不用一上来就把自己拖进 profiler 的开销里。
把显存问题从“感觉”变成“证据”
我现在越来越觉得,显存排查最需要的不是“更多经验”,而是“更少猜测”。MemScope 做的事情并不魔法:它只是把训练过程切成事件、在事件上采样、把峰值和台阶变得可见,然后给你一页能搜索、能对照、能复盘的报告。
你可以用它做三件很具体的事:
当 OOM 出现时,定位峰值发生在什么时候、靠近哪个模块;当显存基线出现台阶时,判断是 step0 初始化还是泄漏;当你做了优化(checkpoint、并行策略、bucket、dtype 等)时,用同一套报告做前后对比,而不是靠“我感觉好像省了点”。
如果你打算把它当成团队里的“显存取证工具”,我建议你从最轻量的路径开始:只开 hooks + HTML,把基线/峰值先看清楚;真的需要抓尖峰或做 allocator 归因,再逐步打开 profiler 或 snapshot。这样你不会被工具反过来拖慢训练节奏,也不会在一堆 trace 里迷路。
项目的github链接:https://github.com/junjiewang253-ctrl/memscope

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)