Langchain(二)
四. Langchain之Chain链
-
为开发更复杂的应用程序,需要使用Chain来链接LangChain中的各个组件和功能,包括模型之间的链接以及模型与其他组件之间的链接
-
链在内部把一系列的功能进行封装,而链的外部则又可以组合串联。 链其实可以被视为LangChain中的一种基本功能单元。
-
API地址:https://python.langchain.com/api_reference/langchain/chains.html
1. 链的基本使用
-
LLMChain是最基础也是最常见的链。LLMChain结合了语言模型推理功能,并添加了PromptTemplate和Output Parser等功能,将模型输入输出整合在一个链中操作。
-
它利用提示模板格式化输入,将格式化后的字符串传递给LLM模型,并返回LLM的输出。这样使得整个处理过程更加高效和便捷。
1.1 使用chain
from langchain.chains.llm import LLMChain
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
import os
from dotenv import load_dotenv
load_dotenv()
# 原始字符串模板
template = "桌上有{number}个苹果,四个桃子和 3 本书,一共有几个水果?"
# 创建模型实例
llm = ChatOpenAI(api_key=os.getenv("api_key"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model='qwen-max',
temperature=0)
# 创建LLMChain
llm_chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template(template)
)
# 调用LLMChain,返回结果
result = llm_chain.invoke({"number": 2})
print(type(result))
print(result['text'])1.3 使用表达式语言 (LCEL)
-
LangChain Expression Language 是一种以声明式方法,轻松地将链或组件组合在一起的机制。通过利用管道操作符,构建的任何链将自动具有完整的同步、异步和流式支持。
-
LangChain 表达式语言(LangChain Expression Language,简称 LCEL)是一种专为链组件(Chain)编排设计的声明式语法,其核心价值在于以统一的方式实现从简单到复杂的 AI 应用构建。从设计之初,LCEL 就致力于消除原型开发与生产部署间的鸿沟 —— 无论是基础的 "提示词 + LLM" 单链结构,还是包含 100 + 步骤的复杂工作流,均可通过同一套语法实现,无需修改代码逻辑。
-
python实现管道调用
class Chain(): def __init__(self, value): self.value = value def __or__(self, other): # 调用 | 运算符 触发的魔法方法 return other(self.value) def prompt(text): return "请求回答问题:{}".format(text) aa = Chain('人工智能是什么?') res = aa | prompt print(res) -
普通调用

from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
import os
load_dotenv()
# 创建提示词
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
# 创建llm模型
model = ChatOpenAI(api_key=os.getenv("api_key"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus")
# 创建输出解释器
output_parser = StrOutputParser()
# 使用chain链在一起
chain = prompt | model | output_parser
print(chain.invoke({"topic": "ice cream"}))
2. Runnable是什么?
-
Runnable 接口是
LangChain 0.2版本后推出的核心抽象层,旨在通过函数式编程模型统一各类 AI 组件的交互方式。它将语言模型(LLM)、链(Chain)、工具调用、数据处理等操作抽象为可组合的 "可运行单元"(Runnable),允许开发者以类似流水线(Pipeline)的方式编排复杂逻辑,而无需关注底层实现细节。
2.1 核心特性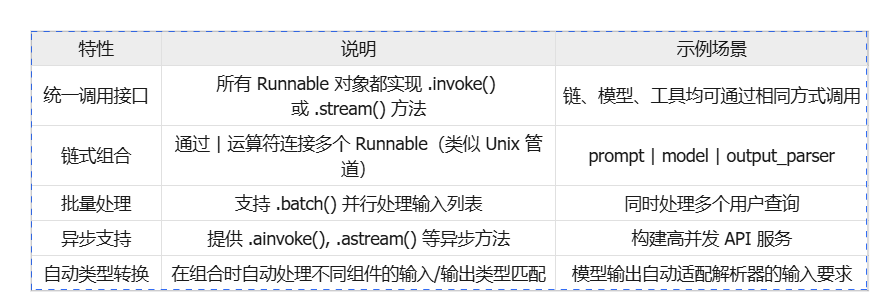
2.2 主要实现类
-
LangChain中几乎所有核心组件都实现了Runnable接口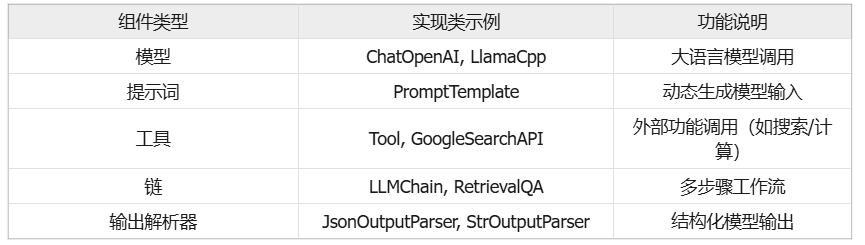
-
https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.base.Runnable.html#langchain_core.runnables.base.Runnable可以在这个网站中查询所有Runnable对应的方法
2.3 案例
from langchain_openai import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.vectorstores import InMemoryVectorStore
from langchain.schema.runnable import RunnableMap, RunnableBranch, RunnableLambda
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_huggingface import HuggingFaceEmbeddings
from dotenv import load_dotenv
import os
load_dotenv()
class TravelQASystem:
def __init__(self, openai_api_key, serpapi_api_key, embed_path):
"""初始化旅游问答系统核心组件"""
# 初始化语言模型
self.llm = ChatOpenAI(api_key=openai_api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus")
# 初始化搜索工具
self.search = TavilySearchResults(tavily_api_key=serpapi_api_key)
# 初始化嵌入模型
self.embeddings = HuggingFaceEmbeddings(model_name=embed_path)
# 构建景点知识库
self.attraction_data = [
"故宫:北京地标,明清皇宫,开放时间8:30-17:00",
"颐和园:皇家园林,昆明湖、长廊等景点",
"八达岭长城:距离市区70公里,建议游览3-4小时"
]
# 使用内存型向量存储类
self.vector_store = InMemoryVectorStore.from_texts(
self.attraction_data, self.embeddings, k=1
)
def setup_runnable_pipeline(self):
"""定义Runnable流程管道"""
# 3.1 问题解析模块:识别地点与查询类型
parse_prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="你是旅游助手,需从用户问题中提取地点和查询类型(天气/景点介绍/行程规划)"),
("user", """问题:{user_question}请以JSON格式返回:{{"location": "地点", "type": "查询类型"}}""")
])
parse_module = parse_prompt | self.llm | JsonOutputParser() # Output JSON string
# 3.2 并行数据获取:天气查询+景点信息检索
weather_query = RunnableLambda(
lambda x: self.search.invoke(f"{x['location']} 今日天气")
)
attraction_retrieval = (lambda x: x["location"]) | self.vector_store.as_retriever() | (
lambda x: x[0].page_content)
# RunnableMap:并行执行天气查询和景点检索
data_acquisition = RunnableMap({
"weather": weather_query,
"attraction": attraction_retrieval,
"location": (lambda x: x["location"])
})
# 3.3 回答生成模块:整合信息并格式化
generate_prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="你是专业旅游顾问,需结合景点信息和天气生成建议"),
("user", """地点:{location}
景点信息:{attraction}
天气情况:{weather}
请生成1条行程建议,包含注意事项(如天气相关准备)""")
])
generate_module = generate_prompt | self.llm | (lambda x: x.content.strip())
"""
RunnableBranch实现
RunnableBranch(
(lambda x: 条件1, 执行的代码),
(lambda x: 条件2, 执行的代码2),
lambda x: {"location": x["location"], "attraction": attraction_retrieval.invoke(x)}
)
"""
# 3.4 全流程串联
self.travel_qa_pipeline = (
# 阶段1:解析问题
parse_module
| (lambda x: {"location": x["location"], "type": x["type"]})
# 阶段2:并行获取数据(仅当查询类型为天气或行程时触发)
# RunnableBranch:根据查询类型选择数据获取路径
| RunnableBranch(
(lambda x: "天气" in x["type"], data_acquisition),
lambda x: {"location": x["location"], "attraction": attraction_retrieval.invoke(x)}
)
# 阶段3:生成回答
| generate_module
)
def process_user_question(self, user_question):
"""处理用户提问并返回回答"""
input_data = {"user_question": user_question}
# try:
response = self.travel_qa_pipeline.invoke(input_data)
return response
# 示例用法
if __name__ == "__main__":
# 替换为实际API密钥
OPENAI_API_KEY = os.getenv("DASHSCOPE_API_KEY")
# https://www.tavily.com/
SERPAPI_API_KEY = os.getenv("TAVILY_API_KEY")
embed_path = r"D:\LLM\Local_model\BAAI\bge-large-zh-v1___5"
# 初始化系统
travel_qa = TravelQASystem(OPENAI_API_KEY, SERPAPI_API_KEY, embed_path)
travel_qa.setup_runnable_pipeline()
# 测试1:查询天气与景点建议
question1 = "今天故宫的天气怎么样?"
answer1 = travel_qa.process_user_question(question1)
print(f"User Question: {question1}\nAI Answer: {answer1}\n")
链的调用方式
Agent代理的核心思想是使用语言模型来选择要采取的一系列动作。在链中,动作序列是硬编码的。
在代理中,语言模型用作推理引擎来确定要采取哪些动作以及按什么顺序进行。
因此,在LangChain中,Agent代理就是使用语言模型作为推理引擎,让模型自主判断、调用工具和决定下一步行动。
Agent代理像是一个多功能接口,能够使用多种工具,并根据用户输入决定调用哪些工具,同时能够将一个工具的输出数据作为另一个工具的输入数据。
1. Agent的基本使用
1.1 Tavily在线搜索
-
通过invoke方法
from langchain_core.prompts import PromptTemplate from langchain_openai import ChatOpenAI from dotenv import load_dotenv import os load_dotenv() # 原始字符串模板 template = "桌上有{number}个苹果,四个桃子和 3 本书,一共有几个水果?" prompt = PromptTemplate.from_template(template) # 创建模型实例 llm = ChatOpenAI(api_key=os.getenv("api_key"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model='qwen-plus', temperature=0) # 创建Chain chain = prompt | llm # 调用Chain,返回结果 result = chain.invoke({"number": "3"}) print(result)通过batch方法(原apply方法):batch方法允许输入列表运行链,一次处理多个输入。
from langchain.chains.llm import LLMChain from langchain_core.prompts import PromptTemplate from langchain_openai import ChatOpenAI from dotenv import load_dotenv import os load_dotenv() # 创建模型实例 template = PromptTemplate( input_variables=["role", "fruit"], template="{role}喜欢吃{fruit}?", ) # 创建LLM llm = ChatOpenAI(api_key=os.getenv("api_key"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model='qwen-plus', temperature=0) # 创建LLMChain 0.1.17 开始被标记为弃用,并计划在未来的 1.0 版本中移除 # llm_chain = LLMChain(llm=llm, prompt=template) llm_chain = template | llm # 输入列表 input_list = [ {"role": "猪八戒", "fruit": "人参果"}, {"role": "孙悟空", "fruit": "仙桃"} ] # 调用LLMChain,返回结果 result = llm_chain.batch(input_list) print(result[0].content) print(result[1].content)五. Agent代理
在LangChain框架中,Agents是一种利用大型语言模型(Large Language Models,简称LLMs)来执行任务和做出决策的系统
在 LangChain 的世界里,Agent 是一个智能代理,它的任务是听取你的需求(用户输入)和分析当前的情境(应用场景),然后从它的工具箱(一系列可用工具)中选择最合适的工具来执行操作
-
使用工具(Tool):LangChain中的Agents可以使用一系列的工具(Tools)实现,这些工具可以是API调用、数据库查询、文件处理等,Agents通过这些工具来执行特定的功能。
-
推理引擎(Reasoning Engine):Agents使用语言模型作为推理引擎,以确定在给定情境下应该采取哪些行动,以及这些行动的执行顺序。
-
可追溯性(Traceability):LangChain的Agents操作是可追溯的,这意味着可以记录和审查Agents执行的所有步骤,这对于调试和理解代理的行为非常有用。
-
自定义(Customizability):开发者可以根据需要自定义Agents的行为,包括创建新的工具、定义新的Agents类型或修改现有的Agents。
-
交互式(Interactivity):Agents可以与用户进行交互,响应用户的查询,并根据用户的输入采取行动。
-
记忆能力(Memory):LangChain的Agents可以被赋予记忆能力,这意味着它们可以记住先前的交互和状态,从而在后续的决策中使用这些信息。
-
执行器(Agent Executor):LangChain提供了Agent Executor,这是一个用来运行代理并执行其决策的工具,负责协调代理的决策和实际的工具执行。
-
构建一个具有两种工具的代理:一种用于在线查找,另一种用于查找加载到索引中的特定数据。
-
在LangChain中有一个内置的工具,可以方便地使用Tavily搜索引擎作为工具。
-
访问Tavily(用于在线搜索)注册账号并登录,获取API 密钥
-
TAVILY_API_KEY申请:https://tavily.com/
-
# 加载所需的库 import os from langchain_community.tools.tavily_search import TavilySearchResults from dotenv import load_dotenv load_dotenv() # 查询 Tavily 搜索 API 并返回 json 的工具 search = TavilySearchResults(tavily_api_key=os.getenv("tavily_key")) # 执行查询 res = search.invoke("目前市场上苹果手机16的售价是多少?") print(res)创建检索器
-
根据上述查询结果中的某个URL中,获取一些数据创建一个检索器。
-
# 加载所需的库
import os
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from dotenv import load_dotenv
load_dotenv()
# 查询 Tavily 搜索 API 并返回 json 的工具
# search = TavilySearchResults()
# # 执行查询
# res = search.invoke("目前市场上苹果手机16的售价是多少?")
# print(res)
# 创建索引器根据上述查询的结果
# 加载HTML内容为一个文档对象
loader = WebBaseLoader("https://news.qq.com/rain/a/20240920A07Y5Y00")
# 读取文档
docs = loader.load()
# print(docs)
# 分割文档
documents = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200).split_documents(docs)
# 向量化
vector = FAISS.from_documents(documents, DashScopeEmbeddings(dashscope_api_key=os.getenv('api_key')))
# 创建检索器
retriever = vector.as_retriever()
# 测试检索结果
print(retriever.get_relevant_documents("目前市场上苹果手机16的售价是多少?"))-
得到工具列表
-
from langchain.tools.retriever import create_retriever_tool # 创建一个工具来检索文档 retriever_tool = create_retriever_tool( retriever, "iPhone_price_search", "搜索有关 iPhone 16 的价格信息。对于iPhone 16的任何问题,您必须使用此工具!", ) # 创建将在下游使用的工具列表 tools = [search, retriever_tool]对接大模型
-
创建Agent,这里使用LangChain中一个叫OpenAI functions的代理,然后得到一个AgentExecutor代理执行器
# 加载所需的库
import os
from langchain import hub
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_openai import ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from dotenv import load_dotenv
from langchain.tools.retriever import create_retriever_tool
load_dotenv()
# 查询 Tavily 搜索 API 并返回 json 的工具
search = TavilySearchResults(tavily_api_key=os.getenv("tavily_key"))
# # 执行查询
# res = search.invoke("目前市场上苹果手机16的售价是多少?")
# print(res)
# 创建索引器根据上述查询的结果
# 加载HTML内容为一个文档对象
loader = WebBaseLoader("https://news.qq.com/rain/a/20240920A07Y5Y00")
# 读取文档
docs = loader.load()
# print(docs)
# 分割文档
documents = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200).split_documents(docs)
# 向量化
vector = FAISS.from_documents(documents, DashScopeEmbeddings(dashscope_api_key=os.getenv('api_key')))
# 创建检索器
retriever = vector.as_retriever()
# 测试检索结果
# print(retriever.get_relevant_documents("目前市场上苹果手机16的售价是多少?"))
# 创建一个工具来检索文档
retriever_tool = create_retriever_tool(
retriever,
"iPhone_price_search",
"搜索有关 iPhone 16 的价格信息。对于iPhone 16的任何问题,您必须使用此工具!",
)
# 创建将在下游使用的工具列表
tools = [search, retriever_tool]
# 初始化大模型
llm = ChatOpenAI(api_key=os.getenv("api_key"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model='qwen-plus', temperature=0)
# https://smith.langchain.com/hub
# 获取要使用的提示
prompt = hub.pull("hwchase17/openai-functions-agent")
# 打印Prompt
# print(prompt)
# 使用OpenAI functions代理
from langchain.agents import create_openai_functions_agent
# 构建OpenAI函数代理:使用 LLM、提示模板和工具来初始化代理
agent = create_openai_functions_agent(llm, tools, prompt)
from langchain.agents import AgentExecutor
# 将代理与AgentExecutor工具结合起来
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 执行代理 进行对比
# agent_executor.invoke({"input": "目前市场上苹果手机16的各个型号的售价是多少?如果我在此基础上加价5%卖出,应该如何定价?"})
agent_executor.invoke({"input": "美国2024年谁胜出了总统的选举?"})
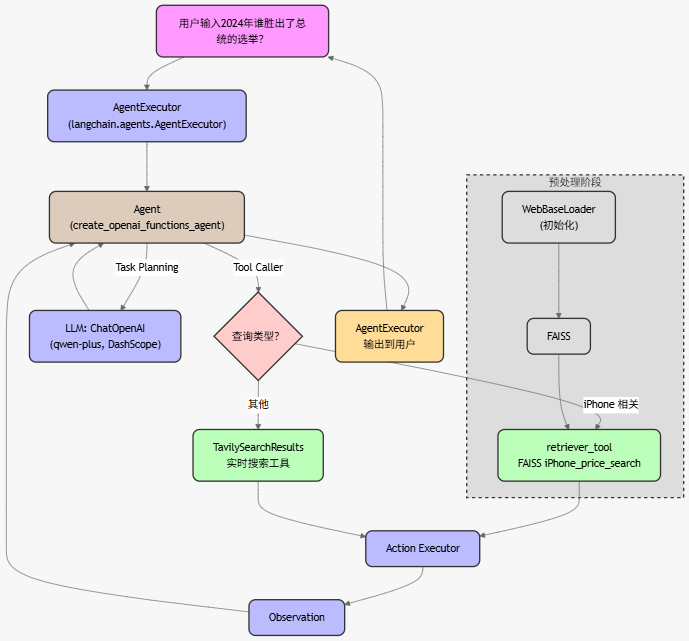
2. OpenAI Functions Agent
from langchain.agents import create_openai_functions_agent, AgentExecutor
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_core.tools import Tool
import os
from dotenv import load_dotenv
load_dotenv()
# 定义查询订单状态的函数
def query_order_status(order_id):
if order_id == "1024":
return "订单 1024 的状态是:已发货,预计送达时间是 3-5 个工作日。"
else:
return f"未找到订单 {order_id} 的信息,请检查订单号是否正确。"
# 定义退款政策说明函数
def company_refund_policy(company_name):
print(company_name)
if company_name == "tom公司":
return "tom公司的退款政策是:在购买后7天内可以申请全额退款,需提供购买凭证。"
else:
print('输入有误')
# 查询年龄
def get_age(name):
if name == "tom":
print(name)
return "我的年龄是56岁!"
else:
print('输入有误')
# 初始化工具
tools = [
TavilySearchResults(max_results=1, tavily_api_key=os.getenv("tavily_key")),
Tool(
name="queryOrderStatus",
func=query_order_status,
description="根据订单ID查询订单状态",
args={"order_id": "订单的ID"}
),
Tool(
name="companyRefundPolicy",
func=company_refund_policy,
description="查询某某公司退款政策详细内容",
args={"company_name": "公司名称"}
),
Tool(
name="getAge",
func=get_age,
description="查询tom年龄大小",
args={"name": "查询tom年龄大小"}
),
]
# 获取使用的提示
prompt = ChatPromptTemplate.from_messages([
("system",
"你是一个客服助手,使用工具回答问题。传递给工具的内容必须是准确的json数据不结尾的括号多加一个,如果是字符串数据必须和输入的保持一致要完整,不是篡改**重要规则**, "
),
# 用户输入变量
("user", "{input}"),
# 关键点:添加代理中间步骤占位符
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# print(prompt)
# 选择将驱动代理的LLM
llm = ChatOpenAI(api_key=os.getenv("api_key"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model='qwen-plus')
# 构建OpenAI函数代理
agent = create_openai_functions_agent(llm, tools, prompt)
# 通过传入代理和工具创建代理执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, handle_parsing_errors=True, verbose=True)
# 定义一些测试询问
queries = [
"请问订单1024的状态是什么?",
"请问tom公司退款政策是什么?",
"2024年谁胜出了美国总统的选举"
]
# 运行代理并输出结果
for input in queries:
response = agent_executor.invoke({"input": input})
print(f"客户提问:{input}")
print(f"代理回答:{response}\n")
# response = agent_executor.invoke({"input": "2024年谁胜出了美国总统的选举"})
# print(f"代理回答:{response}\n")
-
六. LangChain之Tools工具
1. 工具Tools
工具是代理、链或LLM可以用来与世界互动的接口。它们结合了几个要素
-
工具的名称
-
工具的描述
-
该工具输入的JSON模式
-
要调用的函数
-
是否应将工具结果直接返回给用户
1.1 工具的初步认识
from langchain_community.tools.tavily_search import TavilySearchResults
from dotenv import load_dotenv
import os
load_dotenv()
# 初始化工具 可以根据需要进行配置
tool = TavilySearchResults(top_k_results=1, doc_content_chars_max=100)
# 工具默认名称
print("name:", tool.name)
# 工具默认的描述
print("description:", tool.description)
# 输入内容 默认JSON模式
print("args:", tool.args)
# 是否直接返回工具的输出。
print("return_direct:", tool.return_direct)
# 可以用字典输入来调用这个工具
print(tool.run({"query": "langchain"}))
# 使用单个字符串输入来调用该工具。
print(tool.run("langchain"))
# 需要科学上网1.2 自定义工具
-
在LangChain中,自定义工具有多种方法
-
@tool装饰器
-
@tool装饰器是定义自定义工具的最简单方法。装饰器默认使用函数名称作为工具名称,但可以通过传递字符串作为第一个参数来覆盖此设置。此外,装饰器将使用函数的文档字符串作为工具的描述 - 因此必须提供文档字符串。
from langchain.tools import tool
@tool
def add_number(a: int, b: int) -> int:
"""add two numbers."""
return a + b
print(add_number.name)
print(add_number.description)
print(add_number.args)
res = add_number.run({"a": 10, "b": 20})
print(res)
七. LangChain之Memory
-
大多数的 LLM 应用程序都会有一个会话接口,允许我们和 LLM 进行多轮的对话,并有一定的上下文记忆能力。但实际上,模型本身是不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。而实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把所有的历史信息都输入给模型,让模型输出最终结果。
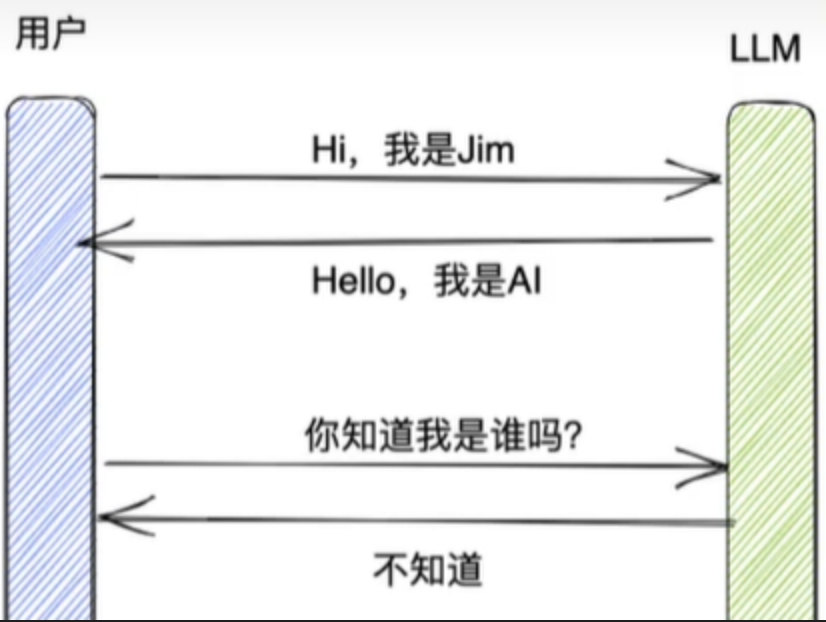
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
import os
load_dotenv()
llm = ChatOpenAI(api_key=os.getenv("api_key"),
base_url=os.getenv("base_url"),
model_name="qwen-plus")
# 直接提供问题,并调用llm
response = llm.invoke("你好我是宝宝")
# print(response)
# print("=" * 50)
print(response.content)
response = llm.invoke("我是谁?")
print(response.content)
-
而在 LangChain 中,提供这个功能的模块就称为 Memory,用于存储用户和模型交互的历史信息。
-
记忆系统需要支持两种基本操作:读取和写入。
-
在接收到初始用户输入之后但在执行核心逻辑之前,链将从其内存系统中读取并增强用户输入。
-
在执行核心逻辑之后但在返回答案之前,链会将当前运行的输入和输出写入内存,以便在将来的运行中引用它们。
-
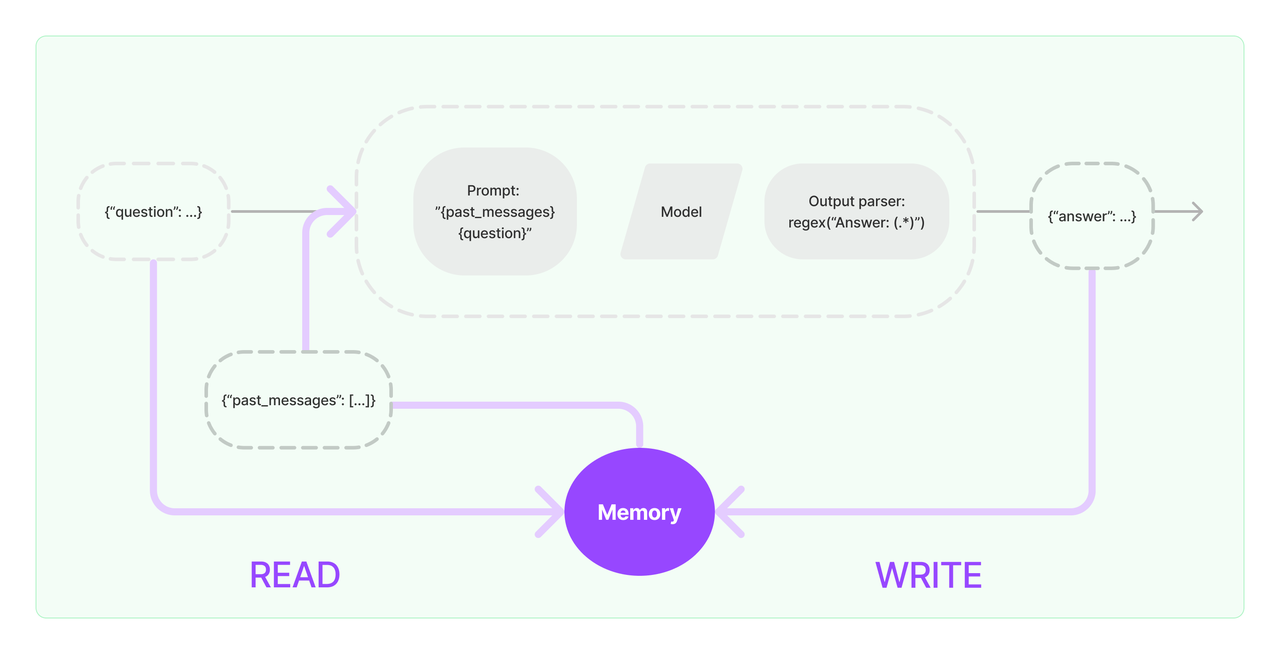
-
对该图的解释:
1、输入问题: ({"question": ...})
2、读取历史消息: 从Memory中READ历史消息({"past_messages": [...]})
3、构建提示(Prompt): 读取到的历史消息和当前问题会被合并,构建一个新的Prompt
4、模型处理: 构建好的提示会被传递给语言模型进行处理。语言模型根据提示生成一个输出。
5、解析输出: 输出解析器通过正则表达式 regex("Answer: (.*)")来解析,返回一个回答({"answer": ...})给用户
6、得到回复并写入Memory: 新生成的回答会与当前的问题一起写入Memory,更新对话历史。Memory会存储最新的对话内容,为后续的对话提供上下文支持。
1. Chat Messages
-
Chat Messages: 最基础的记忆管理方法,是用于管理和存储对话历史的具体实现。它们通常用于构建对话系统,帮助系统保持对话的连续性和上下文。这些消息通常包含了对话的每一轮,包括用户的输入和系统的响应。
2. RunnableWithMessageHistory
-
RunnableWithMessageHistory包装另一个 Runnable 并为其管理聊天消息历史记录;它负责读取和更新聊天消息历史记录。
2.1 本地内存存储
-
可以将聊天记录进行本地存储
import json
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain.schema import messages_from_dict, messages_to_dict
from dotenv import load_dotenv
import os
# 加载环境变量(需要包含API_KEY)
load_dotenv()
# 初始化大语言模型(通义千问)
llm = ChatOpenAI(
api_key=os.getenv("api_key"), # 从环境变量读取API密钥
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 阿里云兼容端点
model="qwen-turbo" # 使用qwen-turbo模型
)
# 创建对话提示模板
prompt = ChatPromptTemplate.from_messages([
# 系统角色设定
("system", "你是一个友好的助手"),
# 历史消息占位符(变量名必须与链配置中的history_messages_key一致)
MessagesPlaceholder(variable_name="history"),
# 用户输入占位符
("user", "{input}")
])
# 构建基础对话链(组合提示模板和语言模型)
base_chain = prompt | llm
# 全局会话存储字典(Key: session_id, Value: ChatMessageHistory实例)
store = {}
def get_session_history(session_id):
"""获取或创建会话历史存储对象
Args:
session_id: 会话唯一标识(用于多会话隔离)
Returns:
对应会话的聊天历史记录对象
"""
if session_id not in store:
store[session_id] = ChatMessageHistory() # 初始化空历史记录
return store[session_id]
# 创建支持历史记录的对话链
conversation = RunnableWithMessageHistory(
base_chain, # 基础对话链
get_session_history=get_session_history, # 历史记录获取方法
input_messages_key="input", # 输入文本的键名
history_messages_key="history" # 历史记录的键名(需与提示模板中的变量名一致)
)
def save_memory(filepath, session_id):
"""保存指定会话的历史记录到文件
Args:
filepath: 文件保存路径(建议使用.json扩展名)
session_id: 要保存的会话ID(默认"default")
"""
history = get_session_history(session_id)
# 将消息对象列表转换为字典格式
dicts = messages_to_dict(history.messages)
# 写入JSON文件(UTF-8编码)
with open(filepath, "w", encoding='utf-8') as f:
json.dump(dicts, f, ensure_ascii=False)
def load_memory(filepath, session_id):
"""从文件加载历史记录到指定会话
Args:
filepath: 历史记录文件路径
session_id: 要加载到的会话ID(默认"default")
"""
with open(filepath, "r", encoding='utf-8') as f:
dicts = json.load(f)
# 将字典转换回消息对象列表
messages = messages_from_dict(dicts)
# 更新全局存储中的会话历史
store[session_id] = ChatMessageHistory(messages=messages)
def legacy_predict(input_text: str, session_id: str = "default") -> str:
"""模拟旧版predict方法的调用接口
Args:
input_text: 用户输入文本
session_id: 会话ID(默认"default")
Returns:
AI生成的回复文本
"""
return conversation.invoke(
{"input": input_text}, # 输入参数
# 配置参数(必须包含session_id来关联历史记录)
config={"configurable": {"session_id": session_id}}
).content
if __name__ == "__main__":
# 使用默认会话ID
SESSION_ID = "default"
# 模拟连续对话(4轮)
legacy_predict("你好", SESSION_ID) # 问候
legacy_predict("你是谁,我是宝宝", SESSION_ID) # 身份确认
legacy_predict("你的背后实现原理是什么", SESSION_ID) # 技术原理询问
# 查询对话历史(第4轮)
last_response = legacy_predict('截止到现在我们聊了什么?', SESSION_ID)
print("最后一次回答:", last_response)
# 持久化保存对话历史(JSON格式)
save_memory("./memory_new.json", SESSION_ID)
# 模拟重新加载历史记录(清空当前会话后重新加载)
load_memory("./memory_new.json", SESSION_ID)
# 验证历史恢复效果(第5轮)
reload_response = legacy_predict("我回来了,我们之前都聊了一些什么?", SESSION_ID)
print("\n恢复后的回答:", reload_response)八. LangSmith使用
1. 什么是 LangSmith?
LangSmith 是一个用于构建、调试和监控大型语言模型 (LLM) 应用的平台,由 LangChain 团队开发。它帮助开发者跟踪 LLM 的调用、性能和输出,优化提示词(Prompt)设计,并管理数据集和评估。
主要功能:
-
跟踪(Tracing):记录 LLM 调用、输入输出和元数据。
-
调试(Debugging):分析模型行为,识别问题。
-
数据集管理:创建和维护测试数据集。
-
评估(Evaluation):运行测试用例,评估模型性能。
-
监控(Monitoring):实时监控生产环境中的 LLM 应用。
2. 配置 API 密钥
-
注册
LangSmith账号。 -
在
LangSmith仪表板中获取 API 密钥。 -
设置环境变量:.env
LANGSMITH_API_KEY = 'Langsmith-key' LANGCHAIN_TRACING_V2="true" LANGCHAIN_PROJECT="在Langsmith存储的名称" LANGCHAIN_ENDPOINT="https://api.smith.langchain.com" # 任务发布站点
-
执行代码不需要有任何的改动,会自动把执行的内容上传到
Langsmith进行管理,在平台把任务已树结构展示项目的内容,展示项目的耗时,加载的提示词内容等等
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
import os
# 定义小红书文案提示词
prompt = PromptTemplate.from_template("""
你是一位小红书内容创作者,擅长撰写简洁、吸引人的种草文案。目标是创作100-150字的小红书风格文案,面向18-35岁用户,激发兴趣和互动。
**输入**:
- 产品/主题:{product}
- 核心特点:{features}
- 目标情绪:{emotion}
- 目标行动:{action}
**要求**:
1. 风格:亲切、口语化,带小幽默或生活场景,融入“种草”“安利”等流行词。
2. 结构:吸睛开头(问题/场景),中间突出特点,结尾引导互动(提问/号召)。
3. 使用1-2个emoji,保持自然。
4. 标题:10字以内。
**输出**:
标题:
文案正文:分2-3段,每段2-3句,结尾带互动引导
""")
llm = ChatOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url=os.getenv("DASHSCOPE_BASE_URL"),
model='qwen-plus'
)
# 创建 LangChain 链
chain = prompt | llm
# 输入示例
input_data = {
"product": "无线耳机",
"features": "音质清晰、佩戴舒适、续航长",
"emotion": "科技感、轻松",
"action": "分享体验"
}
response = chain.invoke(input_data)
# 输出生成的小红书文案
print(response.content)
3. 提示词优化
-
Langsmith提供了提示词优化和导出提示词模版,可以用Langsmith优化自己的提示词得到满意的输出,在将提示词导出使用
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
from langsmith import Client
import os
client = Client(api_key=os.getenv("LANGSMITH_API_KEY"))
prompt = client.pull_prompt("test")#test是存储的prompt
print(prompt)
llm = ChatOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url=os.getenv("DASHSCOPE_BASE_URL"),
model='qwen-plus'
)
# 创建 LangChain 链
chain = prompt | llm
# 输入示例
input_data = {
"product": "无线耳机",
"features": "音质清晰、佩戴舒适、续航长",
"emotion": "科技感、轻松",
"action": "分享体验"
}
response = chain.invoke(input_data)
# 输出生成的小红书文案
print(response.content)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)