你分不清 API、MCP和Skills 时,早已混淆了 “接口” 与 “智能”--API、MCP 与 Skills的区别与联系
AI 应用落地的浪潮中,API、MCP 与 Skills 成为大模型能力交付的三大核心载体,却因概念相近常被混淆。从基础接口到标准化协议,再到模块化能力包装,三者层层递进、彼此协同,构筑起 AI 连接世界与执行任务的完整体系。本文将清晰拆解三者的边界与关联,带你读懂 AI 能力扩展的底层逻辑。
先破四个认知误区
误区一:"不用 MCP 就没法查数据库"
真相: 完全不需要 MCP,AI 照样可以查数据库。
# 传统方式:直接给 AI 数据库连接串
import sqlite3
def query_db(sql):
conn = sqlite3.connect('data.db')
return conn.execute(sql).fetchall()
# AI 生成 SQL → 执行 → 返回结果
# 这种方式已经存在几十年了,完全可行MCP 的价值不在于"能不能",而在于"标准化"。它解决的是不同 AI 应用复用同一套工具集成的问题,而非提供新的技术能力。
误区二:"MCP 和 Skills 都是封装的 API"
真相: 两者封装的对象完全不同。
|
概念 |
封装的是 |
类比 |
|---|---|---|
| API |
数据/功能 |
餐厅后厨(提供食材加工) |
| MCP |
连接协议 |
外卖平台标准(统一接单、配送流程) |
| Skills |
行为逻辑 |
菜谱(告诉你怎么切、怎么炒、按什么顺序) |
MCP 封装的是通信标准(AI 如何发现工具、如何传参、如何接收结果),而 Skills 封装的是工作流和决策逻辑(面对什么场景应该做什么、怎么做)。
误区三:"Skills 都是封装的 MCP"
真相: 实际上两者是正交关系。
Skills 可以完全脱离 MCP 存在:
# Email Classification Skill (纯文本版)
## 工作流
1. 阅读邮件主题和正文
2. 判断紧急程度(高/中/低)
3. 分类标签(工作/广告/社交)
4. 输出 JSON 格式结果
## 分类标准
- 包含"紧急"、"ASAP" → 高优先级
- 发件人域名是 @company.com → 工作标签误区四:MCP 不能脱离 API
真相: MCP 在协议定义上完全不依赖 API,它只规定通信标准,不关心底层实现。虽然工程实践中 90% 的 MCP Server 确实在封装现有 API,但技术上完全可以直接操作文件、数据库或硬件。
关键区分:
|
层级 |
职责 |
是否必须依赖 API |
|---|---|---|
| MCP Protocol |
定义 AI 如何发现工具、传参、接收结果 |
❌ 不依赖 |
| MCP Server 实现 |
具体执行逻辑 |
❌ 可选 |
|
└─ 直接实现 |
本地文件 IO、数据库驱动、系统调用 |
❌ 零 API |
|
└─ API 封装 |
调用 REST/gRPC/第三方 SDK |
✅ 依赖 API |
零 API 的实现示例:
# 文件系统 MCP Server(无 HTTP API 层)
@mcp.tool()
def read_local_file(path: str) -> str:
# 直接系统调用,不经过任何 API
with open(path, 'r') as f:
return f.read()
@mcp.tool()
def query_sqlite(sql: str):
# 直接数据库驱动,无 REST 接口
import sqlite3
conn = sqlite3.connect('local.db')
return conn.execute(sql).fetchall()架构视角:
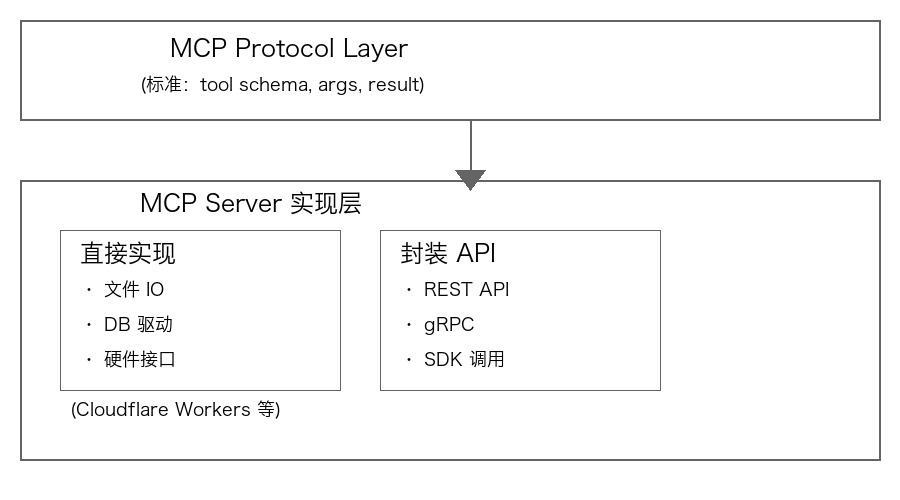
准确说法:
MCP 是 AI 与工具的"通用插头标准",而 API 是发动机的一种。你可以把发动机直接焊在插头上(直接实现),也可以通过传动轴连接(封装 API)。后者更常见,但前者完全可行且符合协议规范。
架构视角:三者的真实位置
让我们看看在完整的 AI 系统中,这三者各自站在什么位置:
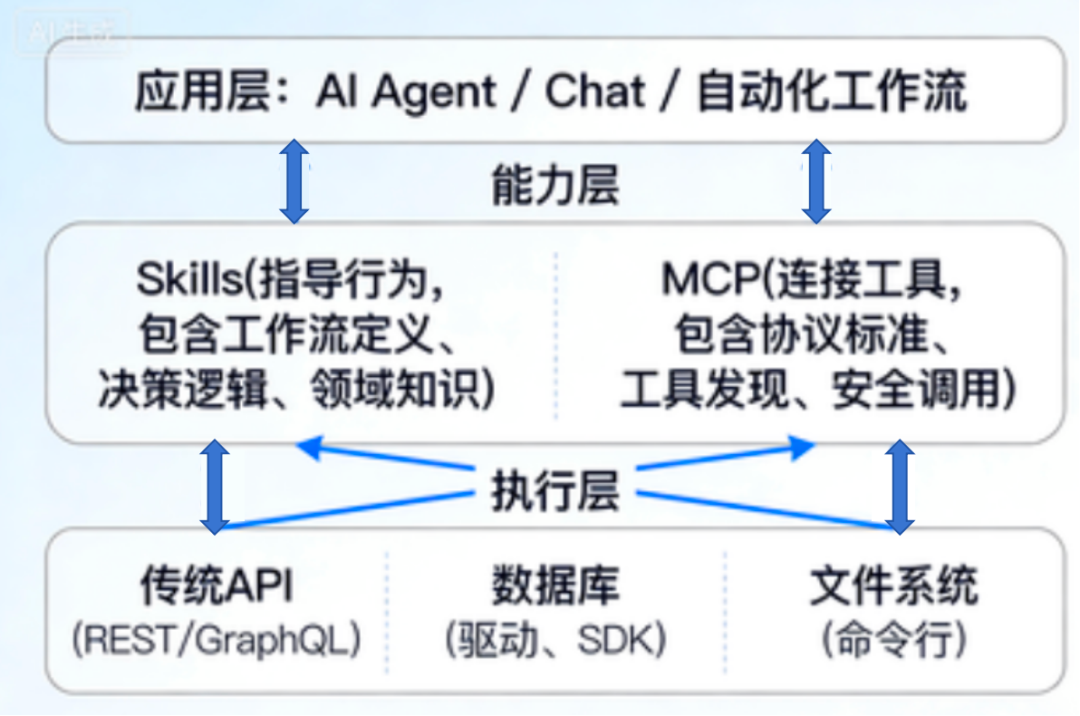
关键洞察:
-
MCP Server 是实际干活的地方,它可以调用传统 API(如 GitHub REST API)、可以直接连数据库(用 JDBC/ODBC)、可以操作本地文件。MCP 只是规定了 AI 怎么和这些 Server 对话,而不是替代了底层实现。
-
Skills 站在更高层,它们告诉 AI:"当用户问天气时,先调用天气 MCP 工具,然后用温暖的语气回复"。这是一种行为编排,而非技术连接。
实战对比:同一个需求,三种实现
需求: 让 AI 查询公司库存并生成报告
方案 A:纯 API 模式(传统)
# 手动集成,每个项目都要重写
import requests
def get_inventory():
headers = {"Authorization": "Bearer " + get_token()}
response = requests.get("https://api.company.com/inventory", headers=headers)
return response.json()
# AI 调用这个函数,处理异常,格式化输出...
# 每个新项目都要重复这套集成代码方案 B:MCP 模式(标准化)
// MCP Server 配置 (inventory-server)
{
"name": "inventory-server",
"tools": [{
"name": "query_inventory",
"description": "查询实时库存",
"parameters": {
"category": "string"
}
}]
}
// AI 自动发现工具,标准化调用
// 不同 AI 应用(Claude、Cursor、Openclaw等)都能复用这个 Server方案 C:Skill + MCP 组合(完整方案)
# 库存分析 Skill
## 触发条件
用户询问库存、销售预测、补货建议时激活。
## 执行流程
1.**数据获取**:调用 `inventory-server/query_inventory`
2.**分析逻辑**:
- 库存 < 安全库存 → 标记"需补货"
- 周转天数 > 30天 → 标记"滞销风险"
3.**输出格式**:
- 先用一句话总结整体状况
- 用表格展示关键 SKU
- 给出具体行动建议(语气要专业且紧迫)
## 示例
用户:看看上周销售情况→ [调用 MCP 工具] → [分析] → "上周 A 类商品动销良好,
但 SKU-8845 库存仅剩 3 件,建议立即补货..."区别一目了然:
-
API 提供原始数据能力
-
MCP 让 AI 能发现并使用这个能力(不用每个项目都写适配代码)
-
Skill 让 AI 用对这个能力(什么时候查、查完后怎么处理、怎么回复)
决策表
|
场景 |
选择 |
原因 |
|---|---|---|
|
已有成熟系统,只需简单 AI 包装 |
传统 API |
引入 MCP 增加复杂度,收益不明显 |
|
需要 AI 调用多样外部工具(查 GitHub、改数据库、发邮件) |
MCP |
标准化降低集成成本,一次开发多端复用 |
|
需要封装复杂业务逻辑(医疗诊断、法律分析、客服 SOP) |
Skills |
将专家知识转化为 AI 行为指导 |
|
AI 既要"做对事"又要"会做事" |
MCP + Skills |
MCP 提供工具,Skills 提供说明书 |
总结
API 是"提供能力",MCP 是"连接能力",Skills 是"指导使用能力"。
-
没有 MCP,你也能查数据库,只是每个项目都要写一遍适配代码;
-
没有 Skills,AI 也能调用工具,只是可能用错场景或输出不符合业务规范;
-
三者结合,才能构建既强大又可靠的 AI 应用。
在架构设计时,记住这个分层:Skills 负责"想得对",MCP 负责"连得上",API 负责"干得了"。混淆这三者的边界,往往会导致架构过度设计或能力不足。
创作不易,禁止抄袭,转载请附上原文链接及标题

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)